畳み込みネットワークとは
画像処理で多く用いられる手法です。CNN(Convolutional Neural Network)とも書かれます。
仕組みはとてもシンプル、以下の処理を繰り返します。
1.畳み込み
2.Activation (活性化関数、多くの場合RelU、非線形性を与えるため)
3.プーリング(Pooling)
畳み込み処理について
入力(画像)と33~1111pxの小さいフィルタとの内積を計算する処理です。
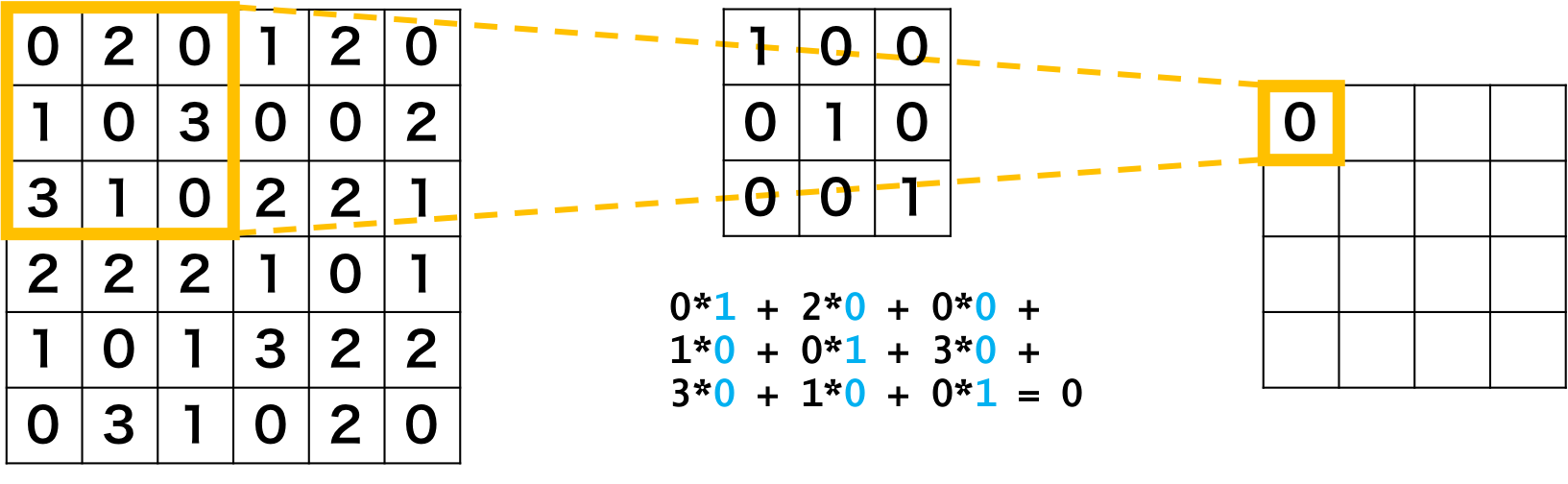
画像の引用:https://axa.biopapyrus.jp/deep-learning/cnn/convolution.html
画素の値とフィルタの値を掛け算します。
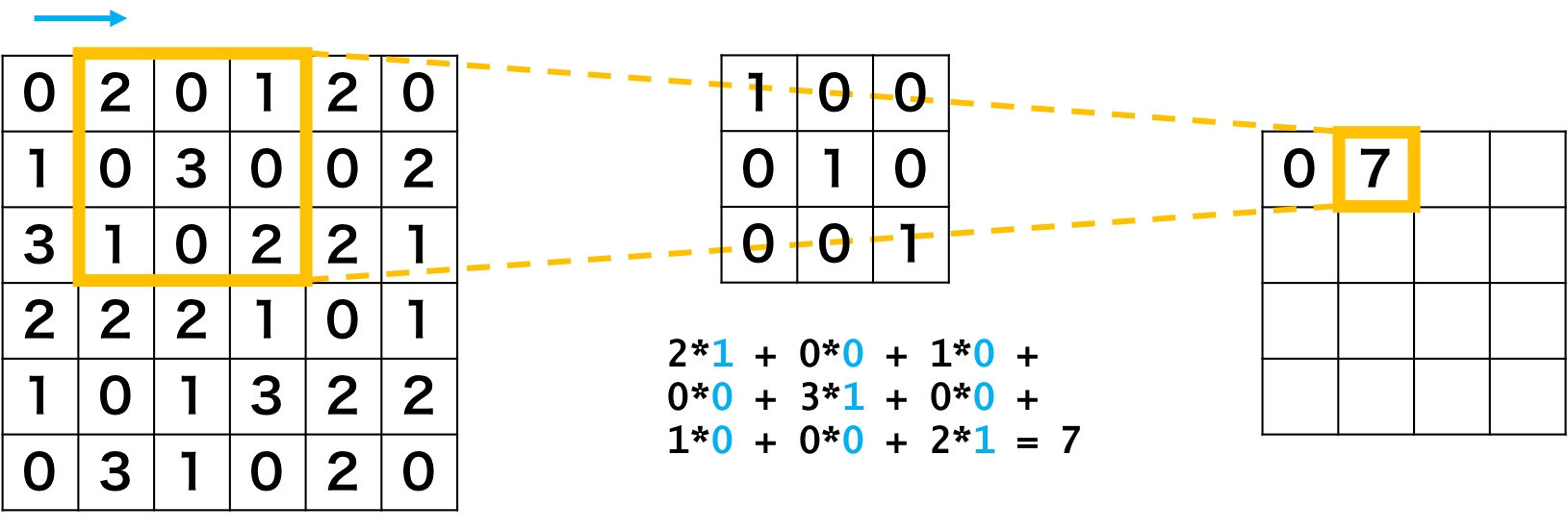
フィルタを右に一画素ずらし、同様な演算を行います。

画像の一番右に行ったら下に一画素移動し、左から再スタート。
すべての画素に行い、出力結果を得ます。
フィルタの重みは手動やBackPropagationで求めます。
代表例に
・エッジ抽出に用いられるラプラシアンフィルタ
・縦(横)線を抽出するソーベルフィルタ
などがあります。
またパラメータを大きく削減でき、高速化や汎化性能の向上が見込まれます。
例えば100100の入力を全部結合した際、10000個のパラメータが必要になりますが33のフィルタを用いれば9個のパラメータ調整で済みます。これをパラメータ共有といいます。
またのちに紹介する転移学習が楽になるメリットもあります。
