はじめに
Prometheusでメトリクス監視を構築すると、メトリクスは取得できるものの
「データは取れているが見づらい」と感じることがあります。
そこで活躍するのが Grafana です。
Grafanaを使うことで、Prometheusで収集したメトリクスを
CPU・メモリ・ディスク・ネットワークなどのダッシュボードとして可視化できます。
以下はGrafanaで作成できるダッシュボードの例です。
※このダッシュボードはGrafana公式コミュニティダッシュボード
「Node Exporter Full(ID:1860)」を利用しています。
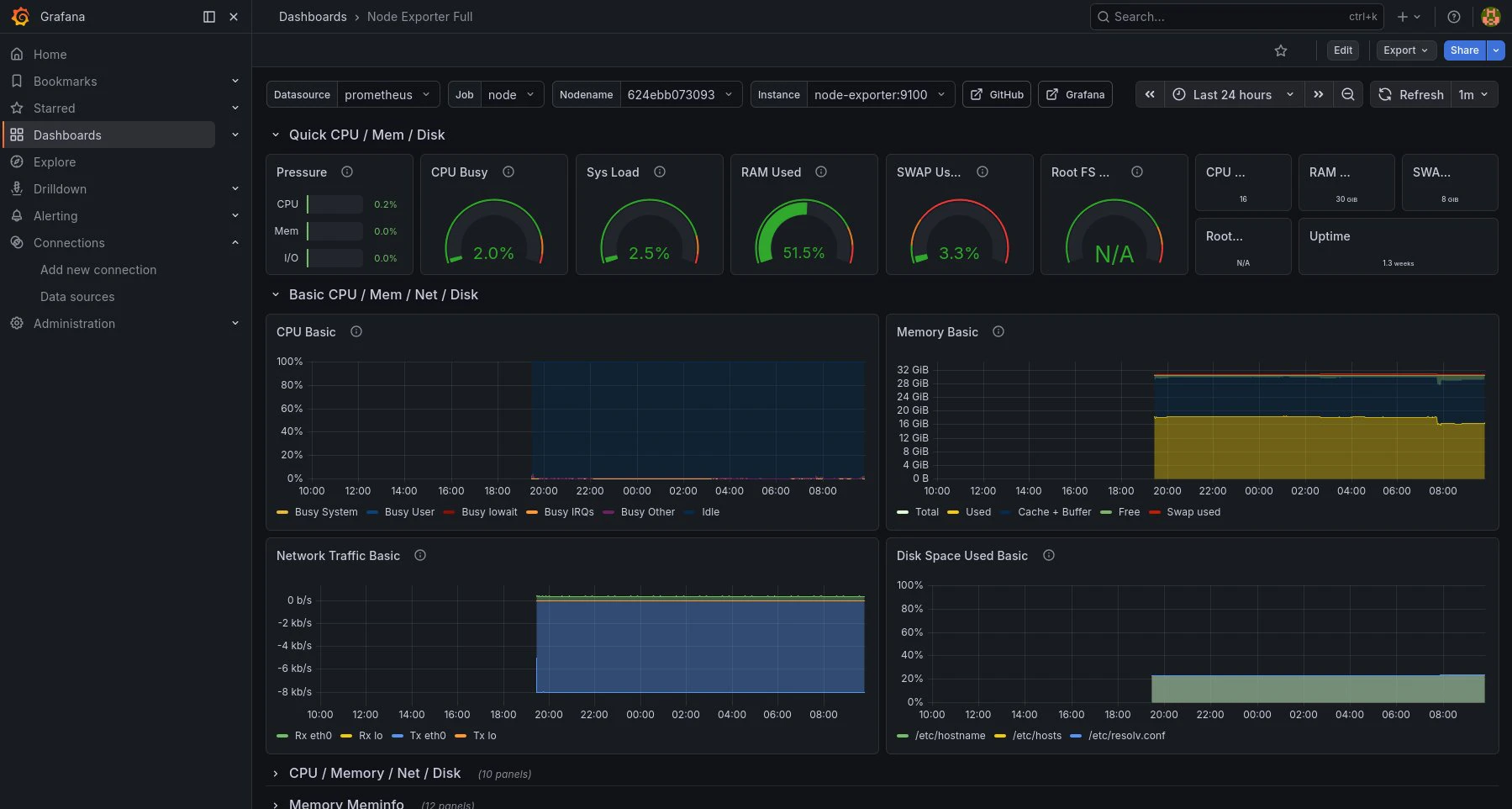
このようなダッシュボードを一から作り込むのは大変です。
そこでこの記事では、まず CPU・メモリ・GPUのメトリクスをGrafanaで可視化するところまで を紹介します。
Observabilityへの道シリーズ
このシリーズでは、監視スタックを段階的に構築しながら「見える化」から「使える監視」へと進めていきます。
1.Prometheusでメトリクス監視を構築
https://qiita.com/KanshiKun/items/1176246d27e52be652eb
2.AlertmanagerでSlack通知
https://qiita.com/KanshiKun/items/c56754fa6baaffec5de0
3.Grafanaでメトリクス可視化
https://qiita.com/KanshiKun/items/5979d2aaed5221ce0a1e
4.Minecraftサーバ監視
