huluのcrawlが禁止されていることを知った(huluのrobots.txt)
ため、このサイトの更新は現在停止しております。ご迷惑をおかけしてしまい申し訳ございません。
皆さん、映画はご覧になりますか。私は英語勉強という意識高げな名目も兼ねてちょいちょい見ます。
特に最近はchrome castやfire stick等でネット配信のものもテレビで見れて非常にいい時代に生まれたものだなと感じます。
しかし映画は時間を食べます。変ちきりんな作品を見るとなんだか損したような気になります。
コーディングに勤しむ皆さんはせっかくの貴重な時間を良い作品を見るのに使いたいですよね。
ということで、Huluで配信されている洋画をYahoo映画のスコアと紐づけてランキング表示するサイト作りました!
毎日夜中の3時に更新の処理(クローリング)が走り出すので常に最新の情報が表示されております!
- サイト
- ソースコード
フロントもバックもほぼ何も知らない素人がグーグル先生の力で書いた拙いものなので、ツッコミどころは満載かもしれませんが参考まで。
概要
python大好きマンなのでpythonでflaskやaspschedulerといったライブラリを使って組みました。
バックエンドにはHerokuを使いました。以前、お試しで深層学習のモデルを走らせて表示するサイトを研究のデモ用で作ったのですが、git pushだけでサーバーのセットアップすべてが完結する世界に感動し、また使ってみました。
お財布は寒いので無料プランで完結させてます。そのため後述するようにハマったところもあったのですが...
無料で使えるというのはherokuといい、google colaboratoryといい、端的に言って神ですね。
やっていること
一行で言いますと、aspschedulerで登録されたseleniumを使ったクローリングジョブが夜中に起動し、データベースを更新、そのデータベースの内容をflaskで、footableというテーブルを表示するライブラリおよびbootstrapを使ってブラウザ表示してます。
クローリングジョブは下記2つのことをやっております。(なぜかseleniumを使いましたが、spiderなどの方がいいのかもしれません。)
- Huluの映画リストをHuluの洋画一覧から取得
- 取得した映画リストを一つ一つYahoo映画の検索にかけ、検索で最初に表示されたものをクリックし、スコアと評価数を抽出
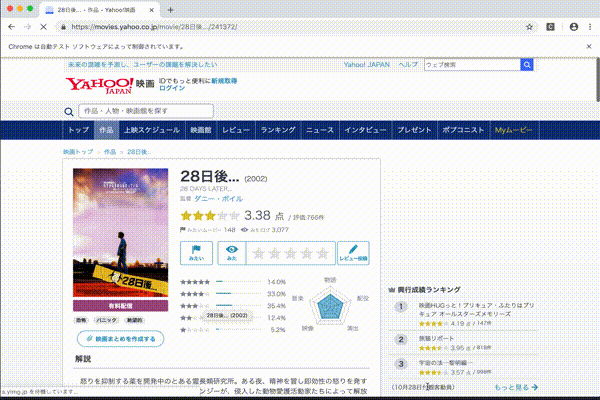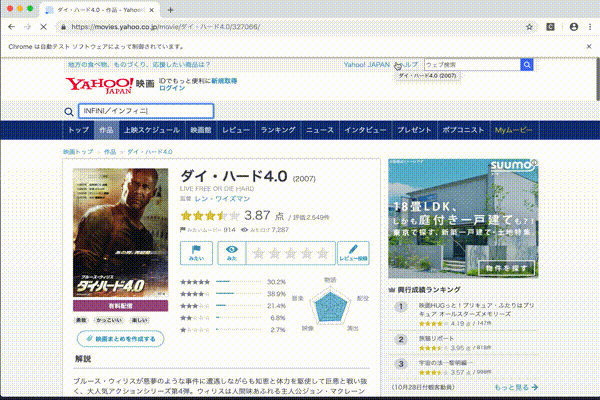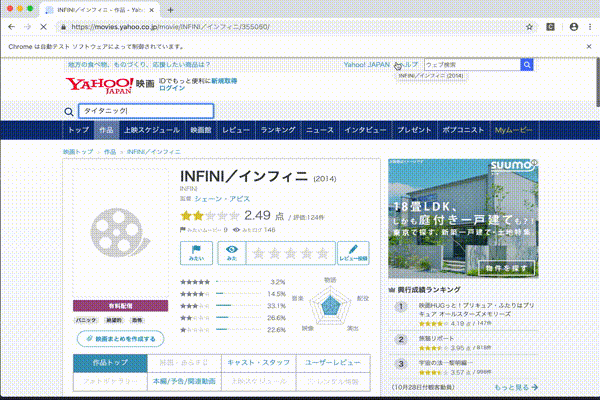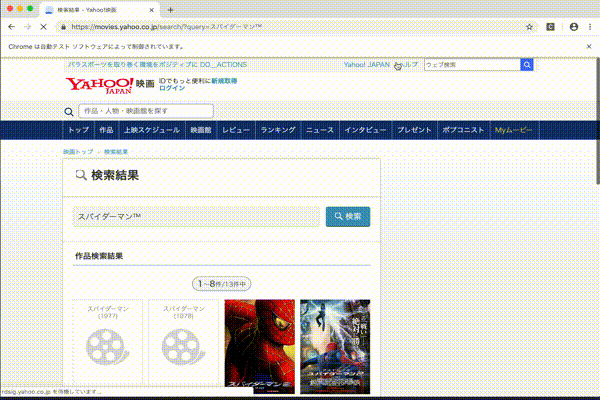
問題点にもあげましたが、これだとタイタニックの例のようにうまく取れない場合がある。作成年とかでさらに絞りこむ必要がありそうです。
詰まったところとその対応
初心者なので常識がなく、しょうもないと思われるようなところで詰まりました汗
①テキストファイルで書き出していたが、herokuではファイルを書き込めない仕様
基本的な事実のはずなのに、気づくのに時間がかかってしまいました汗。
【対策】 heroku postgresqlで対応
②server.pyに、flaskのブラウザ表示の処理に加え、クローリングを一定時刻に呼ぶ処理を書いていたが、下記エラーのようにこれだと30分(?)たつと勝手にsleepしてしまうため、クローリングの処理が呼ばれない
2018-11-04T03:18:14.609283+00:00 app[scheduler.2679]: 2018-11-04 12:18:14,609 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-11-04T03:18:14.609703+00:00 app[scheduler.2679]: 2018-11-04 12:18:14,609 INFO sqlalchemy.engine.base.Engine INSERT INTO yahoo (id, title, score, n_eval) VALUES (%(id)s, %(title)s, %(score)s, %(n_eval)s)
2018-11-04T03:18:14.609905+00:00 app[scheduler.2679]: 2018-11-04 12:18:14,609 INFO sqlalchemy.engine.base.Engine {'id': 330, 'title': 'バトルランナー', 'score': 3.07, 'n_eval': 262}
2018-11-04T03:18:14.611956+00:00 app[scheduler.2679]: 2018-11-04 12:18:14,611 INFO sqlalchemy.engine.base.Engine COMMIT