プーリング(pooling)
入力の縮小処理を指します。
画像認識では広いエリアの情報が必要です。ですが畳み込み演算は局所的な演算なので、画像認識の処理とマッチしません。
そこでプーリングをし、広いエリアの情報を処理できるようにします。
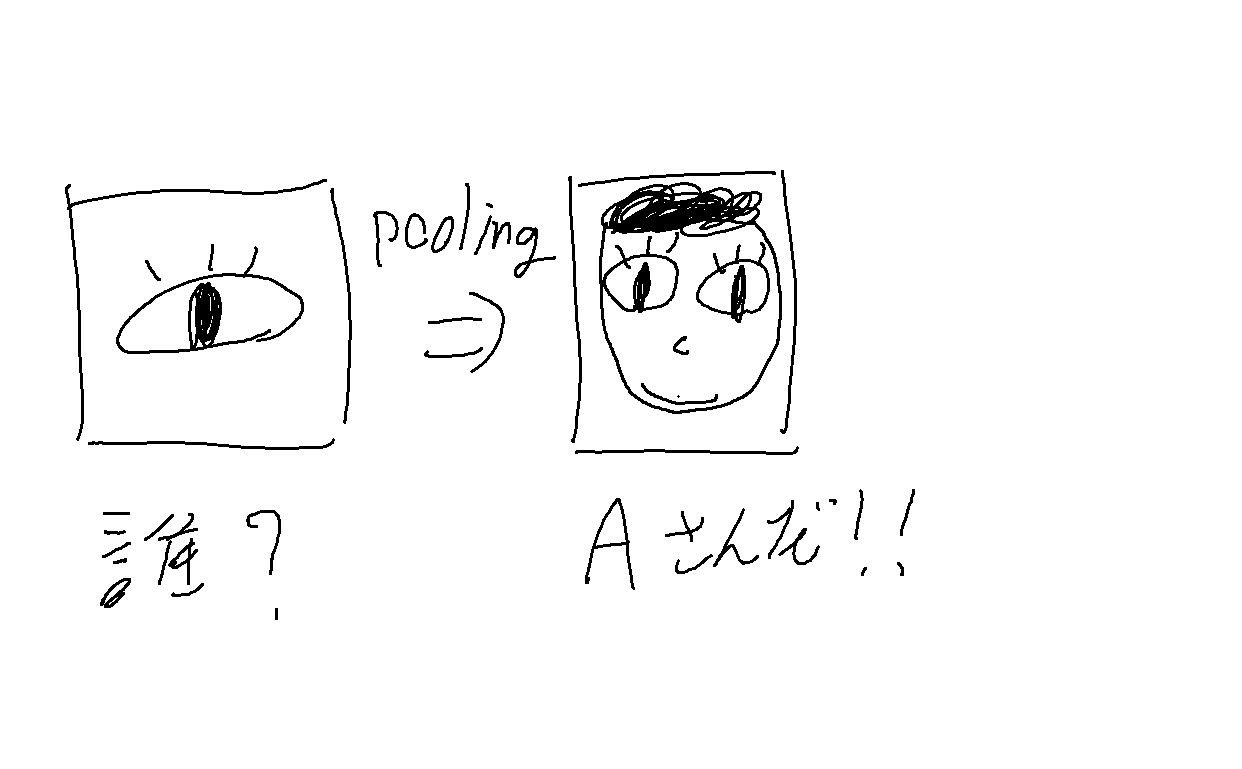 プーリングのイメージ
プーリングのイメージ
また特徴の移動にロバスト(頑強)になるという特徴もあります。
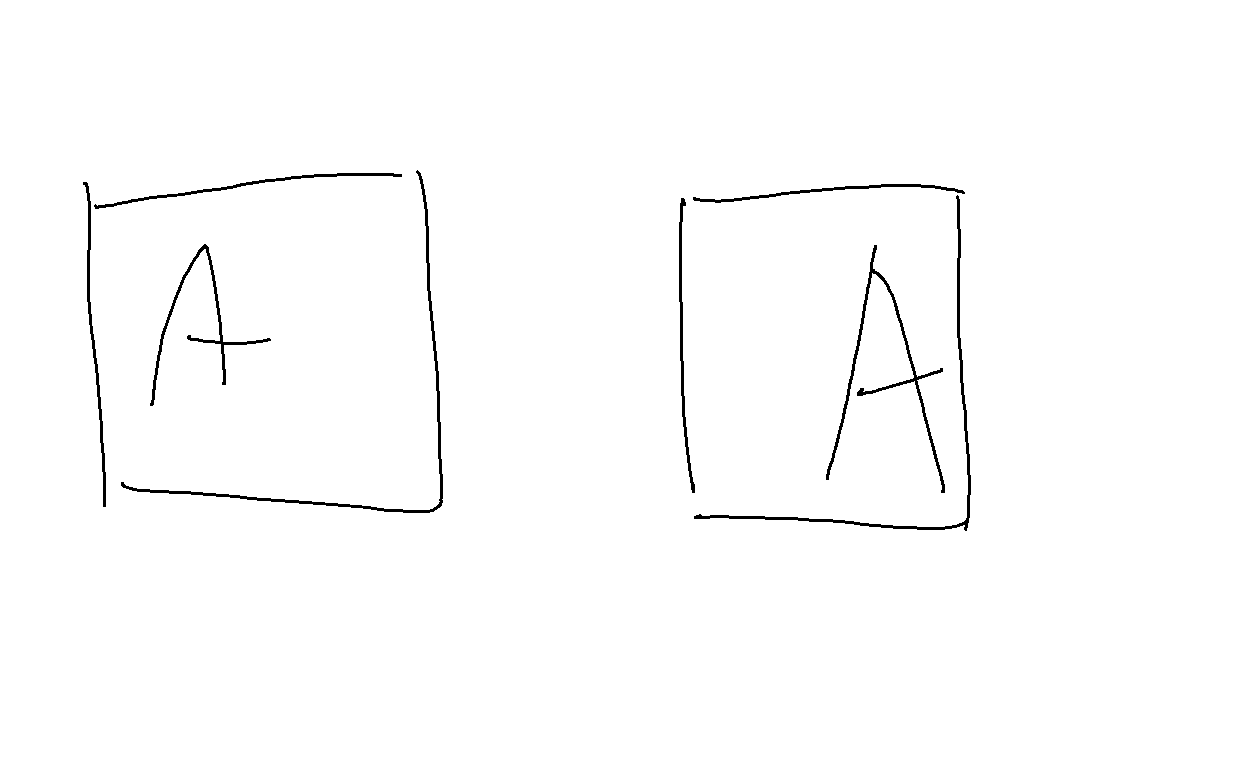
通常のCNNでは上の二枚の画像は別の出力になりますが、プーリングを施すと同じ出力結果になります。
手法をいくつかご紹介。
(画像の引用:https://www.renom.jp/ja/notebooks/tutorial/basic_algorithm/convolutional_neural_network/notebook.html)
average pooling
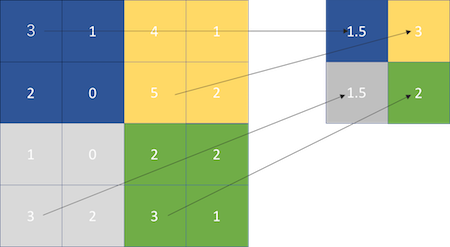
決めたエリアの平均値を出力します。
max pooling
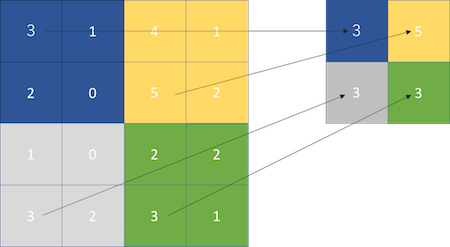
決めたエリアの最大値を出力します。
Global Average Pooling
各チャンネル(面)の画素平均を求め、まとめる手法。大きい画像を1*1pxにして処理するイメージ。
FC層(次の層のニューロンがすべてつながっている層)を削除しパラメータを大幅に減らせました。
