モチベーション
動画(2D画像)を3Dにできれば素敵だと思いませんか?
ロボティクスや自動運転に使うもよし。ムフフな動画を3次元で満喫するもよし。
夢とか色々膨らみます。
はじめに。この記事の内容は?
本稿では2020年に提案された自己教師有りの単眼デプス&モーション推定手法であるUnsupervised Monocular Depth Learning in Dynamic Scenes (https://arxiv.org/abs/2010.16404) を紹介します。
平たく言うと、ごく普通の(2D)動画から、正解データを人が準備することなく、3D(Depth)と物体のモーションを推定する深層学習の手法です。

まとめ
- 普通の2D動画だけで、デプスとモーションを学習できる。すごい。
- カメラの特性(視野角など)もわからなくてOK。まとめて推定してしまう。すごい。
- カメラ自身はもちろん、撮影対象が動いていてもいい。グローバルなモーション(カメラの動き)と、撮影対象の動作を別個に推定することができる。すごい。
- 学習が難しい。不適切な局所最適をかわしてゴールを決める学習テクを要する。
そもそも自己教師あり学習とは?
データ自身から正解データを生成し、人によるラベリングやアノテーションをおこなわない魅力的な手法です。既にすばらしい記事がありますので、詳しくは別の記事をご参考ください。
https://qiita.com/omiita/items/a7429ec42e4eef4b6a4d
今回紹介する手法は、連続するフレームの画像を用いることで、1つ目のフレームの画像から2つ目のフレームの画像(正解)を推定する問題を解かせ、その過程で対象画像の3D座標(xyz)とモーションを予測させようというアプローチです。
モデル概要 (推論時)
繰り返しますが、本手法は『連続するフレームの画像を用いることで、1つ目のフレームの画像から2つ目のフレームの画像(正解)を推定する問題を解かせ、その過程で対象画像の3D座標(xyz)とモーションを予測する』ことを目的とします。
学習フェーズは少し複雑なので、まずはわかりやすい推論モデルを見てみます。
全体の構成は下図のようになります。
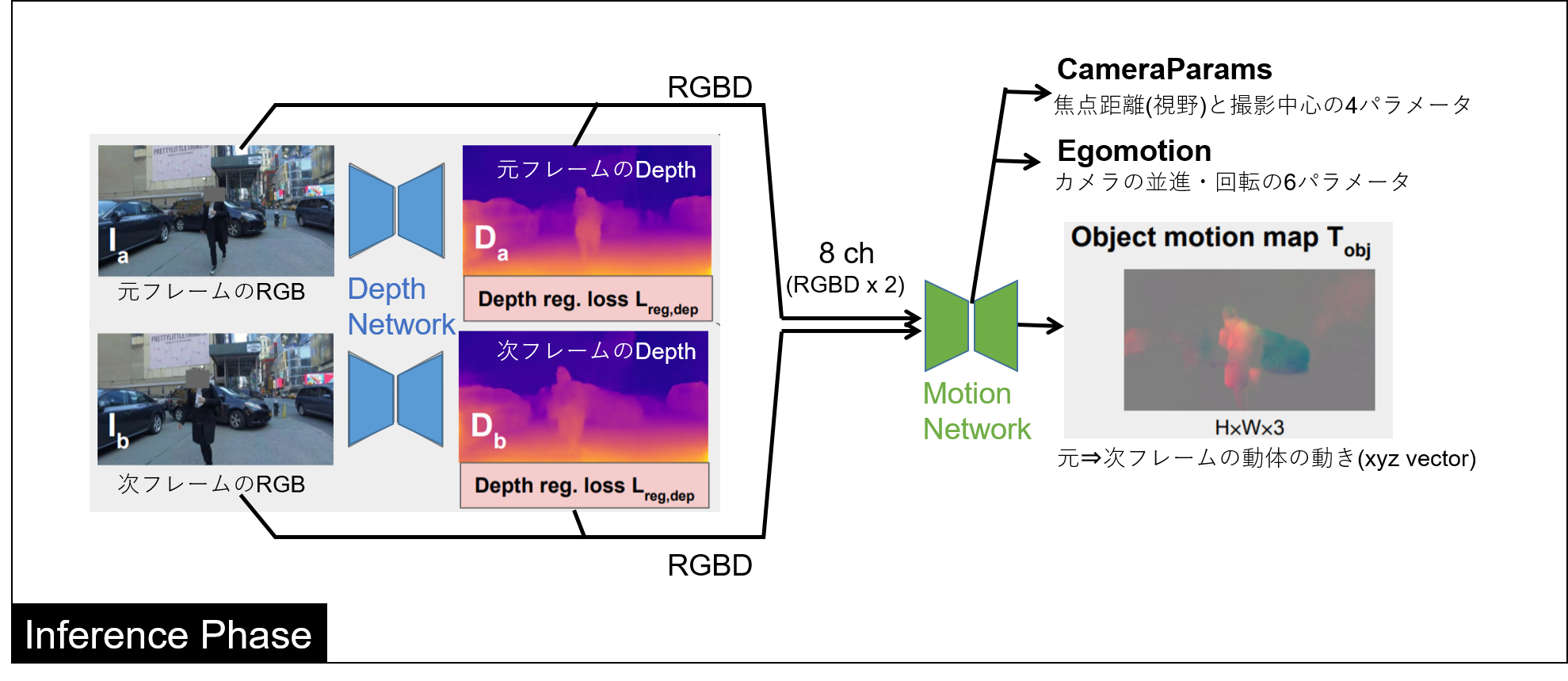
図に示す通り、Depth NetworkとMotion Networkの大きく2つのNetworkにより形成されます。
