卒業研究でGANを扱う中で、GANの生成する画像を1枚ずつ保存する必要が出てきました。
しかし、調べても調べてもGANの実装をしている記事はどれもこんな感じの出力ばかり…

このような複数枚まとめての出力ではなく、これらが1枚ずつ出力されるようにしました。
備忘録も兼ねて記しておきます。
目的
GANの実装を行う&GANの生成画像を1枚ずつ保存する
GAN
GAN(Generative Adversarial Network):敵対的生成ネットワークはIan J. Goodfellow氏が提案した生成モデルです。
Generative Adversarial Nets
GANの基本構造はこんな感じ
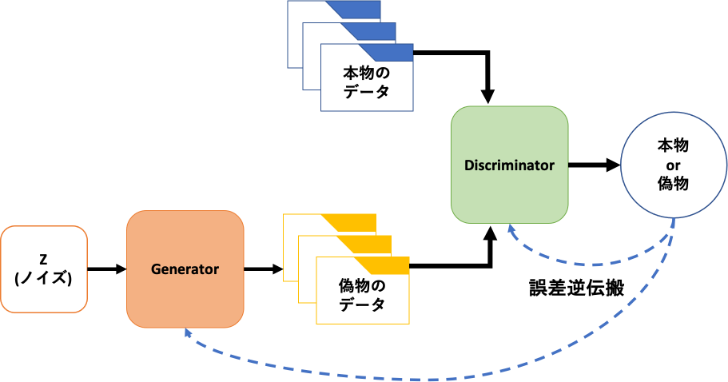
2つのネットワークを有していて、お互いに競い合いながら学習を進めていきます。
Generator:生成器 は Discriminator:判別器 を騙せるような画像を生成し、Discriminator は本物の画像か偽物の画像かを判別していきます。
GANを一躍有名にしたDCGANや驚くほどリアルな画像を生成するStyleGANなど様々なアーキテクチャが提案されています。
GANの実装
それではGANの実装に移っていきます。今回は先ほどのDCGANの実装を行っていきます。
実装の参考にしたコードはこちら
実行環境
Google Colaboratory
import&ディレクトリ作成
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
import torch.nn as nn
import torch
os.makedirs("./images", exist_ok=True)
必要なモジュールをインポートしていきます。今回はPyTorchで実装を行っていきます。
GANの出力画像を保存するディレクトリも作成します。exist_ok=Trueとなっているので、既にディレクトリが存在する場合はスルーされます。
コマンドライン引数&デフォルト値の設定
コマンドラインでepoch数やバッチサイズなどの値を指定できるようにします。同時にデフォルトの値も設定します。
epoch数やバッチサイズなどについてはこちらの記事がわかりやすいと思います。
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
コマンドラインを使用できる環境ならこのままでいいのですが、Google Colaboratoryで実装を行う場合は以下のようなエラーが発生してしまいます。
usage: ipykernel_launcher.py [-h] [--n_epochs N_EPOCHS]
[--batch_size BATCH_SIZE] [--lr LR] [--b1 B1]
[--b2 B2] [--n_cpu N_CPU]
[--latent_dim LATENT_DIM] [--img_size IMG_SIZE]
[--channels CHANNELS]
[--sample_interval SAMPLE_INTERVAL]
ipykernel_launcher.py: error: unrecognized arguments: -f /root/.local/share/jupyter/runtime/kernel-ecf689bc-740f-4dea-8913-e0d8ac0b1761.json
An exception has occurred, use %tb to see the full traceback.
SystemExit: 2
/usr/local/lib/python3.6/dist-packages/IPython/core/interactiveshell.py:2890: UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)
Google Colabではopt = parser.parse_args()の行をopt = parser.parse_args(args=[])としてあげると無事通ります。
CUDAの設定と重みの初期化
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
GPUを使用しないと学習に相当時間かかってしまうのでCUDA(GPU)を使用できるようにします。Google Colabではランタイムの設定をGPUに変更するのを忘れないでください。
Generator
Geberator:生成器のネットワークを定義します。
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
Discriminator
Discriminator:判別器のネットワークを定義します。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
損失関数の設定とネットワーク周りの設定
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
DataLoaderの作成
DataLoaderを作成していきます。今回はMNISTデータセットを用いて画像生成を行います。
MNIST:手書き数字の画像データセット
# Configure data loader
os.makedirs("./data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST("./data/mnist",train=True,download=True,
transform=transforms.Compose([
transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),batch_size=opt.batch_size,shuffle=True,
)
Training
いざGANのTrainingを行っていきます。
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Tensor(imgs.shape[0], 1).fill_(1.0)
fake = Tensor(imgs.shape[0], 1).fill_(0.0)
# Configure input
real_imgs = imgs.type(Tensor)
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
実行結果
一定間隔で結果が保存されるので実行結果をGIF画像で見ていきます。

人が見てもきちんとわかる数字たちが生成されています。
画像を1枚ずつ保存したい
こんな人なかなかいないと思うのですが、調べてもなかなか出てこなかったので共有します。
上記のTrainingの部分にあった
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
この部分を以下のように変更すれば1枚ずつ保存できます。
if batches_done % opt.sample_interval == 0:
save_gen_img = gen_img[0]
save_image(save_gen_imgs, "images/%d.png" % batches_done, normalize=True)
1枚ずつ複数枚保存したい場合はfor文でも使って欲しい枚数文save_imageを繰り返せば大丈夫だと思います。訓練時間はグッと増えますが
これで最初の目的であったGANの出力を1枚づつ保存することを達成しました。
まとめ
今回はPyTorchでDCGANの実装を行うとともに、GANの出力を1枚ずつ保存できるようにし、実際に手書きの数字が生成されていることを確認できました。
次はGANの出力を制御できるconditional GAN(cGAN)について書いていこうと思います。cGANも同様にクラスごとに1枚ずつ画像が保存できるようにしていきます。