TensorFlowで機械学習の勉強を始める
機械学習(マシンラーニング)や深層学習(ディープラーニング)を始めるときに、TensorFlowのチュートリアルが勉強になるのでオススメしたい。
TensorFlowのチュートリアルのページには、以下のようなコードが載っており、実行すると、
「なにかデータを読み込んで、深層学習を始めて、正解率約98%でした」
という一連の流れを5分程度で味わえる。
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
[0.06344309603424045, 0.9801] #答えは一例
このコードだけ見せられても正直よくわからないため、詳しく中身を見ていきたい。
先に結論から
このコードで、モデルデータ、ニューラルネットワーク、活性化関数、過学習、最適化、損失関数といった、
機械学習の「美味しいところを一通り楽しめる」ことがわかった。
TensorFlowとは
"""TensorFlowのimport"""
import tensorflow as tf

TensorFlowは、Googleが開発し無料で使える機械学習用のライブラリである。
例えばNumpyが数値計算に適しているため、最初にimportして使う。
同様に、TensorFlowは機械学習に適したものであるため、これをimportして使う。
Keras、MNISTとは
"""KerasからMNISTを読み出す"""
mnist = tf.keras.datasets.mnist

Kerasは、Pythonの深層学習(ディープラーニング)のライブラリである。
深層学習を行うときに、イチから全部作っていたら大変なので、使いやすいものを用意してある。
TensorFlowのようにimportして使うことも可能だが、
あまりに使い勝手が良いため、tf.kerasとしてTensorFlowの機能として組み込まれている。
tf.kerasのたくさんの機能の一つとして、datasetsがある。
今回使用する手書き数字データベースMNISTを始め、
ファッションデータベースFashion-MNISTや、ボストンの住宅価格回帰データセットといったものが使えるようになっている。

MNISTは、28×28サイズの60,000枚の手書き数字画像と、10,000枚のテスト画像のデータセットであり、
深層学習のニューラルネットワークを学ぶ際によく使われる。
数字のデータをもとに深層学習を行い、テストデータで正解率を求めることが行われる。
MNISTデータの読み込み
"""MNISTデータの読み込み"""
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 #正規化
![x_train[0].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F192073%2Ff156cfeb-1994-c3b9-fde8-a3d9850b866a.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=b477ee00597cf64c2d316dd93d783be4)
mnist.load_data()で中身を訓練データ(x_train, y_train)と、テストデータ(x_test, y_test)に分ける。
xには28×28サイズの手書き数字画像(の0~255輝度値)が、yにはその数字のラベルが入っている。
x_train, x_test = x_train / 255.0, x_test / 255.0 で、データの値の範囲が0~1になるように正規化している。
下記のコードで確認してみると、上のような「5」の画像が得られ、「5」というラベルがprintされる。
import matplotlib.pyplot as plt
plt.imshow(x_train[0], cmap='gray')
plt.colorbar()
# plt.savefig('x_train[0]')
plt.show()
print(y_train[0])
Sequentialモデルとは
"""レイヤーを構築"""
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), #28×28サイズの2次元データを784の1次元データに平滑化する
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
Sequentialモデルについては、以下のDocumentationに書いてあるが、何が何やらという形である。
Getting started with the Keras Sequential model
https://keras.io/getting-started/sequential-model-guide/

引用:https://medium.com/datadriveninvestor/when-not-to-use-neural-networks-89fb50622429
よく、深層学習ではニューロンと同じ構造を持ったニューラルネットワークという言葉をよく聞く。
そのイメージ図がこれで、階層(layer)構造になっていることがわかる。
Sequentialモデルでは、このような階層構造が直列につながっているような状態を表す。
階層をつなげていくことで、複雑な構造を作ることが可能である。
tf.keras.models.Sequential()の中身を見ていく。
最初のtf.keras.layers.Flatten(input_shape=(28, 28))では、28×28サイズの2次元データを784の1次元データに平滑化している。
上のニューラルネットワークの図で、最初の層(Input Layer)は1次元の緑の丸の列になっているので、2次元データを1次元にしている、くらいの感覚で今は考えておけば良い。
2行目のtf.keras.layers.Dense(512, activation=tf.nn.relu)では、二層目のHidden Layerを定義しており、
図のように前後のレイヤーと、全てのネットワークでつながっている。
ここで重要なのが、活性化関数である。
全てのネットワークから受け取った情報が有益か、否か、ふるいにかける機能を持っている。
活性化関数の選び方で、ニューラルネットワークの良し悪しが決まると言っても過言ではない。
活性化関数には、様々な種類がある。
中でもかなり優秀な活性化関数として知られるのが、ReLU、通称ランプ関数である。

