初めに
「TensorFlow」は、2015年にGoogleが開発した機械学習のソフトウェアライブラリです。
TensorFlowの1番の特徴は、ニューラルネットワークの構築、訓練ができるシステムの要求に応えられる点となります。
下記では、TensorFlow Decision Forests(TFDF)を使用したkaggleのnotebookを用いて、Spaceship Titanicデータセットに基づくランダムフォレストモデルの基本的なトレーニング方法の概要を見ていきたいと思います。
以下は、その実装に関するコードの概要です。
基本的なコードの流れ
import tensorflow_decision_forests as tfdf
import pandas as pd
# データセットの読み込み
dataset = pd.read_csv("project/dataset.csv")
# TensorFlowデータセットに変換(ラベル列を指定)
tf_dataset = tfdf.keras.pd_dataframe_to_tf_dataset(dataset, label="my_label")
# ランダムフォレストモデルの定義
model = tfdf.keras.RandomForestModel()
# モデルのトレーニング
model.fit(tf_dataset)
# モデルの概要を表示
print(model.summary())
データセットのロード
csvファイルからデータフレームにデータセットを読み込みます。
# Load a dataset into a Pandas Dataframe
dataset_df = pd.read_csv('/kaggle/input/spaceship-titanic/train.csv')
print("Full train dataset shape is {}".format(dataset_df.shape))
データセットの基本的な探索
まず、データセットを読み込み、簡単なデータ探索を行います。
データ探索とはデータ準備の初期段階に欠かせない工程で、データの全体像や概要を確認する工程です。
describe()とinfo()を使用してデータの概要を確認し、カテゴリカルデータの分布や数値データの分布を可視化します。
dataset_df.describe()
dataset_df.info()
# ラベル列「Transported」の棒グラフを作成
plot_df = dataset_df.Transported.value_counts()
plot_df.plot(kind="bar")
# 数値データの分布をヒストグラムで表示
fig, ax = plt.subplots(5,1, figsize=(10, 10))
plt.subplots_adjust(top = 2)
sns.histplot(dataset_df['Age'], color='b', bins=50, ax=ax[0])
sns.histplot(dataset_df['FoodCourt'], color='b', bins=50, ax=ax[1])
sns.histplot(dataset_df['ShoppingMall'], color='b', bins=50, ax=ax[2])
sns.histplot(dataset_df['Spa'], color='b', bins=50, ax=ax[3])
sns.histplot(dataset_df['VRDeck'], color='b', bins=50, ax=ax[4])
ヒストグラムの例を挙げてみましょう。
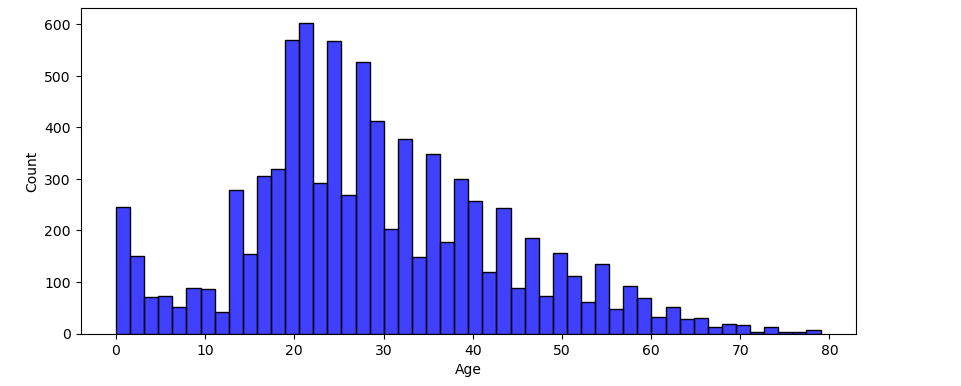
データセットの前処理
次に、データセットの不要な列や欠損値の処理を行います。PassengerIdとName列はモデルのトレーニングに必要ないため削除します。
dataset_df = dataset_df.drop(['PassengerId', 'Name'], axis=1)
また、欠損値の確認と処理を行います。このデータセットには数値、カテゴリカル、ブール型のフィールドが含まれており、ブール型フィールドの欠損値に対しては0で埋めます。これにより、TFDFがサポートしていないブール型フィールドも整数型に変換しています。
dataset_df[['VIP', 'CryoSleep', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']] = dataset_df[['VIP', 'CryoSleep', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']].fillna(value=0)
dataset_df['Transported'] = dataset_df['Transported'].astype(int)
dataset_df['VIP'] = dataset_df['VIP'].astype(int)
dataset_df['CryoSleep'] = dataset_df['CryoSleep'].astype(int)