2018-11-04T03:18:17.650421+00:00 heroku[scheduler.2679]: Idling
2018-11-04T03:18:17.651196+00:00 heroku[scheduler.2679]: State changed from up to complete
2018-11-04T03:18:17.657959+00:00 heroku[web.1]: Idling
2018-11-04T03:18:17.658628+00:00 heroku[web.1]: State changed from up to down
2018-11-04T03:18:18.434297+00:00 heroku[scheduler.2679]: Stopping all processes with SIGTERM
2018-11-04T03:18:18.439157+00:00 heroku[web.1]: Stopping all processes with SIGTERM
2018-11-04T03:18:18.528582+00:00 heroku[web.1]: Process exited with status 143
2018-11-04T03:18:18.538678+00:00 heroku[scheduler.2679]: Process exited with status 143
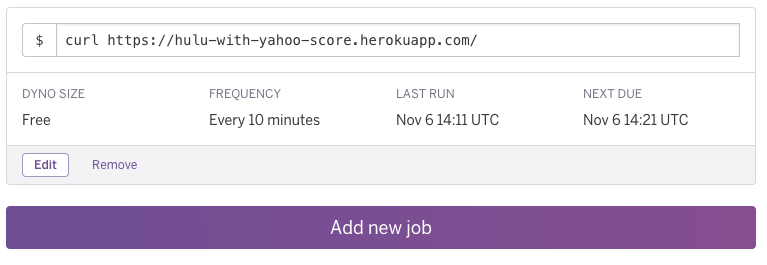
【対策】 調べると、すぐsleepするのは無料プランの仕様のようだと判明。下記画像のようにherokuのスケジューラで10分間隔でクリック処理をしてsleepしないようにすることで解消しました。
(ただ上記の処理に加えて、クローリングの処理もheorkuのスケジューラに登録してしまうとクローリングが動かなかった。これも無料プランの仕様のようだったので、クローリングの処理はpythonから呼び出し、スケジューラの処理は10分間隔でクリック処理する一つのみにすることで回避した。)
10分間隔でクリック処理する設定
③下記のようなエラーが出てメモリで死ぬ
2018-10-23T18:47:59.602408+00:00 app[scheduler.8054]: 2018-10-24 03:47:59,602 INFO sqlalchemy.engine.base.Engine INSERT INTO yahoo (id, title, score, n_eval) VALUES (%(id)s, %(title)s, %(score)s, %(n_eval)s)
2018-10-23T18:47:59.602666+00:00 app[scheduler.8054]: 2018-10-24 03:47:59,602 INFO sqlalchemy.engine.base.Engine {'id': 403, 'title': 'ヤング・アダルト・ニューヨーク', 'score': 2.94, 'n_eval': 342}
2018-10-23T18:47:59.618502+00:00 app[scheduler.8054]: 2018-10-24 03:47:59,618 INFO sqlalchemy.engine.base.Engine COMMIT
2018-10-23T18:48:16.300434+00:00 heroku[scheduler.8054]: Process running mem=1035M(198.5%)
2018-10-23T18:48:16.300522+00:00 heroku[scheduler.8054]: Error R14 (Memory quota exceeded)
2018-10-23T18:48:36.310918+00:00 heroku[scheduler.8054]: Process running mem=1035M(199.1%)
2018-10-23T18:48:36.310918+00:00 heroku[scheduler.8054]: Error R14 (Memory quota exceeded)
2018-10-23T18:48:48.084150+00:00 app[scheduler.8054]:
2018-10-23T18:48:48.085227+00:00 app[scheduler.8054]: 2018-10-24 03:48:48,085 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-10-23T18:48:48.085808+00:00 app[scheduler.8054]: 2018-10-24 03:48:48,085 INFO sqlalchemy.engine.base.Engine INSERT INTO yahoo (id, title, score, n_eval) VALUES (%(id)s, %(title)s, %(score)s, %(n_eval)s)
