こちらの勉強会は、本形式にまとめています。
https://zenn.dev/mandenaren/books/algorithm-study
はじめに
私は今年新卒 1 年目エンジニアとして活動しており、同期と週に一度勉強会を開催していました。
その勉強会の企画運営をローテーションで回していて、私のターンではプログラミングの問題を解く会を開くことにしました。
使用言語は文法が分かりやすいで Python をサポートします。
全部で 6 回実施し、学びが得られたと好評だったため記事に書き起こします。今回はその第一回目の記事となります。
| 回 | テーマ |
|---|---|
| 第 1 回 | 二分探索 |
| 第 2 回 | ソートアルゴリズム |
| 第 3 回 | 暗号化 |
| 第 4 回 | bit 演算 |
| 第 5 回 | 連想配列 |
| 第 6 回 | グラフ理論 |
目的としては以下になります。
- アルゴリズムについての理解を深め、エンジニアとしての教養を深める
- 将来の選択肢を広げる
- 他人の問題の解き方、発想の仕方、観点を学ぶ
また、勉強会では、少人数のグループに分かれペアプロ形式で問題を解いて行きました。
議論しながら問題演習を重ねることで色々な発想を知ることができます。
プログラミングやアルゴリズム学習の題材としてこちらの記事を活用することもできると思います。
プログラミングの問題演習では手軽なオンライン実行環境のPaiza.ioを利用します。
一般化できる学びを得られるようなテーマを毎回設定します。
普段エンジニアリングをする上で背景まで知っている事柄が増えるとより納得感を持って取り組めると思います。
また見える景色が変わっていき、エンジニアリングがどんどん楽しくなっていけば勝利です。
チュートリアル
(初回のため、チュートリアルの内容となります。)
一つの数字 A と 1 から始まる連続する数列が以下のように与えられます。
7
1,2,3,4,5,6,7,8,9,10,11,12,13,14,15
数列の順番に、A まで、3 の倍数だった場合は「Fizz」を、5 の倍数だった場合は「Buzz」を、15 の倍数だった場合は「Fizz Buzz」と出力、いずれも当てはまらなかったら数字をそのまま出力するプログラムを書いてください。なお、以下の条件に従ってください。
- テストケースは全て満たすこと
- 組み込みメソッドは使わないこと。つまり、分岐、繰り返し処理を自分で書くこと。
- Array.find などは使わない
- 解法を調べるために chatgpt、インターネットは使用しないこと
- 文法を調べることのみ可
- 計算量は問いません
テストケース
8
1,2,3,4,5,6,7,8,9,10
1
2
Fizz
4
Buzz
Fizz
7
8
15
1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17
1
2
Fizz
4
Buzz
Fizz
7
8
Fizz
Buzz
11
Fizz
13
14
Fizz Buzz
コマンドラインからの入力を受け取る方法
# 入力
last_number = int(input())
array_elements = list(map(int, input().split(',')))
初回のため、Paiza.ioの使い方を簡単に説明します。
まずプログラミング言語を選択し、ソースコードを記入します。
その後「入力」にテストケースの input を記入実行して「出力」を見て、output が合っているか確認するだけです。
解答例
クリックすると解答例が見られます
# 入力
last_number = int(input())
array_elements = list(map(int, input().split(',')))
# 回答
def fizz_buzz(last_number,numbers):
for i in range(last_number):
number = array_elements[i]
if number % 15 == 0:
print("Fizz Buzz")
elif number % 3 == 0:
print("Fizz")
elif number % 5 == 0:
print("Buzz")
else:
print(number)
fizz_buzz(last_number, array_elements)
古典的な FizzBuzz 問題ですね。ループで指定の回数回していき、倍数を割り切れるかどうかの条件式で判定していきます。
問題
一つの数字とソートされた数列が以下のように与えられます。
7
1,2,3,4,5,6,8,9,10
1 行目の数字が 2 行目の数列に含まれているなら Yes と、含まれていないなら No と出力するプログラムを書いてください。なお、以下の条件に従ってください。
- テストケースは全て満たすこと
- 組み込みメソッドは使わないこと。つまり、分岐、繰り返し処理を自分で書くこと。
- Array.find などは使わない
- 解法を調べるために chatgpt、インターネットは使用しないこと
- 文法を調べることのみ可
- 計算量が小さい方が望ましいです。
- 実際の競プロ等では、10^9 のような大きな計算回数が求められます。
- 目視ではまず分からない条件が出ます。
- 用意するのが大変なため、勉強会では簡単なテストケースを利用します。
- 目視では分からないものだよね!という想定でプログラムを書きましょう
テストケース
3
1,2,3,4,5
Yes
7
0,2,3,5,6,8,9,10
No
解答例
クリックすると解答例が見られます
# 入力
number_to_find = int(input())
array_elements = list(map(int, input().split(',')))
# 回答
def binary_search(sorted_array, number):
left, right = 0, len(sorted_array) - 1
while left <= right:
mid = (left + right) // 2
if sorted_array[mid] == number:
return "Yes"
elif sorted_array[mid] < number:
left = mid + 1
else:
right = mid - 1
return "No"
print(binary_search(array_elements, number_to_find))
「ソートされた数列」をヒントに、半分ずつ探索対象を絞っていくことで計算量を小さくできます。
この探索手法のことを二分探索と呼びます。
解説
この問題からは、二分探索で計算量を抑えられるという学びがあります。
計算量とは?
