初回の記事『Kaggle画像コンペでやっていること①』では、どんなコンペでも大体やることをあげさせていただき、『Kaggle画像コンペでやっていること②』以降では、ドメインを考えることに関する話をしてきました。
kaggle advent calender 2024の24日目の記事は、画像コンペで適用ドメインを考えて独自モデルやアーキテクチャを考えるお話になります。数回にわけて書かせていただいており、基本的に初級者(Expertぐらい)向けですのでご了承ください。
8日目:Kaggle画像コンペでやっていること① (タスク関係なくやること)
14日目:Kaggle画像コンペでやっていること② (特徴量まわり)
21日目:Kaggle画像コンペでやっていること③ (Loss, Augmentationまわり)
24日目:本記事
前回記事の振り返り 
- 深層学習で解こうとしているタスク固有の特徴を考えたい
- 自分にとってのあたりまえも、深層学習モデルにとってのあたりまえではない
- うまく効かせると精度があがるしカッコいい
- いろんな活かし方がある
- 特徴量エンジニアリング【済】
- タスク特化のLoss【済】
- タスク特化のAugmentation選定や作成【済】
- タスク特化のモデルアーキテクチャ (←本ページで紹介)
- タスク特化のパイプライン (←本ページで紹介)
ドメイン意識④:タスク特化のモデルを考える
既存モデルが建売住居なら、そのタスク(コンペ)専用デザインモデルはさながらセミオーダ住居です。というのは適当ですが、コンペの短い期間でドンピシャのデザインをすることは中々難しく、決まればロマンがあります。
タスク固有のルールをLossやAugmentationではなく、モデル自体の特性として埋め込むような枠組みを作ることになると思います。任意のモデル構造を組めることが前提として求められるので、要求されるスキルは高くなりますが、うまく作用したときの効果は抜群です![]()
いくつか例を紹介します。
■ タスク専用モデルの例:単眼デプス推定
論文ではたくさんのタスク専用モデルが提案されています。
