こちらの勉強会は、本形式にまとめています。
https://zenn.dev/mandenaren/books/algorithm-study
はじめに
新卒エンジニア同士で実施している勉強会の第 5 回目の記事になります。
今回のテーマは連想配列についてです。
| 回 | テーマ |
|---|---|
| 第 1 回 | 二分探索 |
| 第 2 回 | ソートアルゴリズム |
| 第 3 回 | 暗号化 |
| 第 4 回 | bit 演算 |
| 第 5 回 | 連想配列 |
| 第 6 回 | グラフ理論 |
前提
連想配列とは、キーバリュー型のデータ構造のことを指します。Python で言うと辞書型のデータ構造のことです。
dict_person = {'name' : 'tanaka', 'age' : 25, 'email' : 'a@gmail.com'}
これは値に対して一意のキーを割り当てたデータ構造であり、dict_person['age']のように任意のキー名の値を取り出すことができます。連想配列はデータに名前を付けて扱いやすくできるメリットがありますが、実は内部的に O(1)の計算量で情報を取得することができるメリットもあります。通常の配列データから任意の値を取得する場合は検索するために全探索や二分探索といった操作が必要となり計算量が発生します。連動配列はハッシュ関数を内部的に使用することで検索せずとも一発で欲しい情報を取り出すことができるのです。
ハッシュ関数とは、なんらかのデータの集合を重複のない数字に変換する関数です。連想配列の場合、キー集合に対してハッシュ関数を実行します。そして変換された数字を、配列のインデックスとして利用することで一発で欲しい情報のアドレスを GET できるというわけです。
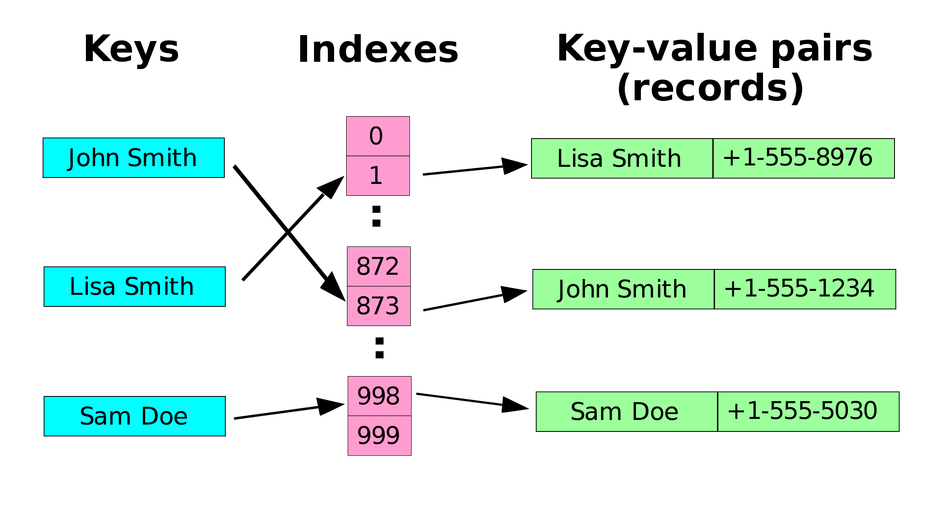
問題 1
ハッシュ関数には様々な実装方法がありますが、まずは簡単なハッシュ関数を作りましょう。
テストケースの 3 つのデータを、長さ 8 の配列に格納することを考えます。データをどの index に格納するか決めるためのハッシュ関数を作ります。以下の対応表をもとに、input の各アルファベットを数字に変換して、和をとってください。この数字(ハッシュ値)を、さらに 8 で割ったあまりを出力してください。これが格納先の index になります。
{
"A": 1,
"B": 2,
"C": 3,
"D": 4,
"E": 5,
"F": 6,
"G": 7,
"H": 8,
"I": 9,
"J": 10,
"K": 11,
"L": 12,
"M": 13,
"N": 14,
"O": 15,
"P": 16,
"Q": 17,
"R": 18,
"S": 19,
"T": 20,
"U": 21,
"V": 22,
"W": 23,
"X": 24,
"Y": 25,
"Z": 26
}
なお、以下の条件に従ってください。
- 組み込みメソッドは使わないこと。つまり、分岐、繰り返し処理を自分で書くこと。
- Array.find などは使わない
- 解法を調べるために chatgpt、インターネットは使用しないこと
- 文法を調べることのみ可
- 計算量は問いません
テストケース
SATO
7
TANAKA
0
WATANABE
3
コマンドラインからの入力を受け取る方法
# 入力
name = str(input())
解答例
クリックすると解答例が見られます
# 入力
name = str(input())
mapping = {
"A": 1,
"B": 2,
"C": 3,
"D": 4,
"E": 5,
"F": 6,
"G": 7,
"H": 8,
"I": 9,
"J": 10,
"K": 11,
"L": 12,
"M": 13,
"N": 14,
"O": 15,
