概要
単一デバイス(Ultra96)内でROS2通信を利用して画像を送受信した場合、
画像のサイズ、圧縮するか否か、使用するDDS、などを変えて画像の送受信にかかる時間を測定・評価しました。
どちらかというと通信遅延そのものについての評価というより、画像を送信する際にかかる時間の評価です。ですので、圧縮画像送信の際には画像の圧縮にかかる時間も遅延時間に含んでいたりします。
(※『本当の意味で』ROS2の通信なんもわからんなので、あまり考察はしてないです・・・・)
はじめに
最近、ROS2に関わる記事を投稿したのですが
????「せっかく何か書くならアドベントカレンダーに投稿すればいいのに・・・・」
という天の声(?)が聞こえたのでアドベントカレンダーに初挑戦します。
先輩方と一緒に自律運転ロボミニカーを開発しており、ソフトウェア部分でROS2をいじる開発に主に携わっています。
システムでは画像をカメラから取得し、画像認識ノードに送信して画像認識をしてもらう、という動作を行なっています。
直感的に、この部分の遅延が大きいのではないかという気がしてきました。
executorは闇とかいう声をちらっと聞いたことがありますが、いやそれでもネットワーク層を経由するプロセス間通信よりexecutor使った方が早いのではないかと
また、「pcamを使うと起動時間に比例して遅くなっている」のではないかという情報を聞いたので、僕たちの環境でもそうなっていないか検証せんとあかんなと思いました。
そこで、環境を様々変えて画像の出版にかかる時間を測定し、比較しました。
最終的に一番いいやり方をロボットに採用するというのが目的です。
評価環境
- Ultra96 v1
- Ubuntu 18.04
- ROS2 Dashing
Ultra96をインターネットに接続されている無線LANに接続し、ホストPCからコマンドの入力やログの取得を行いました。
カメラはPCAMを使用し、640*480サイズの画像を取得します。
評価方法
出版ノードはPCAMから画像を取得し、30msec間隔で500枚出版します。
通常画像の場合は出版直前に、圧縮画像の場合は圧縮直前にROSのシステム時刻をマイクロ秒単位で取得し、文字列に変換してImage.frame_idフィールドに持たせ、画像と共に送信します。
(Image.header.stamp ( Time型)に持たせたかったのですが、int64で取得するシステム時刻がint32のフィールドに収まらなかったので、あかんかなあと思いつつ無理やり文字列に入れてます)
画像を受信しコールバック関数が呼び出されると、その時点でのシステム時刻を計測します。
次に、画像のframe_idフィールドに保持されている文字列を取得し、int64に変換します。
最後に、受信後に取得したシステム画像と画像データに格納されていたシステム時刻の差分を取り、それを通信の遅延時間として出力します。
