2回目の投稿です。
前回はPyTorchでDCGANの実装を行うとともに出力画像を1枚ずつ保存できるようにしました。
今回はGANの出力を制御できるように改良したconditional GAN(条件付きGAN)の実装を行なっていきます。それと同時に前回同様、出力画像を1枚ずづ保存できるようにしていきます。
目的
conditional GANの実装を行い、出力を1枚ずつ保存する
conditional GAN
conditional GANは生成する画像を明示的に分けられるようにしたものです。訓練時に教師データのラベル情報も用いて訓練することでこれを可能にしました。
論文はこちら
以下論文より
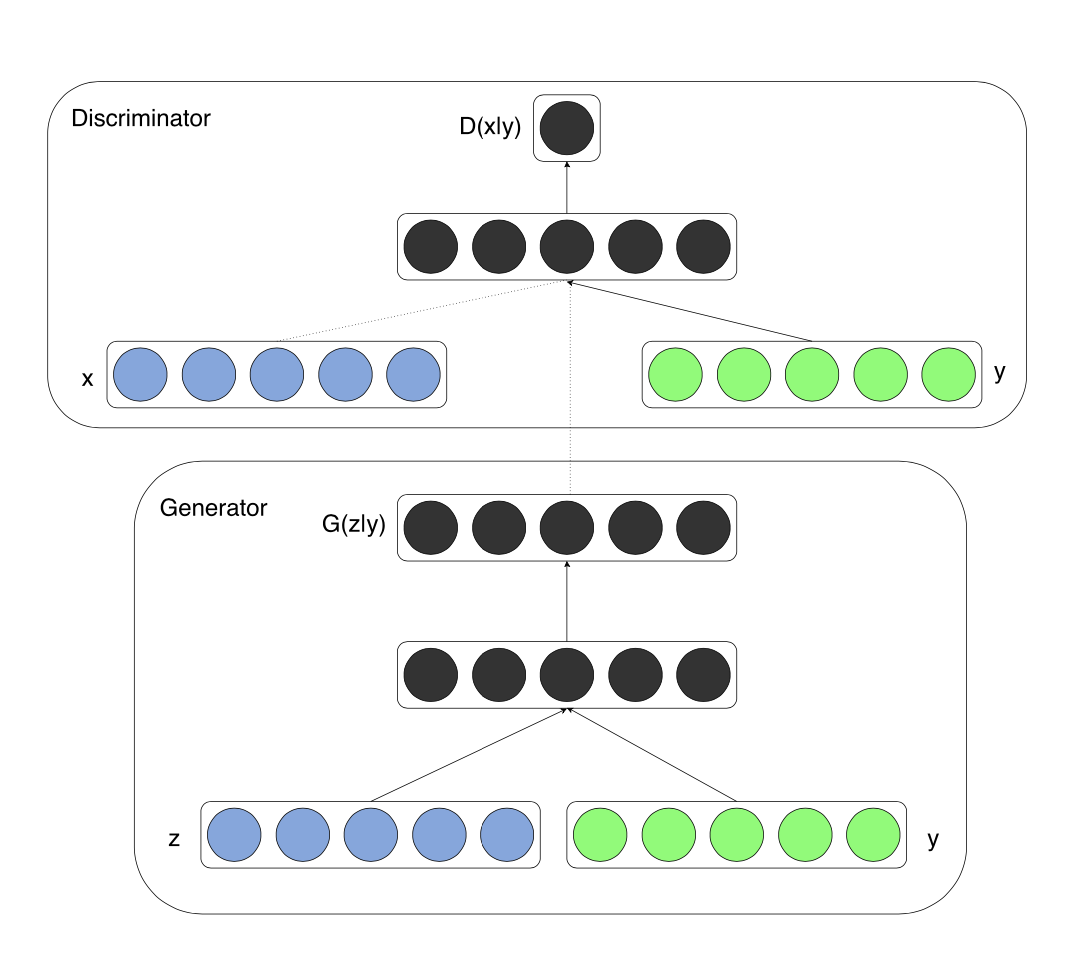
GeneratorとDiscriminatorの両方の入力にクラスラベルの情報を追加して学習を行う感じです。入力の形式が少し変わる感じですがGANの基本的な構造としては変わらないです。
実装
実装に移っていきます。今回は前回実装したDCGANをベースとしたconditional GANの実装をしていきます。
実行環境
Google Colaboratory
モジュールのインポート&保存先の設定
まずはモジュールのインポートから
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
import torch.nn as nn
import torch.nn.functional as F
import torch
img_save_path = 'images-C_dcgan'
os.makedirs(img_save_path, exist_ok=True)
コマンドライン&デフォルト値の設定
前回とほぼ同じです。
微妙な変更点としては、生成する画像サイズがMNISTデフォルトの28×28ではなく32×32になっています。
parser = argparse.ArgumentParser()
parser.add_argument('--n_epochs', type=int, default=200, help='number of epochs of training')
parser.add_argument('--batch_size', type=int, default=64, help='size of the batches')
parser.add_argument('--lr', type=float, default=0.0002, help='adam: learning rate')
parser.add_argument('--beta1', type=float, default=0.5, help='adam: decay of first order momentum of gradient')
parser.add_argument('--beta2', type=float, default=0.999, help='adam: decay of second order momentum of gradient')
parser.add_argument('--n_cpu', type=int, default=8, help='number of cpu threads to use during batch generation')
parser.add_argument('--latent_dim', type=int, default=100, help='dimensionality of the latent space')
parser.add_argument('--n_classes', type=int, default=10, help='number of classes for dataset')
parser.add_argument('--img_size', type=int, default=32, help='size of each image dimension')
parser.add_argument('--channels', type=int, default=1, help='number of image channels')
parser.add_argument('--sample_interval', type=int, default=400, help='interval between image sampling')
args = parser.parse_args()
#google colabの場合は args=parser.parse_args(args=[])
print(args)
C,H,W = args.channels, args.img_size, args.img_size
重みの設定
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
torch.nn.init.normal(m.weight, 0.0, 0.02)
elif classname.find('BatchNorm2d') != -1:
torch.nn.init.normal(m.weight, 1.0, 0.02)