さらに、Cabin列をDeck、Cabin_num、Sideの3つの新しい列に分割します。
分割した後は、データフレームからCabin列をdropします。
dataset_df[["Deck", "Cabin_num", "Side"]] = dataset_df["Cabin"].str.split("/", expand=True)
dataset_df = dataset_df.drop('Cabin', axis=1)
データセットの分割
データセットをトレーニングデータと検証データに分割します。データの20%を検証用に使用します。
# データセットをトレーニングデータとテストデータに分割する関数
# test_ratio: テストデータの割合(デフォルトでは20%)
def split_dataset(dataset, test_ratio=0.20):
# データセットの各行に対して、ランダムに数値を生成し、test_ratio未満の値であればTrueを返す
# Trueの場合、そのデータはテストデータに含まれる
test_indices = np.random.rand(len(dataset)) < test_ratio
# ~test_indicesはTrue/Falseを反転させたもの
# ここではテストデータに含まれない行がトレーニングデータに、テストデータに含まれる行がテストデータになる
return dataset[~test_indices], dataset[test_indices]
# 関数を使って、データセットをトレーニングデータと検証データに分割する
# train_ds_pdにはトレーニング用のデータ、valid_ds_pdには検証用のデータが格納される
train_ds_pd, valid_ds_pd = split_dataset(dataset_df)
データセットのTensorFlow形式への変換
次に、PandasのデータフレームをTensorFlowのデータセット形式に変換します。これは、高速なデータロードやGPU/TPUの利用に役立ちます。
※ちなみに、Kerasとは、TensorFlowやTheano上で動くニューラルネットワークライブラリの1つです。
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label="Transported")
valid_ds = tfdf.keras.pd_dataframe_to_tf_dataset(valid_ds_pd, label="Transported")
モデルの選択とトレーニング
トレーニング用のデータセットをTensorFlowの形式に変換したので、次にモデルを選択してみましょう。ツリーベースのモデルにはいくつかの選択肢があります。
- RandomForestModel
- GradientBoostedTreesModel
- CartModel
- DistributedGradientBoostedTreesModel
まずは、最も有名で一般的に使われているランダムフォレスト(RandomForest)を使用します。ランダムフォレストは、トレーニングデータセットのランダムなサブセットに基づいて独立した決定木を複数訓練するアルゴリズムです。サンプリングは「置き換えあり」で行われます。このアルゴリズムの特徴は、過学習に強いことと、使いやすいことです。
次に、TensorFlow Decision Forestsで利用可能なモデルを以下のコードで確認できます。
# 利用可能なすべてのモデルをリスト化
tfdf.keras.get_all_models()
以下が出力結果になります。

TFDFには複数のツリーベースのモデルが用意されていますが、今回は最も一般的なランダムフォレストモデルを使用します。
rf = tfdf.keras.RandomForestModel() # ランダムフォレストモデルを作成
rf.compile(metrics=["accuracy"]) # モデルの評価指標として「accuracy(正確度)」を設定
rf.fit(x=train_ds) # トレーニングデータでモデルを訓練
※ランダムフォレスト(Random Forest)とは、「決定木」と「アンサンブル学習(バギング)」という2つの手法を組み合わせたアルゴリズムです。機械学習の「分類」「回帰」といった用途で用いられます。
決定木ベースのモデルの簡単な説明
RandomForestModel
多くの決定木をランダムに構築し、それらの予測を統合して最終予測を行うモデルです。過学習に強く、分類や回帰のタスクに適しています。
GradientBoostedTreesModel
決定木を順番に作成し、前のモデルの誤差を修正するように次の木を訓練していくブースティングの手法です。高い精度が期待できますが、計算コストが高い場合があります。
CartModel
単一の決定木モデルで、データを分割しながら予測を行います。シンプルで解釈が容易ですが、過学習しやすいという欠点があります。
DistributedGradientBoostedTreesModel
分散環境で動作する勾配ブースティングツリーです。大量のデータや並列処理に適しています。
モデルの可視化と評価
上記で、トレーニングデータでモデルを訓練しました。