**DepthNetworkで画像から奥行きを推定し、生成したDepth画像とRGB画像2フレーム分を用いて、Motion Networkによってカメラや物体のモーション、そしてカメラパラメータを推定します。**カメラパラメータ(視野角など)の情報と、Depth画像があれば対象を3次元的に(xyzで)表現することができます。
以下にそれぞれのNetworkの入出力をざっくりまとめます。
(1) Depth Network
-
入力:
RGB画像(3ch) -
出力:
Depth画像(1ch) -
概要:
U-Net likeなアーキテクチャ。論文ではResNet18ベース。
BatchNormalizationの代わりにRandomNormalizationを使用する。
(2) Motion Network
-
入力:
基準&次フレームのRGBD。合計8ch。
基準FrameのRGB画像 & DepthNetで生成した基準FrameのDepth画像
& 次FrameのRGB画像 & DepthNetで生成した次FrameのDepth画像 -
出力@ボトルネック部分:
カメラモーション(XYZ並進と、XYZオイラー角。合計6パラメータ)
カメラマトリクス(画像の高さ&幅の各方向の焦点距離と撮影中心。合計4パラメータ) -
出力@デコーダ部分:
動体のモーション(画像の各ピクセルに対して、xyzベクトル 3chモーション) -
概要:
同じくU-Net likeなアーキテクチャ。論文ではFlowNetベースでDecoder部分のConvを分岐させて増やしたものを採用。画像全体から推定される特徴はボトルネック部分から推定し、ピクセルレベルの動作推定(residual motion)はデコーダで解像度を上げつつ推定していく。
モデル概要 (学習時)
学習時には上述したモデルから得た情報を元に、2つ目のフレームの画像を元画像の位置関係に投影したもの(warp image)をつくります。言い換えると、「推論したカメラモーションや物体の動きを考えると、元のフレームではこう見えるだろうな」というものを論理的に導出します。このワープ画像が元の画像と合致するように学習させていきます。
それ以外にも複数の制約条件を与えて学習させます。構成は以下のようになります。
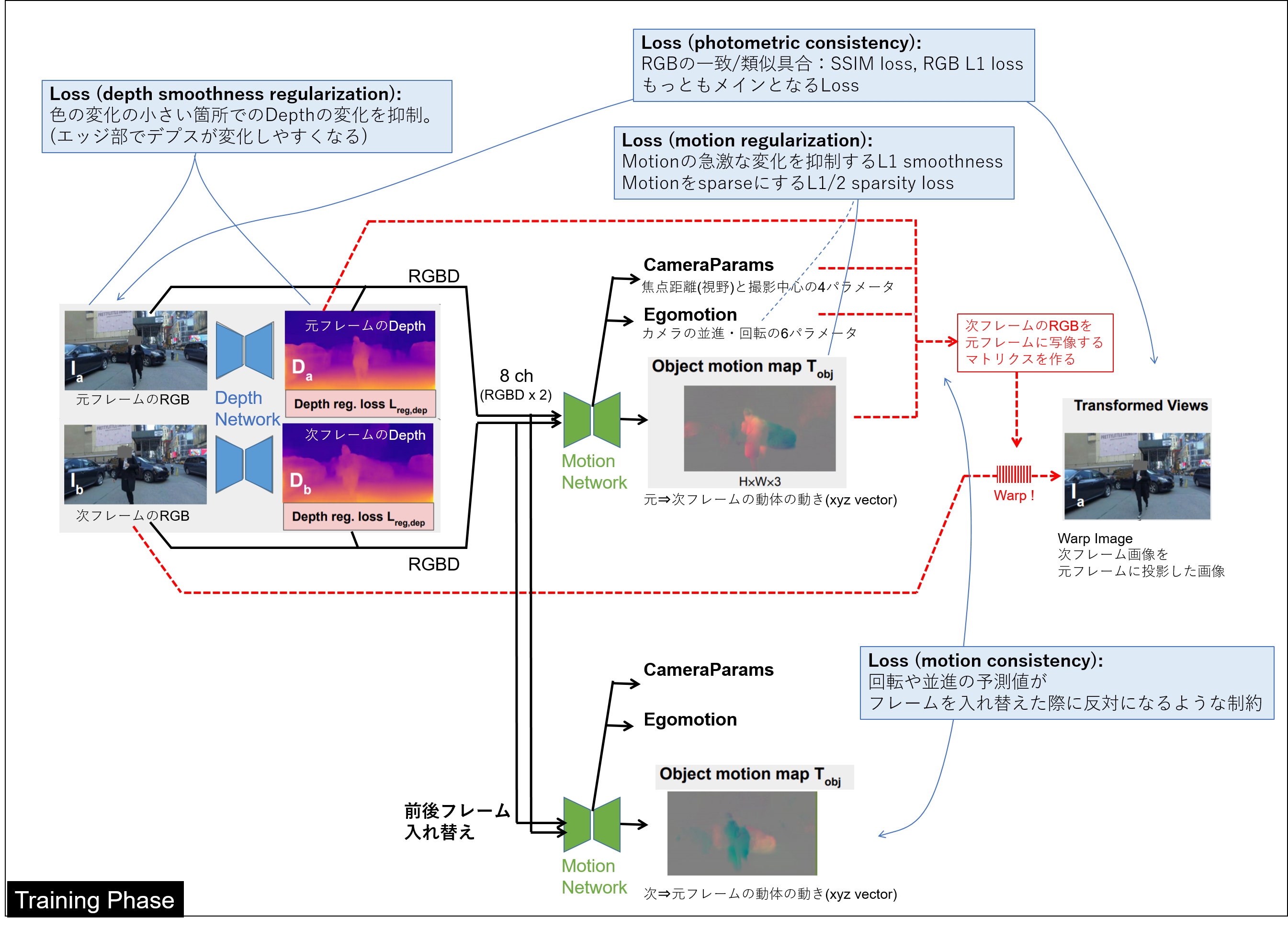
ちょっと複雑ですね。Lossを簡単に説明していきます。
- photometric consistency loss
