はじめに
こんにちは。(株) 日立製作所の Lumada Data Science Lab. の文景厚(むん)です。
みなさまは「AI研究者」が企業の中でどんな仕事をしているのかご存じですか?日立にはさまざまな分野で活躍するAI研究者がたくさんいます。この記事では、私が一緒に仕事をしているメンバーの紹介を通して、AI研究者の具体的な業務を深堀りします。
刑部 好弘さん
今回紹介するのは、(株) 日立製作所 研究開発グループ の刑部 好弘さんです。
💡プロフィール
-
大学時代は情報工学/電子工学を専攻。高校時代から物理系に興味があり、理学部と工学部で迷ったが、モノを生み出す過程も面白いと工学系に進む
-
現在はMI(マテリアルズインフォマティクス)とよばれる分野で使われる機械学習や深層学習の研究を行っている
-
より良い材料や新材料の開発を効率化することに取り組んでいる
研究職の仕事内容とは?
ーー日立ではAIの研究をされているそうですが、「研究職」とはどのようなことをするのですか?
現在はMI(マテリアルズインフォマティクス)とよばれる分野で使われる、機械学習や深層学習の研究を行っています。
学習モデルの構成や組み合わせを考えたり、新しい仕組みを考えたりしています。画像認識・自然言語処理のような他の分野で使われている技術を応用したいと思ったときに、考慮が必要な材料分野ならではの事情、というものがたくさんあります。そういった事情に合わせて、新しいものを考えていくというのが主な研究です。
💡マテリアルズ・インフォマティクスとは統計分析などを活用したインフォマティクス(情報科学)の手法により、材料開発を高効率化する取り組みです。
ーー「材料分野ならではの事情」とは、どのようなものですか?
いろいろありますが、一番顕著なのはデータが少なかったり、使える形で蓄積されてないというところです。
例えば、テキストデータや画像データはWebから比較的容易に大量のデータを取得することができます。研究用のデータセットを作る活動も活発です。ジャンルの偏りがないとは言いませんが、画像処理や自然言語処理は、ベンチマークのためのオープンデータが比較的整っている分野だと言えます。
材料分野の場合、材料のどういった性質に着目するべきかは、その用途によって変わってきます。温度特性に興味があるケース、電気伝導率に注目しているケースなど、その対象に応じて測定項目や測定方法も変わります。たとえば、融点・沸点や分子量などのような基礎物性を集めたデータベースはある程度存在しますが、実際にプロダクトを作るレベルになるとそういった基礎的な情報だけでは足りません。
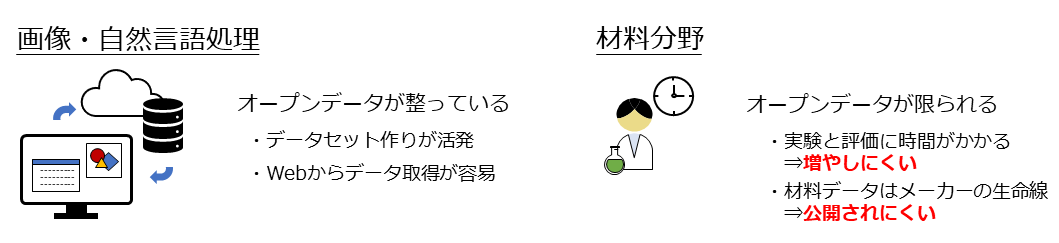
このため、重要になるのが、お客さま自身が手を動かして取得する実験データです。ただし、測定対象の実験材料を試作・合成して測定・評価をするだけでも、場合によっては数か月単位の作業になるため、Web上にあふれているデータと異なり、ぽんぽんと増やせないのが実情です。機械学習や深層学習を適用する場合、ビッグデータに象徴されるように、大量のデータが存在するということが一種の前提になっていたりするのですが、材料分野の場合はそうもいきません。少ないデータしかないけれども、何とかうまくやりたいという、そこが技術的にチャレンジングなところです。
ーーお客さまが必要とされている測定情報がそろったデータが簡単には手に入らないという難しさがあるのですね。
そうですね。また、「材料データ」は材料メーカーさんにとっては自社の生命線みたいなものなので、自社製品の情報を簡単には外部に公開しません。そういう意味でもオープンで使えるようなデータというのはとても限られているのです。
担当しているお仕事(よりよい材料や新材料の開発)
お客さまの課題
ーー現在担当されているお仕事について教えてください。お客さまはどのような課題を持っているのでしょうか?