受信ノードより得られた出力結果をExcelに放り込み、受信メッセージ数・平均・分散の計算、およびグラフ描画をします。
測定条件は以下のパターンを試しました
- 画像圧縮: cv:Matから変換した画像そのまま or cv:imencodeで圧縮した上で変換した画像(圧縮品質30)
- DDS: FastRTPS (デフォルト) or OpenSplice
(今回はQoSは触っていないです。今後QoSを変えた時の影響も評価したいです。)
評価結果:プロセス間通信を利用した場合
ROSで画像を送信すると聞いて僕が最初に思いうかんだシステム構成です。
以下のようなソフトウェア構成で測定を行いました。
image_speedtest_component pcam_component
| |
image_speedtest <-----通信-----> pcam
受信ノードがFastRTPSを使用する場合
まず、受信ノードのDDSをFastRTPSに固定します。
評価結果を表にしたものが以下です。
※平均および分散は、四捨五入で整数に丸めています。
※先述の通り、圧縮画像の場合は圧縮処理も時間計測対象の処理としています。
| パターン | 受信メッセージ数 | 平均 [μsec] | 分散 |
|---|---|---|---|
| 通常 + FastRtps | 500 | 5975 | 3833268 |
| **通常 + OpenSplice ** | 104 | 9342667 | 117216*10^8 |
| 圧縮+ FastRtps | 498 | 10393 | 7070 |
| 圧縮 + OpenSplice | 501 | 10382 | 35529 |
次に、これらをグラフにします。
「時間がかかるほど遅くなる」のかどうか検証したかったため、時系列の折れ線グラフを用いました。
通常(非圧縮)画像+OpenSpliceはあまりにも時間がかかりすぎてているため除外します。
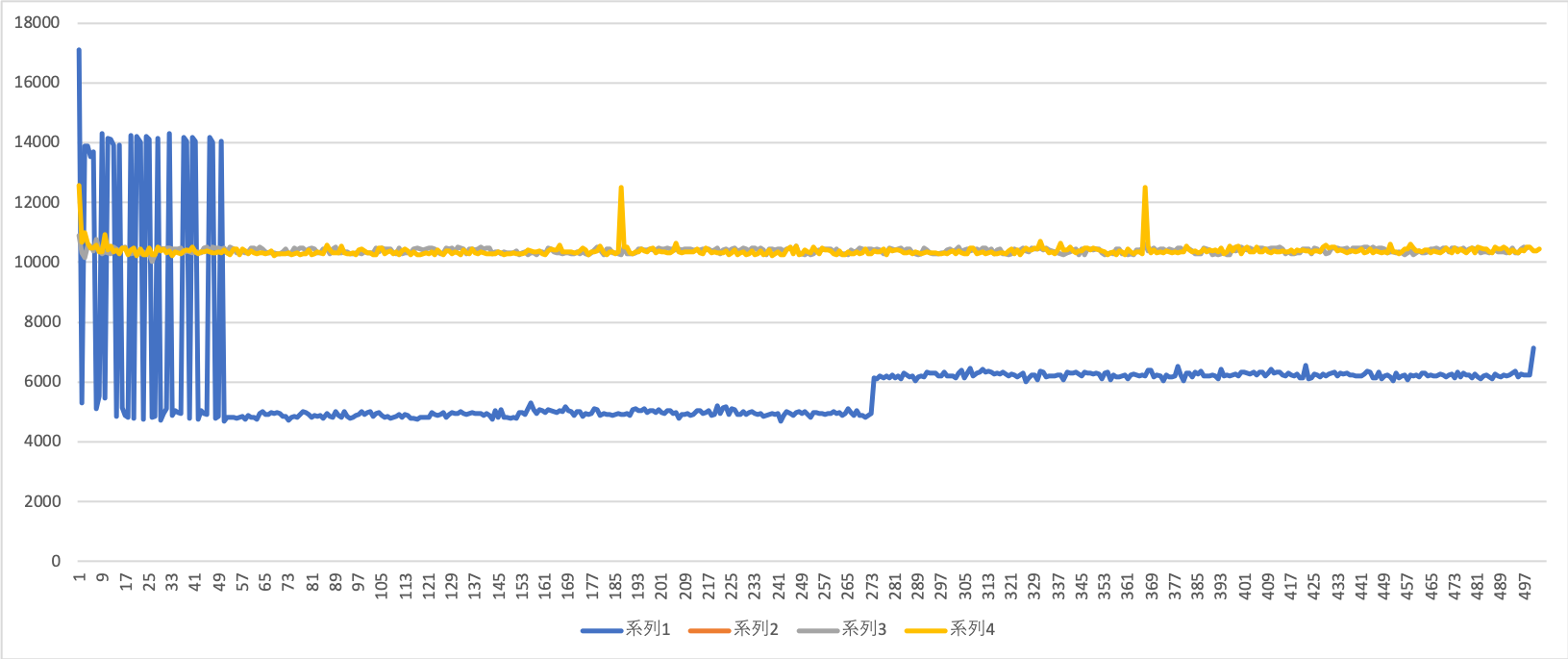
(Excelでグラフ作るの下手太郎なので拙いグラフでごめんなさい)
縦軸が受信の遅延時間(μ秒単位)、横軸が受信したメッセージの数です。
系列1−4が上の表の項目に上から順に該当します。(ただし系統2はグラフに含めていません)
考察?
ばらつきに目を瞑れば、圧縮なし画像+FastRTPSが一番良さそうですね。
送信画像のサイズは圧縮後の方が小さいので、画像圧縮にかかるオーバヘッドがサイズの通信時間差を上回っているという感じでしょうか。
このグラフにのせている物に限っては「時間が経てばたつほど処理時間が遅くなる」ということはなさそうですね。
FastRTPSを使った通常画像送信で、途中から通信時間がやや跳ね上がっているのが少し気になりますが・・・
何かバッファに溜まってしまっているんでしょうか?
