はじめに
Qiita 初投稿です。
作成したモデルを Raspberry pi でも実行できるようにしたいと思い、Keras でモデル圧縮の手法の一つである知識の蒸留を試してみました。
学習データは TGS Salt Identification Challenge | Kaggleを使用しています。
Keras での実装する上でハマった部分がありましたので、参考になれば幸いです。
Faster-RCNN で蒸留を適用した論文の記事を書きました。
よければ、こちらの記事も見て下さい。
https://qiita.com/HiroZelda/items/431e2d63d1e9134c1038
Moriyasu Komiyaさんが画像ディレクトリををtrain_test_splitする関数を紹介する記事を書かれています。非常に便利なので、ぜひ、使って下さい!
https://qiita.com/komiya-m/items/c37c9bc308d5294d3260
環境
GPU:Geforce RTX 2070
CPU:Intel Core i5-6500
OS:windows 10
Python:3.6.6
keras:2.2.4
TensorFlow:1.12.0
データセット
TGS Salt Identification Challenge | Kaggle
アーキテクチャ
U-Net
知識の蒸留の概要(Knowledge Distillation)
Deep Learning では一般に、層が深くてパラメータ数の多い大きいモデルのほうが精度が上がりやすいことが知られています。モデルを大きくすると精度は上がりますが、計算コストが高くなり、予測時間が長くなります。逆に、モデルを小さくすると計算コストが低くなり、予測時間が短くなります。その代わりに、大きいモデルと比べると予測精度が下がります。小さいモデルでも精度を向上させる手法として「知識の蒸留」があります。
基本となる考え方は予測精度の良い大きいモデルを教師モデルとします。教師モデルの推論結果を小さいモデルである生徒モデルの正解ラベルとして学習を行います。そうすることにより、通常の正解ラベルで学習するよりも精度が上がります。(実際に検証したら、精度が上がりました。)
 [Deep Learningにおける知識の蒸留](http://codecrafthouse.jp/p/2018/01/knowledge-distillation/) より
[Deep Learningにおける知識の蒸留](http://codecrafthouse.jp/p/2018/01/knowledge-distillation/) より
soft target loss, hard target loss ~二つの損失~
生徒モデルを学習する際には「soft target loss」と「hard target loss」の2つの損失もしくは「soft target loss」のみで学習します。
soft target loss:教師モデルの出力と生徒モデルの出力の損失
hard target loss:学習データの正解ラベルと生徒モデルの出力の損失。通常の損失。(なくても良い)
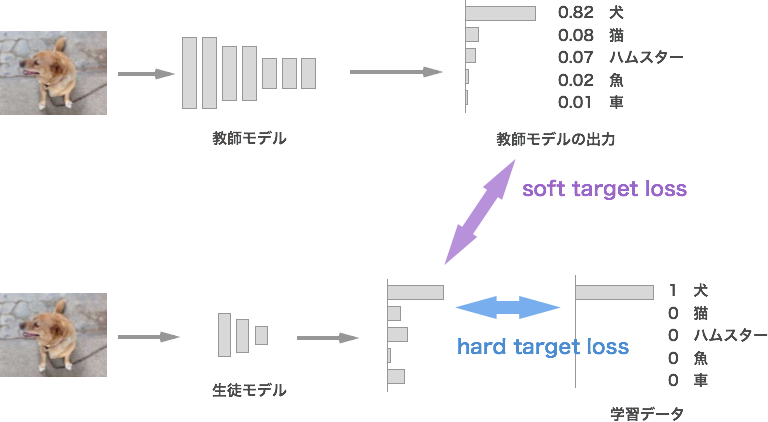
損失関数の概要
蒸留の手法はいくつか提案されています。今回は温度付き soft max(Softmax with Temperature) + soft target loss + hard target loss を実装します。soft target loss のみ場合と hard target loss + soft hard target loss の場合の説明をします。