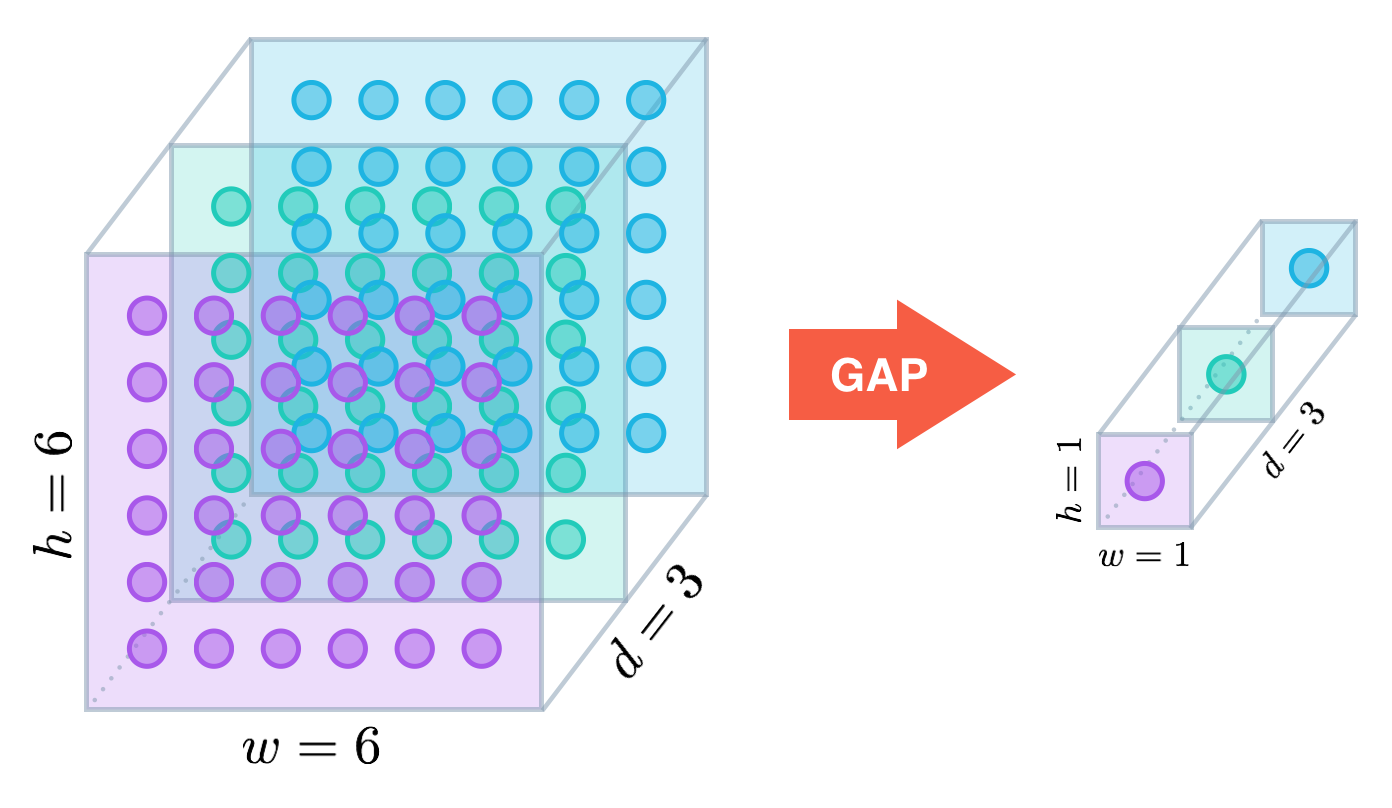
引用:https://alexisbcook.github.io/2017/global-average-pooling-layers-for-object-localization/
特殊な畳み込みの例
をご紹介。
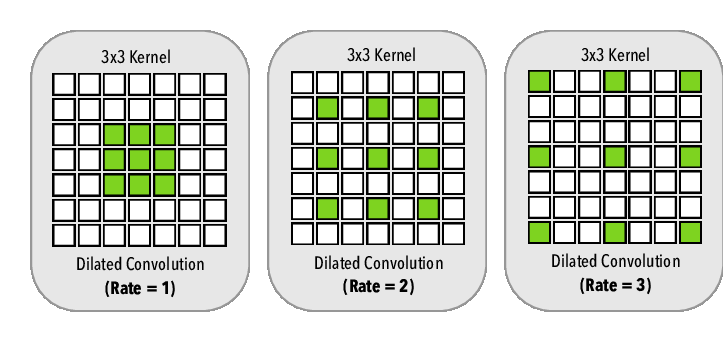
Dilated Convolution
広い範囲を処理したいときに使います。
これまでの手法を用いて広い範囲を処理したいとき、以下の問題点があります。
・フィルタサイズを大きく:サイズを2倍にするとパラメータ数が4倍になる
・層を増やす:処理範囲が線形にしか増えない
・プーリング:画素数が半分になるので回数に限界がある
下図のように畳み込む入力画像の間隔をあけて処理をし、広い範囲を畳み込みます。
Up Convolution (Deconvolution)
畳み込んだ後の画像を大きくする処理。
入力画像のピクセル間に0を埋めて拡大する処理。その後畳み込みます。
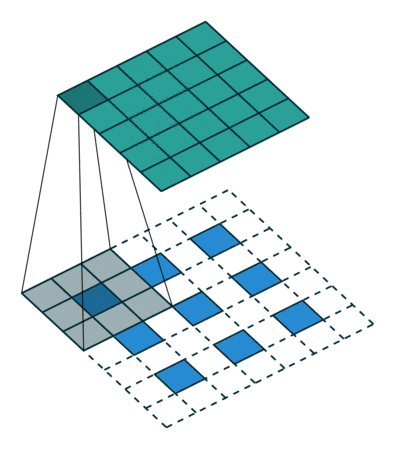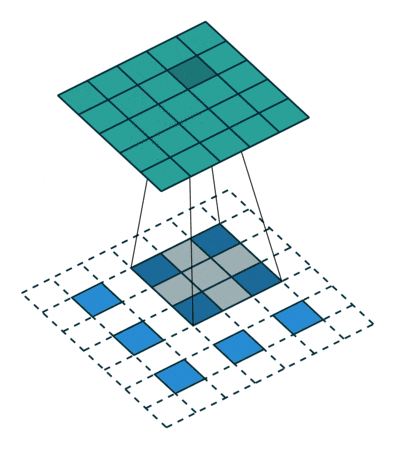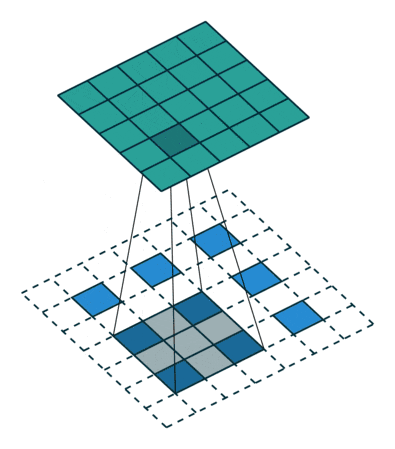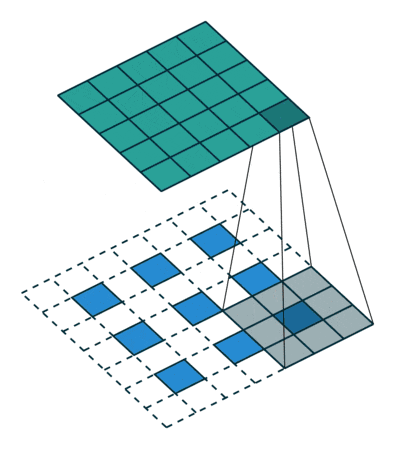
引用:https://datascience.stackexchange.com/questions/6107/what-are-deconvolutional-layers
