はじめに
IBM Match 360は、マスターデータ管理(MDM)を実現するIBMのサービスです。
本記事では、IBM Match 360における「バケツ(bucket)」の情報を確認する方法について、APIを活用した手順を中心に解説します。
IBM Match 360のバケツとは?
IBM Match 360における「バケッティング(bucketing)」とは、候補データを効率的に比較するために、似た特徴を持つレコードをグループ(バケツ)に分ける仕組みです。
膨大なデータを全件突き合わせるのではなく、同じバケツに分類されたレコード同士だけを比較することで、処理速度を大幅に改善しつつ、精度も保ちます。
バケツは通常、氏名や電話番号、住所などの属性をもとにハッシュ値が生成され、その値をもとに共通の特徴を持つレコードが同じバケツに入ります。この仕組みによって、マスターデータ管理におけるマッチング処理が効率化され、一致判定を現実的な時間内で実行することが可能になります。
バケツ情報を取得するには?
バケツの情報を取得するには、IBM Match 360が提供するAPIを利用します。
APIの実行については、下記のAPIページを使って実行コマンドを作成します。
APIを実行するには以下の情報が必要です。
- IBM CloudのIAMトークン
- CRN(Cloud Resource Name)
詳細な手順は、以下の記事の通りですので、ここでは割愛します。