https://qiita.com/KanshiKun/items/65446702d765ec580d7a
5.Mincraftサーバの障害を定義(アラートルール作成)
https://qiita.com/KanshiKun/items/8f8239b65639e9d3c749
6.AWSを監視拠点にした外形監視の実装
https://qiita.com/drafts/5002eb89d4019ed96ccc/edit
7.Loki × Promtail × Grafanaでログを可視化する
https://qiita.com/KanshiKun/items/4b768d00433d1b5f700b
8.ログから監視を設計する 〜「何が起きているか」を捉える〜
https://qiita.com/drafts/6642323ec0b45368e932/edit
Grafanaとは
Grafanaはオープンソースの可視化ツールです。
Prometheusなどのデータソースを接続することで
ダッシュボードを作成できます。
監視スタックでは次のような役割になります。
Exporter
↓
Prometheus(メトリクス収集)
↓
Alertmanager(通知)
↓
Grafana(可視化)
Prometheusが収集したメトリクスをGrafanaが読み取り、
ダッシュボードとして表示します。
システム構成
構成は以下となります。
Prometheusが収集したメトリクスをGrafanaが参照して可視化します。
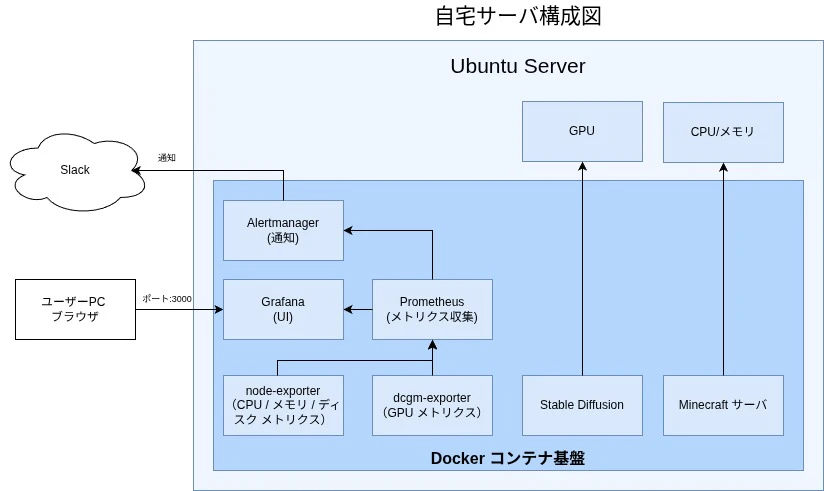