Semantic Segmentationで用いられます。
im2col,col2img
GPUの計算に最適化した計算手法です。
画像データを一度計算しやすい行列に変換します。
下が例です。
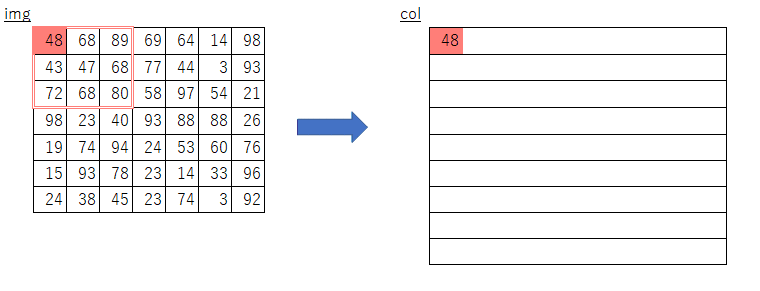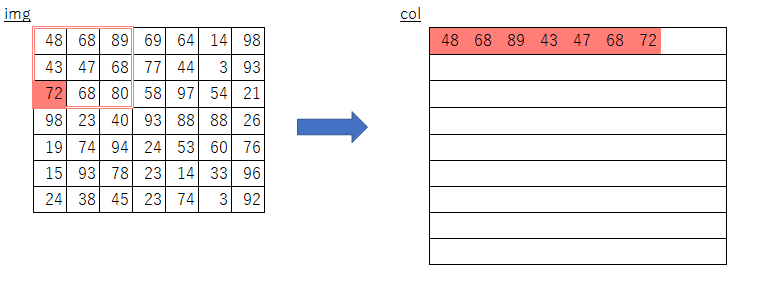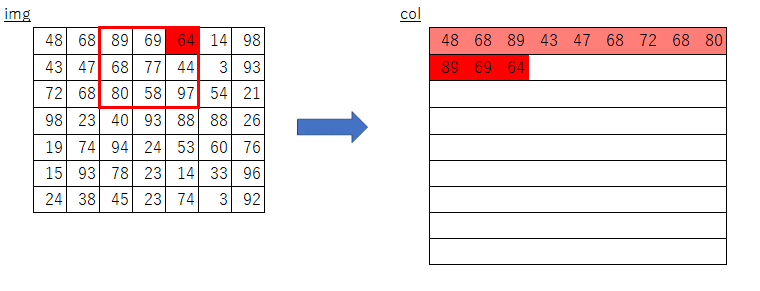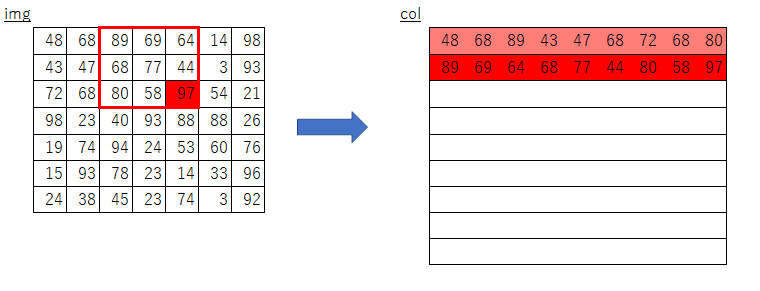
引用:https://qiita.com/kurumen-b/items/236c6255959a266cefaa
データの種類
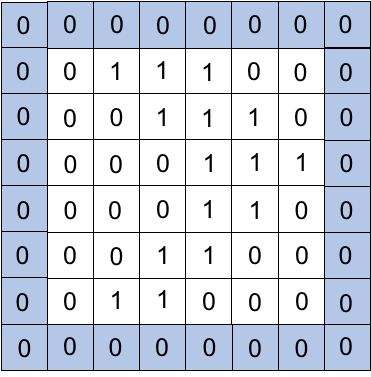
Padding(パディング)
畳み込みを繰り返すと入力が小さくなってしまいます。
そこで入力画像の周りに新たに画素を追加し、小さくなりすぎないよう処理する手法です。
例:zero padding
Filter size(カーネルサイズ)
フィルタは正方形の形をしており、一辺のサイズ(=畳み込む領域)を表しています。
だいたい一辺k=3~11ぐらいの大きさです。
Stride
画像を畳み込んだ後、入力画像に対してフィルタをずらしながら畳み込み演算をします。ずらす数をStride(ストライド)といいます。
構造出力
画像を畳み込んだ後の大きさ(px)は以下の式で表せます。
h'=\frac{(h+2p-k)}{s}+1 \\
w'=\frac{(w+2p-k)}{s}+1