次フレーム画像を元フレームへと再構成したwarp画像を元の画像と合致させようとするロス。
warp画像と、元フレームの画像のRGB差分によるL1Lossと、画像類似度のSSIMベースのLossの和。
- motion consistency loss
元フレーム①から次フレーム②へのモーション(回転と並進)予測値が、次フレーム②から元フレーム①へのモーション(回転と並進)予測値と反対になるような一貫性を強いるロス。
- depth smoothness regularization
色彩の変化が小さい箇所(非エッジ)では急峻なdepth変化が無いという仮定の元、RGBの変化が小さい箇所での大きいdepth変化を抑制するロス。
- motion regularization
近接するピクセルのモーション予測値の変化が急激に変化することを抑制するL1 smoothness lossと、モーション予測値をsparseにするためのL1/2 sparsity loss。
motion regularizationは少し難しいですが、モーション予測のヒートマップ(等高線)の変化を穏やかに抑えつつも、フラットなピークを好むようになります。物体の速度が場所によって変わらないことを意識しています。
予測結果(論文より抜粋)
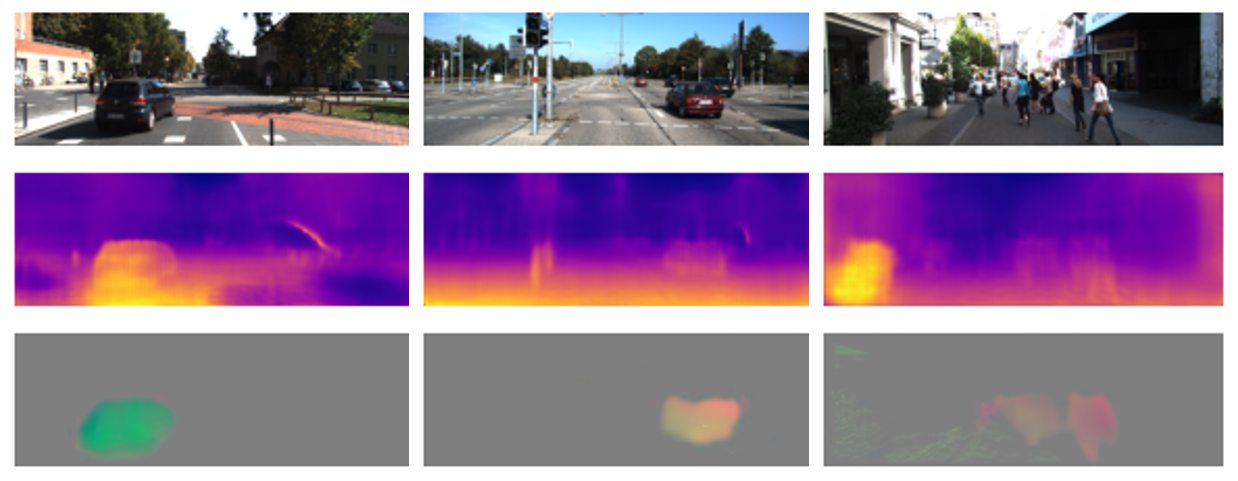
下図は各データセットでの推論結果例です。左から順に、元画像、推論デプス画像(disparity, 1/depth)、推論モーション画像です。時折おかしいところもありますが、かなり綺麗にくっきり予測できているように見えます。
カメラパラメータも予測できるので、Youtube動画を用いても学習することができます。

結局何がすごいのか?
主観ですが、以下が好きです。
動画一本、教師無しでデプス推定ができる!
画像⇒デプスの学習をする最も簡単な方法は2つセットでデータを取得してimage to imageの教師あり学習をおこなうことだと思います。正解データ不要で済むのは本手法のオシャレポイントです。
カメラパラメータが不要!
普通にアプローチするとカメラの視野角などの情報をつかってデプスデータの3次元化をおこないたくなるところですが、それさえも推測対象にしてしまう豪胆っぷりです。
ピクセルの動きではなく、XYZのモーションが推定できる!