"P": 16,
"Q": 17,
"R": 18,
"S": 19,
"T": 20,
"U": 21,
"V": 22,
"W": 23,
"X": 24,
"Y": 25,
"Z": 26
}
sum = 0
for char in name:
sum += mapping[char]
index = sum % 8
print(index)
繰り返し処理を用いて文字列から文字を一つずつ取り出し、対応する数字を加算していきます。合計値を 8 で割った余りを出力します。
三つのテストケースの場合、たまたま 8 で割った余りを求めるアルゴリズムを使えば 7, 0, 3 のように重複のない数字に変換することができました。
問題 2
問題 1 で作ったハッシュ関数を使って、以下のような首都の連想配列を自作します。
capital = {
"JAPAN": "Tokyo",
"USA": "Washington D.C.",
"SPAIN": "Madrid"
}
手順は以下です。
- 長さ 8 の配列を初期化する
- 値を代入するメソッド set を作成する
a. key と value を引数にとる
b. key を問題 1 で作成した hash 関数にかけて、index に変換する
c. index を指定して配列へ値を代入する - 値を取得するメソッド get を作成する
a. key を引数にとる
b. key を同じく hash 関数にかけて index を得る
c. index を指定して配列から値を取得する
なお、以下の条件に従ってください。
- 組み込みメソッドは使わないこと。つまり、分岐、繰り返し処理を自分で書くこと。
- Array.find などは使わない
- 解法を調べるために chatgpt、インターネットは使用しないこと
- 文法を調べることのみ可
- 計算量は問いません
テストケース
まずは以下を実行して値を代入してください。
set("JAPAN", "Tokyo")
set("USA", "Washington D.C.")
set("SPAIN", "Madrid")
その後、get 関数を実行して値を取得できることを確認しましょう。
get("JAPAN")
get("USA")
get("SPAIN")
Tokyo
Washington D.C.
Madrid
コードの最後に以下のメソッドを実行します。
set("JAPAN", "Tokyo")
set("USA", "Washington D.C.")
set("SPAIN", "Madrid")
get("JAPAN")
get("USA")
get("SPAIN")
解答例
クリックすると解答例が見られます
array = [0] * 8
mapping = {
"A": 1,
"B": 2,
"C": 3,
"D": 4,
"E": 5,
"F": 6,
"G": 7,
"H": 8,
"I": 9,
"J": 10,
"K": 11,
"L": 12,
"M": 13,
"N": 14,
"O": 15,
"P": 16,
"Q": 17,
"R": 18,
"S": 19,
"T": 20,
"U": 21,
"V": 22,
"W": 23,
"X": 24,
"Y": 25,
"Z": 26
}
def hash(key):
sum = 0
for char in key:
sum += mapping[char]
index = sum % 8
return index
def set(key, value):
index = hash(key)
array[index] = value
def get(key):
index = hash(key)
print(array[index])
set("JAPAN", "Tokyo")
set("USA", "Washington D.C.")