h':畳み込んだ後の画像の高さ
h:畳み込む前の画像の高さ
w':畳み込んだ後の画像の横幅
w:畳み込む前の画像の横幅
k:フィルタサイズ
p:パディングのサイズ
s:ストライドの幅
パディングのサイズですが、下図の場合1のように囲った枠の数を指します。
効率的な畳み込みアルゴリズム
をここでは紹介します。
AlexNet
ILSVRCという画像分類チャレンジコンテストで優秀な成績を収めました。
のちのVGG16につながります。
VGG16
畳み込み層13層、FC層3層からなる手法。
それなりの性能が出ており、学習済みモデルは今でも使われています。
AlexNetでは
フィルタサイズが大きい:最適化が難しい
PoolingのStride(移動幅)が大きい:情報が失われる
と問題点がありました。そこでこの手法では
1.3*3の畳み込み層を何回か繰り返す
2.max poolingを一度挟んで1/2に縮小
3.pooling後チャンネル数を倍にする
と対策を取り、既存の問題を解決しました。
引用:https://hazm.at/mox/machine-learning/computer-vision/classification/keras-transfer-learning/index.html
なぜ33の畳み込み層なのかといいますと、55の畳み込み1回しているのと、3*3の畳み込みを2回して見るのでは畳み込む範囲は同じなのにパラメータ数を減らせるからからです。
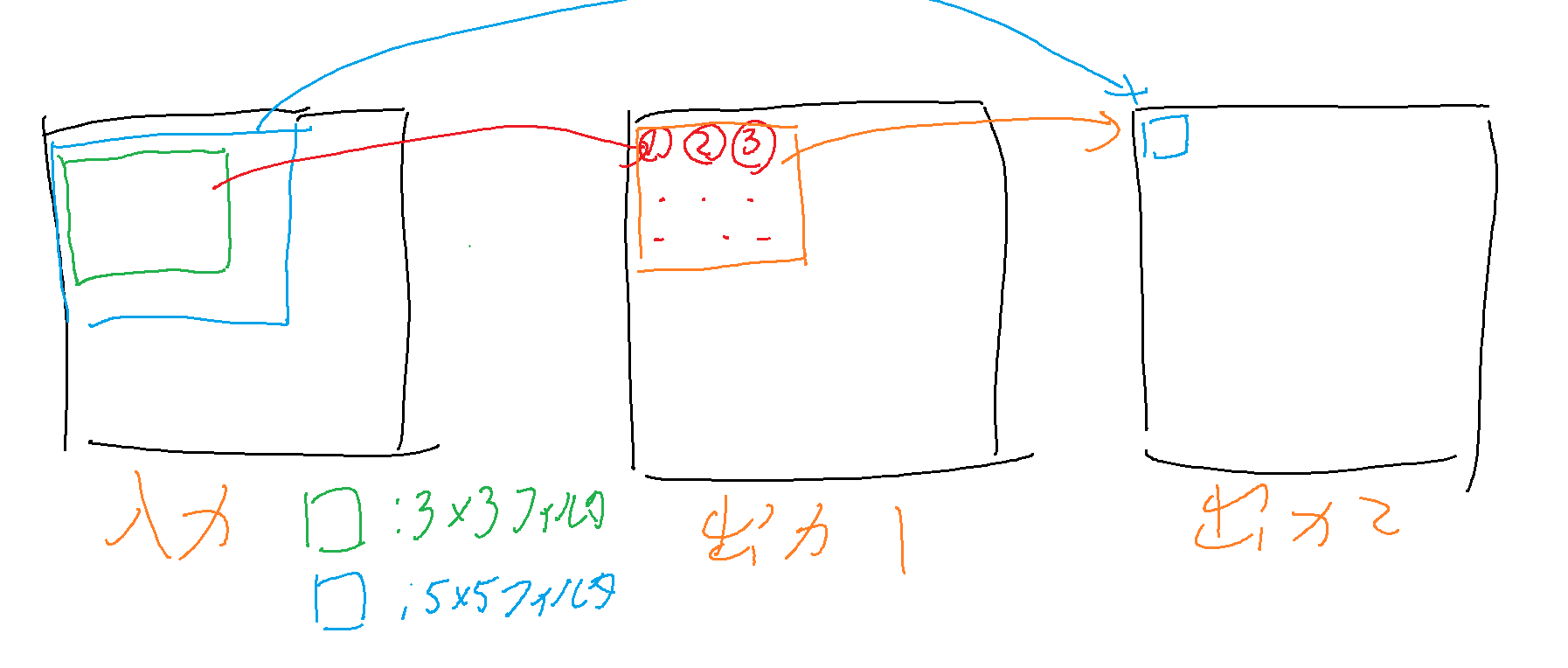
イメージ図
Google LeNet