受信ノードがOpenSpliceを使用する場合
次に。受信ノードのDDSをFastRTPSに変更して同じ測定を行います。
| パターン | 受信メッセージ数 | 平均 [μsec] | 分散 |
|---|---|---|---|
| 通常 + FastRtps | 499 | 12740 | 195160 |
| **通常 + OpenSplice ** | 255 | 4272293 | 39810*10^8 |
| 圧縮+ FastRtps | 501 | 10839 | 26926 |
| 圧縮 + OpenSplice | 501 | 10880 | 32629 |
次に、先ほど同様折れ線グラフにします。
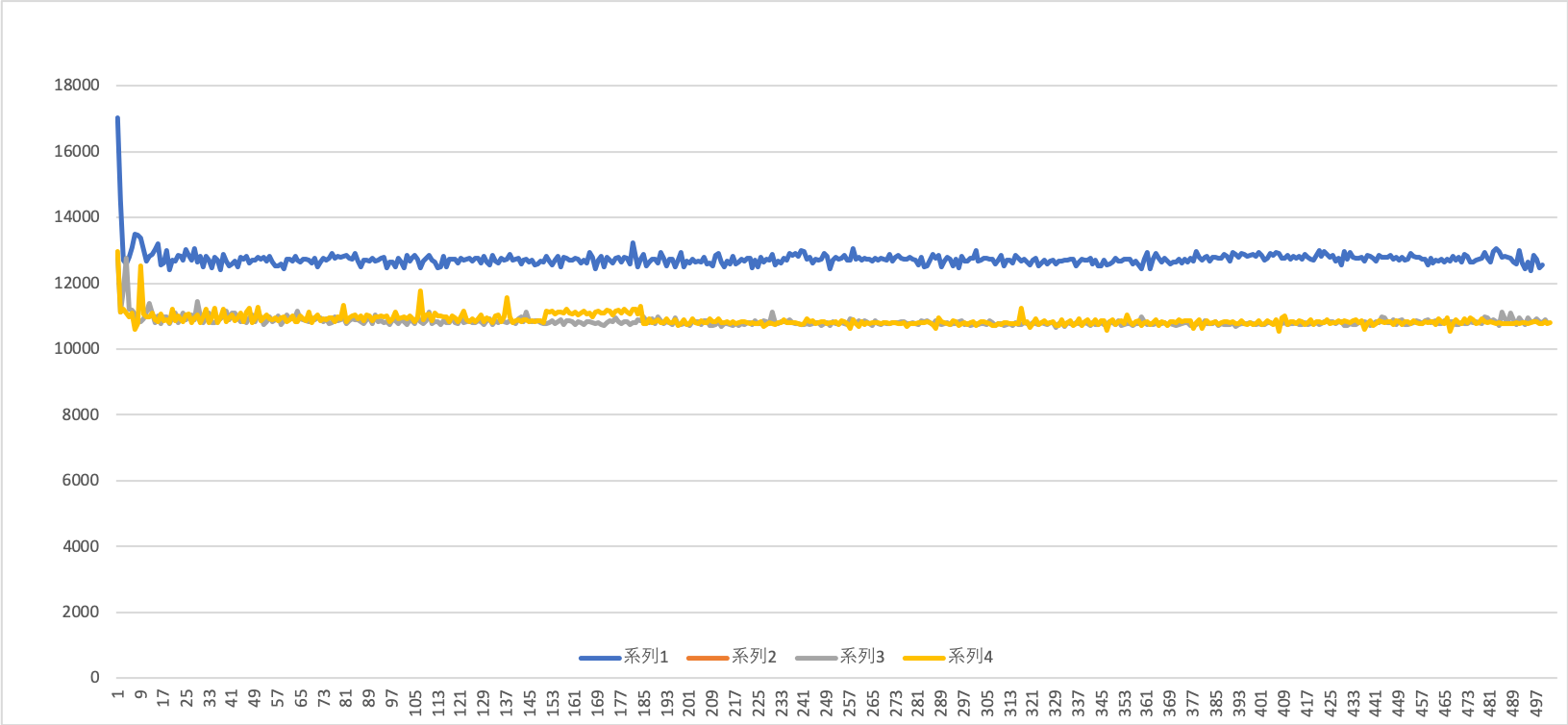
考察?
圧縮画像に関しては先ほどと変わらない結果でした。
一方、FastRTPSを用いた通常画像送信にかかる時間が跳ね上がってしまいました。画像圧縮より大きくなってる・・・
結果を見る限り、この方針はロボットには採用できなさそうですね。。。
通常画像をOpenSpliceを使って送信する場合
先ほどは掲載しなかった、通常画像を用いてOpenSpliceで送信する場合のグラフを以下に示します。
送信ノードはOpenSpliceの使用で固定し、受信ノードの使用DDSを変更します。
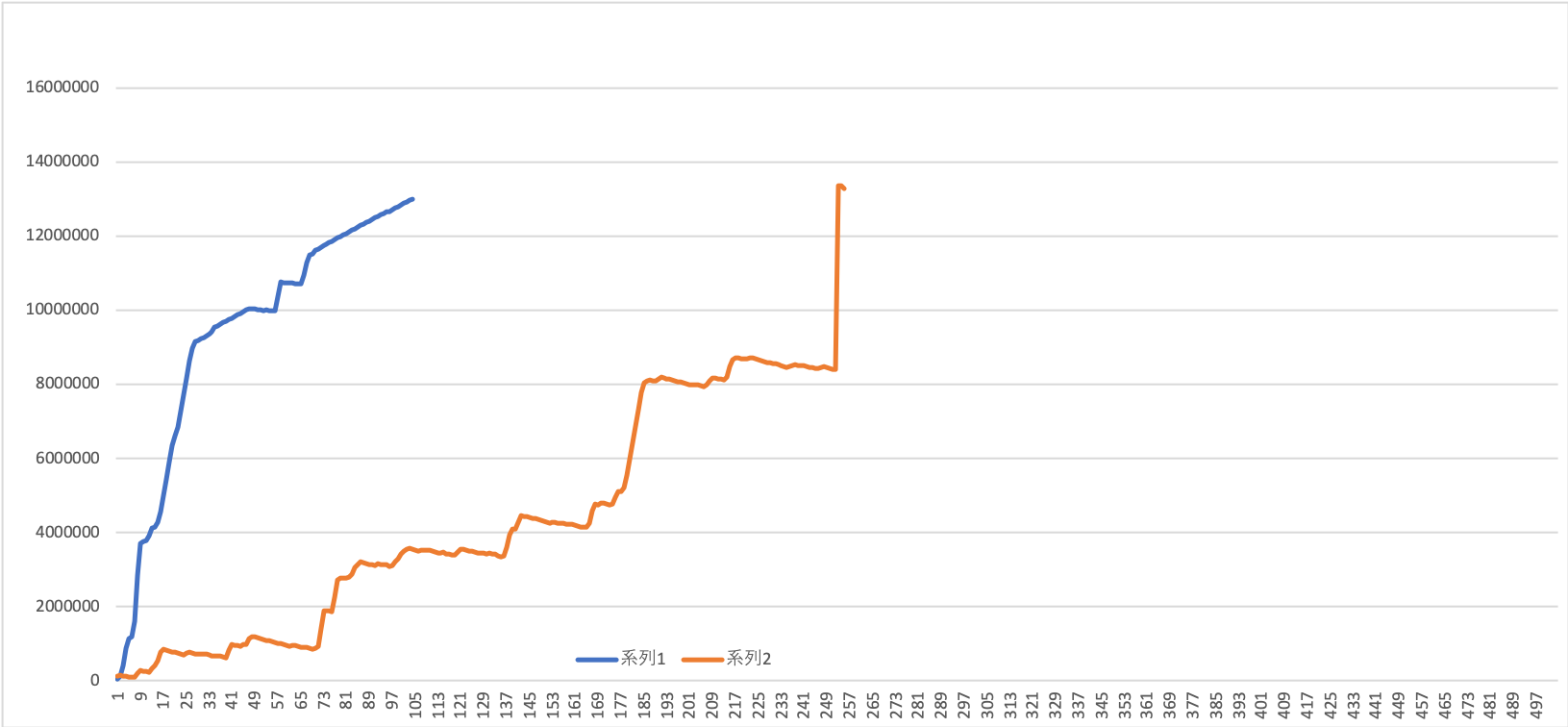
考察?
