この記事はTensorFlow Advent Calendar 2020の19日目の記事です。
2019年08月20日:Deep写輪眼V1
「【Tensorflow】Object DetectionでDeep写輪眼」を投稿しました。
そう、__Deep写輪眼__の研究は1年以上前から始まっていたのです。
当初、印を認識するための手法として「Object Detection」と「Hand Pose Estimation」を考えました。
しかし、印の性質上、常に片方の手が、もう片方の手によるオクルージョンにさらされます。
その頃の「Hand Pose Estimation」モデルでは、隠れた手の推定は難しかったため、
「Object Detection」による認識に挑戦しました。
- フレームワーク:Tensorflow1系 Object Detection API
- モデル:MobileNet v2 SSD
- 学習画像:約2000枚(自分で撮影した画像+アニメ画像)
- 印の種類:12種類(子~亥)
上記の条件で物体検出モデルを訓練しました。
その結果が以下の動画です。
夏休みの自由研究で、NARUTOの印をObject Detection🐤
— 高橋 かずひと@孫請級プログラマー🦔 (@KzhtTkhs) August 18, 2019
正直、組手をObject Detectionして、そのあと、Classificationで分類した方が良い気もする。。。🐤🐤pic.twitter.com/K1pdBCsiau
見てわかるように「子」「未」「申」の検出精度が少々低いです。
「子」「未」「申」は以下の印です。



このままでは忍び同士の戦闘での使用に耐えません。
検出精度に不満は残るものの「Object Detection」での印認識の実現性を予感させる動きをしています。
この時点の__Deep写輪眼__を仮に「Deep写輪眼V1」と呼称します。特に呼び方に意味はありません。
2020年10月2日:Deep写輪眼V2
時は流れ、Tensorflow2のObject Detection APIがリリースされました(2020年7月11日)
EfficientDet、CenterNet、RetinaNetが新たにサポートされた強力なAPIです。
(少々怪しい挙動があったり、動かないチュートリアルがあったり、メモリ食いすぎじゃねえ?って思うことがあったり、Tensorflow-Liteへの変換がSSD系しかサポートしていなかったりしますが、強力なAPIです)
Tensorflow2 Object Detection APIの使い方を確認しつつ、
新たにデータセットを集め、以下条件でモデルを訓練しました。
- フレームワーク:Tensorflow2系 Object Detection API
- モデル:EfficientDet-D0
- 学習画像:約5000枚
(自分で撮影した画像+アニメ画像+Naruto Hand Sign Dataset) - 印の種類:14種類(子~亥、壬、合掌)
※壬と合掌を追加することによって、NARUTO一コスパの悪い術(水遁・水龍弾の術)、
NARUTO一卑劣な術(穢土転生の術)に対応可能となる見込み
結果が以下の動画です。
Deep写輪眼の現時点の完成度です🦔 pic.twitter.com/KEyURRlZQY
— 高橋 かずひと@孫請級プログラマー🦔 (@KzhtTkhs) October 2, 2020
検出精度が改善しています。
「水遁・水龍弾の術」もあと一歩のところまで来ています。
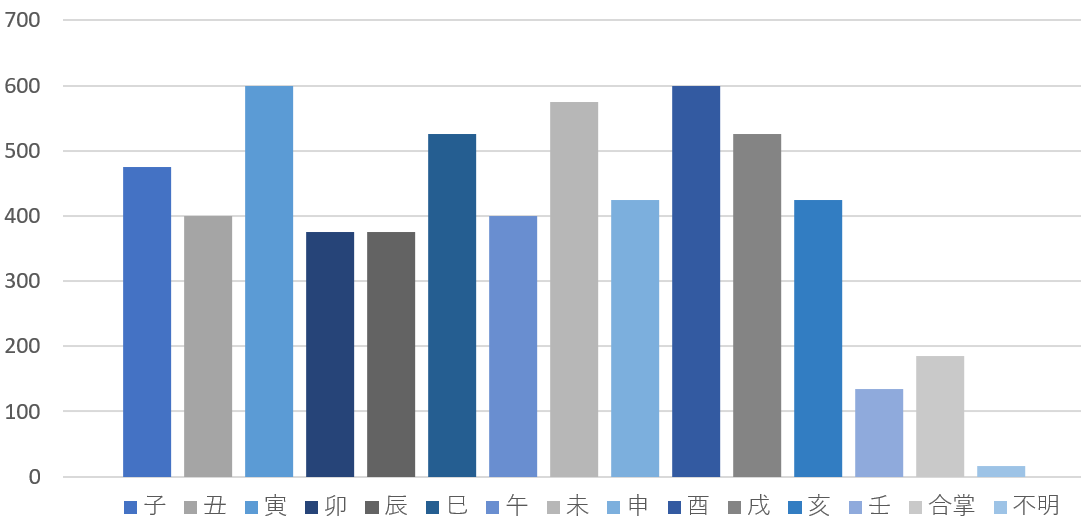
ただし、新たに追加した「壬」が「申」と似ているため、誤検出が少々目立ちます。
グラフを後述しますが、新たに追加した「壬」と「合掌」のデータ数が少なく不均衡になっていることも要因の一つかと思います。
まだまだ改善の余地はあるものの「EfficientDet」の検出能力の高さを実感できました。
この時点の__Deep写輪眼__を仮に「Deep写輪眼V2」と呼称します。特に呼び方に意味はありません。
2020年10月10日:Deep写輪眼V2 Githubリポジトリ公開
服装や背景の色柄によっては不安定になることはありますが、多少遊べるレベルに達したと判断したため、Githubで訓練済みモデル&サンプルプログラムを公開しました。