soft target loss
soft target loss のみ場合と hard target loss + soft hard target loss の場合の説明をします。
以下の図は soft target loss のみ場合のモデル図になります。通常の学習と異なるのは一つは出力層の直前(図では soft max or sigmoid)に温度 T で割る処理が入ります。もう一つは損失には生徒モデルの出力(Ys_soft)と学習データの正解ラベルでなく、重みを固定した教師モデルの出力(Yt_soft)を利用します。教師モデルは学習した出力が欲しいので重みを固定し学習は行いません。数式にすると以下になります。
$
Loss:= Loss_{soft}(Yt \_ soft , Ys \_soft )・・・・①
$
$Loss_{soft}$ :損失関数(今回は交差エントロピー誤差)

hard target loss
hard target loss + soft hard target loss の場合のモデル図は以下のようになります。先程のモデルと異なるのは温度 T 割らない出力(Ys-hard)があることです。
生徒モデルにの出力が「Ys-hard」と「Ys-soft」の二つがあるのは、soft target loss と hard target loss で損失を計算する必要があるためです。
損失関数の中身と言うとは教師モデルからの出力「Yt_soft」と生徒モデル出力「Ys_soft」との交差エントロピー誤差。**学習データの正解ラベル(Ytrue)**と「Ys_hard」との交差エントロピー誤差二つの合算になります。ただし、温度付き soft max を使うとsoft target loss の勾配の強さが $ \frac { 1 }{ { T }^{ 2 } } $ となることから、hard target loss を加える場合はsoft target loss $T^2$ を加える必要があります。数式すると以下のようになります。
$Loss:= (1-λ)Loss_{soft}(Yt \_ soft, Ys \_ soft) + λ T^2 Loss_{hard}(Ytrue, Ys \_ hard)・・・・②$
$Loss_{soft}, Loss_{hard}$ :損失関数(交差エントロピー)
$λ$は$Loss_{soft}$と$Loss_{hard}$は各損失の比重
※出力層にSigmoid 関数を使用する場合は$T^2$→$T$になります。

モデルの実装
実装する上で注意が必要な部分を説明をしていきます。
生徒モデルを作成するには学習済みの教師モデルが必要となるので、教師モデルを作成し、学習をさせておきます。
教師モデルの構築
学習した教師モデルには温度 T で割る処理が入っていないので、teacher_model.layers.pop() を使用して出力層を外します。外した後に温度 T で割る層と出力層を追加します。今回はセグメンテーションのため、出力層に Sigmoid を追加します。
# 教師モデル構築
from keras.models import load_model
teacher_model = load_model("teacher_model.h5", custom_objects={'mean_iou': mean_iou})
# 重み固定
for i in range(len(teacher_model.layers)):