系列1がFastRTPSを用いた受信、2がOpenSpliceを用いた受信です。
どちらも500枚受信する前に何かしらの問題が起きていて、半分しか正しく受信できていないようです。
時間を経ることに遅延が大きくなっていって、最後には死んでしまっているという形をしていますね・・・・
まさに「時間が経つごとに処理が重たくなっている」状況に見えます。
特にOpenSpliceを受信に使用した場合、受信にかかる時間がほぼ一定周期?で下がっていっているのがとても気になります。何故かは全くわかりません・・・
評価結果:executorを利用した場合
さていよいよ本命です。executorを使い、以下のようなシステム構成で実行してみます。
image_speedtest_component pcam_component
\ /
image_speedtest (プロセス内通信を行う)
ので既存のパッケージをexecutorとunique pointerを使う仕様に書き換えた・・・・のですがここに結構ハマってしまいました。ハマるのは毎度のことですね
ここに書くのも本質的ではないので、別記事にする予定です。是非そちらもご覧ください。
さて、この設定をすると途端に画像を受信しなくなってしまいます
正確には受信するのですが、十数枚受信するとそこから先は何もしなくなってしまいます。

おおん・・・・
ので、 ここから先のexecutorを使う評価は出版間隔を30ms間隔から50ms間隔に広げ ます。こうするとうまい具合に受信してくれます。ううむ?