VGG16とは逆で非常に複雑です。なので要点だけお話ししますと
・Inception モジュールを使う
・1*1の畳み込みを積極的に使う
の2つ、
Inception モジュール
どれが最適な畳み込みからわからないからそれぞれのデータに対し、ふさわしい変換を全部連結しようというのがInception モジュールです。
1*1 convolution
入力層から重要そうなチャンネルを重み付けして取り出します。
3*3に比べて1/9の計算量とパラメータででき、精度を保ったままチャンネル情報を圧縮できる効果があります。
精度を保ったまま畳み込めるので「スパースな畳み込み」ともいわれます。
オーグジュリアリ(補助)ロス
ネットワークに分岐を作り、途中から誤差伝播をさせることで誤差信号が減衰させないようにする手法です。
今はあまり使われません。
Residual Network(ResNet)
CNNといったらResNetぐらい支配的な手法。
DLは多層にすればするほど性能が上がるといわれていますが、50層以上を超えると性能が下がることが知られています。
多層にすると性能が下がる問題を解決したのがこの手法です。
Residual Block
ResNetでは何をしているかというと、入力を出力につなぐだけ。
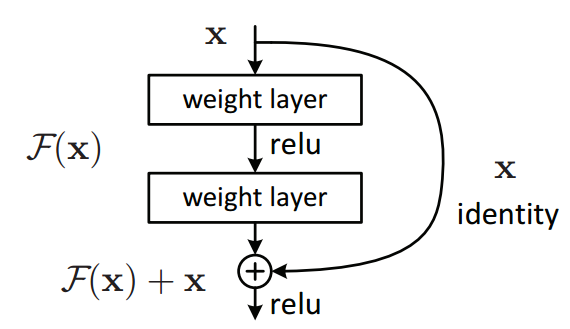
引用:https://towardsdatascience.com/residual-blocks-building-blocks-of-resnet-fd90ca15d6ec
このブロックをResidualBlockといいます。