また、本記事では、「IBM Cloud Shell」上でAPIを実行することとします。
「IBM Cloud Shell」は、IBM Cloudをブラウザで開き、右上のアイコンから開きます。
下記のようにコマンドを実行できる画面が表示されます。こちらが「IBM Cloud Shell」です。

バケツ情報の確認
本記事では、下記のステップでバケツ情報を取得し、確認します。
- 名寄せレコードの確認
- バケツ・ハッシュ値の取得
- バケツ情報の取得
- バケツ情報の確認
前提
以下の前提で進めます。
- IBM Match 360の下記のチュートリアルで「タスク4:データモデルの発行とマッチングの実行」まで実施済みであること。
-
APIページのAuthorizeが完了していること。
-
IBM Cloud Shellが使用可能であること。
1. 名寄せレコードの確認
まずは、バケツ情報を確認したい対象の名寄せレコードを確認します。
マスター・データ・ホーム画面を開きます。
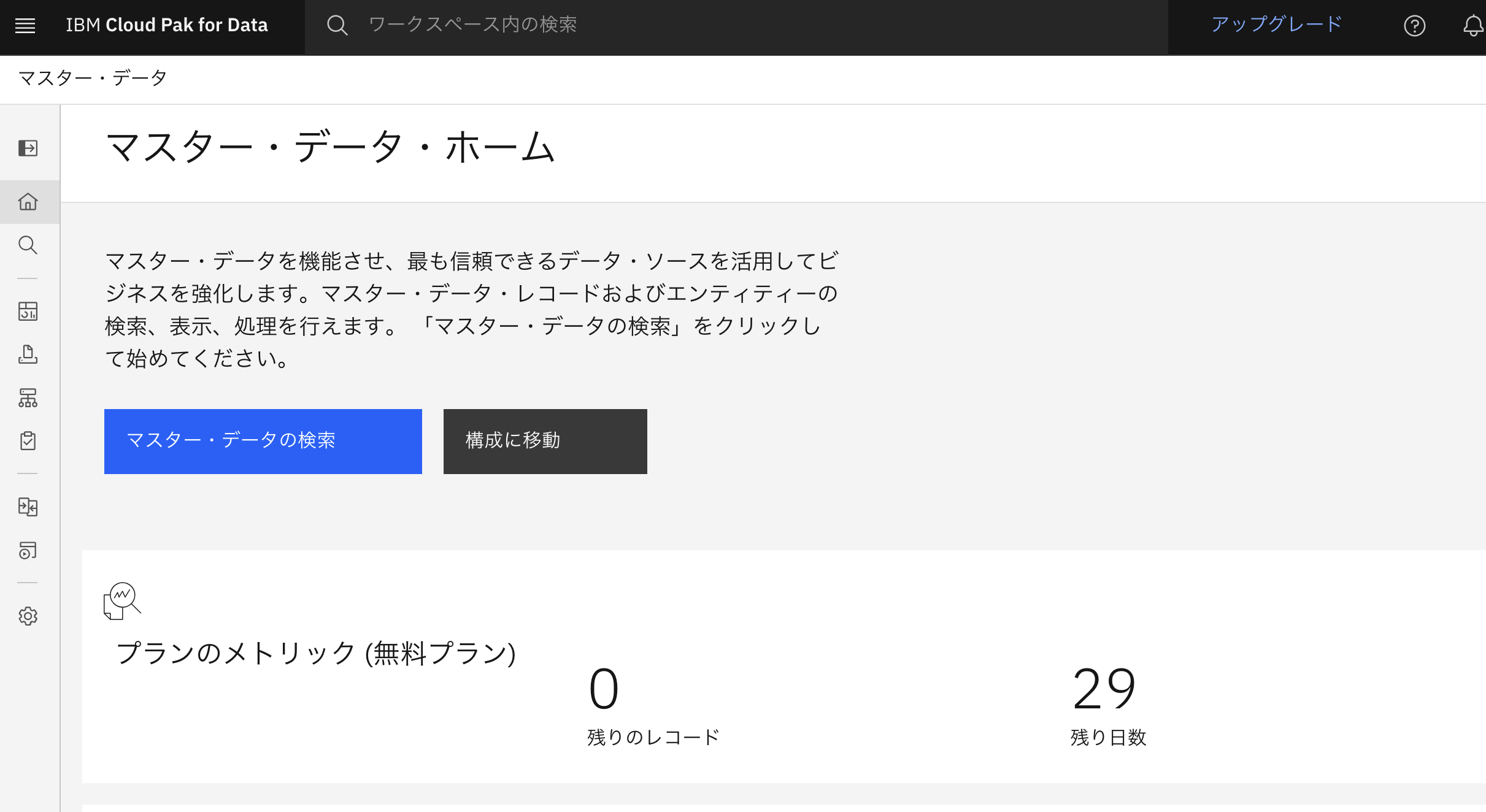
左のメニューから「Search」を開きます。
ここでは、例として検索バーに「Brandon Banks」と入力し、検索してみます。
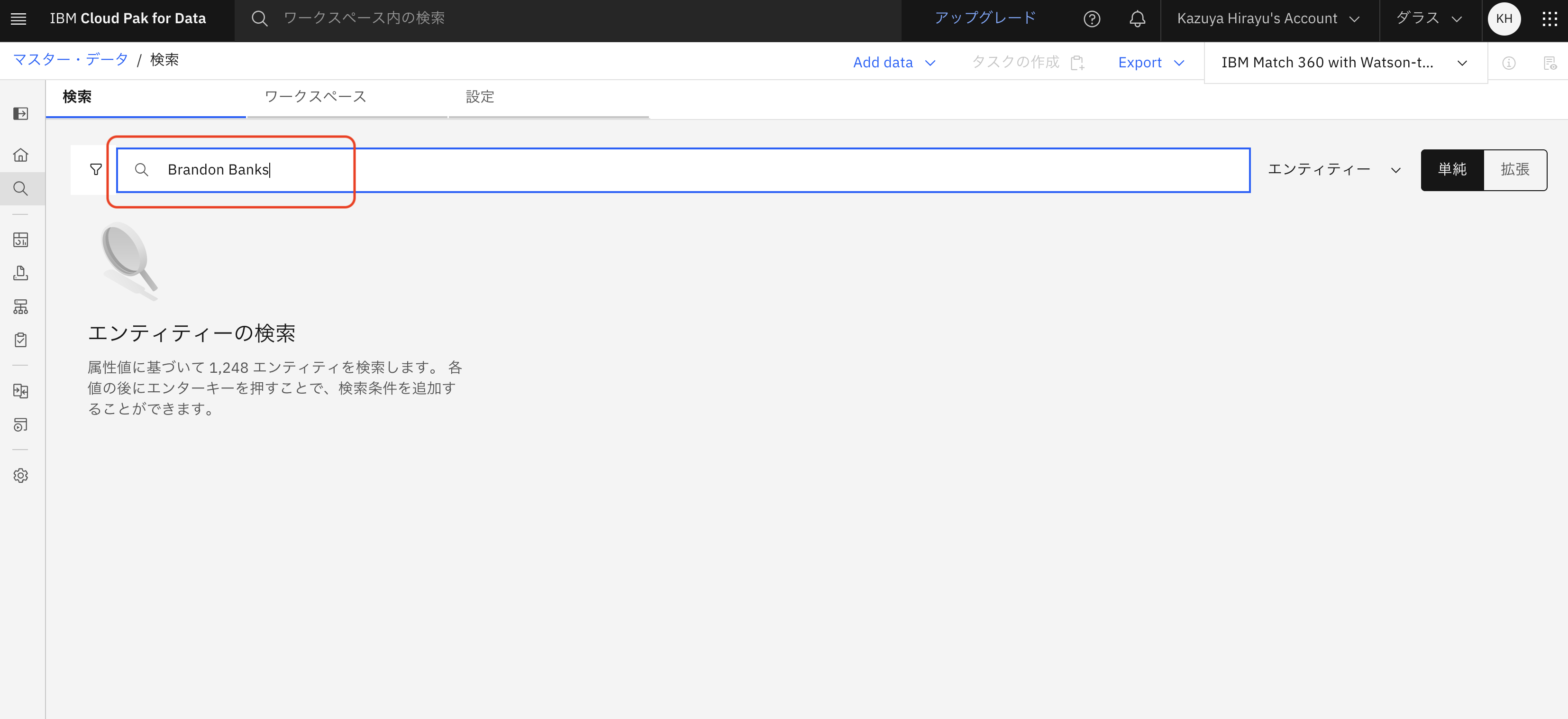
下記のようなマッチングされたデータが表示されました。1行目のエンティティについて、左側にある「>」をクリックし、レコードを確認します。