torch.nn.init.constant(m.bias, 0.0)
Generator
Generatorの定義をしていきます。catで生成画像の情報とラベルの情報をくっつけて生成します。
class Generator(nn.Module):
# initializers
def __init__(self, d=128):
super(Generator, self).__init__()
self.deconv1_1 = nn.ConvTranspose2d(100, d*2, 4, 1, 0)
self.deconv1_1_bn = nn.BatchNorm2d(d*2)
self.deconv1_2 = nn.ConvTranspose2d(10, d*2, 4, 1, 0)
self.deconv1_2_bn = nn.BatchNorm2d(d*2)
self.deconv2 = nn.ConvTranspose2d(d*4, d*2, 4, 2, 1)
self.deconv2_bn = nn.BatchNorm2d(d*2)
self.deconv3 = nn.ConvTranspose2d(d*2, d, 4, 2, 1)
self.deconv3_bn = nn.BatchNorm2d(d)
self.deconv4 = nn.ConvTranspose2d(d, C, 4, 2, 1)
# forward method
def forward(self, input, label):
x = F.relu(self.deconv1_1_bn(self.deconv1_1(input)))
y = F.relu(self.deconv1_2_bn(self.deconv1_2(label)))
x = torch.cat([x, y], 1)
x = F.relu(self.deconv2_bn(self.deconv2(x)))
x = F.relu(self.deconv3_bn(self.deconv3(x)))
x = torch.tanh(self.deconv4(x))
return x
前回はUpsampling+Conv2dでGeneratorを実装しました。今回は前回の方法ではなく、ConvTranspose2dを利用して実装を行っています。この違いについてはこちらの記事にまとめられているので気になる方はご覧ください。
Discriminator
Discriminatorの定義です。こちらもcatでラベル情報をくっつけています。
class Discriminator(nn.Module):
# initializers
def __init__(self, d=128):
super(Discriminator, self).__init__()
self.conv1_1 = nn.Conv2d(C, d//2, 4, 2, 1)
self.conv1_2 = nn.Conv2d(10, d//2, 4, 2, 1)
self.conv2 = nn.Conv2d(d, d*2, 4, 2, 1)
self.conv2_bn = nn.BatchNorm2d(d*2)
self.conv3 = nn.Conv2d(d*2, d*4, 4, 2, 1)
self.conv3_bn = nn.BatchNorm2d(d*4)
self.conv4 = nn.Conv2d(d * 4, 1, 4, 1, 0)
def forward(self, input, label):
x = F.leaky_relu(self.conv1_1(input), 0.2)
y = F.leaky_relu(self.conv1_2(label), 0.2)
x = torch.cat([x, y], 1)
x = F.leaky_relu(self.conv2_bn(self.conv2(x)), 0.2)
x = F.leaky_relu(self.conv3_bn(self.conv3(x)), 0.2)
x = F.sigmoid(self.conv4(x))
return x
Loss関数やネットワークの設定
Loss関数の定義や、重みの初期化、Generator・Discriminatorの初期化、Optimizerの設定を行います
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize Generator and discriminator
generator = Generator()
discriminator = Discriminator()
if torch.cuda.is_available():
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=args.lr, betas=(args.beta1, args.beta2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=args.lr, betas=(args.beta1, args.beta2))
Dataloaderの作成
Dataloaderを作成していきます。今回は32*32の大きさで画像を生成するので、画像の前処理の部分でMNISTの画像をリサイズしています。
