はじめに
以前、書いた記事 keras での蒸留方法に関連してした「Faster R-CNN」で蒸留を行った論文を読みました。
自分なりに理解したいとをまとめたいと思います。
論文:
Learning Efficient Object Detection Models with
Knowledge Distillation
以前の記事
Kerasによる知識の蒸留 (knowledge distillation) ~TGS(kaggle)~
https://qiita.com/HiroZelda/items/0ba24788c78540046bcd
概要
畳み込みニューラルネット(CNN)ベースのオブジェクト検出器における精度は向上しています。しかし、最先端のモデルでは多くの場合、非常に深いネットワークを使用し、大きい桁数の浮動小数点数を必要とします。そのため、リアルタイム検出を行うには非常に大きなリソースを必要とします。本論文ではFaster R-CNNをベースとして、知識の蒸留[1]とヒント学習[2]適用させた、軽量で高速な物体検出ネットワークを精度良く学習するための手法を提案しています。
知識の蒸留とヒント学習
本論文を理解する上で知識の蒸留とヒント学習の知識が必要となりますので、簡単に説明をします。
知識の蒸留
基本概念
基本となる考え方は大きいモデルからの出力を小さいモデルで学習することです。大きいモデルとは層が深く精度の良いモデルのことを指し、教師モデルと呼びます。教師モデルから学習した知識を継承する小さいモデルを生徒モデルと呼びます。生徒モデルは教師モデルが推論した結果を学習します。そうすることにより、教師モデルと同じような出力分布に近づきます。通常のデータセットの正解ラベルを使用するよりも、精度が向上することが知られています。
学習する際には教師モデルからの出力とデータセットの二つで学習を行います。教師モデルからの出力での損失を「Soft target loss」、データセットでの損失を「Hard target loss」と呼びます。
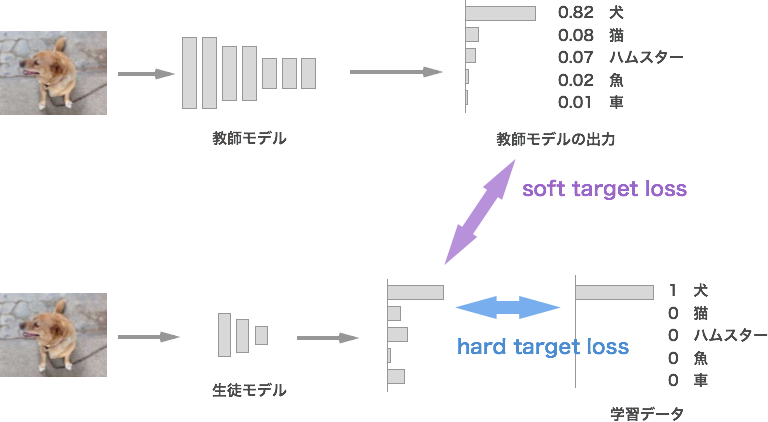
Softmax with Temperature
蒸留を理解するのに必要となる知識としてもう一つ温度付き soft max(Softmax with Temperature) がなります。教師モデルの出力を温度パラメータTで割ったものを生徒モデルで学習させる方法です。温度パラメータTを大きくしていくと、教師モデルの出力が一様分布に近づき、より多くの分類結果を生徒モデルに伝えやすくなります。温度パラメータ T で割るのは出力層の直前に入れます。数式は以下になります。
学習時の損失
前述した損失と Softmax with Temperature を数式すると以下になります。モデルの構成概念図を図2に示します。
$softmax(x_i)=\frac{e^{\frac{x_i}{T}}}{\sum_{j} e^{\frac{x_j}{T}}}$

$Loss:= (1-\mu)Loss_{soft}(Yt \_ soft, Ys \_ soft) + \mu T^2 Loss_{hard}(Ytrue, Ys \_ hard)$
$Yt \_ soft$:教師モデルからの出力
$Ys \_ soft$:温度 T で割った生徒モデルからの出力
$Ys \_ hard$:生徒モデルからの出力
$Ytrue$:データセットの正解ラベル