個人的に好きなものの1つが動画からの単眼デプス推定モデルです。単眼デプス推定では様々な『当たり前(事前知識)』をモデルに組み込む必要があり、かなり複雑なモデル構造になりがちです。
たとえば以下のような事前知識がモデルに反映されています。
| 事前知識 | モデルへの反映方法 |
|---|---|
| 物体の見た目(色)は基本的に維持される | 色の一貫性をLossとして学習できる仕組み |
| 遮蔽物がある場合、次の瞬間にはモノが隠れる/現れることもある | 遮蔽物の影響をロスに反映 (隠れた部分は学習対象外にするなど) |
| カメラ自体のモーションと車や人などの動体による見た目の変化がある(人はそれを脳内で補完できる) | カメラのモーションとオブジェクトモーションを個別に推定 |
| フレームを送る場合と戻す場合でモーションは反転する | モーションの一貫性をLossとして学習できる仕組み |
それほど新しい論文ではありませんが2020年末のUnsupervised Monocular Depth Learning in Dynamic Scenes では下図のような複雑な構成をend to endで学習するモデルになっています。
画像フレーム間推論を用いたconsistency系アプローチは比較的一般的な手法ではあるものの、このモデル構造1つとっても上述のような様々な常識をうまく反映できていることがわかります。
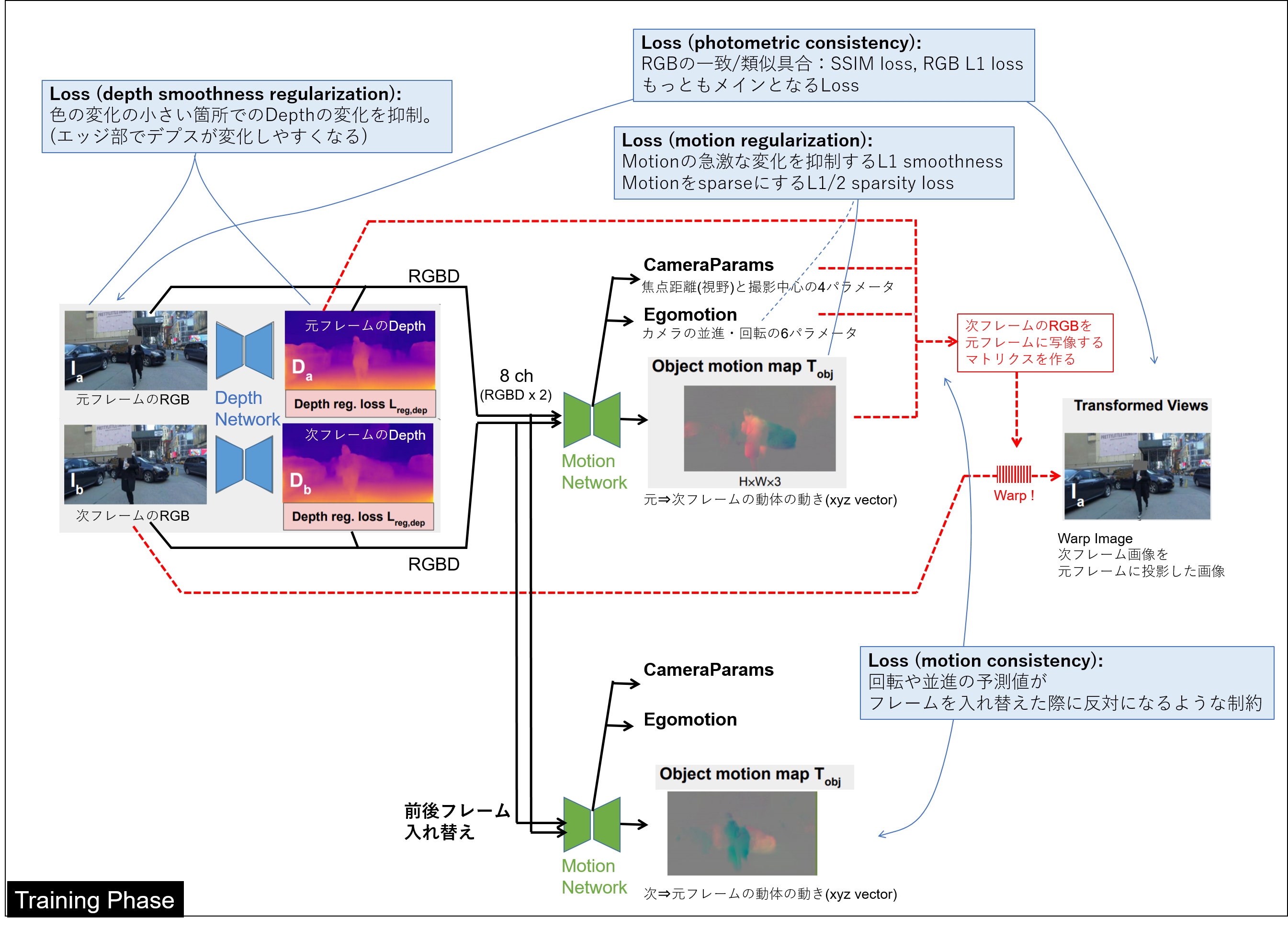
過去に実装してみたことがありますが、デプス推定モデルの予測結果とモーション推定モデルの予測結果の両方を用いて最終的なLossを立てるところもあり、かなり学習がしにくいモデルです。仮にこういったモデルをコンペにおいて作ることができたとしても、これを正しく機能させるためには高いテクニックと強い意思が必要だと思います。
■ タスク専用モデルの例:NFLプレイヤ間の衝突予測
こちらは手前みそで恐縮ですが、自身のコンペソリューション話です。
みなさんは人と人がぶつかったかどうかを判定するときにどこを注視するでしょうか?