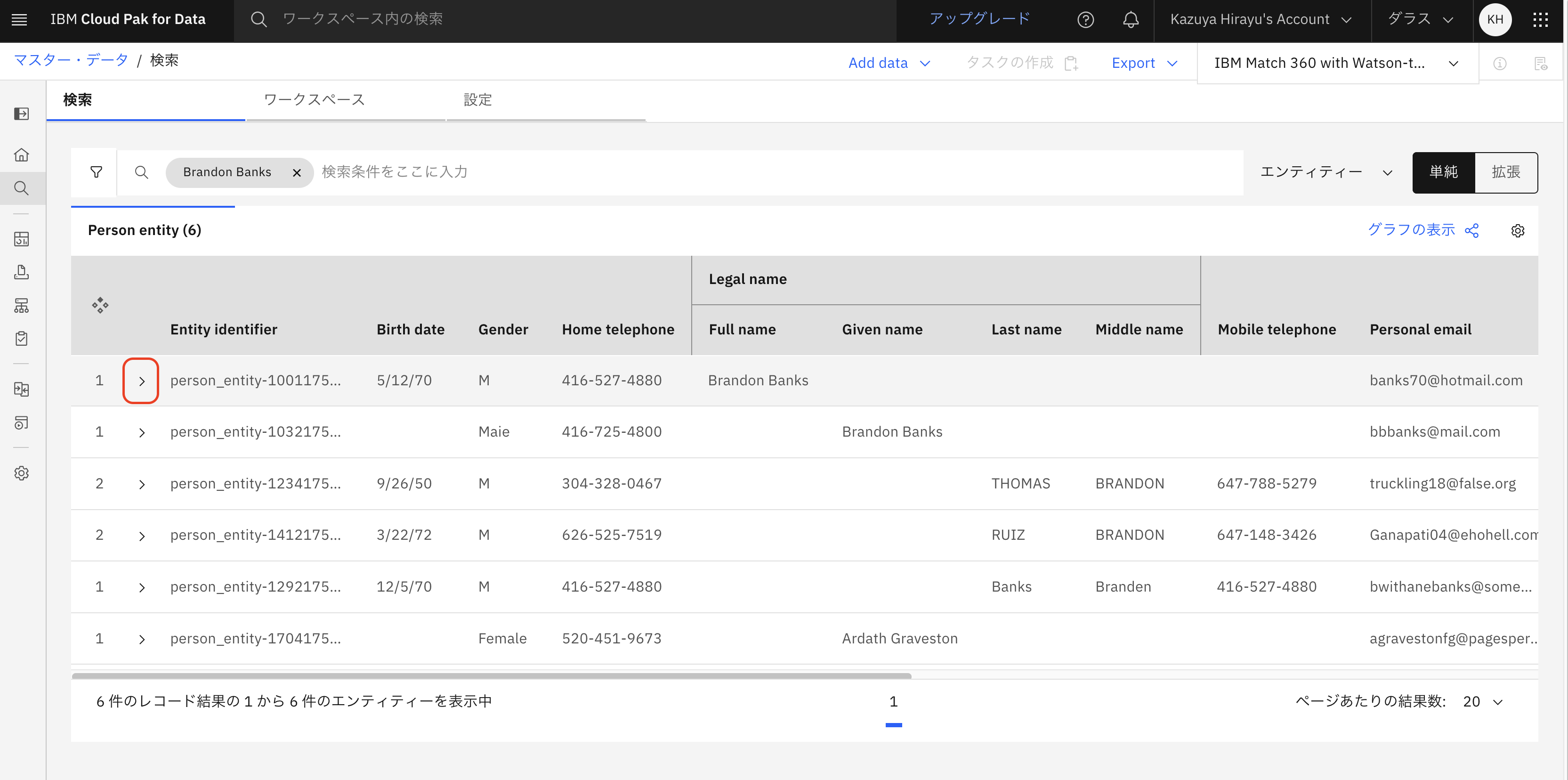
表示されたレコードをクリックします。
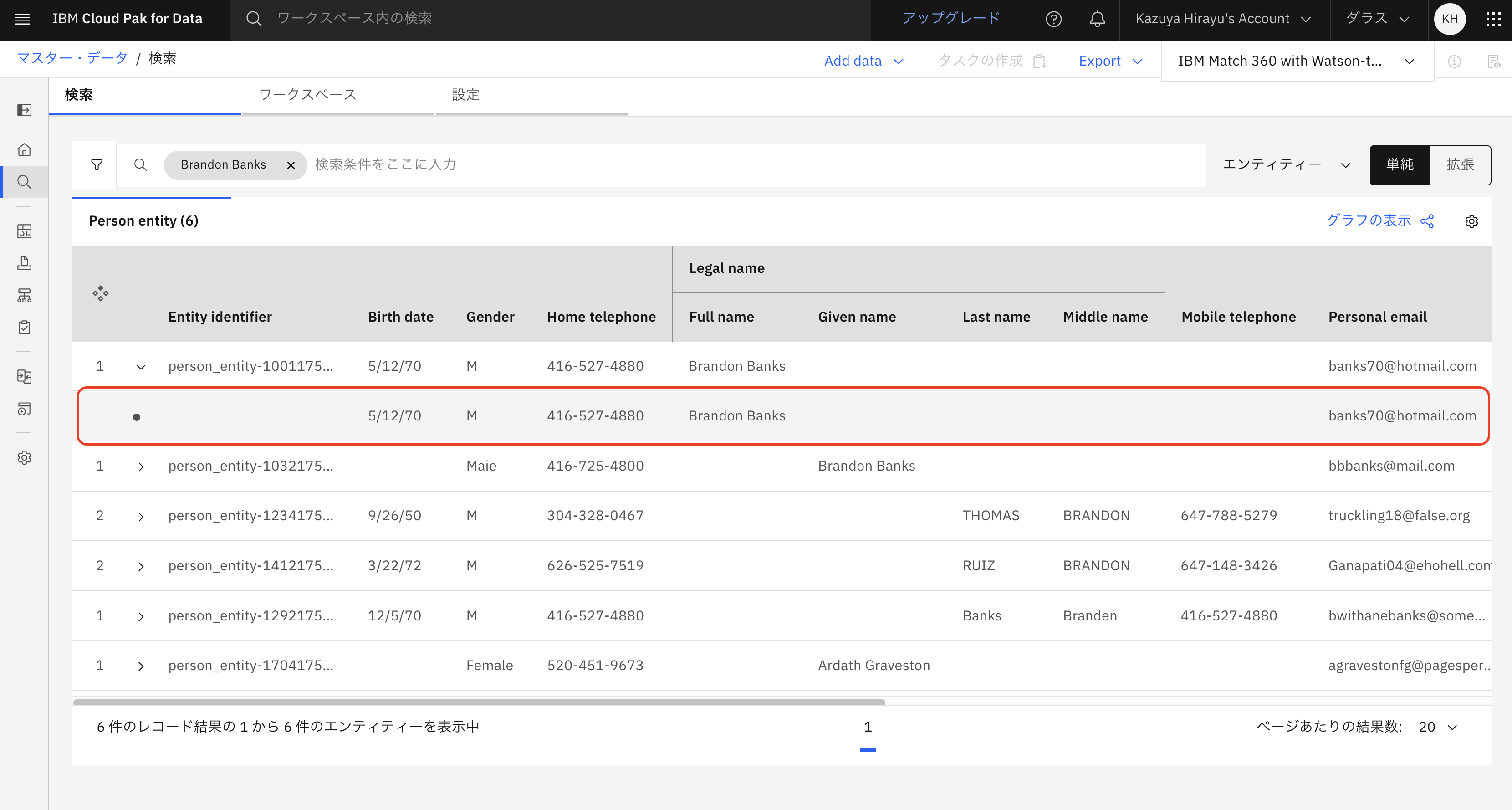
右側に「Personレコードの詳細」が表示されるので、さらに下記の17桁の数字部分をクリックし、レコードの情報を表示します。
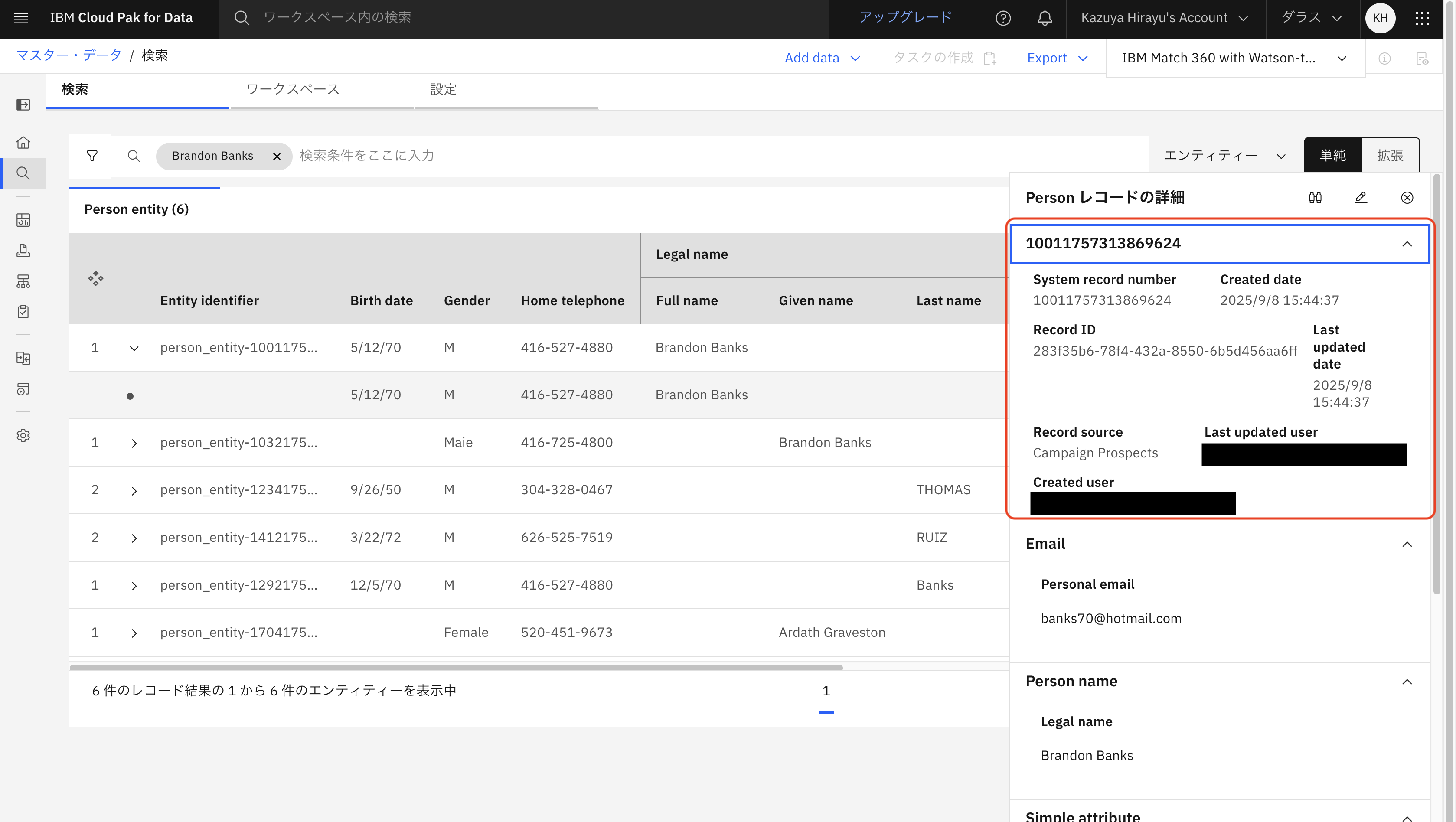
この顧客レコードがどのバケツに入っているかを確認します。
バケツ情報を取得するためには、バケツ・ハッシュ値を取得する必要があります。
2. バケツ・ハッシュ値の取得
次にバケツ・ハッシュ値を取得します。
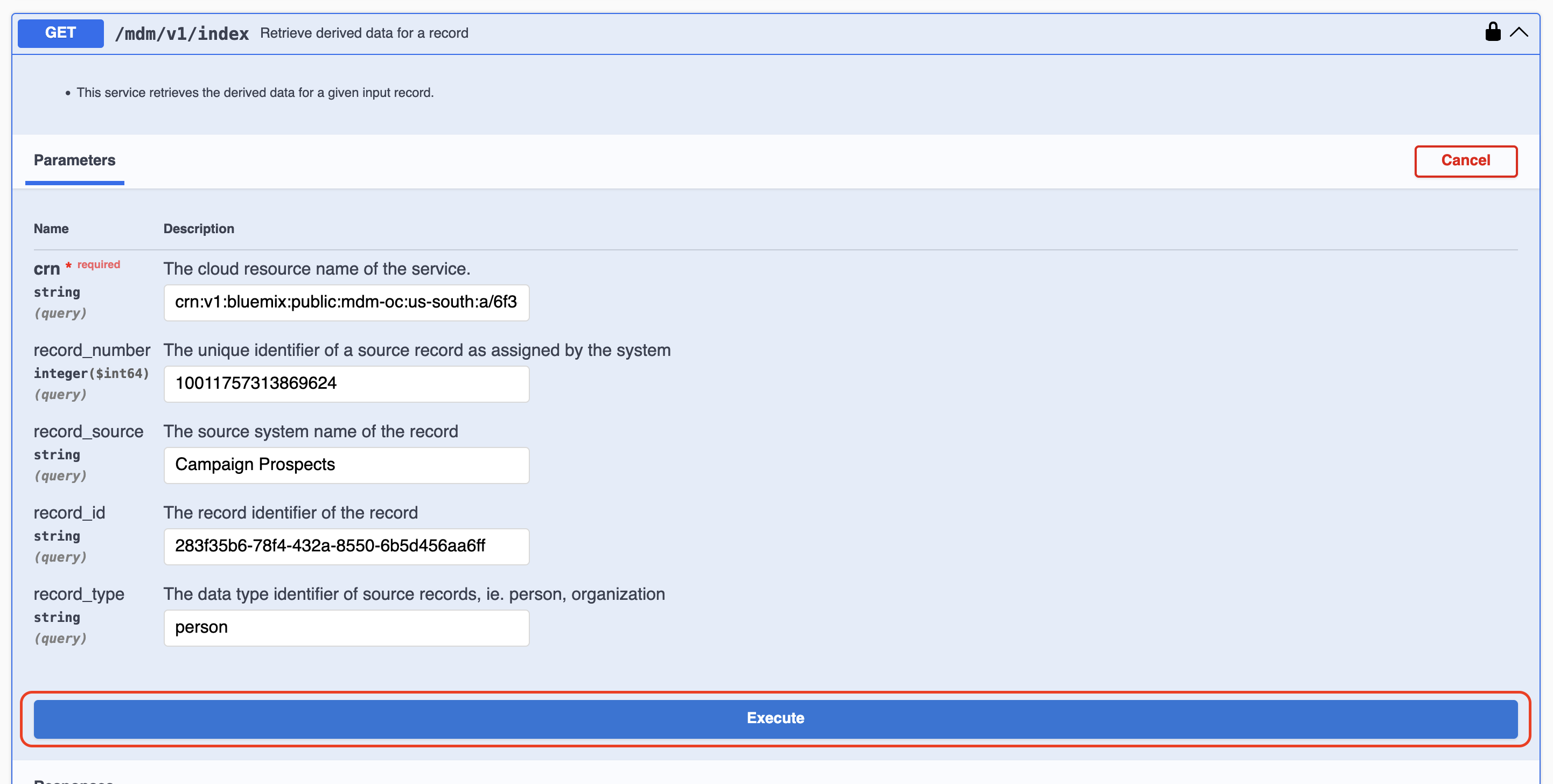
APIページで /mdm/v1/index をクリックして開き、「Try it out」をクリックします。
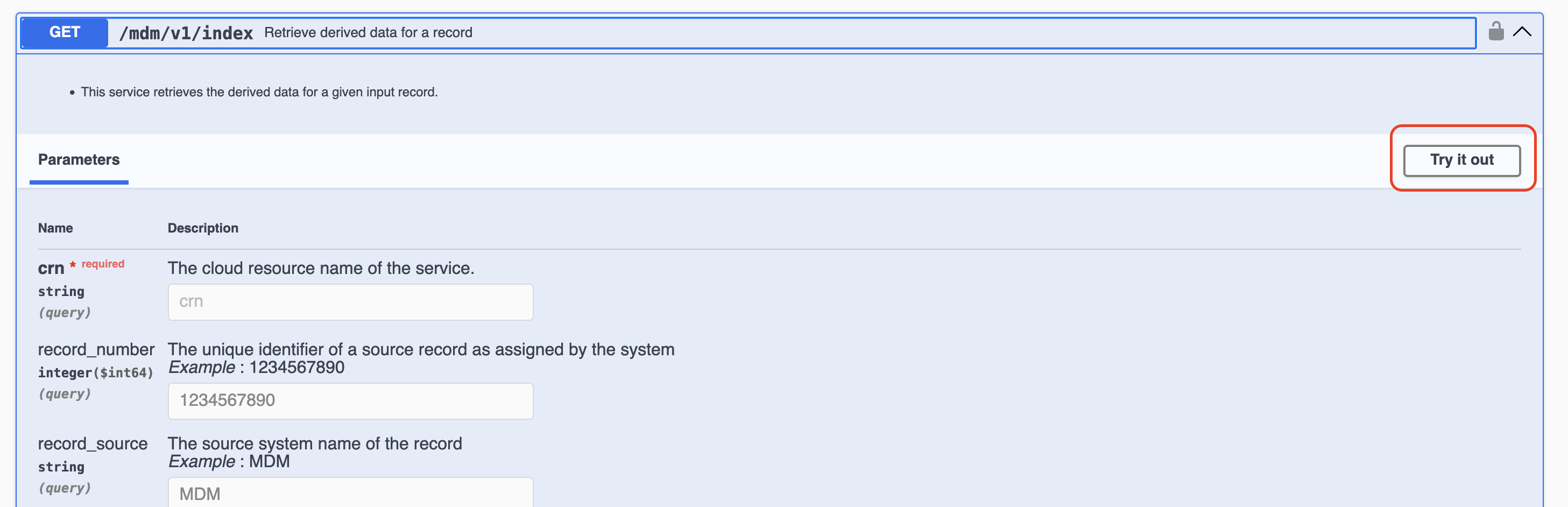
先ほど「Personレコードの詳細」で表示された値を、以下の項目に入力します。
| Name | 値(例) |
|---|---|
| crn | (取得済みのCRN) |
| record_number | 10011757313869624 |
| record_source | Campaign Prospects |
