はじめに
こんにちは。(株) 日立製作所の Lumada Data Science Lab. の文景厚(むん)です。
みなさまは「データサイエンティスト」が企業の中でどんな仕事をしているのかご存じですか?日立にはさまざまな分野で活躍するデータサイエンティストがたくさんいます。この記事では、私が一緒に仕事をしているメンバーの紹介を通して、データサイエンティストの具体的な業務を深堀りします。また、データサイエンティストとしてのキャリアパスも紹介します。
松本 茂紀さん
今回紹介するのは、(株) 日立製作所 Lumada Data Science Lab.の松本 茂紀さんです。
松本さんのインタビュー記事は以下の日立 Lumada Data Science Lab. 紹介サイトにも掲載されております。ぜひご覧ください!
Lumada Data Science Lab.のメンバーインタビュー
💡プロフィール
-
データサイエンティストになる前は、電子部品の材料の研究開発に従事していました。
-
Lumada Data Science Lab.に所属後は、データサイエンティストとして、お客さま業務のDX推進や業務効率の課題解決に取り組んでいます。
-
データサイエンティストの育成にも携わり、OJTを通じてデータサイエンスの知識や技術を伝えています。
-
おうち時間では芋の保存温度をスマホで監視するシステムを構築するなど、IoTデバイスを使ったQOL向上にも熱心です。
松本さんに、課題解決や分析手順についてどのように取り組んでいるのか、そしてデータサイエンティストの育成について話を聞きました。
――Lumada Data Science Lab.に所属する前は、どのようなお仕事をされていたのでしょうか?
電子部品に使う材料の研究開発に携わっていました。材料を分子レベルでシミュレーションしたり、データ分析したりする業務が中心で、リアルに起こっている複雑な問題を、部分的にでも特徴を抽出してコンピュータ上で再現し、「何が起こっていたか」を明らかにする研究をしていました。
今手がけているデータサイエンスの分野も、現実に起こっている難しい問題をデータを使ってコンピュータ上で理解していきます。ロジカルシンキングと言ってしまうと大ざっぱかもしれませんが、ロジックを立てて考えていくところは共通するところが多く、そこは研究開発のころの経験が活かせていると思います。
――Lumada Data Science Lab.に所属してから取り組んでいる業務はどのようなものですか?
物流、製造、保険の分野を中心に、DX推進や業務効率化に関する案件を、3件程度手がけています。
――さまざまな分野の案件を手がけているのですね。課題解決に向けてはどのような方法でアプローチしているのでしょうか?
まずは課題を体系的に整理して、統計解析や数理モデルなどでデータを可視化します。その情報をもとに、課題の種類によって、適切な手法を検討します。
課題解決のアプローチ:統計解析
――統計解析についての事例を聞かせてください
お客さまより「複数の定型業務を効率化したい」とのご依頼を受けたとき、業務効率を測る指標として、単位時間あたり何件の業務を処理できるかを表す業務能率を算出し、他の取得可能なデータと掛け合わせて分析を始めました。
業務能率は、日や人によってばらつくことが想像できます。そこで、統計解析方法の一つであるヒストグラムを作成し、どのような分布になるか確認しました。その結果が以下の図です。
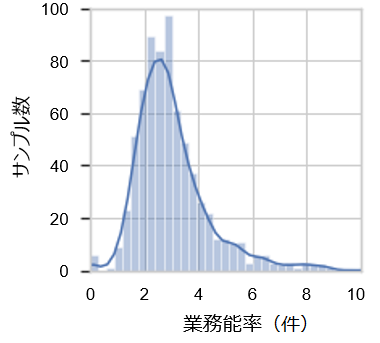
上記の図は対数正規分布になっていて、能率の高いケースの割合が多いことがわかります。どのような統計モデルに従っているかを俯瞰することで、このようなデータを単なるばらつきや異常値ではなく、調べる価値のあるデータだととらえることができます。
――対数正規分布とは何でしょうか?