様々な取り組みがありますが、共通しているのは「材料の研究開発における生産性を向上する」という課題です。
たとえば、既存の製品よりも優れた性能を持つ材料を開発したいと考えます。製品のアップデートみたいなものですね。このとき、お客さまがたどるステップは次のとおりです。
①新材料候補の選別→②実験→③測定・評価→(①~③のくりかえし)→④製品化
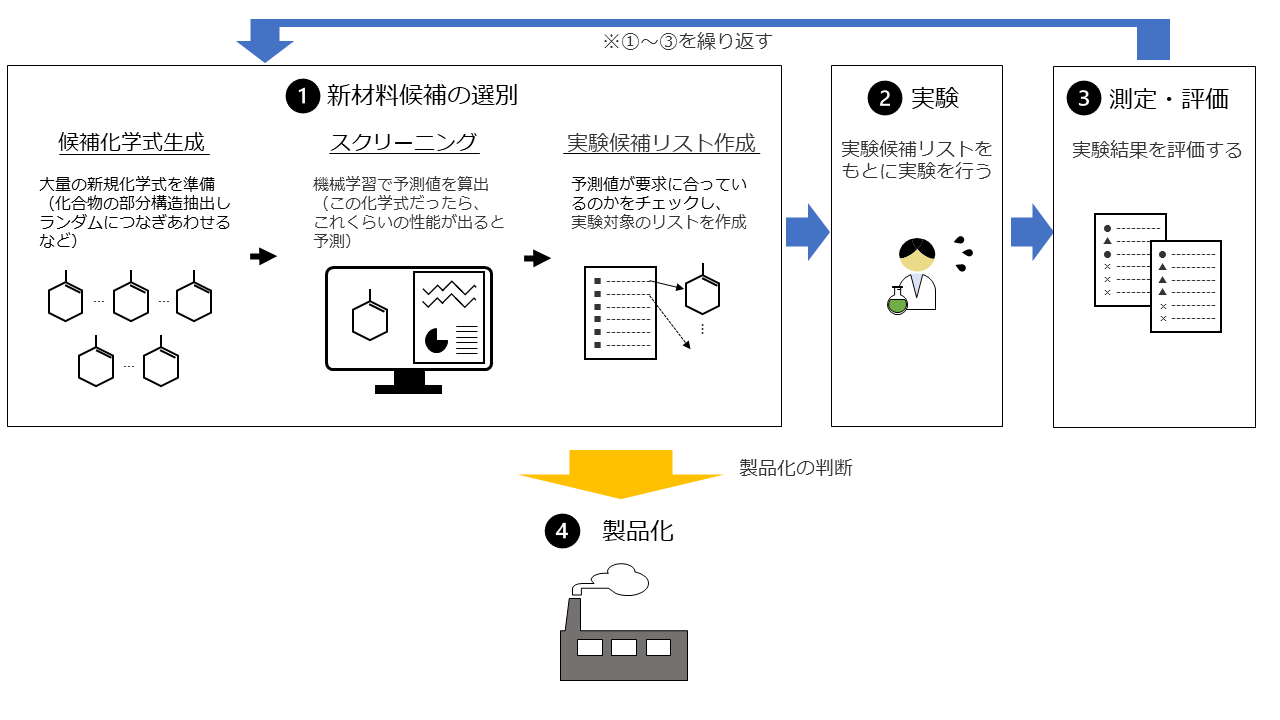
この「②実験」と「③測定・評価」の期間は、大掛かりなものだと数か月かかることがあります。せっかくコストをかけて試作したものが全然期待した性能を示さないとなると、その数か月は無駄になってしまいます。無駄な実験を減らすために、なるべくいいもの、性能がよくなりそうなものを優先して実験していく必要があります。これはコストを下げる上で非常に大事なだけでなく、早くよりよい素材を社会に出していくためにも必要なことです。
しかし、材料を作るときのパラメータの組み合わせや、材料の構造の組み合わせは膨大なので、それらすべてのあり得る組み合わせの中から、本当に性能がよくなりそうなものを「これだ!」と決めるのは非常に難しいのです。
ーーなるほど。膨大な材料の組み合わせの中から、性能がよくなると期待できそうな優秀な候補を選定するところに難しさがあるのですね。
今までそういうプロセスは、熟練した材料科学者の方々の優れた洞察力や長年の経験に頼っていた部分でした。マテリアルズ・インフォマティクスでは、過去のデータをAIが学習・分析することで、次に取るべきアクションを提案するものです。AIは直感が働かないかわりに、人間には把握できない膨大なデータを扱えます。材料研究者の方とはまた違った角度から、実験候補材料やまだ試していない実験条件などを検討する、有力で相補的な手段になればいいなと思い、そういうAIの研究をしています。
課題解決にむけたアプローチ
ーー優秀な新材料の候補を抽出する、というところがポイントということですが、どのようなアプローチで課題に取り組まれているのでしょうか?