ランプ関数(引用:wikipedia)
ランプ関数は、xが正の場合はy=xを、xが負の場合は0を示す。
そのため、ニューラルネットワークでは、重要なものを重み付けし、さほど重要でないと判断したものは無視しようというのがランプ関数である。
このランプ関数を、activation=tf.nn.reluで指定しているのが2行目である。
3行目のtf.keras.layers.Dropout(0.2)では、過学習を防ぐためのドロップアウト率を指定している。
過学習とは、機械学習において、訓練データに対して適応しているが、未知のデータに対して適合できていない状態をいう。
訓練データに対する正解率がいくら良くても、テストデータに対する精度が高くならなければ、それはニューラルネットワークとしては問題である。
この過学習を防ぐために、ランダムでいくつかのニューロンを無効にしようというのがドロップアウトである。
過学習を抑えるためモデルを簡単にするといった方法もある。
4行目のtf.keras.layers.Dense(10, activation=tf.nn.softmax)では、2行目と同じように活性化関数を指定している。
ここでは、ソフトプラス$f(x) = log(1+exp(x))$を使用している。
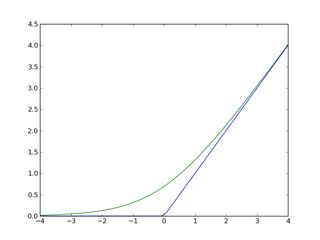
青がReLU(ランプ関数)、緑がソフトプラス(引用:wikipedia)
図のようにランプ関数と、ソフトプラスは本質的には似ていることがわかる。
このように複数ある活性化関数を適切に選択することによって、正解率を高めていく。
選んだレイヤーが良さそうと思ったら、次の訓練プロセスの定義に進む。
Compileとは
"""訓練プロセスの定義"""
model.compile(optimizer='adam', #どうやって学習を最適化するかを決定
loss='sparse_categorical_crossentropy', #どうやって損失を定義するかを決定
metrics=['accuracy']) #メトリックはとりあえずaccuracyを選んでおけば良い
訓練プロセスの定義とは、機械学習の学習方法を決定する工程のことを言う。
先のSequentialで、レイヤー、つまり学習する順番を決定したので、
実際の学習の仕方を細かく決める必要がある。
本来であれば、非常に細かくパラメータをいじって最適な学習をしなければならないが、
Kerasでは、いわゆる「オススメの設定」が組み込まれている。
Optimizerはその名の通り、最適化手法を決定する。
学習を繰り返して最適化を行っていくうえで、より速く、より正確な学習を行うことが求められる。
以下の記事でOptimizerについて、非常に丁寧にまとめられているので参考にしたい。
Optimizer : 深層学習における勾配法について
複数あるOptimizerの中で、とりあえず選んでおけば安心というのがoptimizer='adam'である。
詳細は省くが、他のOptimizerの美味しいところをかいつまんだものだと考えておけばよい。
Lossもその名の通り、損失関数を決定する。
損失関数とは、ニューラルネットワークが教師データに対してどれだけ適合していないかを算出する関数であり、
ニューラルネットワークの性能の悪さを示す指標である。
イメージとしては、関数でフィッティングしたときの$R^2値$がそれに近い。
$R^2値$は1に近い方が良いが、損失関数は0に近いほうが良い。
Lossも複数あるが、必ずしもこれといったものは難しい。
ここでは、使用しているloss='sparse_categorical_crossentropy'について考える。
突然ではあるが、スパースのついていないcategorical_crossentropyと大差ないので、ここはスパースを割愛し、
クロスエントロピー(交差エントロピー)は、「交差エントロピーを理解してみる」がわかりやすいので参考にされたい。
要点だけを引用すると
損失関数といえば二乗誤差が有名ですが、分類問題を扱う際には交差エントロピーが頻繁に使われます。
教師データと学習結果が大きく乖離している(損失関数の値が大きい)時、交差エントロピーを使った方が学習スピードが早い!!(1学習あたりの損失関数の減少幅が大きい)
損失関数はできるだけ速く0に近づいてほしいため、ある程度の振り幅を持って一気に損失を小さくできるのが特徴である。
metrics=['accuracy']について、メトリックは、モデルのパフォーマンスを判断するために使用される関数である。
ここは、何も考えずにmetrics=['accuracy']を選んでおけばいい。
学習・評価する
"""学習・評価する"""
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
これまでモデル、レイヤー、訓練内容を決定してきたので、実際に訓練を行い、テストデータで評価を行う。
1行目のエポック数とは「一つの訓練データを何回繰り返して学習させるか」の回数を示す。
model.fit(x_train, y_train, epochs=5)のように、訓練データと、エポック数を指定するだけで訓練を開始する。
訓練の過程を表示してみる。
"""訓練の過程を表示する"""
import matplotlib.pyplot as plt
history = model.fit(x_train, y_train, epochs=5)
plt.plot(history.history['acc'])
plt.title('accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train'], loc='upper left')
plt.show()

1エポック目から、非常に制度の良い学習ができていることがわかる。
model.evaluate(x_test, y_test)で、テストデータに対する精度を評価する。
結果は、損失は0.06程度でかなり0に近く、正解率も約98%が返される。
まとめ
TensorFlowのチュートリアルに基づき、機械学習の基礎の基礎を解説した。
このチュートリアルに記載されているコードは、「洗練された機械学習を気軽に勉強できる」と言える。
美味しいところだけを味わえるフレンチのコースがこんなにお安くいただけるなんて、というのが正直な感想。
何より、TensorFlow、Kerasといった素晴らしいライブラリがあるのが心強い。
もちろん、いい食材(データセット)があって、いい調理法(活性化関数など)があってのことである。
しかし、これらの各要素がわかっているだけで、十分データサイエンティストのスタートに立てると考えている。
記事は以上となりますが、もしよかったら「いいね!」をお願いします!
参考&良記事の紹介
なぜKerasを使うか?
https://keras.io/ja/why-use-keras/
Kerasの使い方をざっくりと
http://marupeke296.com/IKDADV_DL_No2_Keras.html
KerasでDeep Learning:KerasでMNISTデータを扱ってみる
http://tekenuko.hatenablog.com/entry/2017/07/05/212205
【Deep Learning】過学習とDropoutについて
http://sonickun.hatenablog.com/entry/2016/07/18/191656
Keras / Tensorflowで始めるディープラーニング入門
https://qiita.com/yampy/items/706d44417c433e68db0d
Kerasのオプティマイザの比較
http://bluewidz.blogspot.com/2017/09/keras.html
機械学習で抑えておくべき損失関数(回帰編)
https://www.hellocybernetics.tech/entry/2017/06/19/084210
How to Use Metrics for Deep Learning with Keras in Python
https://machinelearningmastery.com/custom-metrics-deep-learning-keras-python/