日本語係り受け解析モジュールGiNZA 5.1.3には、ja-ginza-bert-largeのβ版が付いてきている。β版とはいえ、かなりの解析精度らしいので、Google Colaboratoryで動かしてみることにした。
!pip install deplacy https://github.com/megagonlabs/ginza/releases/download/v5.1.3/ja_ginza_bert_large-5.1.3b1-py3-none-any.whl
import spacy
nlp=spacy.load("ja_ginza_bert_large")
doc=nlp("吾輩はここで始めて人間というものを見た")
import deplacy
deplacy.serve(doc,port=None)
from ginza import bunsetu_span,bunsetu_spans
from deplacy.deprelja import deprelja
d=bunsetu_spans(doc)
g="digraph{"+";".join([f'x{b.start}[label="{b.text}"]' for b in d]+[f'x{bunsetu_span(t).start}->x{b.start}[label="{deprelja[t.dep_]}",fontsize=9]' for b in d for t in b.lefts])+"}"
import graphviz
graphviz.Source(g)
「吾輩はここで始めて人間というものを見た」を係り受け解析してみたところ、私(安岡孝一)の手元では以下の結果が得られた。
1 吾輩 吾輩 PRON 代名詞 Reading=ワガハイ 12 nsubj _ SpaceAfter=No|Translit=我が輩
2 は は ADP 助詞-係助詞 Reading=ハ 1 case _ SpaceAfter=No
3 ここ ここ PRON 代名詞 Reading=ココ 5 obl _ SpaceAfter=No|Translit=此処
4 で で ADP 助詞-格助詞 Reading=デ 3 case _ SpaceAfter=No
5 始め 始める VERB 動詞-非自立可能 Inflection=下一段-マ行;連用形-一般|Reading=ハジメ 12 advcl _ SpaceAfter=No|Translit=始める
6 て て SCONJ 助詞-接続助詞 Reading=テ 5 mark _ SpaceAfter=No
7 人間 人間 NOUN 名詞-普通名詞-一般 Reading=ニンゲン 10 nmod _ NE=B-Mammal|SpaceAfter=No
8 と と ADP 助詞-格助詞 Reading=ト 7 case _ SpaceAfter=No
9 いう いう VERB 動詞-一般 Inflection=五段-ワア行;連体形-一般|Reading=イウ 8 fixed _ SpaceAfter=No|Translit=言う
10 もの もの NOUN 名詞-普通名詞-サ変可能 Reading=モノ 12 obj _ SpaceAfter=No|Translit=物
11 を を ADP 助詞-格助詞 Reading=ヲ 10 case _ SpaceAfter=No
12 見 見る VERB 動詞-非自立可能 Inflection=上一段-マ行;連用形-一般|Reading=ミ 0 ROOT _ SpaceAfter=No|Translit=見る
13 た た AUX 助動詞 Inflection=助動詞-タ;終止形-一般|Reading=タ 12 aux _ SpaceAfter=No

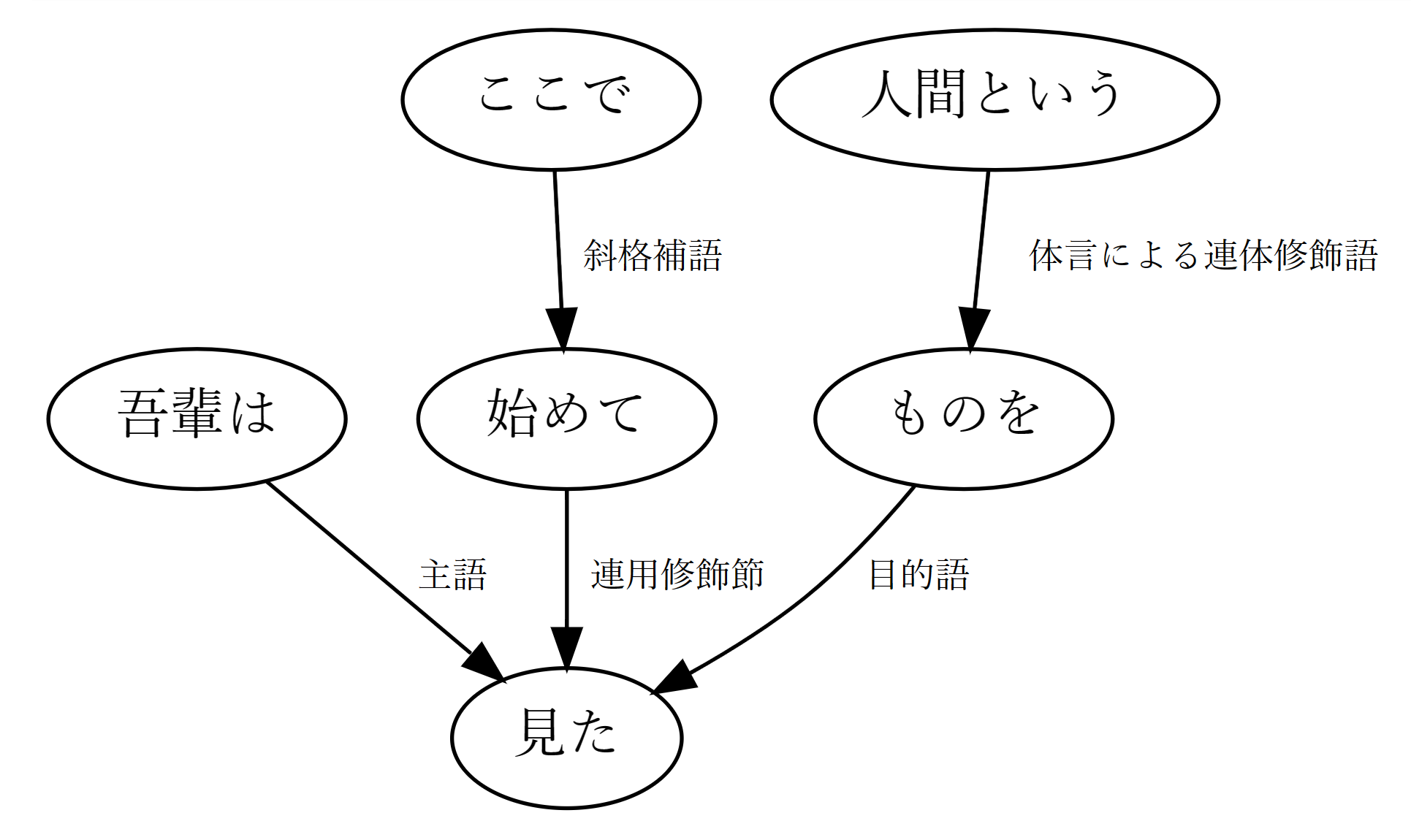
単語間係り受けも二文節間係り受けも、ちゃんと解析できている。この文は、CaboChaが解析できないタイプの文なので、素直にうれしい。ja-ginza-bert-largeが、早く正式リリースされるといいな。