その特定の二人の間ですよね。たったそれだけの話ですが、複数人が写っている写真でNNモデルに特定の二人の接触だけを意識させることは簡単なようで難しいです。
▶ NNの気持ちになって難しさを考える
もし自分がNNで、上司がトレーナだとすると、雑なトレーニングは
何枚かの写真を見させられて
トレーナ「これは正例、こっちは負例。わかったよね」
という状況です。なにも事前知識を付与していないモデルというのはきっとそんな気持ちです。パワハラです。とはいえ、事前知識の与え方も簡単ではありません。
上司「人と人がぶつかったかどうかだよ」
自分「え、どの人の話ですか…?」
モデル構築においてはそういったモデルの理解を妨げる要因を可能な限り排除し、学習の補助ができるといいんじゃないかと思います。
▶ プレイヤー間接触をモデルへ反映する
| 事前知識 | モデルへの反映方法 |
|---|---|
| 接触は特定の二人のプレイヤ間で発生する | 二人のプレイヤを明示的に入力として与える |
| 二人のプレイヤ同士が近づいている部分で接触が発生する | 二人のプレイヤの交差領域から推論をおこなうようにする |
これらを踏まえ、『各プレイヤの存在領域と全接触領域を予測し、複数のプレイヤ領域の交差領域を見つけるモデル』としました。下図のように、プレイヤA領域 & プレイヤB領域 & コンタクト領域 > 0のようなコンセプトで衝突が定義できます。
正解ラベルとして与えられているのは各プレイヤの領域でも接触箇所でもなく、接触の有無だけですが、「交差領域から学習すればいい」という情報をキッチリとモデルに組み込むことができたので、学習がグッと進みやすくなりました。任意のプレイヤ間での接触を効率的に(短時間で)予測する点でも、演算量が少なく便利でした。
また、弱教師あり学習のように、学習後は接触箇所まで推論できるようになったことも興味深かったです。


非常に細かいですが、2人のプレイヤーAとBのコンタクト有無=BとAのコンタクト有無なので、そのあたりの対称性もモデルとして組み込まれていると自然だと思います。例えば
非対称:Concat(A_features, B_features) ≠ Concat(B_features, A_features)
対称:Multiply(A_features, B_features) == Multiply(B_features, A_features)
これ以外にもいろいろな方法がありますが、今回の例では対称性がある方が自然に学習できそうな気がします。
タスク専用モデルの良さ
個人的にはモデルこねこねは好きです。
- NNをコネコネしている感があり、難しいけれどパズルのようで楽しい
- 勝ったときにちょっと自慢しやすい
- うまくいくと非常に強い差別化になるけれど、うまくいかない or うまく機能させられないことが多い
- アイデアと心中する覚悟がある人にオススメ
ドメインを意識したマルチステージなパイプラインをつくる
あらゆるモデルを組み合わせることで常識(ドメイン知識)を押し付けることができます。「モデル一本だけで予測が難しいな」というシーンでは多くのケースでマルチステージの予測がおこなわれます。
難しさも色々ありますが、よくあるものですと:
- 3Dや動画など、model1つではメモリに乗りきらないとき
- そもそも予測や学習が難しいタスクを扱うとき:
- 情報が疎で学習しにくいとき (画像のごくごく一部が予測に重要なとき)
- 入力からラベルが遠いとき (風が吹けば桶屋が儲かるとき)
色々な手法を組み合わせるようなものになるので最低限のテクニックが必要になりますが、2つぐらいはササっと組めないと勝てないコンペもよくあります。
■ RSNA2024コンペにおけるマルチステージ
画像コンペでもっともベーシックな組み合わせは、検出&分類の2stage構成かと思います。RSNA2024コンペではMRI(3D画像)からの診断をおこなうコンペでした。
最もシンプルなアプローチは、何十層もの画像を入力として分類モデルを構築することですが、分類器一本でそれを学習させるのは極めて難しいです。
自分が医師に画像群を渡されて、「これは正例です」と言われた状況を想像しましょう。「なんのこと…?」となると思います。
何重もの層になっている画像から、一部分に着目して症状を判断する場合、最も基本的なアプローチが検出器との組み合わせで、特に検出器+分類器の2stageはよくあるアプローチです。RSNA2024でも、大まかな場所を特定してから症状を分類するようなソリューションが多くみられました。
(下図はyumenekoさんのまとめ記事より引用)

■ DFLコンペにおけるマルチステージ
下図は私自身が過去に取り組んだコンペの中でもかなりゴリ押しのソリューション(DFL 2nd place)で、知っているものをとりあえずすべて詰め込んだみたいなものになっています。コンペはサッカーのイベント判定のタスクですが、与えられたデータがサッカーフィールド全体をとらえた画像なので、1stageでは予測が困難でした。

自分がホストならこんな扱いにくい解法をもらいたくないですね
サッカーのイベント判定に関わる様々な事前知識を埋め込もうとしています。『私ならこの情報をもとに判断するんだからそこを見てほしい』という強い想いがこもっています。
| 事前知識 | 使用したモデル |
|---|---|
| サッカーのイベントはボール周辺で発生する | ボールの物体検出器 |
| ボールや人などの動体が重要 | 検出の前にオプティカルフロー予測モデルの前処理 |
| ボールは急に無くならない(ワープしない) | ボールの過度な動き(コスト)を最小化するダイクストラ法 |
| サッカーのイベントはボールの動きやプレイヤの動きから判断できる | ボールの動きと人の動きを考慮した(2D+1D) NN |
| サッカーのイベントはある程度の時間長さをもって判定できる(パスなのかシュートなのか等) | 長い時間を考慮できるセカンドステージ(1D CNN) |
このように複数のモデルでステージを組んで学習させることで、より意図をもたせた学習をさせることができます。Kaggleをはじめたてのころには手札が少ないと思いますが、続けている内に1D,2D,分類,検出,画像,言語,テーブルと色んなテクニックが身についてきますので、自分の意志をモデル構成で実現する方法が増えてくると思います。
マルチステージの効果
実装や実験効率などの点で、かなり手間がかかってしまいますが、メリットもたくさんあります!
