前々回の記事『Kaggle画像コンペでやっていること①』では、どんなコンペでも大体やることをあげさせていただき、前回の記事『Kaggle画像コンペでやっていること②』ではドメインを考える最初のステップとして特徴量エンジニアリングの話をしました。
kaggle advent calender 2024の21日目の記事は、画像コンペで適用ドメインを考えてLossやAugmentationするお話になります。数回にわけて書かせていただいており、基本的に初級者(Expertぐらい)向けですのでご了承ください。
8日目:Kaggle画像コンペでやっていること① (タスク関係なくやること)
14日目:Kaggle画像コンペでやっていること② (特徴量まわり)
21日目:本記事
24日目:Kaggle画像コンペでやっていること④
前回記事の振り返り 
- 深層学習で解こうとしているタスク固有の特徴を考えたい
- 自分にとってのあたりまえも、深層学習モデルにとってのあたりまえではない
- うまく効かせると精度があがるしカッコいい
- いろんな活かし方がある
- 特徴量エンジニアリング【済】
- タスク特化のLoss (←本ページで紹介)
- タスク特化のAugmentation選定や作成 (←本ページで紹介)
- タスク特化のモデルアーキテクチャ
- タスク特化のパイプライン
ドメイン意識②:Lossを工夫する
カスタムAugmentation・カスタムLossは脱NN初心者のはじめの一歩だと思います。そのコンペのタスクだからこそのルールや縛りなんかを入れられると、グッと学習が進むこともあります。
物理現象を意識させるLossについて
たとえば、RGB画像から奥行きを予測するタスクではDepth Smoothness Lossと呼ばれるLossがよく活用されていました。
これは、『奥行きの変化が起きるのは色味の変化が大きいところ』だという常識をモデルに意識させるためのLossです。入力したRGB画像と予測した奥行き画像との画素間の変化量を用いて、RGBの変化量が少ない箇所での奥行き変化に対して軽いペナルティを与えます。
このように、通常の学習と合わせて制約を与えることで、意図した方向に学習を進めることができます。