| record_id | 283f35b6-78f4-432a-8550-6b5d456aa6ff |
| record_type | person |
入力したら、「Execute」をクリックします。
注意
APIページの「Execute」から直接APIを実行することも可能ですが、実行が失敗する場合があります。また、バケツ・ハッシュ値が丸められて返されるなど、正しく動作しないケースも確認されています。
そのため本記事では、APIページはコマンド確認用とし、実際の実行は「IBM Cloud Shell」で行う方法を紹介しています。
Responsesのcurlの欄に完成されたcurlコマンドが表示されるので、右下にあるコピーボタンをクリックし、コマンドをコピーします。

「IBM Cloud Shell」を開き、コピーしたコマンドを貼り付け、末尾に「 | jq」を付けて、エンターキーを押します。
※「jq」はResponseのJsonデータを見やすくするためのコマンドです。
実行コマンド例:
curl -X 'GET' \
...(省略)
-H 'Authorization: Bearer ...(省略)' | jq
出力結果例:
{
"record_key": {
"record_id": "283f35b6-78f4-432a-8550-6b5d456aa6ff",
"record_src": "Campaign Prospects",
"record_type": "person"
},
"record_number": "10011757313869624",
"self_scores": {
"person_entity": 184
},
"buckets": [
1632338434714166711,
2013769889038183780,
5694575751643138514,
5005448982474064355,
2961161519390334616,
2934434068362481123,
1275989155841466102,
4922320092744129665,
7484608160338151829
],
"standardized_values": "{\"home_telephone\":[{\"phone\":[\"5274880\"]}],\"gender\":[{\"gender\":[\"M\"]}],\"birth_date\":[{\"birth_day\":[\"05\"],\"birth_month\":[\"12\"],\"birth_year\":[\"XX70\"]}],\"legal_name\":[{\"full_name\":[\"BRANDON\",\"BANKS\"]}],\"personal_email\":[{\"email_domain\":[\"HOTMAIL.COM\"],\"email_local_part\":[\"BANKS70\"]}]}"
}