また、からあげさんがGoogle Colaboratoryでお手軽に試すことのできるノートブックを作成してくれました。
ありがとうございます。
ネットワークを経由するため少々の遅延はありますが、雰囲気を体感できます。
.@KzhtTkhs さんの「Deep写輪眼」ブラウザ上で動くGoogle ColabのNotebook作ってみました。カメラ付きのPCなら、ChromeブラウザでアクセスしてクリックしていけばDeep写輪眼ができます https://t.co/l8fpPrUH1l
— からあげ (@karaage0703) October 13, 2020
利用ツール
学習モデル作成やプロトタイプは、からあげさんの「object_detection_tools」を参考にいたしました。

データセット
データセットは非公開です(訓練済みのモデルは公開しています)
以下の枚数を使用しています。
総枚数:6377枚(内アニメ画像:2651枚)
タグ付き枚数:4903枚
タグ無し枚数:1474枚
アノテーションボックス数:6037個
データ拡張
学習時には以下のデータ拡張を実施しています。
random_horizontal_flip:左右反転
※上下反転をすると「巳」と「亥」を混同するためvertical_flipは未指定
random_rgb_to_gray:グレースケール
random_adjust_brightness:明度変更
random_adjust_contrast:コントラスト変更
random_adjust_hue:色相変更
random_adjust_saturation:彩度変更
random_distort_color:明度、コントラスト、色相、彩度の変更をランダムに適用
random_black_patches:黒点付与
random_crop_image:画像切り抜き
random_absolute_pad_image:パディング付与
random_self_concat_image:同画像の連結
random_scale_crop_and_pad_to_square:ランダムスケールクロップ
公開モデル
以下のモデルをリポジトリにて公開しています。
- EfficientDet D0
- MobileNetV2 SSD FPNLite 640x640
- MobileNetV2 SSD FPNLite 640x640(TensorFlow Liteモデル)
- MobileNetV2 SSD 300x300
おわりに
昨年作成したDeep写輪眼V1に比べて大分精度が向上しました。
(MobileNetv2-SSDとEfficientDet-D0では当然と言えば当然ですが)
今後はTensorflow-Lite化してスマートグラスに載せたり、より良いモデルが出たら、そちらで再訓練したいと思っています。
次は、12/20:tonouchi510様の「tf2での開発の個人的ベストプラクティスを書こうと思います。」です。