トレーニング後にランダムフォレストの一部の木を可視化することができます。また、Out of Bag (OOB) データを使った評価や検証データセットでの評価を行います。
# ランダムフォレストの木の可視化
tfdf.model_plotter.plot_model_in_colab(rf, tree_idx=0, max_depth=3)
# OOBデータでの評価
logs = rf.make_inspector().training_logs()
plt.plot([log.num_trees for log in logs], [log.evaluation.accuracy for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Accuracy (out-of-bag)")
plt.show()
# 検証データセットでの評価
evaluation = rf.evaluate(x=valid_ds, return_dict=True)
for name, value in evaluation.items():
print(f"{name}: {value:.4f}")
下記は、ランダムフォレストの木の可視化したサンプルとなります。
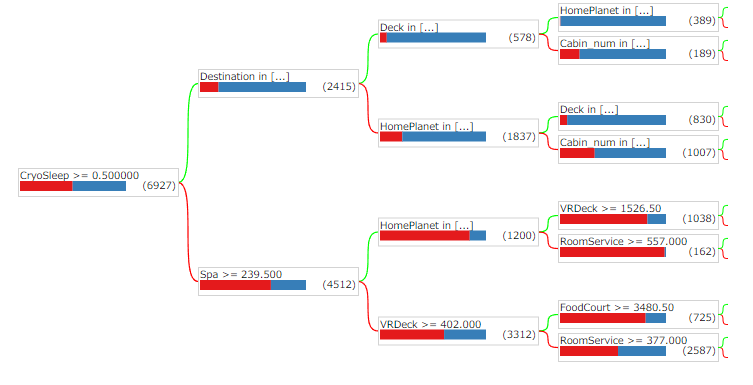
テストデータでの予測と提出
最後に、テストデータを用いて予測を行い、Kaggleに提出してみましょう。
rf.fit(x=train_ds)
上記で、TensorFlow形式のデータセットのトレーニングデータでモデル訓練しました。
下記の
# テストデータに対して予測を実行
predictions = rf.predict(test_ds)
の部分で、テストデータに対してモデル予測を行っています。
# テストデータをCSVファイルから読み込む
test_df = pd.read_csv('/kaggle/input/spaceship-titanic/test.csv')
# 'VIP'と'CryoSleep'列の欠損値を0で埋める
test_df[['VIP', 'CryoSleep']] = test_df[['VIP', 'CryoSleep']].fillna(value=0)
# 'Cabin'列を「Deck」「Cabin_num」「Side」に分割し、新しい列を作成
test_df[["Deck", "Cabin_num", "Side"]] = test_df["Cabin"].str.split("/", expand=True)
# 元の 'Cabin' 列を削除
test_df = test_df.drop('Cabin', axis=1)
# 'VIP' と 'CryoSleep' 列を整数型に変換
test_df['VIP'] = test_df['VIP'].astype(int)
test_df['CryoSleep'] = test_df['CryoSleep'].astype(int)
# PandasデータフレームをTensorFlowデータセット形式に変換
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df)
# テストデータに対して予測を実行
predictions = rf.predict(test_ds)
# predictionsには、モデルが出した予測確率(0から1の範囲)が入っている
# 0.5より大きい場合はTrue(Transportedされた)、0.5以下の場合はFalse(Transportedされていない)に変換
n_predictions = (predictions > 0.5).astype(bool)
# 提出用のデータフレームを作成
# 'PassengerId'はテストデータセットのパッセンジャーIDで、'Transported'は予測結果(TrueまたはFalse)
output = pd.DataFrame({
'PassengerId': submission_id, # テストデータセットから取得した各乗客のID
'Transported': n_predictions.squeeze() # 予測結果をDataFrameに格納(余分な次元がある場合はsqueezeで削除)
})
# 提出用のCSVファイルとして保存
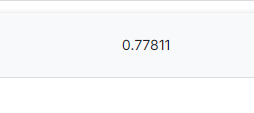
output.to_csv('/kaggle/working/submission.csv', index=False)
これでsubmission.csvをスコアリングすると「0.77811」のスコア値が出ますね。スコアリングですが、kaggleの運営側はもともとy_testの中身を把握しています。今回で言うと、どの乗客がTransportedでどの乗客がTransportedではないかのデータを持っています。その結果のデータと、我々競技者が算出したy_predをもとにしたsubmission.csvを比較してスコアリングしているわけです。
下記のQitta記事は、kaggleの書籍を作られている方が書かれている非常にわかりやすい記事の為、是非ご拝読をおすすめいたします。