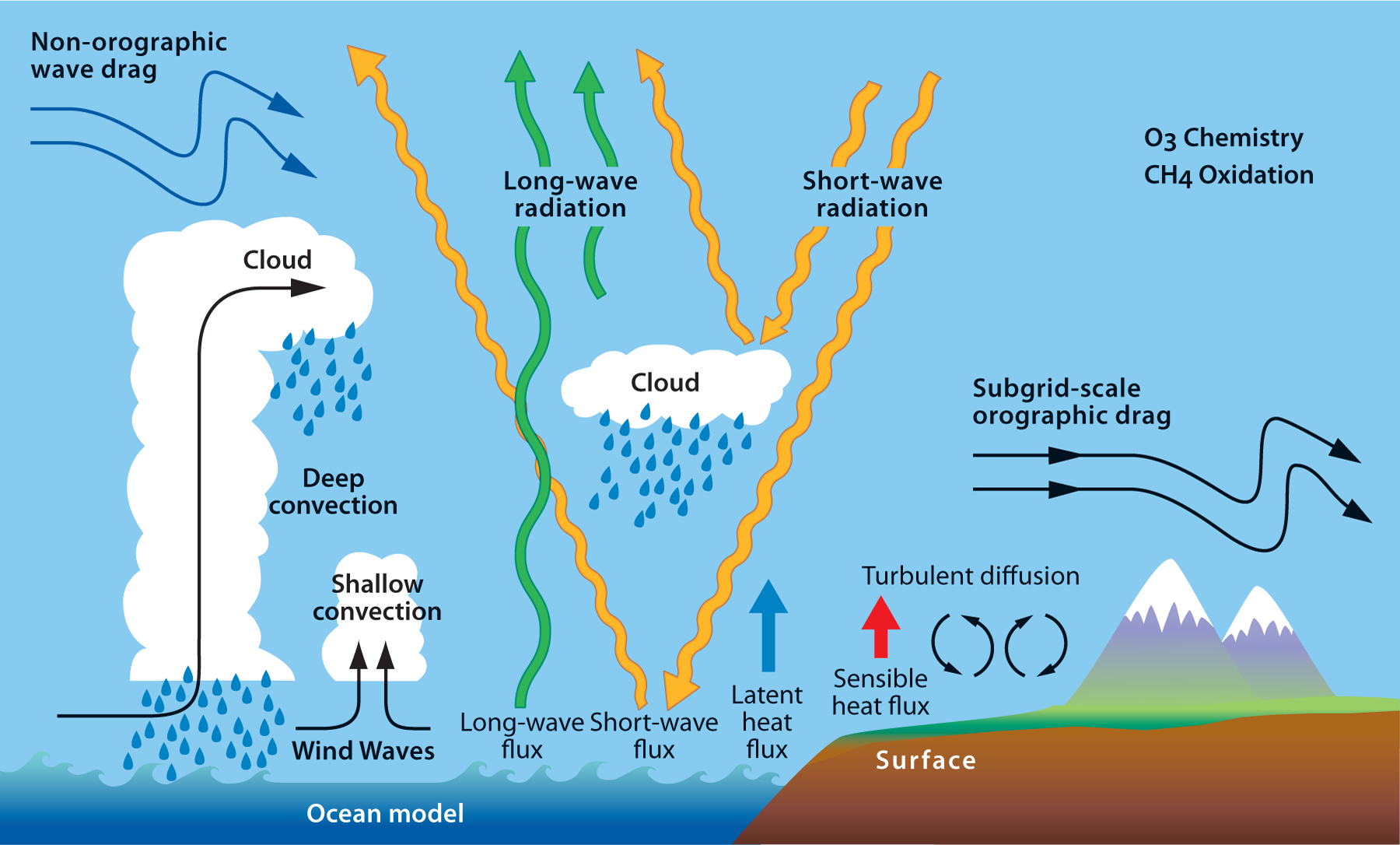
別の例としては、先日のKaggle LEAPコンペでは、少し未来の気象(風速や湿度、気温など)を求めるコンペでした。このようなケースでは現在と未来の間での保存則が成立することが多いです。
- 地球への流入する熱量と流出する熱量の差分は、地球のどこかに蓄えられているので、それらをLossとして定義することができます。たとえば
loss = (流入 - 流出 - 地球蓄え)**2のようにペナルティを与えられます - 水分量も維持されます。地面に含まれる水が蒸発し、大気や雲に含まれ、降雨して…という循環に含まれる水分量を一定に保つようなlossを定義できます
まぁ、LEAPコンペでは地理情報は使用不可だったこともあり保存則を定義しにくく、使えないアプローチでした![]()
サブタスクとしてのLossについて
test dataでは与えられていないけど、train dataには与えられている情報がある場合にはサブタスクを解かせるチャンスです。分類や回帰などの本来解きたいタスクと並列に、そのドメインにとって重要な情報をサブタスク的に学習させることで、メインのタスクに対するパフォーマンスを高めることもできます。

■ ラベルに含まれない追加情報は積極的に活用する 
kaggleでおこなわれたクジラの識別コンペでは、個体識別IDとともに、species(種族)が与えられていました。コンペの目的は個体分類ですので、種族を分類すること自体は求められていませんが、これをサブタスクとして解かせることで精度を上げたチームが多かったようです。
(優勝者チームのcharm先生![]() も、補助ロスはやって損なしとおっしゃっていました)
も、補助ロスはやって損なしとおっしゃっていました)