→ 入力されるデータ量によって、実行時間がどのような割合で変化するのかを表す指標。計算時間と言っても良いでしょう。
O 記法で表します。
if 文のような比較処理は、コンピュータが計算する一つの単位とみなすことができます。
配列の頭からしらみ潰しで全ての要素と比較していくような方法を全探索を言います。
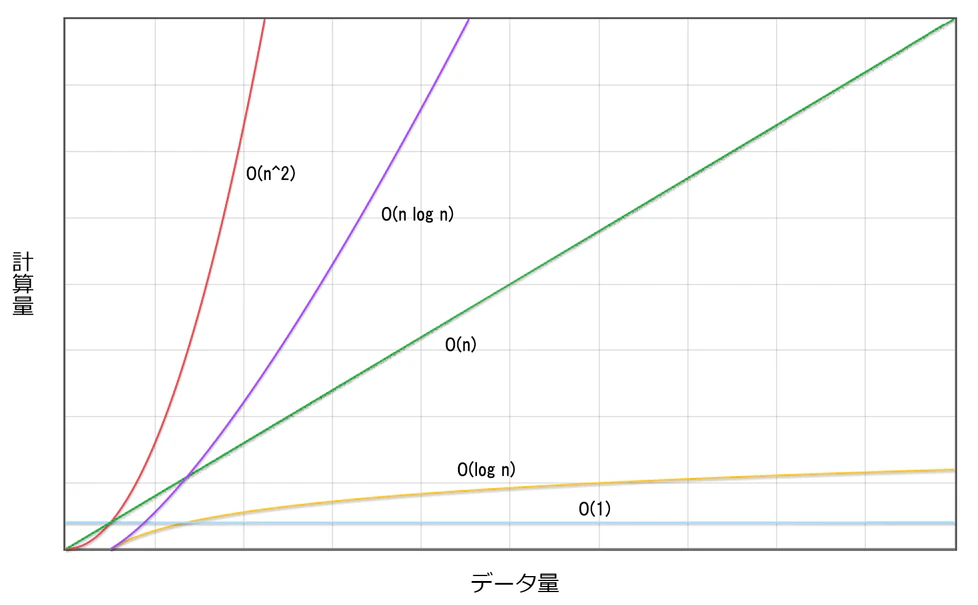
これは、配列の要素数が増えるほど比例して計算時間が増えていくため、オーダー記法で O(n)と書きます。
数学で言うと、1 次関数のことですね。
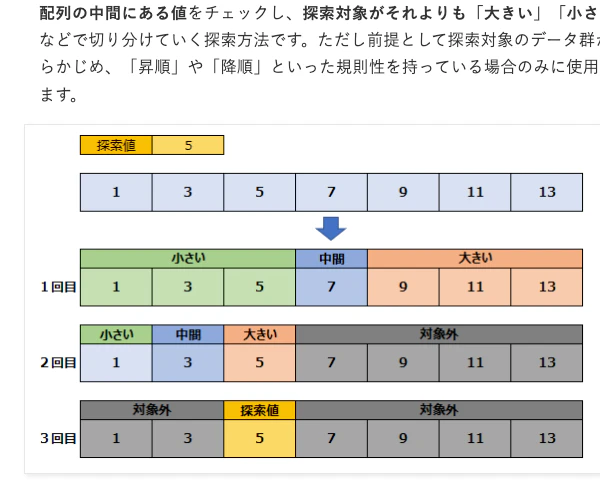
一方で二分探索の場合、配列の要素が増えても、半分ずつ探索対象が減っていくため比較回数を抑えることができます。
どうやら規則性がありそうですね。
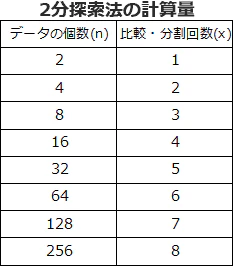
式で表すと、データ量=2^(計算量)が成り立つため、計算量=log(データ量)となります。
このことから、二分探索は O(log)と表現されます。
グラフを見ると、データ量が大きくなるほど、計算量の増加は緩やかなのでより高いパフォーマンスを出すことができるわけですね。
反対に、二重ループの場合のような処理の場合、計算量=データ量^2 になるので O(n^2)と表現します。
これは、データ量の増加に従って爆発的に計算量も増加する=指数関数的増加と表現することがあります。
二分探索は基礎的なアルゴリズムですが、応用例に DB のインデックスがあります。