ROS2ではexecutorを使って同一プロセス内で複数ノードを実行する場合、プロセス内通信(Intra-Process Communication)を利用するかどうかを切り替えることができるようです。
せっかくなので両方の場合について評価してみました。
なお、DDSの設定は二つのcomponentを乗せているプロセスに対して行うため、送信側・受信側で共通になることもご注意ください。
executorでプロセス内通信を利用する場合
まずはプロセス内通信を利用する場合です。
ネットワーク層の経由を回避できるため、直感的にはこれが一番早い通信が出来そうですね。
出版購読両方のノードのコンストラクタ(?)にrclcpp::NodeOptions().use_intra_process_comms(true)を設定し、プロセス内通信を有効にします。
ノード
| パターン | 受信メッセージ数 | 平均 [μsec] | 分散 |
|---|---|---|---|
| 通常 + FastRtps | 500 | 746 | 17854 |
| **通常 + OpenSplice ** | 501 | 1052 | 8767 |
| 圧縮+ FastRtps | 498 | 10136 | 11989 |
| 圧縮 + OpenSplice | 501 | 10762 | 25161 |
先ほどと同様にグラフにしてみます。
なお、今回は通常画像+OpenSpliceがぶっ飛んだ値ではなかったため、一緒にグラフに載せることにしました。
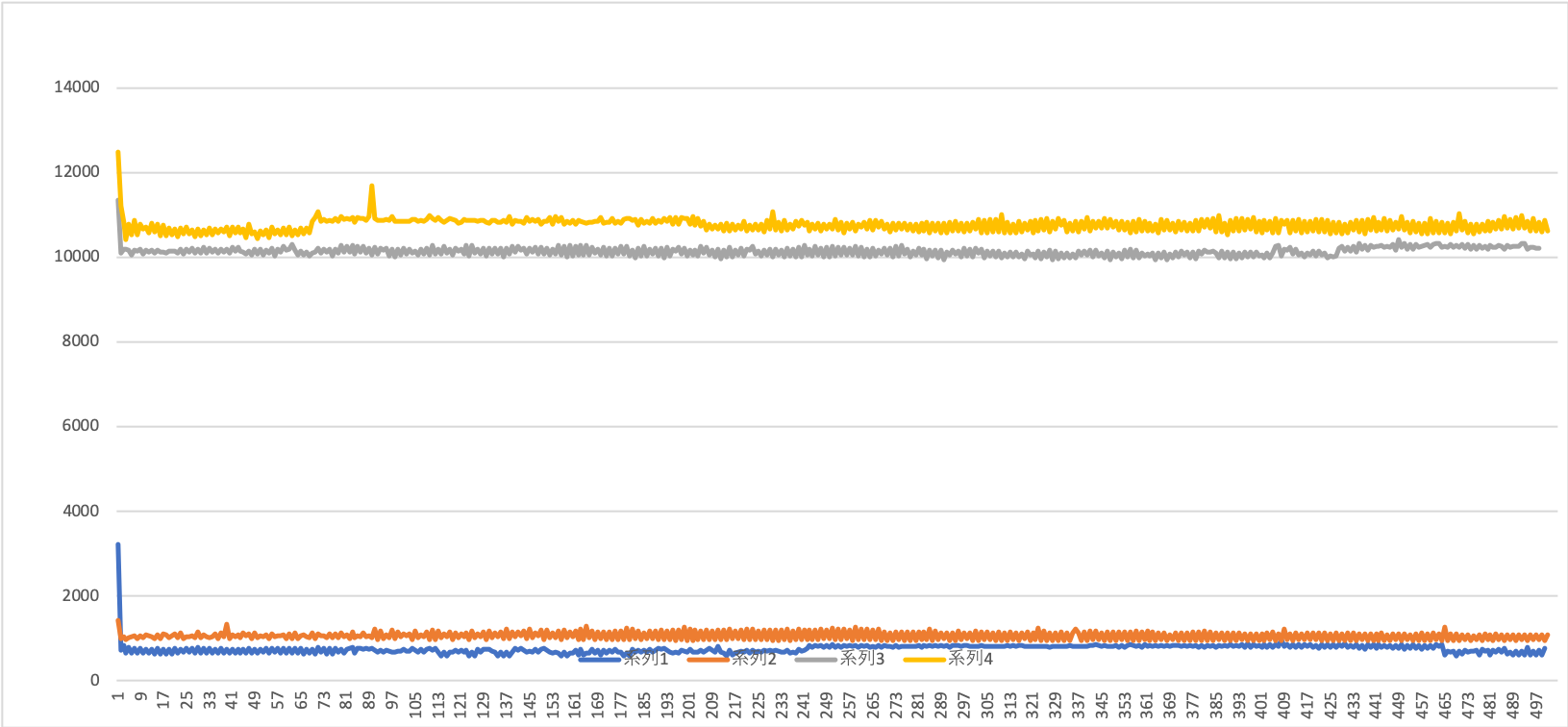
考察?
画像を圧縮しないパターンが、圧縮を行うパターンと比べ速くなっています。
現段階で一番良い結果が出ている非圧縮画像をFastRTPSで送信するパターンと比べても圧倒的にいい結果が出ています。
(これで30ms周期の購読が可能だったらなあ・・・)
プロセス内通信を使う場合と使わない場合で、画像を圧縮して送信するのにかかる時間が概ね同じくらいになっているのはたまたまでしょうか。
圧縮にかかるオーバヘッドが大体8000us~10000usくらい、かつ送信そのものにかかる時間がそれに比べて小さい、と考えると、同じくらいの時間になるのもそうなのかなと思えました。
DDSによる違いはあまりなさそうです、OpenSpliceの方が若干時間がかかる、かつバラつきが大きい感じがします。
「プロセスない通信を利用するならFastRTPSよりOpenSpliceの方がいいよ!」と聞いたことがあったんですがどうもそういうわけではなさそうですね
・・・ん、プロセス内通信ならDDS経由しないからDDS選択で通信速度の違いは出ないはずでは・・・?