# Configure data loader
os.makedirs('./data', exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.Resize(args.img_size),
transforms.ToTensor(),
transforms.Normalize([0.5,], [0.5,])
])),
batch_size=args.batch_size, shuffle=True, drop_last=True)
print('the data is ok')
Training
GANのTrainingです。
for epoch in range(1, args.n_epochs+1):
for i, (imgs, labels) in enumerate(dataloader):
Batch_Size = args.batch_size
N_Class = args.n_classes
img_size = args.img_size
# Adversarial ground truths
valid = torch.ones(Batch_Size).cuda()
fake = torch.zeros(Batch_Size).cuda()
# Configure input
real_imgs = imgs.type(torch.FloatTensor).cuda()
real_y = torch.zeros(Batch_Size, N_Class)
real_y = real_y.scatter_(1, labels.view(Batch_Size, 1), 1).view(Batch_Size, N_Class, 1, 1).contiguous()
real_y = real_y.expand(-1, -1, img_size, img_size).cuda()
# Sample noise and labels as generator input
noise = torch.randn((Batch_Size, args.latent_dim,1,1)).cuda()
gen_labels = (torch.rand(Batch_Size, 1) * N_Class).type(torch.LongTensor)
gen_y = torch.zeros(Batch_Size, N_Class)
gen_y = gen_y.scatter_(1, gen_labels.view(Batch_Size, 1), 1).view(Batch_Size, N_Class,1,1).cuda()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Loss for real images
d_real_loss = adversarial_loss(discriminator(real_imgs, real_y).squeeze(), valid)
# Loss for fake images
gen_imgs = generator(noise, gen_y)
gen_y_for_D = gen_y.view(Batch_Size, N_Class, 1, 1).contiguous().expand(-1, -1, img_size, img_size)
d_fake_loss = adversarial_loss(discriminator(gen_imgs.detach(),gen_y_for_D).squeeze(), fake)
# Total discriminator loss
d_loss = (d_real_loss + d_fake_loss)
d_loss.backward()
optimizer_D.step()
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
g_loss = adversarial_loss(discriminator(gen_imgs,gen_y_for_D).squeeze(), valid)
g_loss.backward()
optimizer_G.step()
print ("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, args.n_epochs, i, len(dataloader),
d_loss.data.cpu(), g_loss.data.cpu()))
batches_done = epoch * len(dataloader) + i
if epoch % 20 == 0:
noise = torch.FloatTensor(np.random.normal(0, 1, (N_Class**2, args.latent_dim,1,1))).cuda()
#fixed labels
y_ = torch.LongTensor(np.array([num for num in range(N_Class)])).view(N_Class,1).expand(-1,N_Class).contiguous()