また、チューリッヒ工科大の論文(CoRL2024)では、扉を開けるタスクの学習において、ロボットの動きとは直接関係のない扉に関する情報を予測させ、それに対してEstimation Lossとして学習させています。この補助的なロスによって結果的にロボットの行動に関わる精度も向上したことが示されています。
扉によっては軽い扉や重い扉、引く扉や押す扉、閉まる方向に荷重がかかるタイプの扉など色々な扉があるので、どのような扉かを予測することが扉開閉の動きを作るうえでの助けになることは想像がつきます。
直接最終的な予測をすることが難しいようなタスクで、その判断の助けになるようなものを補助的に学習するときは効きやすいですね。

■ ラベルよりリッチな情報は積極的に活用する 
珍しいですが、『セグメンテーションラベルが与えられているが評価対象は分類問題』という例もあります。たとえば、先日のRSNA2024では、医療画像における注視箇所が画像座標で与えられていましたが、予測対象は症状の深刻度でした。
単純な分類ラベルと比べると、位置ラベルは非常に大きな情報源で、十中八九は役に立ちます!
『この画像は犬、この画像は猫』と言われるより、『この画像のこの部分が犬、こちらはこの部分が猫』と言われるほうがNNとしても学習が容易なことは想像できると思います。
本コンペでは検出~分類の2stageが強かったのですが、タスクによっては補助ロス的な形も十分に考えられます。
逆に、ラベルよりも情報が少ないタスクを解かせても補助ロスは効きにくいことも多いです。極端な例ですが、犬の画像のセグメンテーションをするときに、画像に犬が含まれるかどうかのサブタスクを解いてもそれほど効果はありません。
■ ラベルからサブタスクを作ってもいい 
先日の第18回atmaCupでは自車の未来の位置推定問題でしたが、位置だけでなく速度や加速度をサブタスクで学習する人がいました。たしかに、『青信号なら加速』『前に車両がいる場合には避ける』など、速度や加速度を用いることで学習しやすくなる要素がありそうなことが想像できます。
ラベルが位置情報だとしても、それを微分して速度をサブタスクとして学習できる例でした
補助ロスの注意点:残念ながら足を引っ張ることもある
補助ロスのせいでメインタスクの性能が悪化するときもあります。とくにサブタスクのターゲット値が極端に大きかったりすると、メインタスクの学習に悪影響を及ぼすこともあります。
そんなときは…
- loss weightを調整するのは手っ取り早いです。補助ロスweightを弱くしても効かないなら他の方法をとってもいいと思います
- チャンネル数を増やすなんかも手っ取り早いことがあります
- 下図のようにサブタスクとメインタスクを遠ざけるのもあると思います。検出器などでもよくありますが、予測対象の特性が異なる場合はブランチを切った方がうまくいきます。
- 難易度はあがりますが、Lossではなくモデル側の出力として制約をかける方がいいケースは多いです
- たとえばx, y, zの3つの予測をするときに互い相関関係を持っている場合、別のv, wの予測問題に置き換えてそこからx, y, zをもとめるようにする
- たとえば、
x**2 + y**2 < 1のようにxとyの数値レンジが決まっているなら、rとΘの予測問題におきかえて、rをsigmoidみたいなので予測してもいいですね - 手前みそですが、Kaggle睡眠コンペでは1日1回以下の入眠&起床というルールを如何に反映するかという際に、Lossではなくtargetの工夫によって学習したことがあります。ここ最近で一番冴えていたのに2nd placeで悔しかったです
- まぁ無理な時は諦めます。「あった方が良いと思うんだけどなぁ」と呟きながら泣く泣く諦めます
Lossの距離感や強弱は難しいですね。モデルへの反映まで考えるとかなり難しく様々なアプローチがあります。

ドメイン意識③:Augmentationを工夫する
使うべきAugmentationと使うべきでないAugmentation
今解こうとしている問題に対して、「このAugmentationって使っていいのか?」と考えることが最初の一歩ではないでしょうか。
■ Augmentaitonによって別ラベルになってしまうケース
たとえば以下の画像から次のアクションを予測するとします。