executorでプロセス内通信を利用しない場合
今度は、rclcpp::NodeOptions().use_intra_process_comms(false)の設定をして、プロセス内通信機能を利用せずに通信を行ってみます。
| パターン | 受信メッセージ数 | 平均 [μsec] | 分散 |
|---|---|---|---|
| 通常 + FastRtps | 497 | 6494 | 6028690 |
| **通常 + OpenSplice ** | 501 | 14762 | 167672 |
| 圧縮+ FastRtps | 500 | 10954 | 33649 |
| 圧縮 + OpenSplice | 501 | 17417 | 138289 |
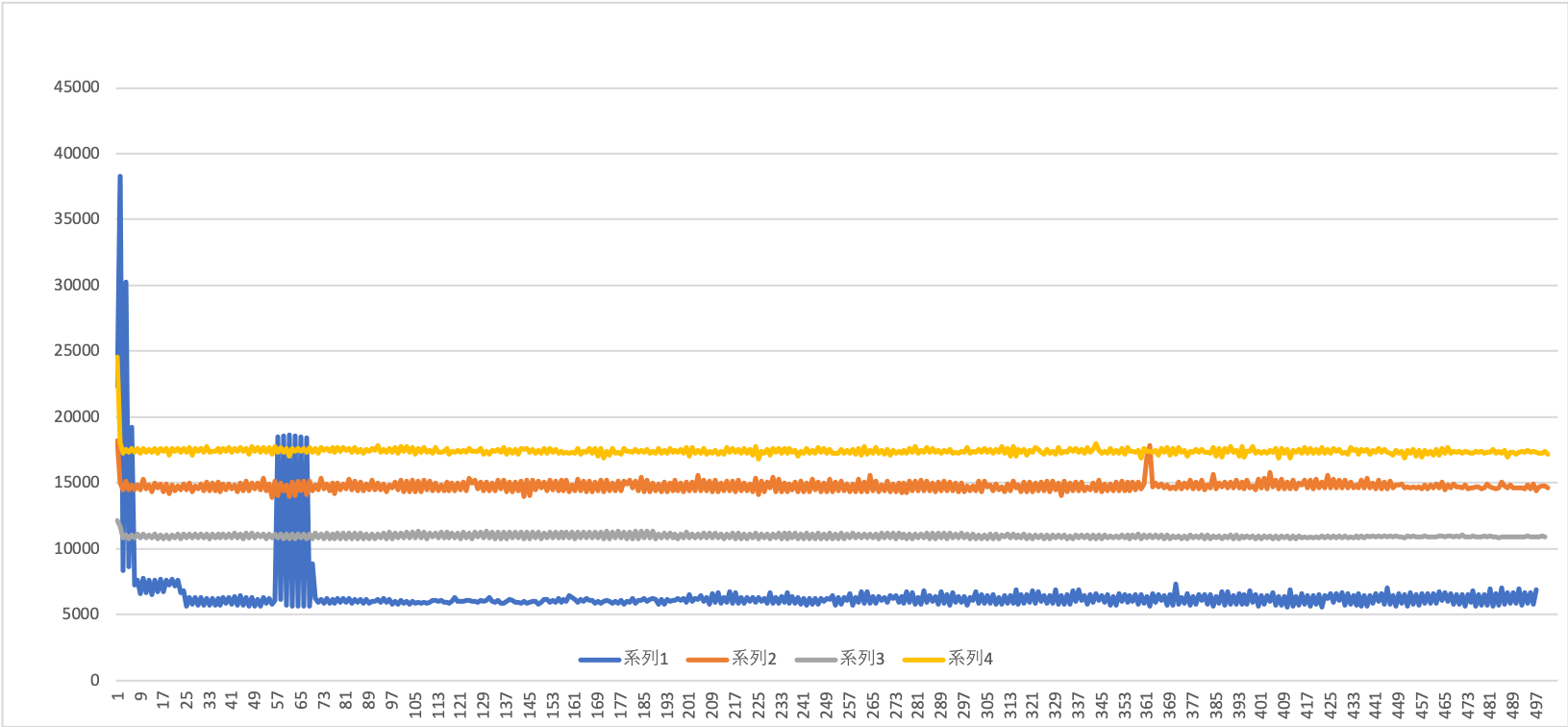
考察?
通常画像+OpenSplice使用パターン(系統2)が最初の検証と比べて劇的に改善しています。
反面、圧縮画像+OpenSplice使用パターン(系統4)はひどく時間がかかるようになってしまいっています。この違いはなんなんでしょう・・・・・
それ以外の二つは概ね最初の検証と同じような形になっていると思います。
通常画像+FastRTPS(系統1)が基本一番よく、かつばらつきの幅が大きいところも同じでした。
ばらつきの頻度が少ないのはたまたまでしょうか・・・?