- 効くときはとても効く
- 公開ベースラインがシンプルなsingle stageしかないことも多く、コンペ次第ではこれだけで銀圏付近が確定する
- 1つ目のモデルに飽きたら2つ目のモデルで遊べばいい。1つのコンペで2倍楽しい気がする
- レゴのようにモデルを組みあげるのは楽しく、とても頑張っている感(充実感)がある
負担が大きい分、効かなかったときや失敗したときの残念感もやや大きいですが、やっていて楽しいです。
マルチステージの注意点
✅ 学習に失敗(リーク)しやすい
1st stageのvalidationを2nd stageに渡して…、これを3rdに渡して…みたいなことをやっているとすぐに予測値でリークしてしまいます。妙に高い精度を疑うのはもちろんですが、最初は安全気味につくることをおススメします。
最初っから精度を出す必要はなく、「2stageにすべきかどうかを見極める」ぐらいの気持ちでもいいと思います。個人的には2foldに切って、片方をテストデータとして確保するぐらいの方が安全で実験効率も良くて好きです。全データを使用せずに1stサブで上位をとれていると、心の中でドヤれます![]()
✅ モデルの可能性を狭めることがある
よく例としてあげているのですが、崩し字コンペでは、下手な検出&分類の2stageが裏目に出ました。
コンペでは崩し字の翻刻が求められていたのですが、当時私はこれを検出&分類の2stageで解きました。分類ステージで様々なAugmentationを加えることで精度が高められると思っていました。
ですが上位解法は文字単位の分類をおこなわないものも多く、その理由が「文字の連なりを見ることで各文字の翻刻の精度があがるから」というものでした。「切り取って予測すべき」という私自身の事前知識をモデルに強制した結果、文脈を見るというモデルの可能性を狭めてしまったのだなと、とても勉強になりました。

上で挙げたサッカーのコンペの場合ですと、ボールが見えなくともカメラの動きからイベントが推定できる(できてしまう)ことがあります。スコアを狙う場合には、むやみにカメラモーションを除外すべきではないかもしれません。まぁ、ホストが喜ぶかどうかはおいといて。
✅ フットワークが低下する
基本的にごちゃつきます。手がかかります。
- 学習も推論も実験効率も低下します
- 検討自体も時間がかかるのでコンペ終盤には手が出ません
- (入賞時の提出物も地味に手間取ります)
細かいところを作りこんでいない序盤に、シンプルにスモールに取り組んで方向性を固めることと、上述したように少ないデータでサクサク実験を回すことがおすすめです。
結局のところ、シンプルにsingle stageでできるのであればそれが一番いいのではないかと思います。シンプルで強いが最強です。「シンプルには解けそうにないぞ…」ってときにレゴブロックを組み立てていくといいのではないかと思います。
まとめ
ということで最終回はドメインを考える話の3回目として、モデル・アーキテクチャづくりの話をさせていただきました。どんなデータ・モデルでも対応できるようになってくると世界が広がって楽しさも倍増です。基盤モデルの時代にそぐわない内容かもしれませんが、ぜひ皆さんにも体感してもらいたいです。
ということで、年の瀬に画像コンペ記事を4本投稿してみました。
私なりに画像コンペでやっていることをザックリ公開してみたつもりです。もちろんこれ以外も色々なことをやっていますが、代表的な部分は5,6割ぐらいは記述したと思います。
- 面白かった人:少しでもお役にたててよかったです!珈琲でもおごってください

- 勉強にならなかった人:スイマセン。こんな話も聞きたかったなどあればぜひ教えてください
![]()