IBM Cloud Shellでの実行イメージ:
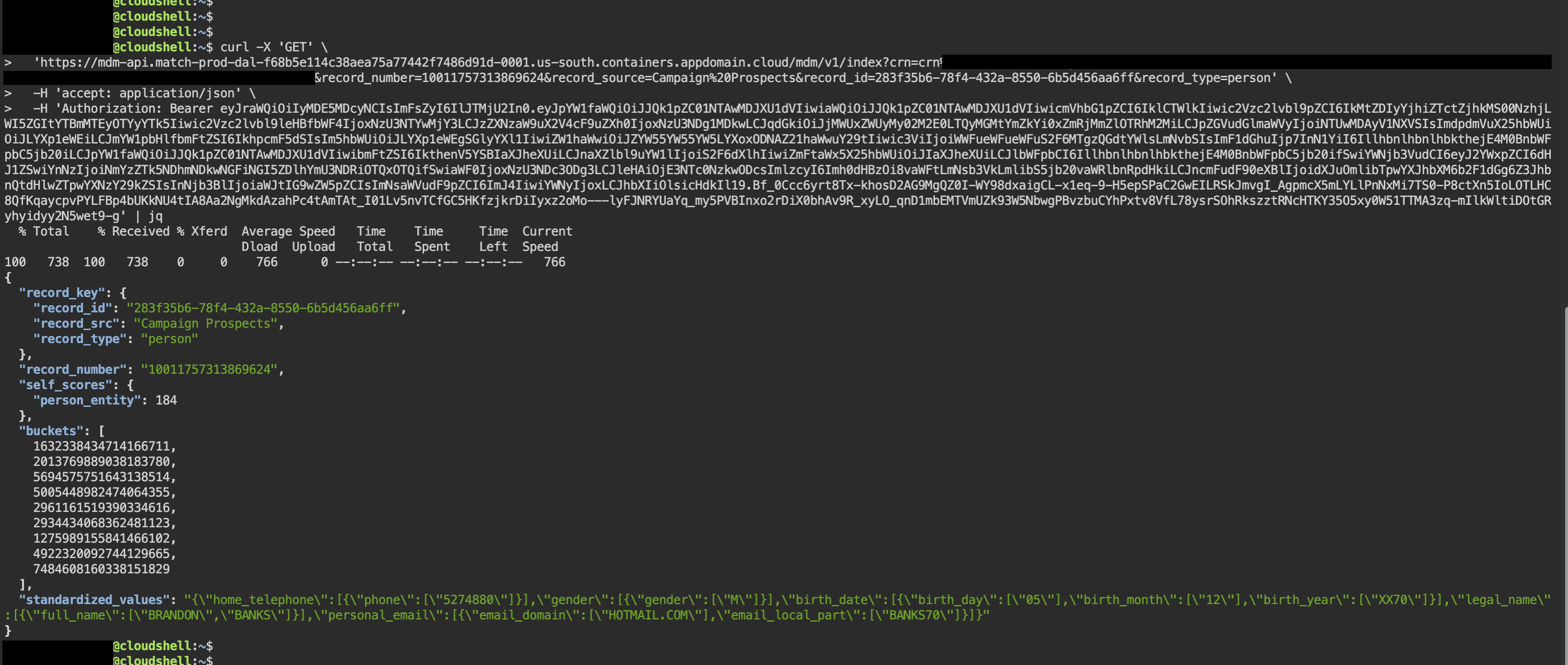
"buckets"のリストの中の値がバケツ・ハッシュ値です。
これにより、複数のバケツ・ハッシュ値が取得できました。
3. バケツ詳細の取得
次に、取得したバケツ・ハッシュ値を使ってバケツの詳細情報を取得します。
APIページで /mdm/v1/bucket_details を開き、「Try it out」をクリック
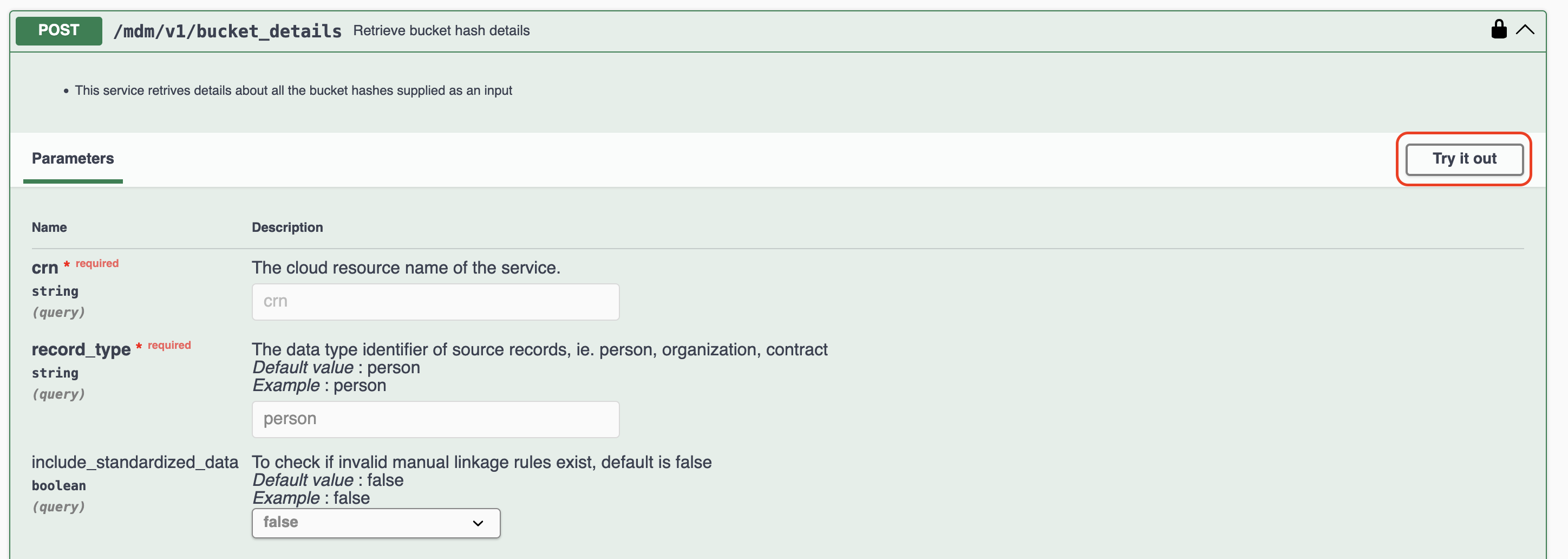
以下の項目を入力します。
| Name | 値(例) |
|---|---|
| crn | (取得済みのCRN) |
| record_type | person |
さらに、Request bodyのEdit Valueの内容を編集し、情報を取得したいバケツ・ハッシュ値を入力します。今回は取得したバケツ・ハッシュ値の中の1632338434714166711を指定します。
入力したら、先ほどと同様に「Execute」をクリックし、完成されたcurlコマンドをコピーします。
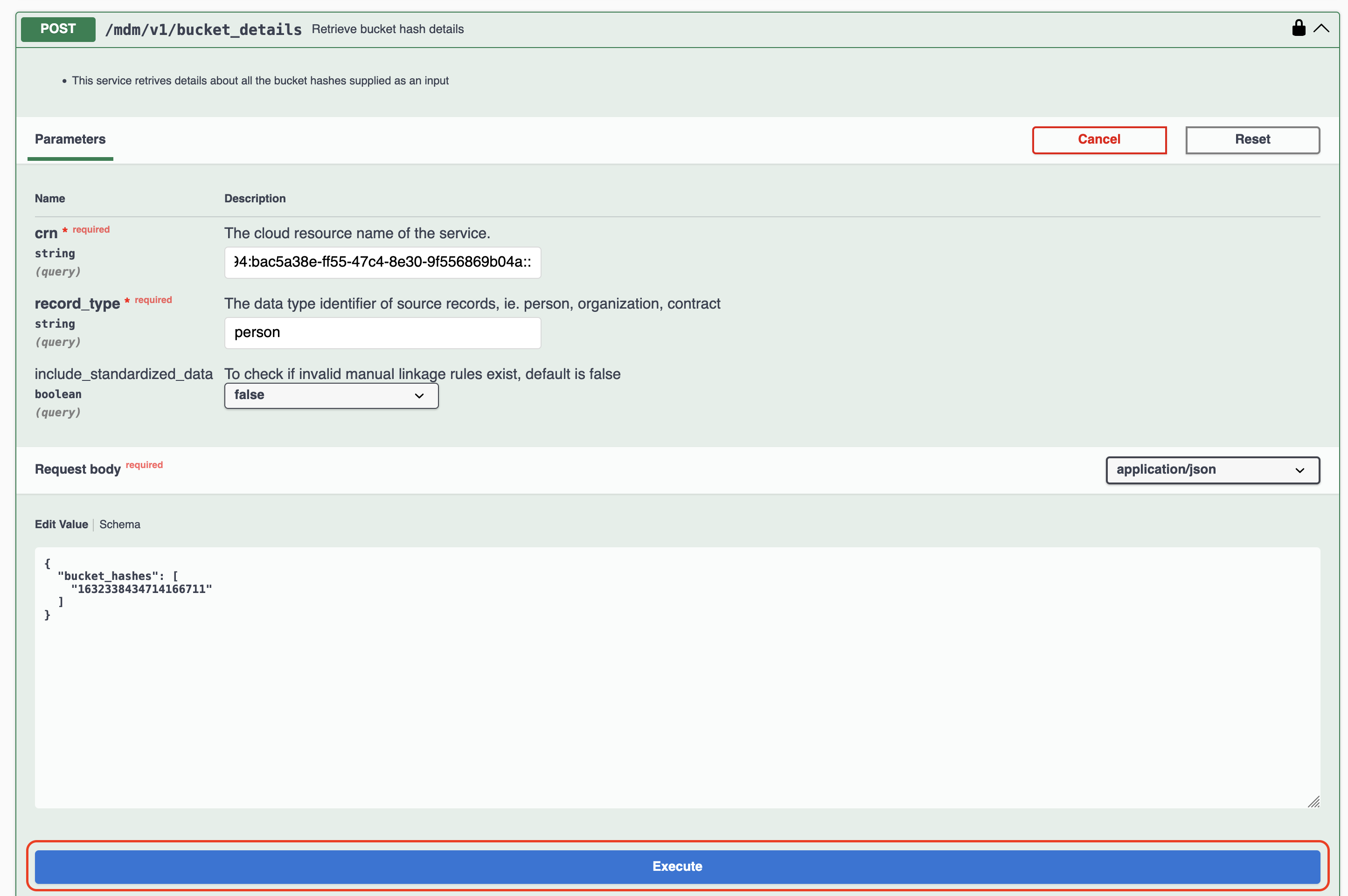

先ほどと同様に「IBM Cloud Shell」を開き、コピーしたコマンドを貼り付け、末尾に「 | jq」を付けて、エンターキーを押します。
出力結果例:
{
"1632338434714166711": {