$Loss_{soft}, Loss_{hard}$ :損失関数(交差エントロピー)
$\mu$:$Loss_{soft}$と$Loss_{hard}$は各損失の比重
$T$:温度パラメータ

ヒント学習
教師モデルの出力だけでなく、中間層の出力を利用するのがヒント学習です。教師モデルと生徒モデルでは隠れ層のユニット数が異なるのでサイズを合わせる必要があります。下図の(b)のように生徒モデルの隠れ層のユニット数を教師モデルのユニット数に変換するための重みが必要となります。
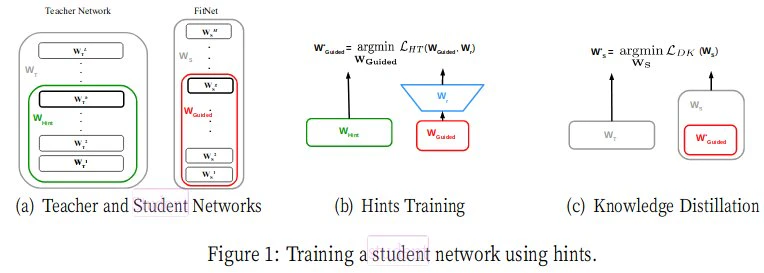
FITNETS : HINTS FOR THIN DEEP NETS:論文より引用
ネットワーク構成
以下より本論文の内容の解説をしていきます。
初めにも述べましたが、Faster R-CNN をベースとして、蒸留とヒント学習学習利用してモデルの高速化を行っています。下図は論文のネットワーク構成図になります。教師モデルの中間層の出力をヒントとして、生徒モデルの中間層の出力と「L2ノルム」を最小化する「L2 Loss」を取ります。教師モデルと生徒モデルではユニット数が異なるので、揃えるために「Adaptation」レイヤーを生徒モデル側に追加しています。Faster R-CNN では物体領域と検出した物体の分類を行っているので教師モデルでの出力と生徒モデルでの出力でそれぞれを損失を取っています。図の「Ground Truth」は学習データの正解ラベルになります。
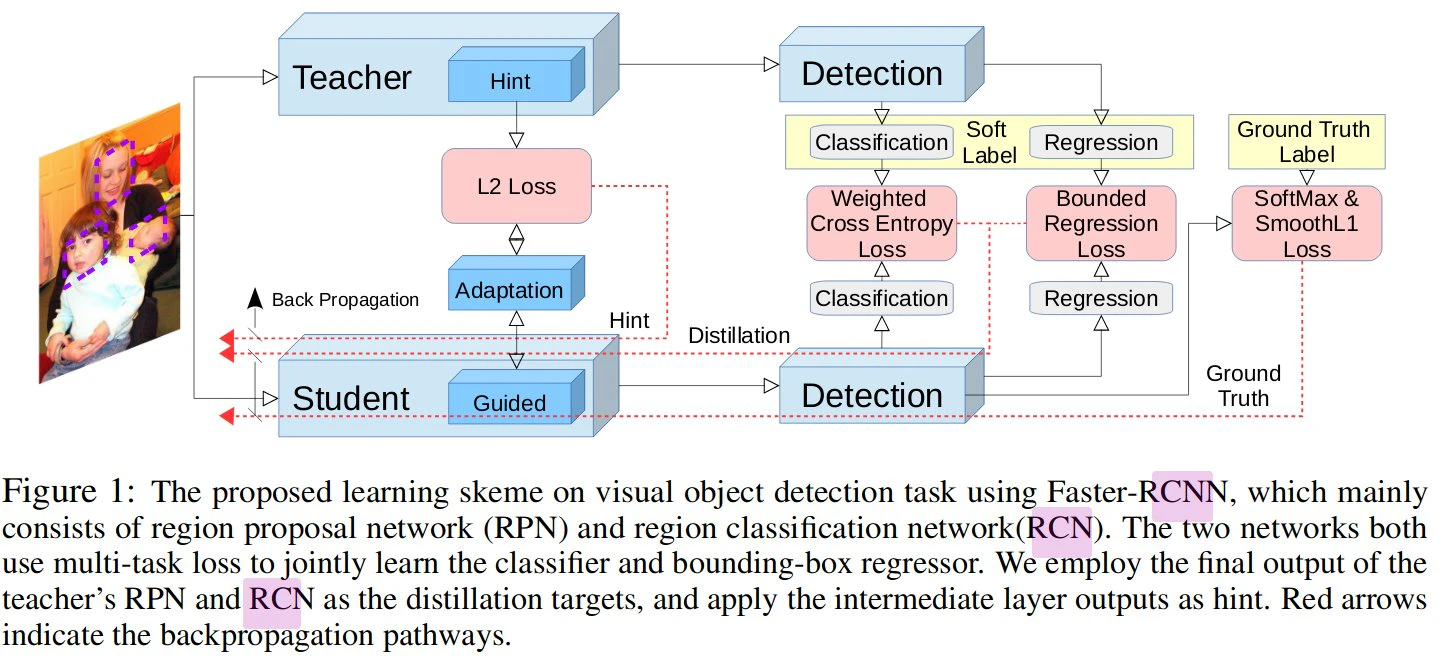
論文より引用
全体構造
学習時の全体構造の損失の数式は以下になります。
$L_{RCN}=\frac{1}{N}\sum_{i}L^{RCN}_{reg}+\lambda \frac{1}{N}L^{RCN}_{CLS}$
$L_{RPN}=\frac{1}{M}\sum_{i}L^{RPN}_{reg}+\lambda \frac{1}{M}L^{RPN}_{CLS}$
$L=L_{RPN} + L_{RCN} + \gamma L_{Hint}$
$L_{RCN}$と$L_{RPN}$は論文よりオブジェクト提案を生成する領域提案ネットワーク(RPN)検出スコアを次のように返す分類回帰ネットワーク(RCN)と定義されいます。
In this work, we adopt the Faster-RCNN [32] as the object detection framework. Faster-RCNN is composed of three modules: 1) A shared feature extraction through convolutional layers, 2) a region proposal network (RPN) that generates object proposals, and 3) a classification and regression network (RCN) that returns the detection score as well as a spatial adjustment vector for each object proposal. Both the RCN and RPN use the output of 1) as features, RCN also takes the result of RPN as input.