teacher_model.layers[i].trainable = False
teacher_model.compile(optimizer="adam", loss="binary_crossentropy")
# 教師モデルの出力層を削除
teacher_model.layers.pop()
input_layer = teacher_model.input
# 温度 T で割る処理
theacher_logits = teacher_model.layers[-1].output
theacher_logits_T = Lambda(lambda X: X/T)(theacher_logits)
teacher_probabilities_T = Activation('sigmoid')(theacher_logits_T)
生徒モデルの構築
生徒モデルの入力層は教師モデルの入力層を使用して共有させます。ここでは、温度T割る出力(Ys_soft)と割らない出力(Ys_hard)、二つの出力層を作成します。推論の際には温度Tで割らない出力(Ys_hard)を使用します。
# 生徒モデル
s = Lambda(lambda x:x /255.0)(input_layer) # 教師モデルの入力層
~省略 (U-Net 構築) ~
output = Activation('sigmoid', name="output")(tc10) # 推論用(Ys-hard)
logits_T =Lambda(lambda X: X/T)(tc10)
probabilities_T = Activation("sigmoid", name="probabilities_T")(logits_T) # soft target loss (Ys-soft)
student_model = Model(inputs=[input_layer], outputs=[output]) # 生徒モデル用に出力を
student_model.compile(optimizer='adam', loss='binary_crossentropy', metrics=[mean_iou])
student_model.summary()
学習用のモデル構築(教師モデル + 生徒モデル)
先程作成した教師モデルと生徒モデルを同士に学習するモデルを作成します。「with tf.device('/cpu:0'):」を使用するとモデルを並列で処理するようになります。「knowledge_distillation_loss」は自作損失関数になります。今回は正解ラベルが「Ytrue」、「Yt_soft」の二つ。推論結果が「Ys_hard」、「Ys_soft」の二つ。変数が計4つあります。損失関数には引数が二つまでしか設定できないため、自作した損失関数をレイヤーに組込みます。そして、「教師モデル + 生徒モデル」の出力を損失値にします。「knowledge_distillation_loss」の実装は次に説明します。
「loss= lambda y_true, y_pred: y_pred」の部分は、コンパイルの損失の設定の部分に自作損失関数を入れず、モデルの出力が loss になるようにしています。
# 生徒モデル
with tf.device('/cpu:0'):
student_model = Model(inputs=input_layer, outputs=output)
