前回の記事でPrometheus + Grafanaの監視基盤を構築して、Minecraftサーバを監視対象に追加しました。
今回、何を持って障害とするのか(通知するのか)を、改めて考えてアラートルールを作成しました。
監視を導入すると、メトリクスの取得や可視化は比較的スムーズに進みますが、
アラートの設計は別の難しさがあります。
一度アラートを設定し始めると、とりあえず検知できる状態にはなりますが、
- 通知が多くなりすぎる
- 重要度の判断が必要になる
- 運用の負担が増える
といった課題が発生しやすくなります。
そのため今回は、
- 何を検知すべきか
- 何は通知しなくてよいか
を整理しながら、アラートルールを見直しました。
「すべてを検知する」のではなく、
“対応が必要なものだけ通知する”状態を目指します。
Observabilityへの道シリーズ
このシリーズでは、監視スタックを段階的に構築しながら「見える化」から「使える監視」へと進めていきます。
1.Prometheusでメトリクス監視を構築
https://qiita.com/KanshiKun/items/1176246d27e52be652eb
2.AlertmanagerでSlack通知
https://qiita.com/KanshiKun/items/c56754fa6baaffec5de0
3.Grafanaでメトリクス可視化
https://qiita.com/KanshiKun/items/5979d2aaed5221ce0a1e
4.Minecraftサーバ監視
https://qiita.com/KanshiKun/items/65446702d765ec580d7a
5.Mincraftサーバの障害を定義(アラートルール作成)
https://qiita.com/KanshiKun/items/8f8239b65639e9d3c749
6.AWSを監視拠点にした外形監視の実装
https://qiita.com/drafts/5002eb89d4019ed96ccc/edit
7.Loki × Promtail × Grafanaでログを可視化する
https://qiita.com/KanshiKun/items/4b768d00433d1b5f700b
8.ログから監視を設計する 〜「何が起きているか」を捉える〜
https://qiita.com/drafts/6642323ec0b45368e932/edit
今回やること
- アラートルールの検討
- アラートルールの適用(Prometheus再起動)
- 通知テスト
アラートルールの検討(設計思想)
今回は「ユーザーが使える状態かどうか」を基準に設計しました。
- サーバが落ちているか(状態)
- 遅くなっていないか(品質)
この2つを分けて考えています。
設計方針
- 明確に障害と言えるもののみ通知する
- 一時的な揺らぎは
forで吸収する - 状態と品質を分ける
- 段階的に重要度を分ける
アラートルール
groups:
- name: minecraft-bedrock-alert
rules:
- alert: MinecraftBedrockDown
expr: minecraft_status_healthy{server_edition="bedrock"} == 0
for: 2m
labels:
severity: critical
annotations:
summary: "Bedrock server is down"
description: "Minecraft Bedrock server is not responding for 2 minutes."
- alert: MinecraftBedrockHighLatency
expr: (
minecraft_status_healthy{server_edition="bedrock"} == 1
)
and
(
minecraft_status_response_time_seconds{server_edition="bedrock"} > 1
)
for: 5m
labels:
severity: warning
annotations:
summary: "Bedrock server latency is high"
description: "Minecraft Bedrock response time is above 1 second for 5 minutes."
- alert: MinecraftBedrockVeryHighLatency
expr: (
minecraft_status_healthy{server_edition="bedrock"} == 1
)
and
(
minecraft_status_response_time_seconds{server_edition="bedrock"} > 3
)
for: 5m
labels:
severity: critical
annotations:
summary: "Bedrock server latency is very high"
description: "Minecraft Bedrock response time is above 3 seconds for 5 minutes."