set("SPAIN", "Madrid")
get("JAPAN")
get("USA")
get("SPAIN")
指示通りに set, get 関数を実装し、出力結果も無事各首都を出力することができました。ちなみに今回のテストケースではarray = [0, 'Washington D.C.', 'Tokyo', 'Madrid', 0, 0, 0, 0]となります。キー名にハッシュ関数を実行し、キー名に対応する数字に変換します。この数字は 0~7 の間を取りますが、今回はたまたま重複がありませんでした。そのため、配列の index として利用できるようになり、O(1)の計算量、つまり一発で値を取り出すことができたというわけです。
問題 2 では、たまたま重複がないケースで連想配列を作成することができました。しかし、世の中のデータの集合を一発で任意の数字に変換できるメソッドには限界があります。
例えば、問題 2 のデータにドイツのケースを追加してみましょう。
set("GERMANY", "Berlin")
この Index は 3 になるので Madrid と重複してしまいます。問題 2 のままでは後に set されるデータに上書きされてしまうので、get("SPAIN")するとBerlinが取得されてしまうことになります。これではデータが失われてしまうのでうまく連想配列を利用できません。
このように異なるデータから同一の数字が得られる状況を衝突と言います。
衝突した場合に備えて、いくつかの対策が考案されてきました。
チェイン法では、同じインデックスに複数の値の保持を許容するといった方法です。各 Index の中では探索アルゴリズムを利用してデータを取得します。ただし、衝突が多くなればなるほど計算量が O(1)からどんどん悪化していきます。
オープンアドレス法では、衝突時に別の空いているインデックスを探し、そちらに値を保持する方法です。空いているインデックスの探し方にはいくつかのパターンがあり、順番に見つけようとする線形走査法、1,2,4,8,,,と探していく 2 次操作法などがあります。
問題 3
問題 2 で自作した連想配列に対策を施しましょう。今回はチェイン法を実装してみます。
状況確認のため、次のデータを追加し実行してみます。
set("GERMANY", "Berlin")
すると、get("SPAIN")でデータを取り出す際にデータが上書きされているのでBerlinが取得されてしまいます。
array = [0, 'Washington D.C.', 'Tokyo', 'Berlin', 0, 0, 0, 0]
チェイン法は、同じハッシュ値(ハッシュ関数を通して得られた数字)に対して複数のデータをリスト形式で保存する方法です。
以下のような 3 次元配列を作成し、各要素に複数のデータセットを格納するようにしましょう。そして全探索で値を取り出すようにしましょう。(余力があれば 2 分探索を利用してみてください)
array = [[], [['USA', 'Washington D.C.']], [['JAPAN', 'Tokyo']], [['SPAIN', 'Madrid'],['GERMANY', 'Berlin']], [], [], [], []]
なお、以下の条件に従ってください。
- 組み込みメソッドは使わないこと。つまり、分岐、繰り返し処理を自分で書くこと。
- Array.find などは使わない
- 解法を調べるために chatgpt、インターネットは使用しないこと
- 文法を調べることのみ可
- 計算量は問いません
テストケース
まずは以下を実行して値を代入してください。
set("JAPAN", "Tokyo")
set("USA", "Washington D.C.")
set("SPAIN", "Madrid")
set("GERMANY", "Berlin")
その後、get 関数を実行して値を取得できることを確認しましょう。
get("JAPAN")
get("USA")
get("SPAIN")
get("GERMANY")
Tokyo
Washington D.C.
Madrid
Berlin
コードの最後に以下のメソッドを実行します。
set("JAPAN", "Tokyo")
set("USA", "Washington D.C.")
set("SPAIN", "Madrid")
set("GERMANY", "Berlin")
get("JAPAN")
get("USA")
get("SPAIN")
get("GERMANY")
2 次元配列の初期化は Python で以下のように書きます。
[[] for i in range(8)]
解答例
クリックすると解答例が見られます
array = [[] for i in range(8)]
mapping = {
"A": 1,
"B": 2,
"C": 3,
"D": 4,
"E": 5,
"F": 6,
"G": 7,
"H": 8,
"I": 9,
"J": 10,
"K": 11,
"L": 12,
"M": 13,
"N": 14,
"O": 15,
"P": 16,
"Q": 17,
"R": 18,
"S": 19,
"T": 20,
"U": 21,
"V": 22,
"W": 23,
"X": 24,
"Y": 25,
"Z": 26
}
def hash(key):
sum = 0
for char in key:
sum += mapping[char]
index = sum % 8
return index
def set(key, value):
index = hash(key)
array[index].append([key,value])
def get(key):
index = hash(key)
for set in array[index]:
if key == set[0]:
print(set[1])
set("JAPAN", "Tokyo")
set("USA", "Washington D.C.")
set("SPAIN", "Madrid")
set("GERMANY", "Berlin")
get("JAPAN")
get("USA")
get("SPAIN")
get("GERMANY")
set 関数では、配列の各要素の配列に、key, value のペアを配列の形で追加します。
そして get 関数では、ハッシュ値の index の中で全探索を行い、キー部分が一致した要素のバリュー部分を出力しています。
おわりに
勉強会第 5 回の内容として、連想配列をテーマに学びました。連想配列は Python でいう辞書型に相当するデータ構造です。キーバリュー型のデータ構造は他言語でも色々なところで目にすると思います。
連想配列は、内部にハッシュ関数を使用することで O(1)の計算量で情報を取得できるメリットがあります。ハッシュ関数は、データの集合を任意の数字に変換するメソッドです。異なるデータから同一のハッシュ値が得られてしまった場合は、対策を施す必要があります。これらの流れを理解するために、問題を通して連想配列を自作しました。なぜ連想配列を使うと良いのか?がしっかり答えられるようになったのではないでしょうか?
次回の勉強会はグラフ理論についてです。