ResNetがうまくいく理由
以下の理由があげられます。
・超多層のDNNの場合、最後の方の層はやる処理がないので恒等写像(入力をそのまま出力に流す)にしたいがDLだと学習によっての恒等写像の実装が難しい
・入力を別のパスからそのまま流せば重みを0にするだけで恒等写像になる
・誤差逆伝播法のとき入力に勾配がそのまま伝わるので勾配消失が起こりにくい
・アンサンブル効果がある(適度にレイヤーが働いている)
・実装が容易
ResNeXt
ResNet内で入力を分岐させて並列に処理する手法
分岐数をC(candinality,濃度)と呼びます。
下図の(a)(b)が例です。
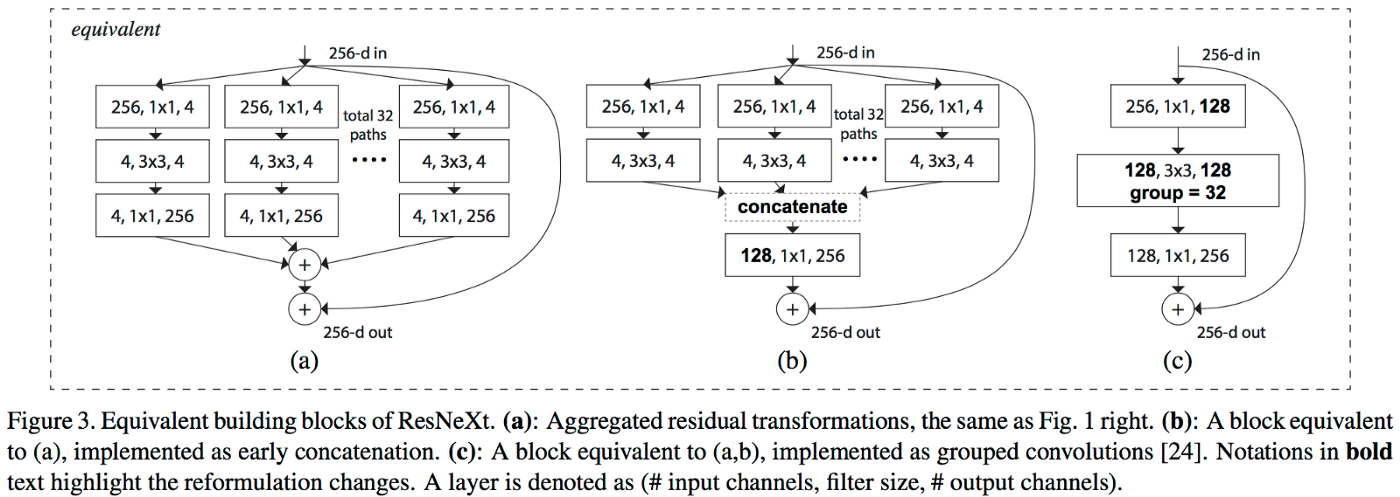
引用:https://towardsdatascience.com/residual-blocks-building-blocks-of-resnet-fd90ca15d6ec
Xception
通常の畳み込みは使わず、KKNの畳み込みを
kK1のDepthwise畳み込み
+
11Nのpointwise畳み込み
に分ける手法です。計算量が減ります。
DenseNet
とにかく精度を上げたいときに用います。
前方にあるすべてのブロックに出力を結合する手法です。
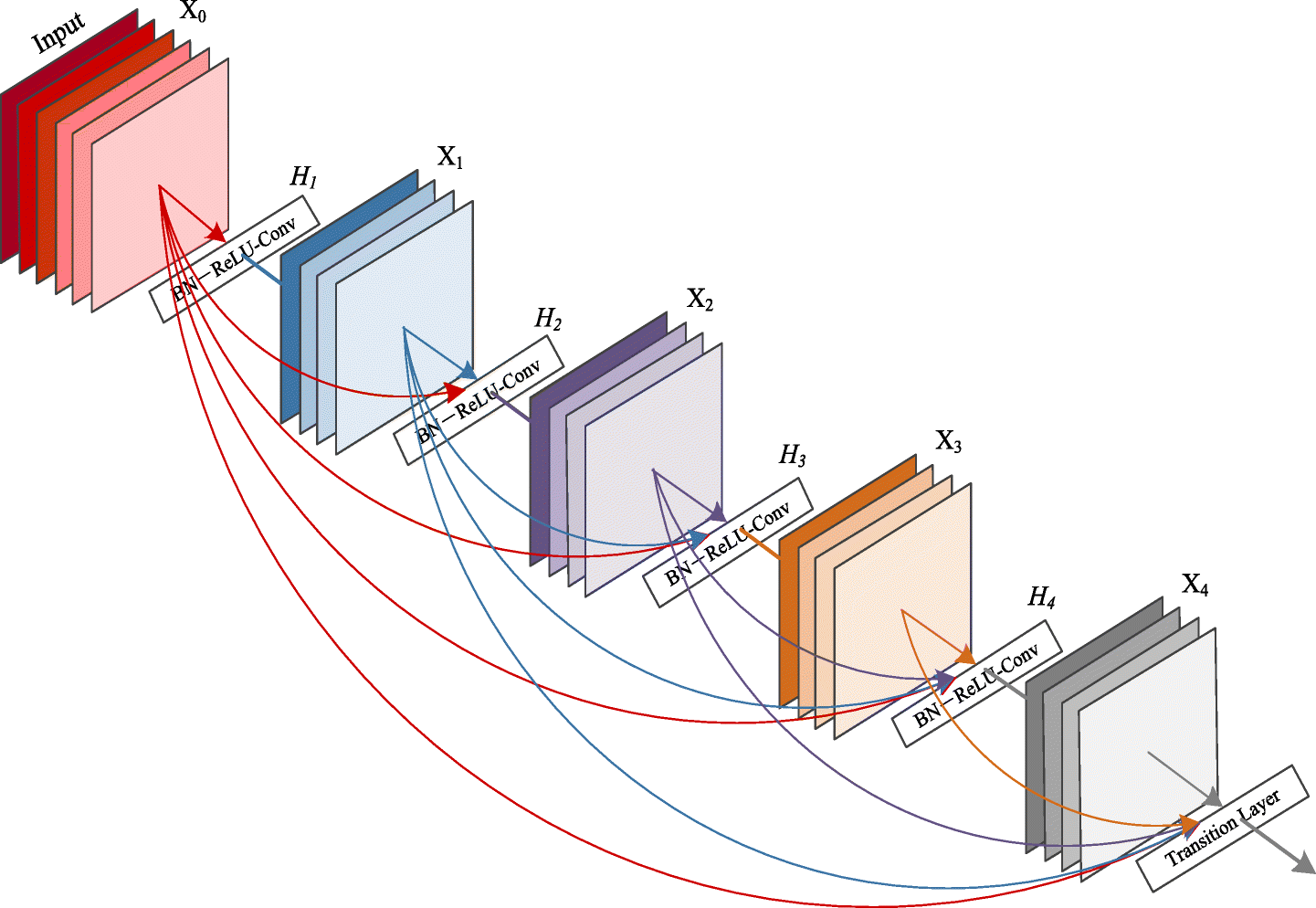
引用:https://ai-pool.com/m/densenet-1568742493
正則化
CNNではDropoutなどの正則化が効きません。そこでCNN独自の正則化を紹介します。