おまけ:CPU使用率について
「ROS2のexecutorは効率がとても悪い」「CPUめっちゃ使う」という噂を耳にしたので、CPU使用率も軽く検証してみました。
(ホントはもっとちゃんと測るべきかもしれませんが・・・)
測定環境
以下のような測定を行いました。
- FastRTPSを利用した、通常(非圧縮)画像の送信
- executorを使用せずノードごとに独立したプロセスを作るパターンと、executorを使用しプロセスない通信を行うパターンの2通りで検証
- Linuxの
vmstatコマンドを使用し、us(ユーザプログラムによるCPU使用率),sy(カーネルプログラムによるCPU使用率),cs(コンテキストスイッチの回数)を、画像の出版・購読開始から完了までで取得 - プロセス内通信とプロセス間通信、共に50ms間隔で通信を行うようコードを一部変更しました。
-
vmstatコマンドを立ち上げる時間差を吸収するため、画像出版後CPU使用率が0%になるタイミングを基準とし、2パターンのデータ位置を揃える
測定結果
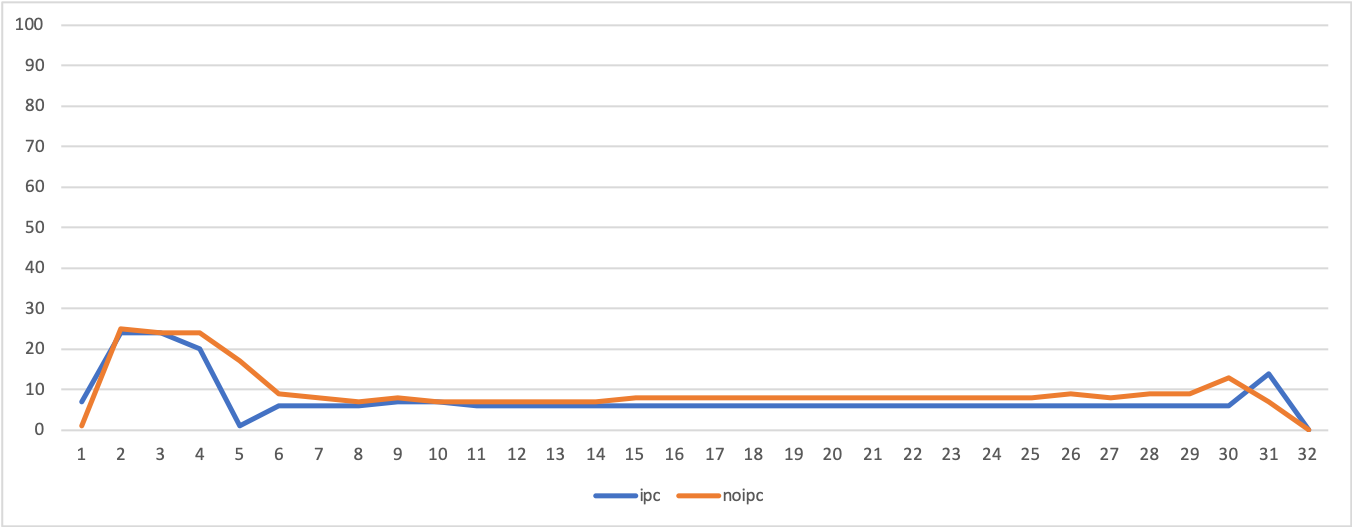
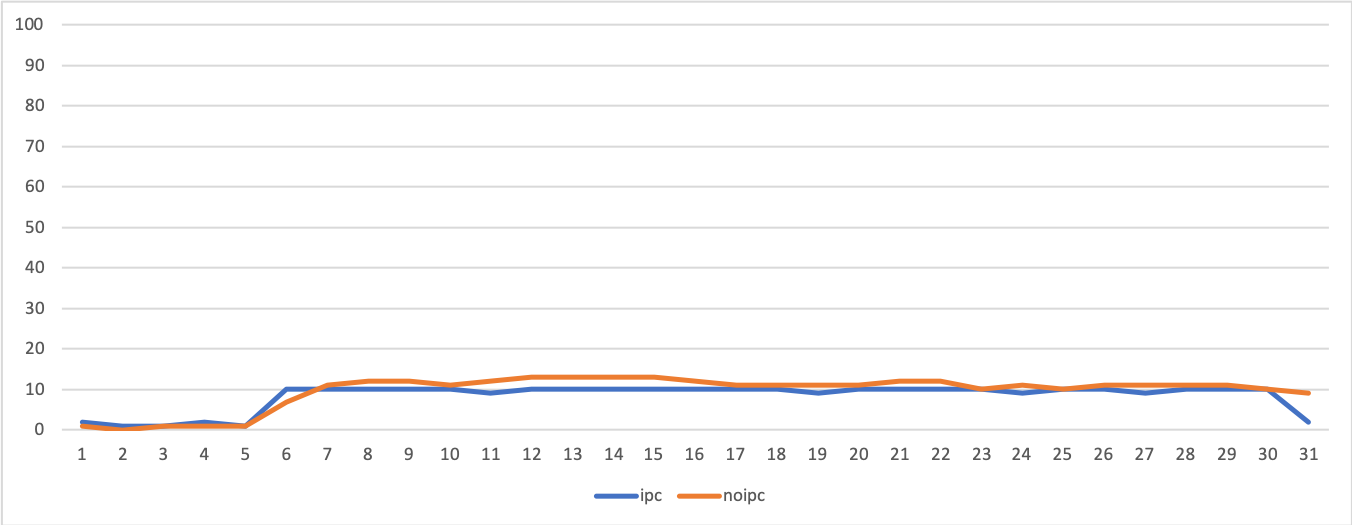
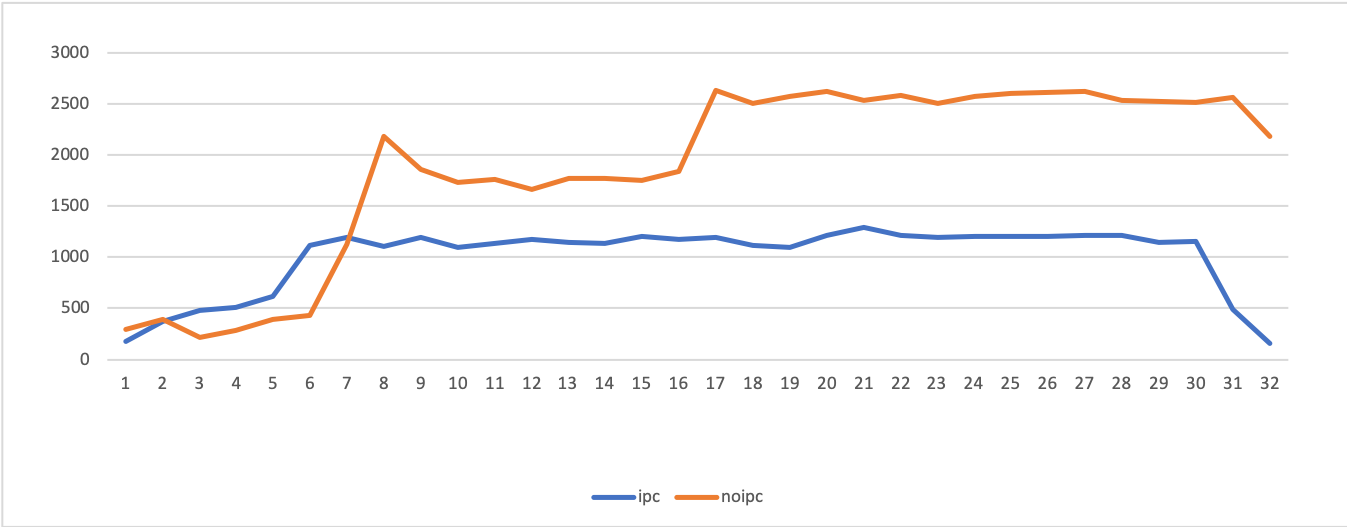
測定結果を折れ線グラフにしました。