ルールごとの設計意図
サーバダウン(critical)
expr: minecraft_status_healthy{server_edition="bedrock"} == 0
for: 2m
完全に応答がない状態を検知します。
for: 2m により瞬断を除外しています。
👉 誰が見ても障害と言える状態のみ通知
高遅延(warning)
expr: minecraft_status_response_time_seconds{server_edition="bedrock"} > 1
for: 5m
ユーザー体験が悪化し始める状態を検知します。
すぐに対応が必要とは限らないため、warningとして扱います。
👉 兆候としての通知(様子を見る)
極端な高遅延(critical)
expr: minecraft_status_response_time_seconds{server_edition="bedrock"} > 3
for: 5m
明確にプレイに支障が出るレベルの遅延です。
継続している場合は障害と判断します。
👉 対応が必要な状態として通知
設計で意識したポイント
状態と品質を分離
- Down:状態異常
- Latency:品質劣化
重複アラートの防止
Latencyアラートでは以下の条件を含めています。
minecraft_status_healthy{server_edition="bedrock"} == 1
これにより、DownとLatencyが同時に通知されることを防ぎます。
段階的な通知設計
- warning:兆候
- critical:障害
これにより、判断負荷を下げています。
アラートルール適用
docker restart prometheus
通知テスト
サーバ停止
- アラート発火:OK
- 通知:OK


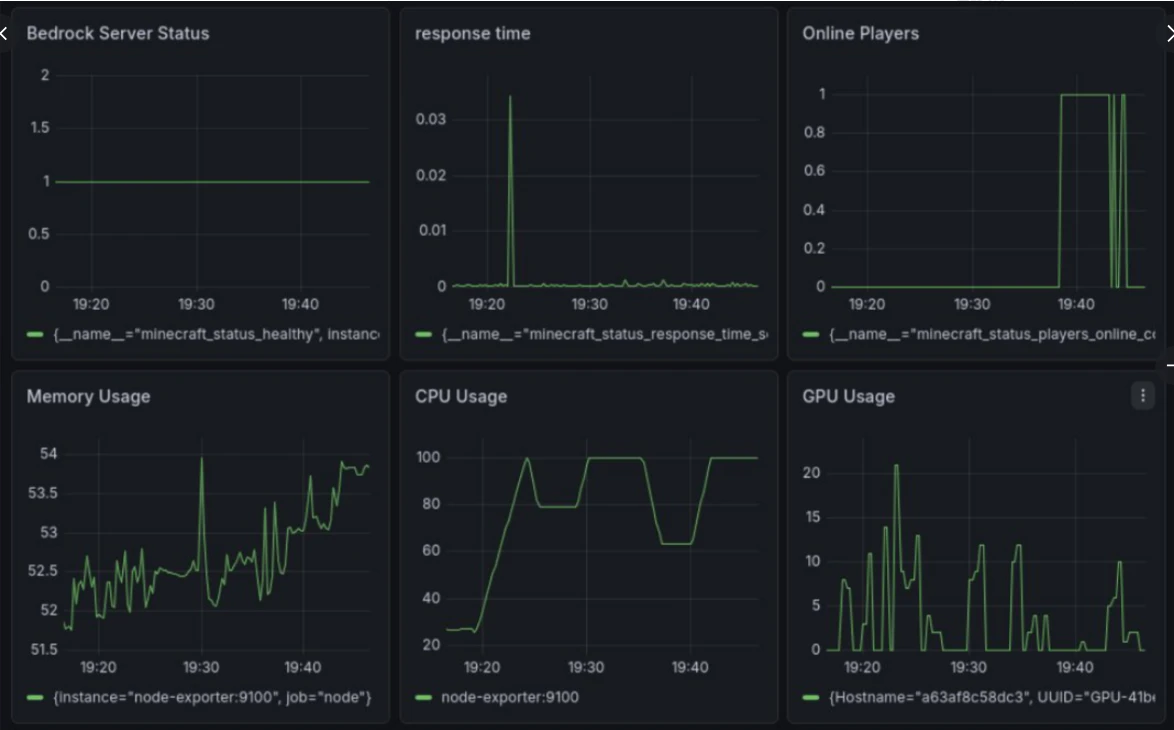
CPUに負荷をかけ遅延検証
docker exec -it mc-bedrock stress-ng --cpu 16 --timeout 300
- アラート発火:NG
CPU性能が高く、CPUが100%に達しても一瞬のスパイクはあったものの遅延は発生しませんでした。
振り返り
- 検知できることと通知すべきことは違う
- アラートは設計しないと増え続ける
- 通知は対応が必要なものだけに絞る
次のステップ
外形監視をさらに活用し、
- ユーザーが使えるか
- 体験が劣化していないか
をより精度高く見ていきます。
まとめ
- アラートは「全部通知」ではなく設計が重要
- 障害の定義を明確にする
- 通知は行動に直結するものだけにする