機械学習の基本的な部分を学ぶにあたって、KaggleのTitanicコンペに取り組みました。
いくつかのモデルを作成したので、そのまとめを書き置きます。
事前処理
- データの読み込み
- ダミー変数化
- 学習用と評価用にデータを分割 …など
import pandas as pd
train= pd.read_csv('./titanic/train.csv')
# 変数の処理など良い感じにいろいろ処理
def preprocessing(data):
df = data.dropna() #例:欠損値の処理とか
df = pd.get_dummies(df, drop_first=True) #例:カテゴリ変数をダミー変数化とか
return df
train = preprocessing(train)
from sklearn.model_selection import train_test_split
x = train.drop("Survived", axis=1).values
y = train["Survived"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)
決定木
概要
図のようにある条件下でYes/Noで分岐していく。
各質問を通して、不純度を減らしていく
例:

引用:[入門]初心者の初心者による初心者のための決定木分析←おススメ!
実装
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(max_depth=5,
min_samples_leaf=5,
random_state=0)
clf.fit(x_train,y_train) #学習
clf.score(x_test, y_test) #モデルの評価
勾配ブ―スティング
概要
複数の決定木を直列につないだような形で、誤差を修正していく方法
例:
決定木 -(誤差を修正)→ 決定木 -(誤差を修正)→ … →最終的な答え
| 弱学習機の並び | 直列 |
| 採用するデータ | 復元抽出 |
| 採用する変数 | 変化しない |
| メリット | あまりパラメータをいじらなくてもそれなりの精度が出る |
| デメリット | 学習に時間がかかる |
実装
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import GridSearchCV
# GridSearchCVを使うと最適なパラメータがどれか、自動で探すことができる
param_grid = {'max_depth':[None, 5, 10, 20], #ノードの深さの制限値
'n_estimators':[20, 50, 100], #決定木の数
'learning_rate':[0.01, 0.03, 0.05]} #決定木を作るときの学習率
clf = GridSearchCV(estimator=GradientBoostingClassifier(random_state=0),
param_grid = param_grid,
scoring = 'accuracy',
cv = 5 #公差検証
)
clf.fit(x_train,y_train) #学習
clf.score(x_test, y_test) #モデルの評価
clf.best_params_ #最適なパラメータがどうだったか
ランダムフォレスト
概要
複数の決定木を並列につないだような形で、それらの決定木で出た答えで多数決をとる
例:
決定木A(答え=3) 決定木B(答え=4) 決定木C(答え=7)
ランダムフォレストで出した答え→4.7
| 弱学習機の並び | 並列 |
| 採用するデータ | 復元抽出 |
| 採用する変数 | ランダム |
| メリット | データ量が多くても高速に動く |
| デメリット | 説明変数をランダムに抽出するためデータと変数が少ないとうまく機能しない |
実装
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# GridSearchCVを使うと最適なパラメータがどれか、自動で探すことができる
param_grid = {'max_depth':[None, 5, 10, 20], #ノードの深さの制限値
'n_estimators':[20, 50, 100]} #決定木の数
clf = GridSearchCV(estimator=RandomForestClassifier(random_state=0),
param_grid = param_grid,
scoring = 'accuracy',
cv = 5) #公差検証
clf.fit(x_train,y_train) #学習
clf.score(x_test, y_test) #モデルの評価
clf.best_params_ #最適なパラメータがどうだったか
ニューラルネットワーク
概要
ニューラルネットワークは生物の神経細胞を真似してる
シンプルな機能を持つニューロンが層を形成し、層の間で接続が行われることでニューラルネットワークが作られる
-
ニューロンは、複数の入力から一つの出力を出す
-
【それぞれ重みをかけたもの総和+バイアス(ニューロンの感度)】を活性化関数で処理する
-
活性化関数は、ニューロンが発火するかどうかの信号に変換する関数
└ 活性化関数には「シグモイド関数」などがある -
ニューラルネットワークは複数の入力と複数の出力があり、多数のパラメータを調整することで多様な表現ができる
- CNN(画像などでよく使う)、RNN(文章、音声などの時系列データが得意)
-
学習:逆伝播、予測:順伝播
ニューロン:
 引用:[【レクチャー: 単一ニューロンの計算】AIパーフェクトマスター講座](https://www.youtube.com/watch?v=qU9sMN_TMjc)
引用:[【レクチャー: 単一ニューロンの計算】AIパーフェクトマスター講座](https://www.youtube.com/watch?v=qU9sMN_TMjc)
ニューラルネットワーク:
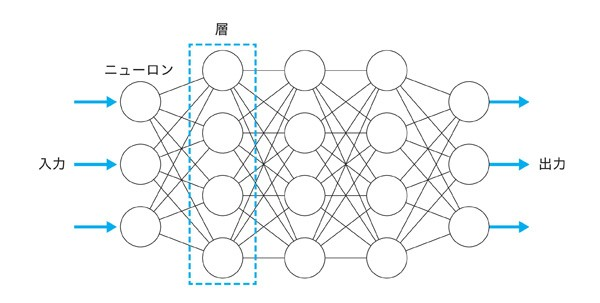 引用:[ディープラーニングと脳の関係とは? 人工ニューロンや再帰型ニューラルネットワークを解説](https://codezine.jp/article/detail/13501)
引用:[ディープラーニングと脳の関係とは? 人工ニューロンや再帰型ニューラルネットワークを解説](https://codezine.jp/article/detail/13501)
実装
from sklearn.neural_network import MLPClassifier
clf = MLPClassifier(hidden_layer_sizes=(100,100,100),
random_state=0)
clf.fit(x_train,y_train) #学習
clf.score(x_test, y_test) #モデルの評価
事後処理
モデルの評価と結果の保存
# 評価
import sklearn.metrics as sk
from sklearn.metrics import confusion_matrix
y_pred = clf.predict(x_test)
confusion_matrix(y_true=y_test, y_pred=y_pred)
'正解率:{}'.format(sk.accuracy_score(y_true=y_test, y_pred=y_pred))
'適合率:{}'.format(sk.precision_score(y_true=y_test, y_pred=y_pred))
'再現率:{}'.format(sk.recall_score(y_true=y_test, y_pred=y_pred))
'F1スコア:{}'.format(sk.f1_score(y_true=y_test, y_pred=y_pred))
# モデルを使って予測を出力する
test = preprocessing(test)
result = clf.predict(test)
result.to_csv('./submission.csv', encoding='UTF-8', header=True, index=True)