また、$L_{CLS}$は分類器の損失関数。$L_{reg}$はバウンディングボックス回帰損失関数を示しています。
RCN とRPN が Faster R-CNN のネットワーク図で言うと「proposals」が「RPN」。「classifier」が「RCN」になります。上記の損失は各二つのレイヤーの出力の損失を取っています。
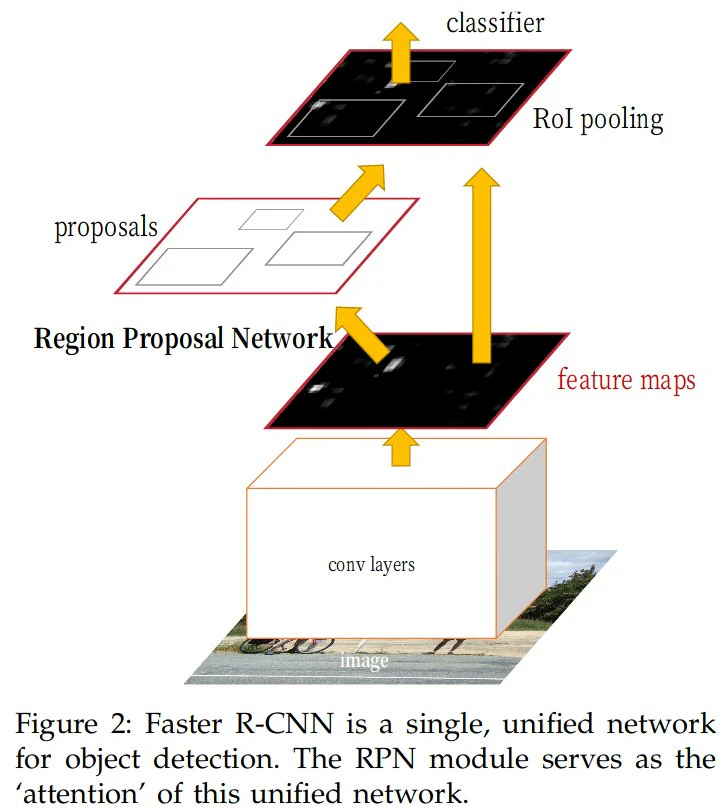
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks:論文より引用
不均衡クラスを用いた分類のための知識蒸留
クラス分類の損失関数では前述した知識の蒸留を使用します。
$L_{cls} = \mu L_{hard}(P_{s},y) + (1-\mu)L_{soft}(P_{s},P_{t})$
$L_{hard}$は学習データの正解ラベル「ground truth label」と生徒モデルの出力との損失。$L_{soft}$は教師モデル出力と生徒モデルの出力との損失になります。$P_{t}, P_{s}$は教師モデル、生徒モデルの出力に Softmax with Temperature を適用しせた値になります。$\mu$は$L_{hard}$と$L_{soft}$のバランスをとるパラメータです。
$L_{hard}$と$L_{soft}$の両方の損失は交差エントロピー損失です。検出問題では背景となるデータが多いため不均衡に対処する必要があります。これに対処するために、蒸留の損失に対してクラス加重クロスエントロピーを採用しています。
$L_{soft}(P_{s}, P_{t}) = -\sum \omega_{c}P_{t}log P_{s}$
論文では背景クラスに $\omega_{0}=1.5$ を使用し、その他全ての $\omega_{i} = 1$ を使用します。また、物体検出ような複雑なモデルに対しては温度パラメータ$T=1$にするのが経験則上よいと書かれています。
both hard and soft losses are the cross entropy losses. But unlike simpler classification problems, the detection problem needs to deal with a severe imbalance across different categories, that is, the background dominates. In image classification, the only possible errors are misclassifications between ‘foreground’ categories. In object detection, however, failing to discriminate between background and foreground can dominate the error, while the frequency of having misclassification between foreground categories is relatively rare. To address this, we adopt class-weighted cross entropy as the distillation loss
