jdepp-python 0.1.7がGoogle Colaboratoryに対応した、とのご連絡をいただいたので、jagger-pythonとともに日本語形態素解析・二文節間係り受け解析に挑戦してみた。
!pip install jagger jdepp
!test -d model/kwdlc || curl -L https://github.com/lighttransport/jagger-python/releases/download/v0.1.0/model_kwdlc.tar.gz | tar xzf -
!test -d model/knbc || curl -L https://github.com/lighttransport/jdepp-python/releases/download/v0.1.0/knbc-mecab-jumandic-2ndpoly.tar.gz | tar xzf -
import jagger,jdepp
tagger=jagger.Jagger()
tagger.load_model("model/kwdlc/patterns")
parser=jdepp.Jdepp()
parser.load_model("model/knbc")
nlp=lambda x:parser.parse_from_postagged("\n".join(t.surface()+"\t"+t.feature() for t in tagger.tokenize(x))+"\nEOS\n")
doc=nlp("吾輩はここで始めて人間というものを見た")
print(doc)
import graphviz
graphviz.Source(jdepp.to_dot(str(doc)))
「吾輩はここで始めて人間というものを見た」を係り受け解析してみたところ、私(安岡孝一)の手元では以下の結果が得られた。
# S-ID: 1; J.DepP
* 0 6D
吾輩 名詞,普通名詞,*,*,吾輩,わがはい,代表表記:我が輩/わがはい カテゴリ:人
は 助詞,副助詞,*,*,は,は,*
* 1 2D
ここ 指示詞,名詞形態指示詞,*,*,ここ,ここ,*
で 助詞,格助詞,*,*,で,で,*
* 2 6D
始めて 動詞,*,母音動詞,タ系連用テ形,始める,はじめて,*
* 3 4D
人間 名詞,普通名詞,*,*,人間,にんげん,*
と 助詞,格助詞,*,*,と,と,*
* 4 5D
いう 動詞,*,子音動詞ワ行,基本形,いう,いう,*
* 5 6D
もの 名詞,形式名詞,*,*,もの,もの,*
を 助詞,格助詞,*,*,を,を,*
* 6 -1D
見た 動詞,*,母音動詞,タ形,見る,みた,*
EOS
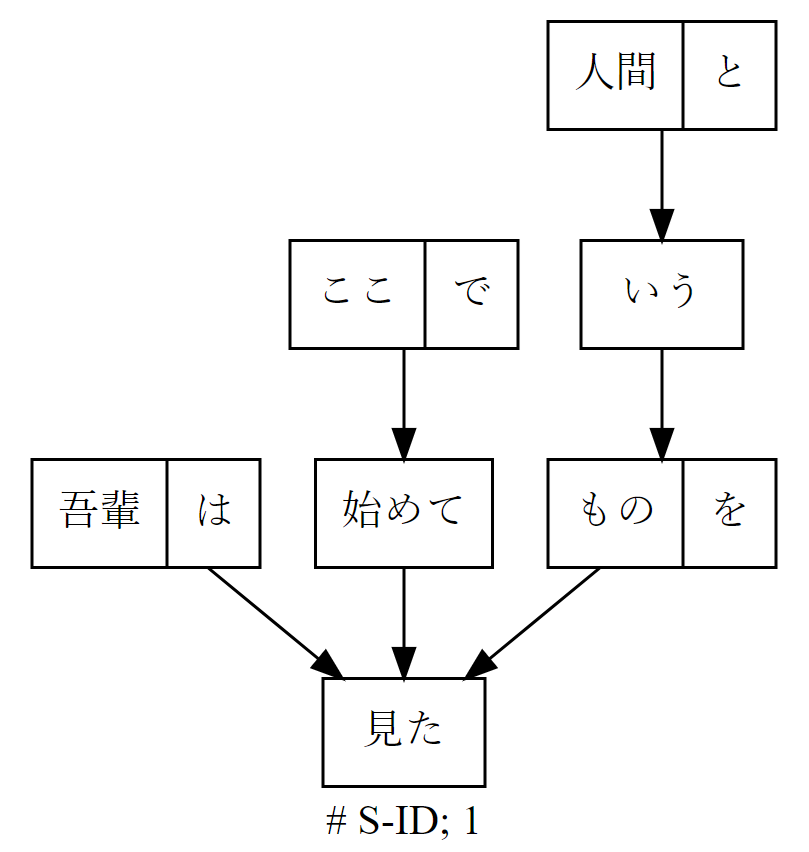
jdepp-pythonでは「人間という」が二文節となっている。ja-ginza-bert-largeでは「人間という」が一文節だったので、その部分が異なっているものの、まあ、文節係り受けとしてはイイ線だと思う。この文は、CaboChaが解析できないタイプの文なので、jdepp-pythonやja-ginza-bert-largeへの移行を、ぜひ考えてほしい。