横軸の値で対数をとったときに、正規分布となっているグラフのことです。上記のグラフは横軸が線形スケールとなっていますが、これを対数スケール(小さい値は目盛の幅が広く、大きい値になるにつれて目盛の幅が狭くなるスケール)にすると、正規分布のような左右対称のグラフとなります。この特徴を持つのが対数正規分布です。
広範囲に分布を持つデータの場合、単純にグラフにすると小さい値は潰れてしまい、大きい値はグラフとして分かりにくくなってしまいます。しかし、小さい値も大きい値も等しく性質を持っているはずなので、データを俯瞰するためには対数をとることが定石となっています。
――最初にデータをもらってから、正規分布に至るまでのアプローチを教えてください
最初は正規分布にこだわらず、どういうデータが多いのかを見ます。データの分布が山の形になっていたら正規分布かな?というように、何かパターンが見えるかどうかが1つの目安になります。
データが正規分布になるかどうかという判断基準もあると思います。「平均的にこのような値になる」という仮説がある場合でも、平均とばらつきがどうなっているかを実際に確認します。その中で仮にデータにばらつきがあっても、たくさんサンプリングをすると正規分布になることがあるのです。
分布として見ることのメリットは、データをある程度予測できることです。新しいデータが追加される場合や、データの一部が欠損している場合など、分布に当てはめることでおおよその見当がつけられます。
課題解決のアプローチ:数理モデル
――数理モデルについての事例を聞かせてください
データの可視化では、統計的な性質(統計解析)を見るだけではなく、規則性についての仮説を立てることも重要です。
先ほど例に挙げたお客さまの案件で、1日の作業時間の中でいったん手を止める回数と時間について調べたことがありました。その結果が以下の図です。
(「いったん手を止める」とは、例えば何かを思い出したり、資料を確認するために手を止めるというような、「自分が意思を持って数秒から最大1分程度の中で作業を休止する」という行為を指しています)
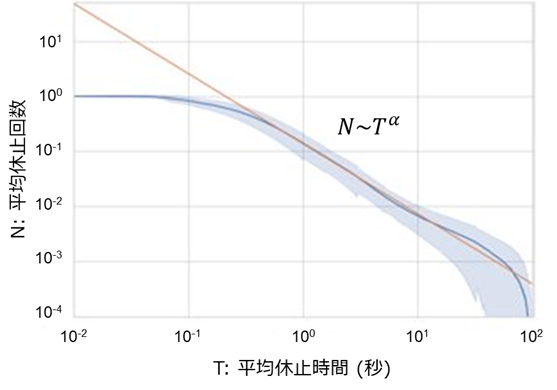
上記の図は、縦軸と横軸が対数スケールとなっている両対数グラフで、2桁にまたがった直線的な分布になっています。このような分布は「ベキ分布」と呼ばれ、一定の確率で起きる事象を可視化する場合に使用されます。
縦軸の平均休止回数の値が小数点以下となっているのは、一番大きい数字で規格化しているためです。作業の日が変わると休止回数がまったく異なる値になるので、一緒に比較するために、一番大きい平均休止回数である「1」で割って規格化しています。
――数理モデルも、統計解析のようにデータの傾向を見てから可視化をしていくのですか?
この例では頻度と時間について調べたのですが、これらの関係は、行動の分野ではベキ分布になるというモデル化された知見があります。その知見をもとに、モデルを事前にイメージしてから可視化しました。
統計解析では、データの全体像がどうなっているかを見ますが、数理モデルの場合、一つ一つのデータが生み出す法則性を見出し、「このようにするとこのようなデータが生成される」と考えてから分布を創造する点が異なります。
森を見て木を見に行くのが統計解析、木を見て森を創造するのが数理モデル、といった感じでしょうか。
――課題解決のアプローチはパターン化されているものなのでしょうか?
パターン化というほどではないですが、最初にデータをしっかり理解することが大事だと考えています。
お客さまからお話を伺うと、データに対する理解の度合いが違うことが多いです。データに対して理解が進んでいない場合は、「データを可視化しましょう」とか「俯瞰する場合は統計的に見てみましょう」というように、データを理解していくスケール感を示していきます。
初めの一歩を地道にやっているという点では、ある意味パターン化なのかもしれません。
――お客さまの傾向としては、ご自身で課題を明確に認識している場合と、漠然と「どんな改善ができそうですか?」というご相談を受ける場合とがあるということでしょうか?