2018-10-23T18:48:48.086706+00:00 app[scheduler.8054]: 2018-10-24 03:48:48,086 INFO sqlalchemy.engine.base.Engine {'id': 404, 'title': '素敵なサプライズ ブリュッセルの奇妙な代理店', 'score': 3.77, 'n_eval': 381}
2018-10-23T18:48:48.096158+00:00 app[scheduler.8054]: 2018-10-24 03:48:48,095 INFO sqlalchemy.engine.base.Engine COMMIT
2018-10-23T18:48:56.138691+00:00 heroku[scheduler.8054]: Process running mem=1039M(200.0%)
2018-10-23T18:48:56.138930+00:00 heroku[scheduler.8054]: Error R14 (Memory quota exceeded)
2018-10-23T18:49:16.798897+00:00 heroku[scheduler.8054]: Process running mem=1042M(200.2%)
2018-10-23T18:49:16.799239+00:00 heroku[scheduler.8054]: Error R15 (Memory quota vastly exceeded)
2018-10-23T18:49:16.799405+00:00 heroku[scheduler.8054]: Stopping process with SIGKILL
2018-10-23T18:49:17.195487+00:00 app[scheduler.8054]:
2018-10-23T18:49:17.201266+00:00 heroku[scheduler.8054]: Process exited with status 137
2018-10-23T18:49:17.215074+00:00 heroku[scheduler.8054]: State changed from up to complete
【対策】 macのアクティビティモニタをみると、chrome helperの消費するメモリが単調増加していることが判明。おそらくブラウザに履歴などがたまりすぎてしまうのがよくないのだと考え50件クロールしたら、ブラウザを再起動する処理にすることで解消されました。
よく使ったコマンド
herokuのpostgresqlの中身を見る
heroku pg:psql -c "select * from hulu;"
herokuのログ確認
heroku logs -t
herokuのログが長すぎて昔のものが消えてしまうときがあるのでそんなときはファイルにも書き出す下記のコマンド。
teeの-aはappend(追記)の意味。
heroku logs -t | tee -a heroku_log.txt
問題点
問題点は色々あります。何か解決策に心当たりがある方はご気軽にコメントいただけると大変幸いですm(_ _)m
- Yahoo映画のスコアを正しいものをとれていない。
- 現在検索の第一番目を取っているがこれが正しい訳ではない。(クローリング対策であえてこうなるのでしょうか。。)
- クローリングに時間がかかる。
- 表示がしょぼい。
- スマホでも見れる
- ソート機能を正確に(現在、数値ではなく文字列ソートになってしまっている)
- テーブルにリンクをHuluのリンクをはる。
- ジャンルで絞り込めるように
- データがvaraietyがしょぼい。
- Huluの邦画、ドラマ対応
- NetFlix、アマゾンプライム対応など
- scrapy使うと早いのかもしれない。
- データベースを現状、上書きしてしまっている。
- Herokuの無料プランを貫きたいため、データを溜めずにいつも上がいている。
- そのためクローリング中に表示すると更新途中のものが表示されてしまう。
参考記事
- simple tables in a web app using flask and pandas with Python
- tableのソート、フィルタ、ページング、編集ができるjQueryプラグイン「footable.js」を使ってみた感想
-
footable.jsのバグ
- footable.jsをこの通りに多少書き直した。
- herokuでのスケジュール管理にAPSchedulerを使ってみる
- Chrome headless + seleniumをherokuで定期実行
- herokuのタイムゾーンを変更したらAPSchedulerが動いた話
- herokuでファイルが出力されない
- 【Heroku Postgresql】アドオンを追加し、テーブル操作を行う
- heroku で DB(postgresql)を利用するときのメモ
今後勉強してブラッシュアップしていく所存です。ご拝読ありがとうございました!