まぁ見ての通りコップをとります。笑
これを学習時にFlip Augmentationで左右反転すると右手が左手になってしまいます。右利きの人の方が多いのでtestに対する予測精度は悪化してしまう可能性があります。であればFlip Augmentationはやめとこうかなと判断できます。
入れるべきAugmentationというのは、どんなコンペでも一回は考えていると思います。
先日のRSNA2024の場合は、人の体に対して左右それぞれのラベルを別々に予測させるような問題でした。この場合は画像を左右反転するときにラベルも左右反転しておけばなんとかなりそうに感じますね。

■ Augmentaitonによってコンテクストが変わるケース
The Elephant in the Room(見て見ぬふり)の論文で有名ですが、下図のように物体検出器が室内の画像に貼り付けた象を検出できないことがあります。これは物体検出器が象そのものだけでなく、部屋の中という文脈も含めて学習していることになります。賢いですねぇ。
コンペにおいても、この象を検出すべきお題かどうかといったことを考えることができます。この象の例の場合は、Mixup Augmentationやcopy paste Augmentationなどで補強すると検出できるようになります。
とはいえ、NNは人が意識していないような思いもよらないところを(いい意味に)判断材料にすることがよくありますので、補助したつもりが迷惑をかけることもよくあります![]()

■ 対象タスクでよくある状況をAugmentationで再現
この分野ではこの変なノイズがよくのるんだよなってときにはそれを自作してみると楽しいです。自作Augmentationは初心者もとっつきやすく、ちょっとした画像処理の練習にオススメです。
タスクによっては影なんかもよくのりますね。どんな形でのせようかとか、影の強弱をどう表現しようか、など色々考えることがあるので、良い頭の体操になります。
効く効かないを問わず、やってる感があるので妙に達成感が得られることもポイント高いですね。

タスク固有Augmentationの注意点:残念ながら足を引っ張ることもある
使うべき使わざるべきという話をしましたが、悲しいことに
- NGだろというときでも、入れたら効いちゃうときもある
- 逆に、入れるべきだろってときでも入れない方がいいことがある
たとえば車載動画をみて、「地面は絶対に下なんだから上下反転だめでしょ」と思っていても効いてしまうことはあります。そんなときに有効なテクニックがあります…!
『どっちも試す』![]()
気を付けたほうがいいぞ、と思いながらどっちも試します。
ちゃんと理解してAugmentationを試行錯誤できることが強さです![]()
なお、Lossと同じくこちらもモデル構造で反映することもできますが複雑な話になるので省略します。
まとめ
ということで今回はドメインを考える話の2回目として、Loss&Augmentationの話をさせていただきました。劇的にスコアを上げるようなものではないですが、実装量も比較的少ないケースが多く、自分なりの工夫をささっと出しやすい部分ではないかと思います。実際、私自身も最初はこのあたりしか手が出なかったです。
ここまでできればもう金圏も見えるのではないでしょうか!?
次回も継続して『そのコンペだからやること』の紹介予定です。さらなるコンペ固有の工夫で今度こそロマン砲を狙いましょう!
参考
- ETH Zurichの扉通行の補助ロス: https://arxiv.org/abs/2409.04882
- Elephant in the room: https://arxiv.org/abs/1808.03305
- LeftRightConsistency(Depth推定におけるLoss): https://arxiv.org/abs/1609.03677
- 影データ: https://arxiv.org/abs/1712.02478
- Kaggle Happy Whaleクジラ識別コンペ: https://www.kaggle.com/competitions/happy-whale-and-dolphin
- Kaggle LEAP 気象コンペ: https://www.kaggle.com/competitions/leap-atmospheric-physics-ai-climsim
- Kaggle CMI 睡眠コンペ: https://www.kaggle.com/competitions/child-mind-institute-detect-sleep-states
- Kaggle RSNA2024: https://www.kaggle.com/competitions/rsna-2024-lumbar-spine-degenerative-classification
- 第18回atmaCup: https://www.guruguru.science/competitions/25/