私が担当しているお客さまからは、漠然としたご相談を受けることが多いですね。
お客さまに「取れるデータとして何がありますか?」と聞いたとき、逆に「何がとれますかね?」と聞かれることもあります。お客さま自身のご要望がふわっとしていることが多いです。
データ分析作業の進め方
――データ分析の作業はどのように進めているのでしょうか?
次のような流れで進めています。流れはウォーターフォールのように見えますが、実際にはアジャイルで進めています。

データ分析の作業は一発で正解にたどり着くわけではないので、手持ちの情報やお客さまとのディスカッションを基に、一つ一つ仮説を立てて検証を繰り返すことが中心になります。
まずは効果検証まで軽く1回試してお客さまにお見せして、問題があればそこに立ち戻ってもう1回試してみる…というサイクルをクイックに回しています。どこまで戻るかは場合によって異なるので、きちんと最初の工程から進めていれば、すぐに戻れる場所がわかるようになっています。
こうして構築したモデルに問題がなければ、最後に精度向上を実施します。
――反復を繰り返しながら完成につなげていくんですね
はい。できるだけ反復の回数を少なくして、お客さまにとって効果的な施策を導くことを重視しています。
作業の流れを無視して、いきなりデータをいじってモデルを構築して精度向上を頑張ってしまったり、力を入れて取り組むべきところを間違えたりすると、反復の回数が多くなってしまいます。
失敗しても、次に効果的なところに戻れるようにするという意味では、早く失敗して手戻りを減らすことを心がけています。
――最初の1サイクルはどのくらいの期間なのですか?
プロジェクトによって異なりますが、最初にお話をいただいて、次にお客さまに分析の方針を示して結果をお見せするまでは約3週間が目安です。
長い時間をかけるとお客さまも不安に思われるので、こちらで仮説を立てて見せて、さらに勘所を引き出すことでモデルの精度を上げていくようにしています。
OJTを通じてデータとの"対話"方法をアドバイス
――OJTを通じてデータサイエンティストの育成もされているそうですが、松本さんがいま指導しているメンバーは何人程度なのでしょうか?
最近では昨年度に研修生を2人指導していました。最後のほうは、私が手に負えない部分を2人に分担してもらったというくらい、即戦力でやってくれました。
基本的に私が手取り足取り教えるというよりは、ヒントを与える感じで指導してきました。
データ分析のときは、データがあるとどうしてもライブラリを使って何かやってみたいという気持ちがはやりますが、一呼吸置いて、
「本当にこのままデータを見てよいのですか?」
「このデータはこう解釈できるから、次はこのように分析したら面白くないですか?」
「次はどんな仮説を立てたら立証できますか?」
というように、どうやってデータとロジカルに対話していくかをアドバイスしながら一緒に進めていきました。
――インターン生の受け入れもしていたのでしょうか?
はい。インターン生は昨年度に3人受け入れ、複数のチームメンバーで指導を担当しました。
社外コンペに出てもらう目的で来ていたので、私が指導したのは、研修生のときと同様に、データの見方や解釈の仕方、現象の背景に何が起きているのかをどのように解いていこうかというところを、少しアカデミックにアドバイスしました。
――OJTの際に心掛けていることやポイントはありますか?