上下左右2軸のピクセルの動きではありません。XYZの3軸の動きを推定できます。(OpticalFlowとは異なります)
カメラモーションと物体のモーションを別個に推定できる!
カメラ起因のモーションと動体起因のモーションを別々に推定できます。対象の動きを知りたいときに、カメラのせいで動いたように見える影響を排除できます。
過去の手法と比べて…
本手法の一年前に、論文Depth from videos in the wildを発表しています。前論文では、動体を事前学習済みの物体検出モデルでマスクすることで、動体とカメラのモーションを切り分けることを実現していました。(下図、論文より抜粋)

一方今回紹介した手法では、モーション関連のregularizationと仮定を与えることで、動体の物体検出を不要にしています。モデルとしてはよりシンプルになっています。
単眼デプスの系譜についてはDeNA宮澤氏の資料がめちゃくちゃ充実していますのでぜひご参考。
https://www.slideshare.net/KazuyukiMiyazawa/depth-from-videos-in-the-wild-unsupervised-monocular-depth-learning-from-unknown-cameras-167891145
実際にやってみた。
githubの著者実装も参考にしつつ自力でモデルを作成し学習させてみました。
以下はちょっとマニアックなので、興味のない方は読み飛ばしてください。
結果
KITTIのトラッキングデータ約10,000枚で80epoch学習した後のモデルの推論結果をいくつか添付します。**上3つは比較的マシな例、下3つは少し残念な例です。**まぁ結局は単眼推定なので完全にデプスが読めるわけではないのですが、そこそこいい線いっていると思います。
デプスを読み違えてもモーションで辻褄を合わせられることがあるので、変な推論結果が出てきます。左下の道路標識は代表例で、どうみてもデプスがおかしいです。デプスを読み違えたのでカメラの動きだけを考慮すると次のフレームでは道路標識が歪んでしまいますが、道路標識が動いていると考えることで無理やり辻褄をあわせていますね。
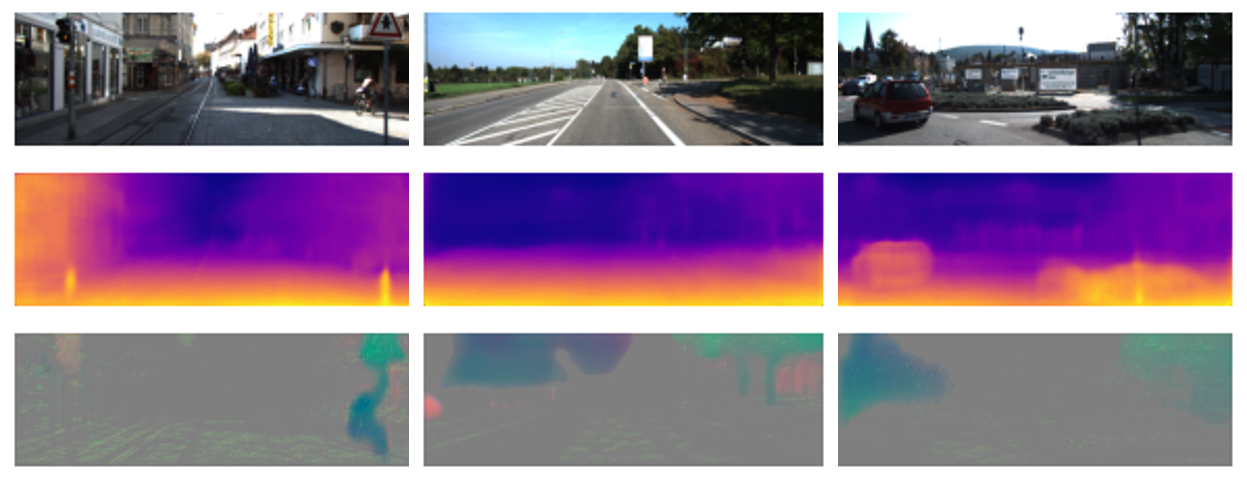
なおこの時点でのロスは、motion regularizationが0.02、depth smoothが0.0007、rgb&motionのcycle lossが0.52です。画像類似度のssim lossがダントツで大きくなります。