Stochastic Depth
Residual Block自体を確率的にDropoutする手法。
出力に近いブロックほどDropされやすくなります。
Shake-Shake Regularization
ブロックを並列に並べ、学習時は一定割合で入力を分ける手法。
BPのときは割合を変更し、テスト時は均等な割合で入力を流します。
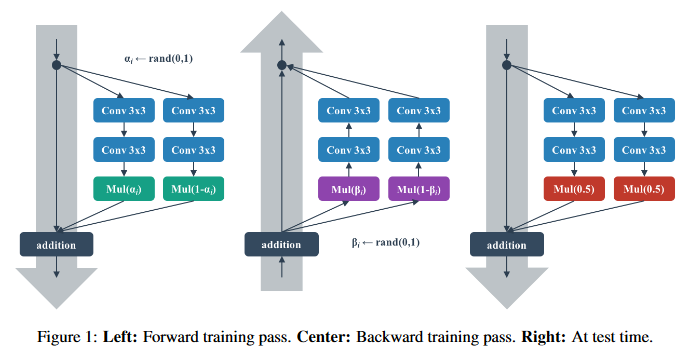
引用:https://github.com/jonnedtc/Shake-Shake-Keras
mix-up
学習時に学習データを混ぜて(例:飛行機0.4,犬0.6)学習させ、混ぜた割合も予測させる手法。
かなり強力な手法です。
CutOut&Random Eracing
Cutoutは画像の一部を平均値の色で正方形に消し、Random Eracingはランダムに画像の一部を消して学習させる手法です。
ひとまずここまで。
参考文献
https://qiita.com/mine820/items/1e49bca6d215ce88594a
http://sagantaf.hatenablog.com/entry/2019/05/26/160401#%E3%81%A9%E3%81%86%E3%83%95%E3%82%A3%E3%83%AB%E3%82%BF%E3%82%92%E9%81%A9%E7%94%A8%E3%81%97%E3%81%A6%E3%81%84%E3%81%8F%E3%81%8B%E3%82%B9%E3%83%88%E3%83%A9%E3%82%A4%E3%83%89