"candidate_records_count": 14,
"bucket_group": 1,
"member_records": [
"11011757314086515",
"10011757313869624",
"13741757313863996",
"12341757313863996",
"18131757313989983",
"14111757313992969",
"16521757313989849",
"10321757313990684",
"15441757313863996",
"19641757313986960",
"11641757313863996",
"14121757313869562",
"10911757313982861",
"18131757313981009"
],
"isLarge": false,
"contributing_prehashed_value": "BRNT"
}
}
これにより、バケツの情報が取得できました。
4. バケツ情報の確認
取得したバケツ情報を確認します。
Responseの各項目については下記のとおりです。
| 項目名 | 説明 |
|---|---|
| is_large | バケットハッシュが大きいかどうかを示すブール値 |
| candidate_records_count | 指定されたバケットハッシュ内のメンバーレコード数 |
| bucket_group | バケツグループ識別子 |
| contributing_prehashed_value | バケツ・ハッシュ値生成に使用されたレコード属性から作成された文字列 |
| member_records | バケツに含まれるメンバーレコード番号の一覧 |
APIマニュアル:
contributing_prehashed_valueを参照すると、バケツ・ハッシュ値の生成で使用されたレコードの属性から導出された文字列値はBRNTであることがわかります。
また、is_largeがfalseであるため、このバケツは極端に大きくないことが分かります。バケツが過度に大きいと比較対象が増え、マッチング処理の性能に影響する可能性がありますが、今回その心配は少ないと言えます。
さらに、candidate_records_countの情報から、このバケツには14件のレコードが含まれていることが分かります。バケツに入っているレコード数が極端に少ないと、本来同一と判定すべきレコードが異なるバケツに分かれてしまい、名寄せ漏れにつながる恐れがあります。そのため、candidate_records_countの値を確認することで、レコード数が適切かどうかを判断できます。
まとめ
本記事では、IBM Match 360におけるバケツ情報の取得手順を紹介しました。APIを活用することで、マッチング処理の効率性や精度に直結するバケツの状態を確認できることをご理解いただけたかと思います。
参考