ディープラーニング使ったアプローチを主に検討しています。
従来の方法の問題点を詳しくみてみましょう。従来の方法は上図のステップで実施されます。
スクリーニングで機械学習のモデルを使っていますが、テキスト形式の化学式をそのまま文字列として機械学習モデルで扱っても、そこから化学的な特徴を抽出することは困難でした。
機械学習で取り込めるように**記述子**という数値データに変換する必要があります。記述子とは、化合物の化学的な特徴を数値変換したデータで、たとえば分子量や分極率などをあらかじめ計算して準備した特徴量だと思ってください。
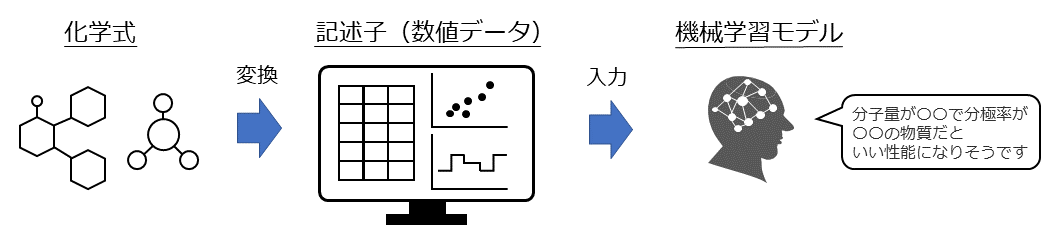
記述子に変換することで、機械学習モデルに入力できるようになったのですが、逆に記述子から化学式に戻すことができないんです。「分子量が〇〇で分極率が〇〇の物質だといい性能になりそうです」という結果が出たとしても、そういった条件にマッチする化学式、化合物が何か、ということは直接的には教えてくれません。最適な記述子がわかっても、それでは物質はわからない。そのものはわからないということですね。相互に変換ができない、逆変換ができないというのが問題でした。
このため、従来の手法では、先に候補となる化学式を大量に作って、それを記述子に変換して予測値を出させるという問題を解かせていました。
これを解決するのが深層生成モデル(ディープラーニングのジャンルの一つ)を使ったアプローチです。ダイレクトに化学式を提案してもらいましょう!というものです。単に新しい化学式を生成してくれるだけではなくて、ちゃんと過去のデータから材料性能を学習したうえで、ダイレクトに性能のよさそうな化学式をAIが作って提示してくれるというものです。
こうした深層生成モデルを活用することで、従来は2ステップに分かれていた候補生成とスクリーニングを一括して実施できるようになりました。現在の私のメインテーマは、実際の高性能材料をAIが発案する確率をさらに高めるというものです。
ディープラーニングを使った解決アプローチの詳細は次のQiitaの記事の中で紹介されていますので、そちらも合わせてご覧ください。
AIやシミュレーション技術を活用したマテリアルズ・インフォマティクス(MI)について
刑部さんのとある一日
研究が忙しいときは、夜遅くまで作業することもあります。うちの研究所には、AI研究用途に特化したかなり大規模なGPUクラスタ計算機が用意されています。産総研のABCI*などにもつなげたりと、クラウドでの計算リソースはわりと豊富に用意されているので、ジョブを流して就寝し、起床後にその結果を確認するといったことができます。
*:AI橋渡しクラウド(AI Bridging Cloud Infrastructure、ABCI) は、国立研究開発法人 産業技術総合研究所が構築・運用する、世界最大規模の人工知能処理向け計算インフラストラクチャです。
今後の野望
ーー刑部さんの今後の野望をお聞かせください。
物理や化学分野で新しい「理論」を打ち立てるような創造性をもったAIの創出です。
今のAIは、データに潜む規則性や相関関係などをとらえられますが、基本的にはそうした表面的・脊髄反射的な推論機構しか実運用レベルでは実現するに至っていません。ただそれでも人間が捉えるよりもはるかに複雑な周期性や特徴を学習できるので、賢く見える挙動がある程度達成出来ているのです。画像処理などが顕著な例です。人間よりもはるかに早く物体が検出できますよね。
一方で、思考に近いようなところ、例えば、ものごとの仕組みとか、一を聞けば十を知るではないですが、「これはきっとこういう仕組みになっているから、だからこうなる」というような推論は、基本的に今の技術ではたどり着けていないのです。ですから、そういうところを次に狙っていきましょう、というのが今のAIの最先端の人たちが考えていることの大きな方向性の一つだと思います。私も、かつての偉人が星の動きの観測データから地動説を思いついたように、様々な測定データから「きっと裏にはこういう原理、こんなメカニズムが潜んでいるに違いない」という部分に切り込んでいけるようなAIが作れたら面白いなと思っています。材料分野は、物理・化学と非常に近い領域に位置していますので、そうした分野での「新しい理論」を打ち立ててしまうような創造性をもったAIが作れるとしたら、かなりワクワクしますね。実際には、我々人間がさらに深い英知を切り拓くための武器になるようなAIを考える方が、健全な発展かなとは思います。
本当の意味での人間に近い知性みたいなものはまだまだ程遠いですね。これは恐らく、数十年とかのオーダーでかかる話なので、一生を通して追及していくことになると思います。
おわりに
どうでしたか?AI研究者がどんなことをやっているのか、少しでも感じていただけたでしょうか?
このシリーズでは様々な経歴のAI研究者の方へのインタビューを通して、実際の業務内容や今後の展望などを紹介していきます。
シリーズ1:データサイエンティストの仕事~日立のデータサイエンティストに聞いてみた!~佐藤 達広~
シリーズ2:データサイエンティストの仕事~日立のデータサイエンティストに聞いてみた!~隠岐 加奈~
シリーズ3:データサイエンティストの仕事~日立のデータサイエンティストに聞いてみた!~松本 茂紀~
最後まで読んでくださり、ありがとうございました。