実装のポイント
上図の結果を出せるようになるまで、正直かなり苦戦しました。
モデル構築自体はデプス画像の処理に慣れていればそれほど難しくはないと思います。ですが、推定対象が非常に多く、それらが互いに影響しあって最終的なワープ画像を生成するので、学習のバランスをとるのがかなり難しい印象を受けました。個人的にはモデリングよりも学習の方が難しかったです。
学習時の局所最適がそこら中にあるので、何も考えずにやるとすぐに穴にはまります。
読んでも楽しくないと思いますが、たとえば以下のようなハマりポイントがあります。
1. カメラ動作の過剰値によりハマる(デプス:小、モーション:大)
対象がカメラに近いところにあり、カメラがめっちゃ動いたから、フレーム間でロスを出す箇所がなくなって安定する。対策としては、強引にモーション制限を与えたり、学習初期の値を小さくするように工夫する。学習時のgradient制限(clip)なども適度にあった方が良さげ。
2. すべてモーションで辻褄を合わせてハマる(モーション:大)
遠くのものが大きく移動した場合でも、近くのものが小さく移動した場合でも、カメラからの見た目変化は同じなので辻褄があってしまって安定する。対策としては、動体モーションの推定レイヤを途中までフリーズするなど。序盤はデプスとカメラモーションだけで頑張らせて、終盤に動体モーションを追加するような形。
3. 動かない方がマシ、でハマる(モーション:過少)
下手に動いて画像の形が崩れるぐらいならモーションを無しにした方がマシ、というニートな安定点。初期値が小さすぎたり、学習時のgradient制限が強すぎると、モデルが怠惰になって学習が進展しなくなるので、ほどほどにランダム性を与えてあげないといけない。
他にも色々ハマった気がします。用途やビデオによってモーションの最大値などの制約を適切に与える方がいいかもしれません。著者を本気で尊敬します。
さいごに
昨年、Pythonを初めて間もないころに、Depth form videos in the wildの解説を日経ロボティクスで拝見し、そのディープラーニングお化けっぷりに感銘を受けました。当時は実装能力も低く到底手が出せなかったのですが、その後約1年で同系列の論文を実装できたので少しばかり成長を感じることができました。
といっても、まだまだ勉強不足ですので、誤りなどございましたらご指摘ください。
お読みいただきありがとうございました。