教師限定による回帰のための知識蒸留
分類レイヤーに加えて提案された物体の領域の位置とサイズを調整するには、バウンディングボックス回帰を使用します。多くの場合、優れた回帰モデルを学習することは、優れた物体検出精度を確保するために重要です。 離散カテゴリの蒸留とは異なり、実際の値の回帰結果には限界がないため、教師モデルの回帰結果は生徒モデルに対して非常に誤ったガイダンスを提供する可能性があります。 さらに、教師は学習データの正解ラベルの方向と矛盾する回帰方向を提供するかもしれません。 したがって、教師の回帰結果を直接ターゲットとして使用するのではなく、それを生徒が達成するための上限として利用します。 生徒の回帰ベクトルは一般的にできるだけ学習データの正解ラベルに近いはずですが、生徒の損失+mより教師の損失の方が大きい場合は、生徒に損失を与えません。
回帰の数式は以下のようになります。
L_{b}(R_{s},R_{t},y){\left\{%
\begin{align}
\; ||R_{s}-y||^{2}_{2}, if ||R_{s}-y||^{2}_{2} + m > ||R_{t}-y||^{2}_{2} \\
\; 0, otherwise
\end{align}
\right.
}
L_{reg}=L_{sL1}(R_{s},y_{reg})+vL_{b}(R_{s}, R_{t}, y_{reg})
$m$はマージン、$y_{reg}$は回帰の学習データの正解ラベル、$R_{s}$は生徒モデルネットワークの回帰出力、$R_{t}$は教師モデルの回帰出力、$v$はウェイトパラメータです。実験では$0.5$に設定しています。
Often, learning a good regression model is critical to ensure good object detection accuracy [13]. Unlike distillation for discrete categories, the teacher’s regression outputs can provide very wrong guidance toward the student model, since the real valued regression outputs are unbounded. In addition, the teacher may provide regression direction that is contradictory to the ground truth direction. Thus, instead of using the teacher’s regression output directly as a target, we exploit it as an upper bound for the student to achieve. The student’s regression vector should be as close to the ground truth label as possible in general, but once the quality of the student surpasses that of the teacher with a certain margin, we do not provide additional loss for the student.