「このデータは本当は何を言っているのだろう?」ということを自分たちで考えてもらうようにしています。
データがあるからとりあえず分析しようというのではなく、データを基に仮説を立て、本当は何が起きているのかを考えること。そこをおろそかにしないように心がけてもらっています。
――将来データサイエンティストを目指す学生さんに対し、「こんなことをやっておくといいよ」というアドバイスがありましたらお願いします
データ分析の技術について意欲的に学んでいると思いますが、データ分析の対象となるさまざまな世の中の物事にも目を向けて、どんどん興味を持つことが大切だと感じます。
データを扱う対象物についての興味があると、データに対する考え方がだいぶ洗練されてくると思います。
松本さんのとある一日
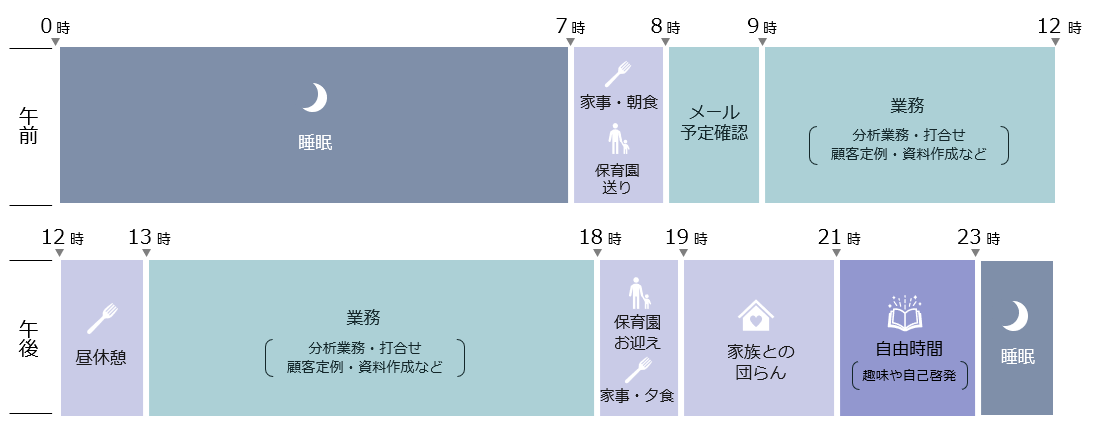
――1日の終わり(就寝前)に自己啓発の時間を確保されていますが、スキルアップのためにやっていることを教えてください
データサイエンス関係の勉強はしていますが、それにプラスして、生活の役に立つIoTデバイスを作って技術の勉強をしています。Raspberry Piやセンサーをたくさん買ったり、子供用に買ったレゴブロックを使ってセンサーデバイスを作ったりしています。
――IoTというと、家電を動かしたりすることもあるのでしょうか?
家電ではないのですが、秋に芋掘りをしたとき、芋を保存するには温度管理が大切なので、スマホから温度を監視できるようなデバイスとアプリを作りました。ほかにも、家にあるエアロバイクを改造して、回転数を取りながらVRコンテンツを作れないかなどを考えて遊んでいたりします。
――すごく面白いですね!これで記事が1本書けそうなくらい、もっとお話しを聞いてみたいです(笑)
そうですね(笑)。いろいろノウハウはたまりました。
一番最新でやっているのが、脳波を使って物を操れないか、ということです。視覚や脳波を使ってモニター上を操作するというデバイスを個人で買ってしまいまして、QOL(Quality of life)を上げられないかなと考えています。半分くだらないけれど、面白いと思っています。ぜひ、記事に貢献できるといいなと思います。
――最後に、今後の野望を教えてください
いろんな分野にインフォマティクスを掛け合わせて、新しい価値が生まれるようなデータ活用によるサイエンスをもっと体験していきたいです。
おわりに
どうでしたか?データサイエンティストがどんなことをやっているのか、少しでも感じていただけたでしょうか?
データ分析をする上で最も重要なことは、お客さまのビジネスを理解し、真の課題を見つけ出すこと。
そして、手持ちのデータをしっかり理解した上で、仮説検証を何度も何度も繰り返すことが課題解決への鍵となることが、お分かりいただけたのではないでしょうか。
また、芋の保存温度をスマホで監視するシステムの話は、非常に興味深い話だと思うので、また別途ご紹介できればと思います。
このシリーズでは様々な経歴のデータサイエンティストの方へのインタビューを通して、実際の業務内容や今後の展望、データサイエンティストあるあるなどを紹介していきます。
シリーズ1:データサイエンティストの仕事~日立のデータサイエンティストに聞いてみた!~佐藤 達広~
シリーズ2:データサイエンティストの仕事~日立のデータサイエンティストに聞いてみた!~隠岐 加奈~
最後まで読んでくださり、ありがとうございました。