以下の3つにおいて「ipc」とラベル付されている青いグラフがexecutorを利用しプロセス内通信を利用した場合、[noipc」とラベル付されているオレンジ色のグラフがノードごとに独立したプロセスを立ち上げた場合です。
(ややこしくてすみません)
ユーザプログラムのCPU使用率(us)
カーネルプログラムのCPU使用率(sy)
コンテキストスイッチの回数(cs)
考察?
結果を見る限りでは「executorを使用する場合CPUをめっちゃ使う」ということはなさそうに思われます。
ユーザプログラムおよびカーネルプログラム両方とも、executorを使用した場合の方が若干高いもののあまり高くありません。
一方、コンテキストスイッチの回数は顕著な差が現れており、ノードをそれぞれ独立プロセスにした方が2倍近い数値になっています。
これは画像出版云々に関係なく、単一プロセスで動かすか複数プロセスで動かすかの差なのでしょうか・・・?
おわりに
ROS2の同一デバイス内画像通信についてかかる時間などを評価したく、色々試してみました。
評価の結果、今まで通り非圧縮画像+FastRTPSを試すのが一番マシなのかな・・・・という感じがしました。
30ms感覚で出版できるなら間違いなくプロセス内通信をするようにしたいのですが・・・・
もっとこういう評価をしたらいいんじゃないか、この結果はこういうことなんじゃないか、などなどのコメント・アドバイス等いただけますととても嬉しいです、お願いします!
それでは、明日以降もROS2アドベントカレンダーをお楽しみください!