エンジニアリングをしていると、検索パフォーマンスを上げるために、Index を貼りますよね。
では、Index を貼るをなぜパフォーマンスが良くなるのでしょうか?
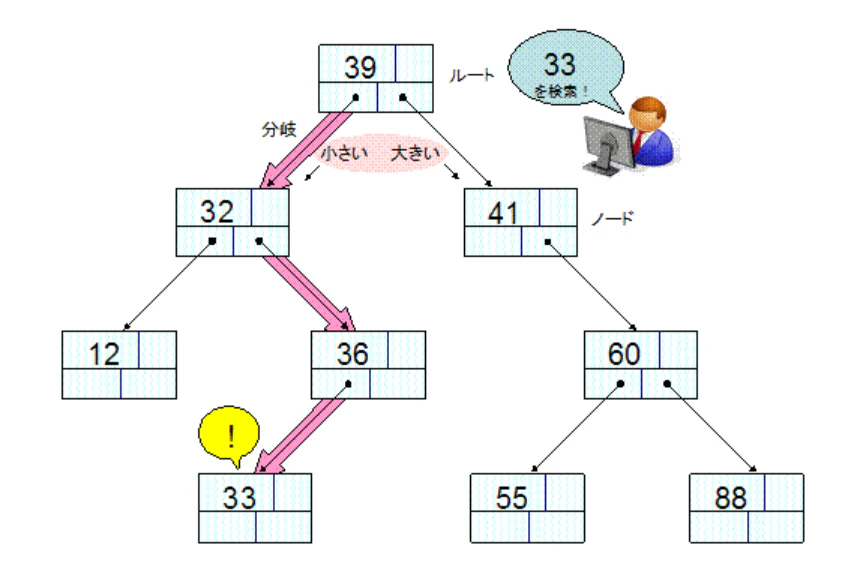
Index を貼ると、裏側に B-tree というものが作られます。これはデータを大小関係に沿って木構造の形に並べたものです。
「データが順番に並んでいる」ということは、以下図のように二分探索の要領で該当のデータに辿り着くことができるんですね。
なので、しらみ潰しに頭から検索するよりも計算量が抑えられ、早く検索できるようになるというわけです ✨
おわりに
勉強会初回の内容として、二分探索をテーマに学びました。
「データが順番に並んでいる」と、半分ずつ探索を絞っていけるため比較回数を抑えることができ、計算量を小さくできます。
このようにアルゴリズムの工夫によって、パフォーマンスを向上することができます。
基礎的なアルゴリズムですが、世の中で様々な応用例があり、代表的なものとして DB のインデックスを挙げました。
この記事を読んだ方は、DB のインデックスを貼るとなぜ検索が早くなるのか?を理解できているはずです。
一つ教養を得ましたね。
このような学びを重ねることで、普段のエンジニアリングの背景が分かってきます。
そうすると、納得感が増して、エンジニアリングが無味乾燥なものから鮮やかな景色が見えてくる感覚があることでしょう。
次回の勉強会はソートアルゴリズムです。