特徴適応を用いたヒント学習
ヒント学習での蒸留は最終出力のみを使用して損失をとります。ヒントとして教師モデルの中間層の出力$Z$と生徒モデルの中間層の出力$V$でL2ノルムを損失として使用します。
$L_{Hint}(V,Z)=||V-Z||^{2}_{2}$
また、L1ノルムでも損失を評価します。
$L_{Hint}(V,Z)=||V-Z||_{1}$
ヒント学習を適用するには、ユニット(チャンネル、幅と高さ)の数は、教師と生徒の対応する層の間で同じである必要があります。ヒントレイヤとガイドレイヤのチャネル数を一致させるために、出力サイズがヒントレイヤと同じガイドレイヤの後にアダプテーションを追加します。
Experiments(実験)
使用するデータセットはKITTI [12]、PASCAL VOC 2007 [11]、MS COCO [6]、およびImageNet DETベンチマーク(ILSVRC 2014)[35]など、一般的に使用されているデータセットを使用します。
モデル
モデルは標準的な畳み込み層、完全に接続された層、ReLU、ドロップアウト層とsoftmax層からなる標準的なCNNアーキテクチャを使用します。また、CNNアーキテクチャは人気のある、AlexNet、Tucker Decompositionを使ったAlexNet、VGG16そしてVGGMを使用しています。
全体的なパフォーマンス
実験は教師モデルと生徒モデルのアーキテクチャを異なる組み合わせで行っています。表は学生モデルに対するmAP(mean Average Precision)を示しています。
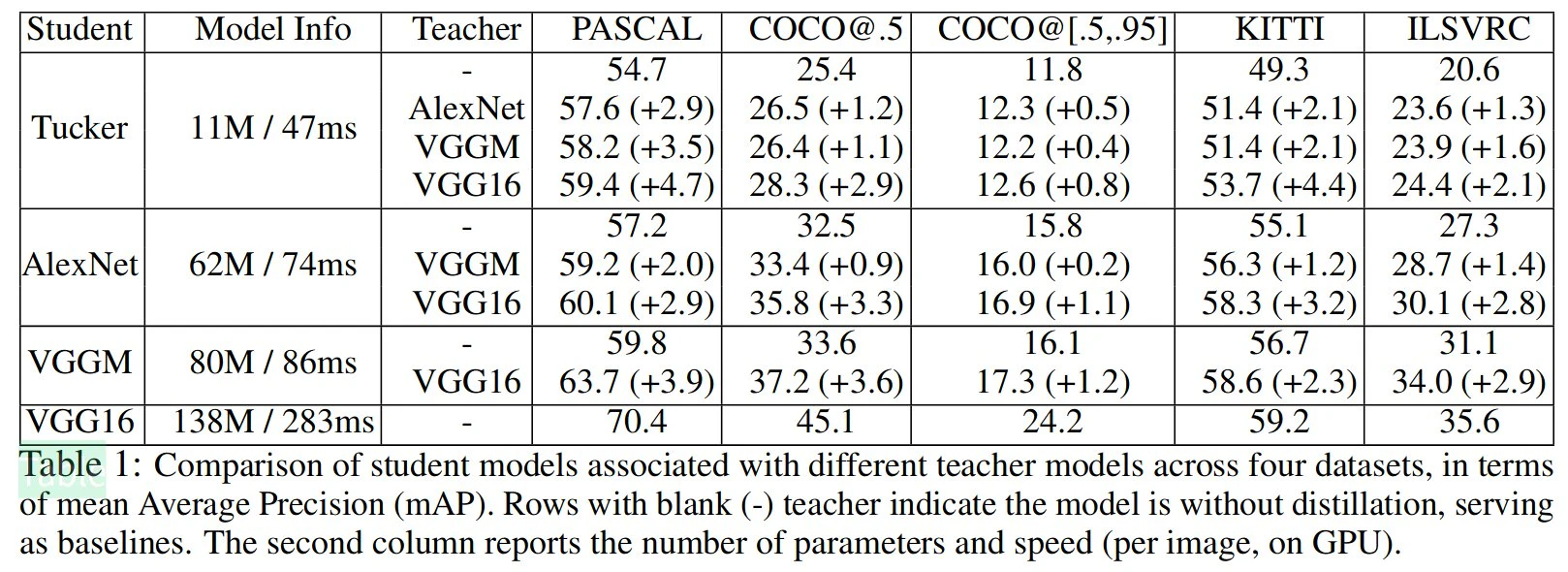
教師と生徒のアーキテクチャ上の違いにもかかわらず、生徒モデルのパフォーマンスは、すべての異なるペアやデータセットにわたる蒸留とヒント学習によって大幅に向上します。教師としてのモデルが深ければ深いほど、生徒のパフォーマンスは向上します。
圧縮モデルにおける速度と精度のトレードオフ
以下の表は学習データセットの正解ラベルで微調整されたモデルと今回の手法で蒸留されたモデルを比較しています。
表からも分かるようにネットワークの圧縮率が高すぎると、精度が大幅に低下します。たとえば、圧縮サイズが元の20%の場合、精度は57.2%からわずか30.3%に低下します。ただし、圧縮されたネットワークでは、本手法の蒸留を使用することで精度低下を回復することができます。