# 入力として学習データの正解ラベルを入れる
input_true = Input(name='input_true', shape=[im_height, im_width, im_chan])
# 教師モデル + 生徒モデル
# 自作損失関数をレイヤーとして組込み
output_loss = Lambda(knowledge_distillation_loss, output_shape=(1,), name='kd_')(
[output, input_true, teacher_probabilities_T, probabilities_T]
)
# input_layer:入力 input_true:学習データの正解ラベル
inputs = [input_layer, input_true]
with tf.device('/cpu:0'):
# 損失値を出力とする
train_model = Model(inputs=inputs, outputs=output_loss)
# 出力が loss になるように設定
train_model.compile(optimizer='adam', loss= lambda y_true, y_pred: y_pred)
損失関数の作成
hard target loss + soft hard target loss の損失関数の数式②をコードにすると以下になります。
from keras.losses import binary_crossentropy as logloss
lambda_ = 0.9
def knowledge_distillation_loss(input_distillation):
y_pred, y_true, y_soft, y_pred_soft = input_distillation
return (1 - lambda_) * logloss(y_true, y_pred) + lambda_*T*logloss(y_soft, y_pred_soft)
検証
hard target loss と hard target loss + soft target loss で比較で比較してみました。
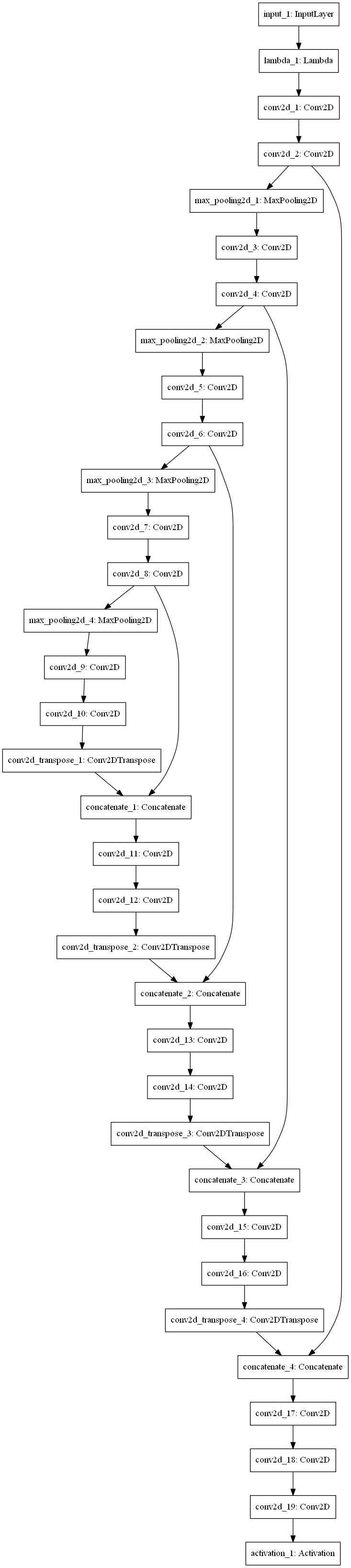
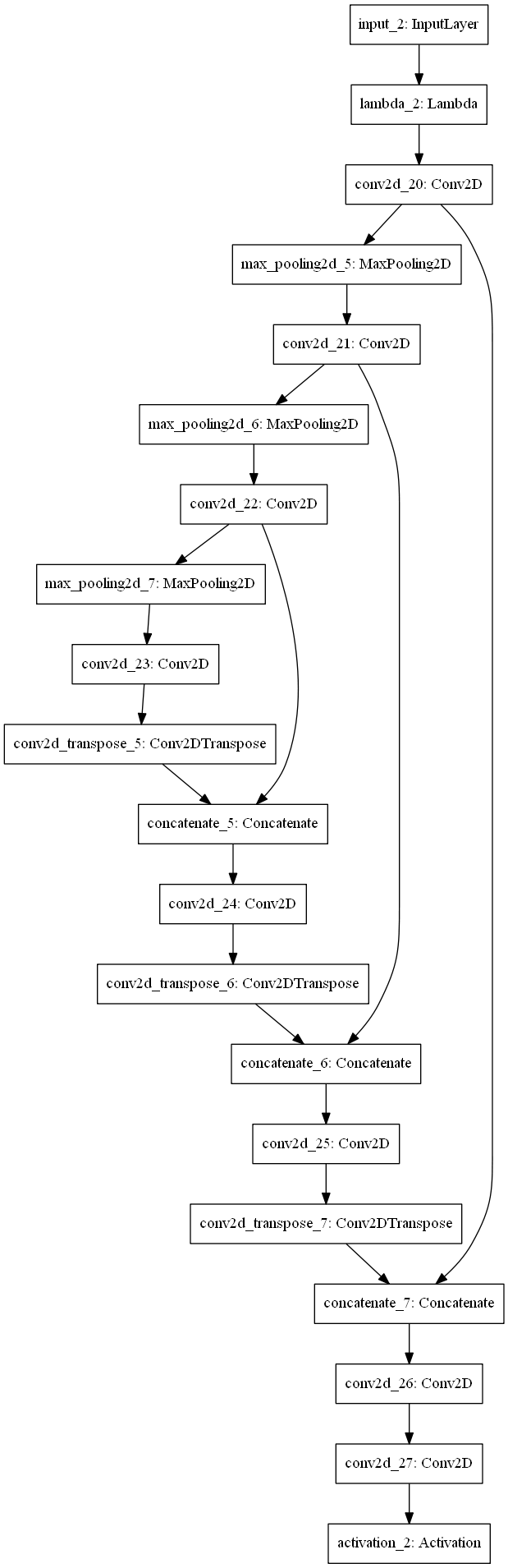
使用した教師モデルと生徒モデルのモデルは以下になります。
教師モデル
生徒モデル
結果
対象画像
正解ラベル
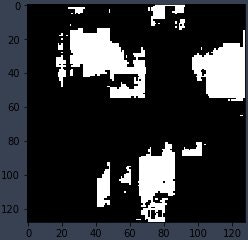
hard target
hard target + soft target
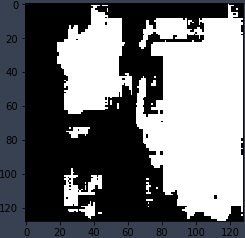
蒸留した方が精度が上がっていることが確認できました。結果の画像はないのですが、温度Tを大きくしたら精度より、精度が上がりました。
今後やりたいこと
● 他のデータセットや二値のセグメンテーション以外ではどのくらい有効なのか検証
● 温度 T をどう変更したら良い精度が出るか検証
● Keras で実行できる蒸留ツールの作成
検証データまとまったら、また、記事に書きたいと思っています。
参考サイト
理論と数式:
蒸留をするの必要な数式、理論はこちらのサイトを参考にしました。
Deep Learningにおける知識の蒸留
蒸留 第1回 | DeepX AI Blog
蒸留 第2回 | DeepX AI Blog
Keras ソースコード:
Keras で蒸留実装するのにこちらの GitHub を参考にしました。
GitHub