y_fixed = torch.zeros(N_Class**2, N_Class)
y_fixed = y_fixed.scatter_(1,y_.view(N_Class**2,1),1).view(N_Class**2, N_Class,1,1).cuda()
with torch.no_grad():
gen_imgs = generator(noise, y_fixed).view(-1,C,H,W)
save_image(gen_imgs.data, img_save_path + '/epoch:%d.png' % epoch, nrow=N_Class, normalize=True)
実行結果
実行結果は以下のようになります。

生成画像がクラスごとに綺麗に並んでいるのがわかります。conditional GANではこのように生成する画像を制御することができます。
クラス毎に画像を生成して保存する
前回同様、こちらも1枚ずつ画像を保存できるようにしていきます。
if epoch % 20 == 0:
noise = torch.FloatTensor(np.random.normal(0, 1, (N_Class**2, args.latent_dim,1,1))).cuda()
#fixed labels
y_ = torch.LongTensor(np.array([num for num in range(N_Class)])).view(N_Class,1).expand(-1,N_Class).contiguous()
y_fixed = torch.zeros(N_Class**2, N_Class)
y_fixed = y_fixed.scatter_(1,y_.view(N_Class**2,1),1).view(N_Class**2, N_Class,1,1).cuda()
with torch.no_grad():
gen_imgs = generator(noise, y_fixed).view(-1,C,H,W)
save_image(gen_imgs.data, img_save_path + '/epoch:%d.png' % epoch, nrow=N_Class, normalize=True)
ここの部分を
if epoch % 20 == 0:
for l in range(10): #各クラス10枚ずつ保存する
noise = torch.FloatTensor(np.random.normal(0, 1, (N_Class**2, args.latent_dim,1,1))).cuda()
#fixed labels
y_ = torch.LongTensor(np.array([num for num in range(N_Class)])).view(N_Class,1).expand(-1,N_Class).contiguous()
y_fixed = torch.zeros(N_Class**2, N_Class)
y_fixed = y_fixed.scatter_(1,y_.view(N_Class**2,1),1).view(N_Class**2, N_Class,1,1).cuda()
for m in range()
with torch.no_grad():
gen_imgs = generator(noise, y_fixed).view(-1,C,H,W)
save_gen_imgs = gen_imgs[10*i]
save_image(save_gen_imgs, img_save_path + '/epochs:%d/%d/epoch:%d-%d_%d.png' % (epoch, i, epoch,i, j), normalize=True)
このように変更します。なおこのようにする場合は画像を保存するディレクトリ構造を変えておく必要があります。
images-C_dcgan
├── epochs:20
│ ├── 0
│ ├── 1
│ ├── 2
│ ├── 3
│ ├── 4
│ ├── 5
│ ├── 6
│ ├── 7
│ ├── 8
│ └── 9
│ .
│ .
│ .
│
└── epochs:200
├── 0
├── 1
├── 2
├── 3
├── 4
├── 5
├── 6
├── 7
├── 8
└── 9
20エポック毎に0~9のディレクトリがある状態です。os.makedirsを使って一気に作成すると楽ですね。これで各クラス毎に画像が保存されるようになりました。
まとめ
今回はDCGANに引き続きconditional GANを実装し、生成画像を1枚ずつ保存できるようにしました。今回は1番簡単な、GeneratorとDiscriminatorの両方の入力にラベル情報を付与する形でconditional GANを実装していきました。今現在、conditional GANを実装する上でデファクトスタンダードとなっているのは、Projection DiscriminatorやConditional Batch Normalizationといった技術です。ここら辺の技術はまだあまり理解していないので機会があれば実装しながら勉強していきたいと思います。