GrafanaをDockerで起動
Prometheus環境にGrafanaを追加します。
docker-compose.yml
version: '3'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml:ro
- ./alert.rules.yml:/etc/prometheus/alert.rules.yml:ro
ports:
- "9090:9090"
restart: unless-stopped
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
ports:
- "9100:9100"
restart: unless-stopped
dcgm-exporter:
image: nvcr.io/nvidia/k8s/dcgm-exporter:latest
container_name: dcgm-exporter
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
ports:
- "9400:9400"
restart: unless-stopped
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml:ro
ports:
- "9093:9093"
restart: unless-stopped
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
volumes:
- grafana-data:/var/lib/grafana
restart: unless-stopped
volumes:
grafana-data:
コンテナ起動
docker compose up -d
起動確認
docker ps
Grafanaコンテナが起動していればOKです。
Grafanaへアクセス
ブラウザからアクセスします。
http://localhost:3000
初期ログイン
user : admin
password : admin
初回ログイン時にパスワード変更を求められます。
Prometheusをデータソースに追加
Grafanaにログイン後、Prometheusをデータソースとして登録します。
Connections
↓
Data sources
↓
Add data source
↓
Prometheus
URLを設定
http://prometheus:9090
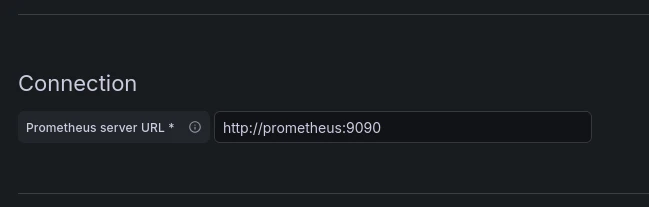
画面の一番下にあるSave & Test を押します。
Data source is working
と表示されれば成功です。
ダッシュボード作成
Grafanaではダッシュボードを作成してメトリクスを表示できます。
Dashboards
↓
New Dashboard
↓
Add Visualization
Prometheusを選択します。
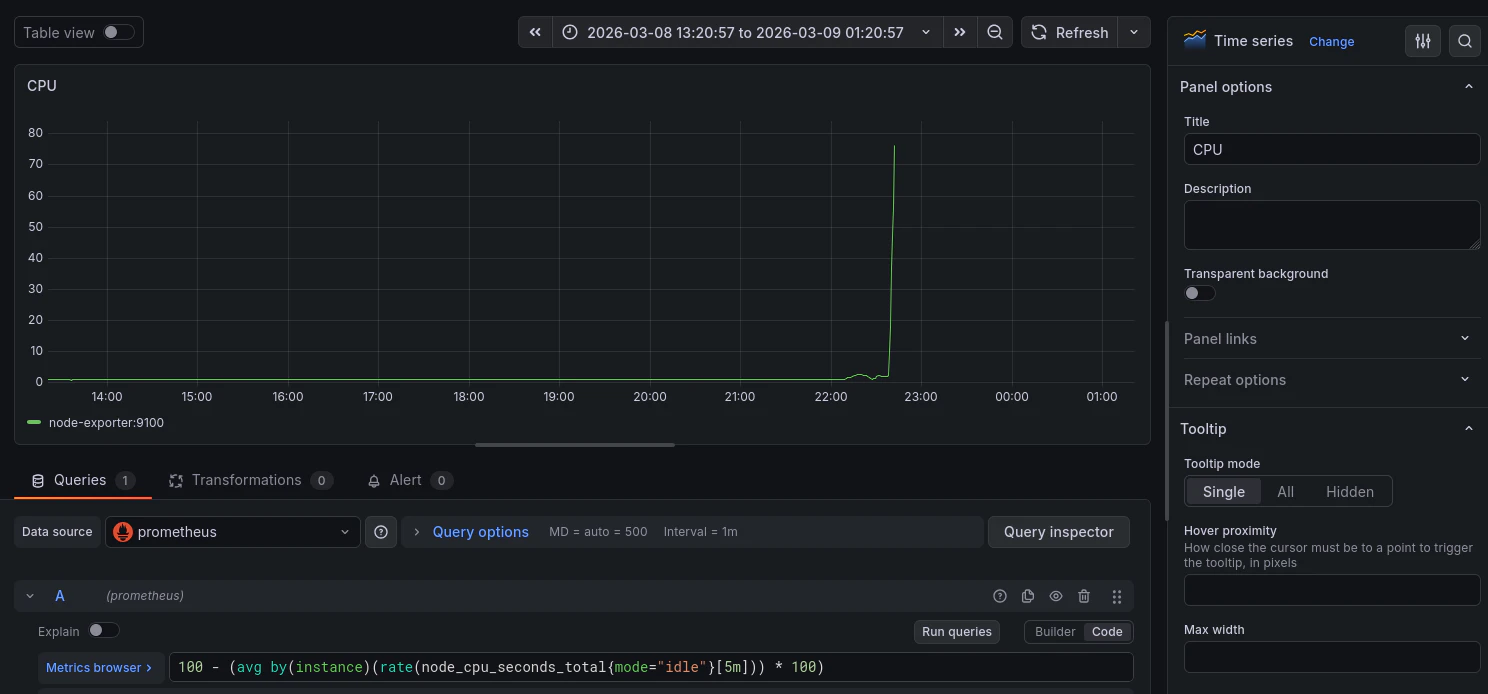
CPU使用率
PromQL
100 - (avg by(instance)(rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
CPU使用率がグラフとして表示されます。
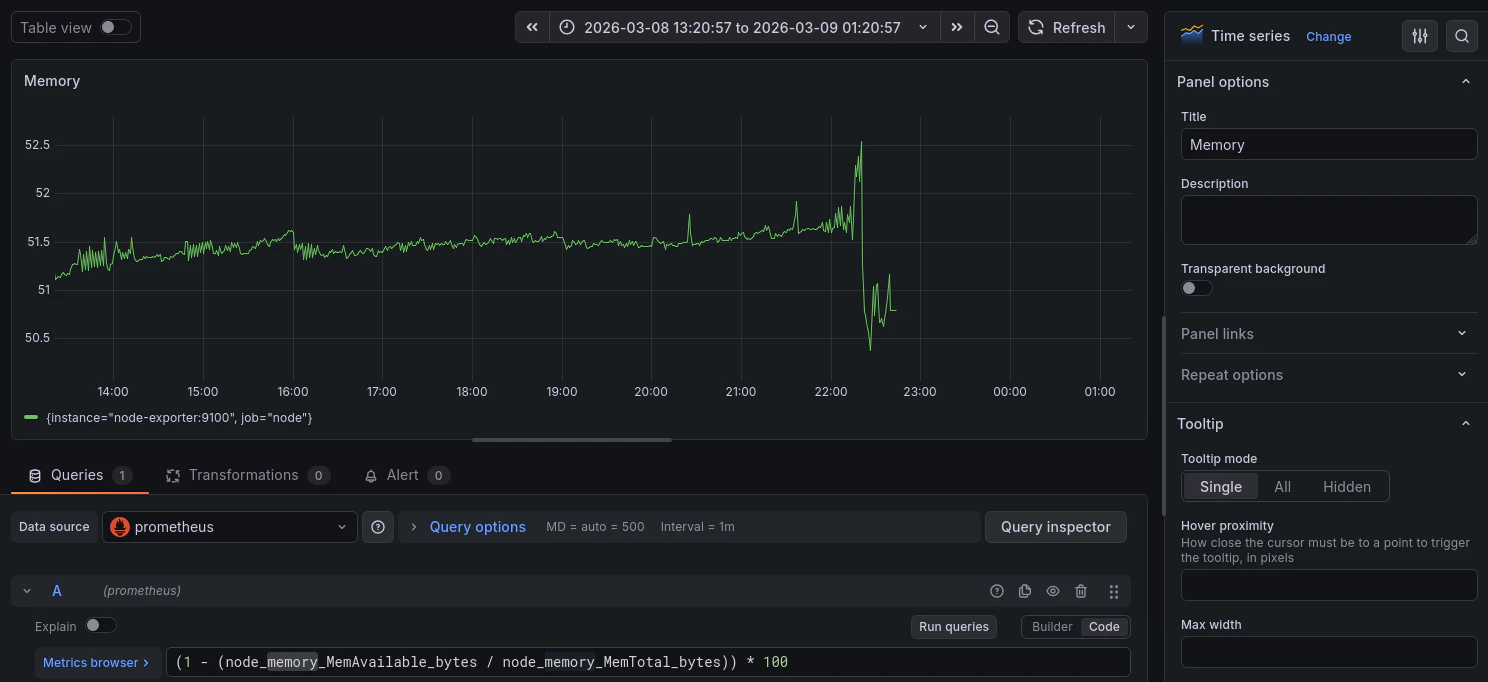
メモリ使用率
PromQL
(1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100
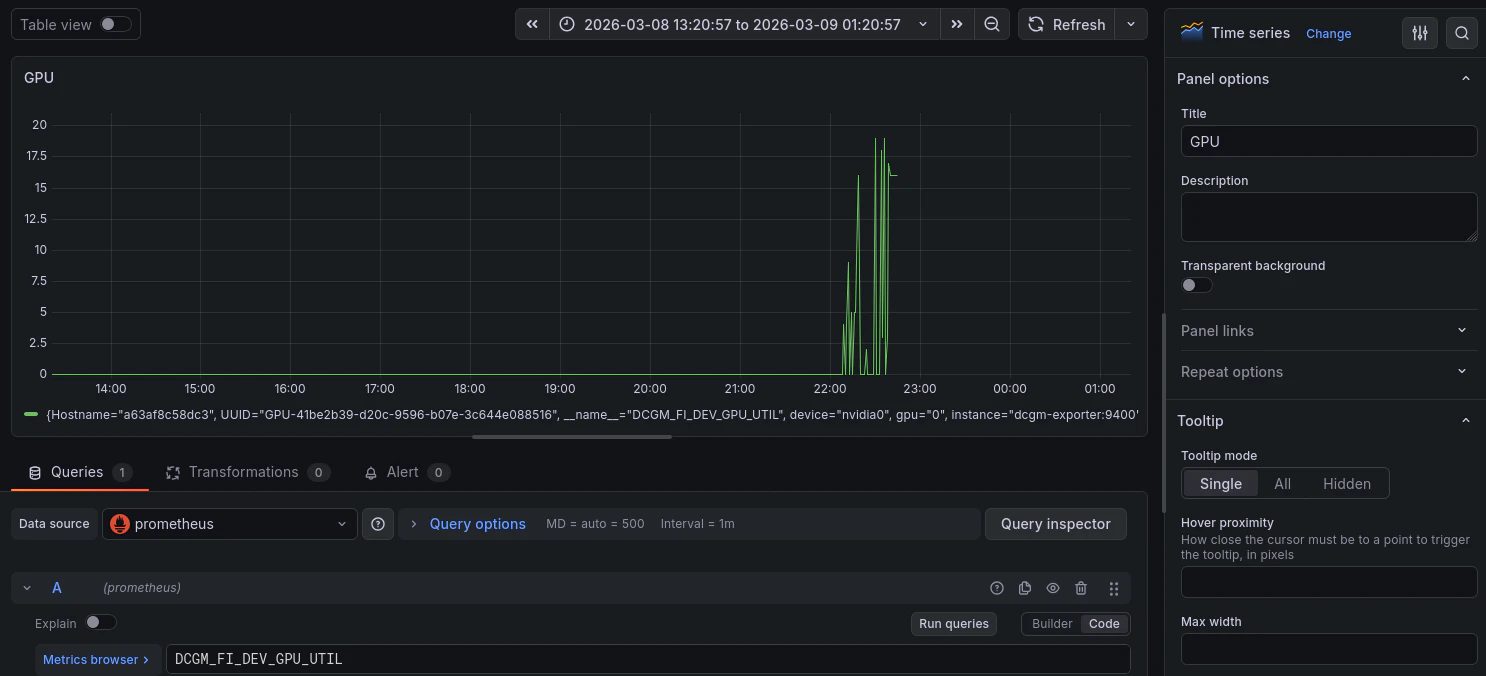
GPU使用率(NVIDIA)
dcgm-exporterを使用している場合はGPU使用率も取得できます。
PromQL
DCGM_FI_DEV_GPU_UTIL
可視化例
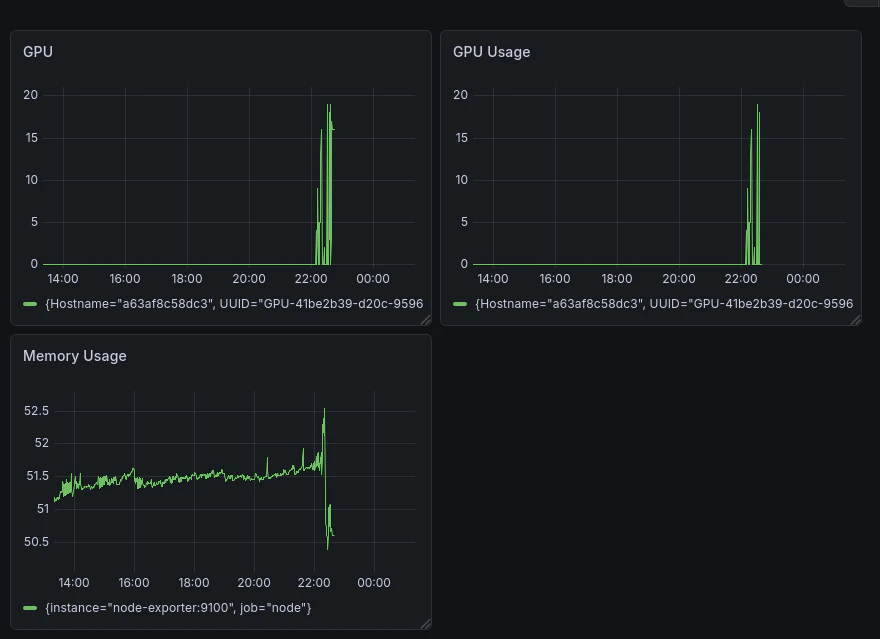
例
- CPU使用率
- メモリ使用率
- GPU使用率
実際のダッシュボードを見ると、
システムの状態を直感的に把握できるようになります。
まとめ
PrometheusとGrafanaを組み合わせることで
システムの状態を可視化できるようになります。
今回構築した監視スタック
Exporter
↓
Prometheus
↓
Alertmanager
↓
Slack
Prometheus
↓
Grafana
Prometheusはメトリクス収集、
Grafanaは可視化という役割になります。
運用の視点
メトリクスを可視化すると
- CPU利用率の傾向
- メモリ利用状況
- GPU使用率
などをチームで共有できるようになります。
監視は
まず「見える化」から始まると感じています。
次回
次回は
- PromQLの基本
- 監視設計
- Prometheus監視の落とし穴
などについて整理していこうと思います。