前回RowNum()関数を使いながら「自己結合」という考え方をご紹介しました。強力なテクニックなので、引き続き深掘りしていきましょう。
今回の要件は:
スキーマのプライマリキー分布状況を知りたい。キー数値の間隔が最大なのはどこか?
たとえば本連載の検証環境で「ワークフロー」スキーマを見てみると、こんな感じです:
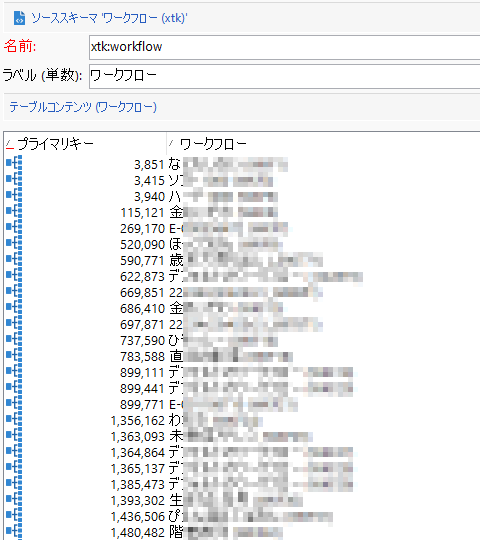
Campaignスキーマのレコードは一意識別のためのキーを持ちます(プライマリキー)。キーの数値は連続しているとは限らず、システム状況により分布はまばらです。この「ワークフロー」スキーマの場合、一見して顕著なところでは899,771から1,356,162へと飛んでいて、大きく間隔が空いてますね。このように間隔が空いているのがどこか、その大きさはどれだけか知りたいというのです1。
この要件に対応するワークフローが、RowNum()関数+自己結合で実装できてしまいます。さっそく見ていきましょう。
今回もまず全体像から:
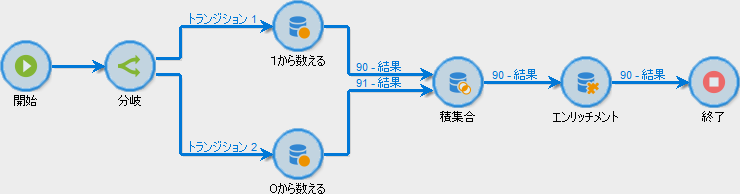
アクティビティごとに主要な点に絞って説明していきます。
クエリー: 1から数える
前回同様まず分岐です。そして上側の分岐に「クエリ」アクティビティを置き、「ワークフロー」スキーマをディメンジョンに取ります2:
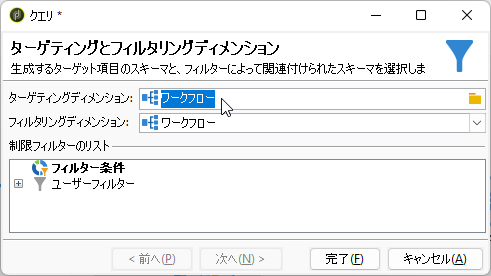
フィルター条件は、プライマリキー(@id)が0より大きいとし、全レコードを取ります:
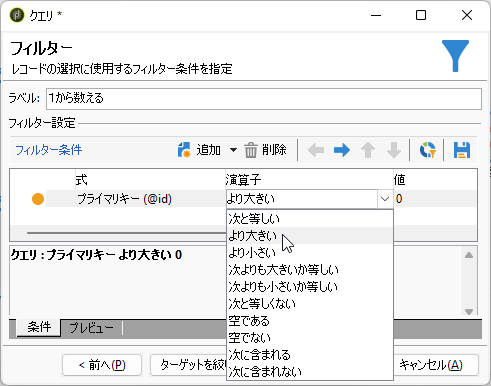
おなじみの手順3で「クエリ」画面に戻って「データを追加...」から「追加データ」画面へ。「使用可能フィールド」で「プライマリキー」をダブルクリックして「出力列」に追加します。ラベルは「プライマリキー(1)」、エイリアスは「from1」としましょう:
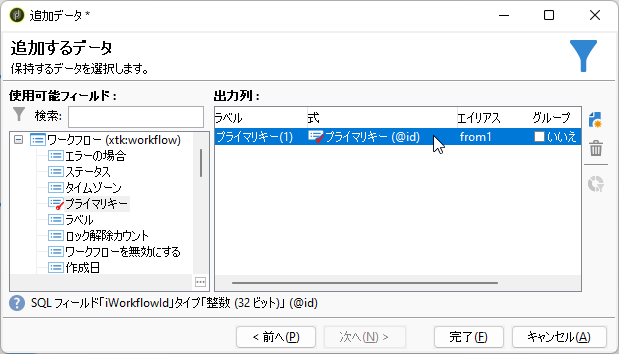
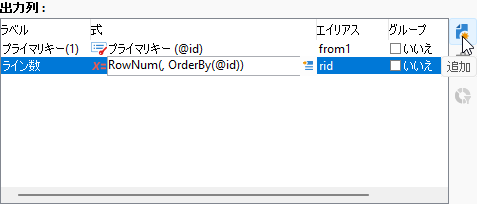
「出力列」ペイン右横の「追加」ボタンをクリック、「式」に以下をコピペ:
RowNum(, OrderBy(@id))
前々回から解説しているRowNum()関数です。「OrderBy(@id)」でプライマリキーの昇順による番号付けを指定しています4。
エイリアスは「rid」としておきましょう:
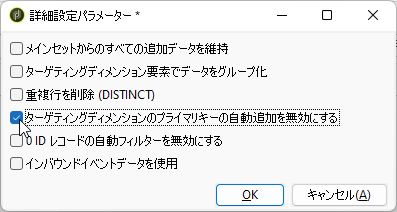
またいつものように「完了」して「クエリ」画面に戻り「追加データを編集...」、「追加列」画面で「詳細設定パラメーター...」クリック。「重複行を削除 (DISTINCT)」をアンチェック、「ターゲティングディメンジョンのプライマリキーの自動追加を無効にする」をチェック:
このアクティビティはこれで出来上がりです。
クエリー: 0から数える
下側の分岐にも「クエリ」アクティビティを置きます:
内容はほぼほぼ同じ。違う点だけ見ていきますが、その違いが重要なので、刮目してご覧あれ。
ディメンジョンは上と同じく「ワークフロー」。フィルター条件は、プライマリキー(@id)が0より 大きいか等しい とします:
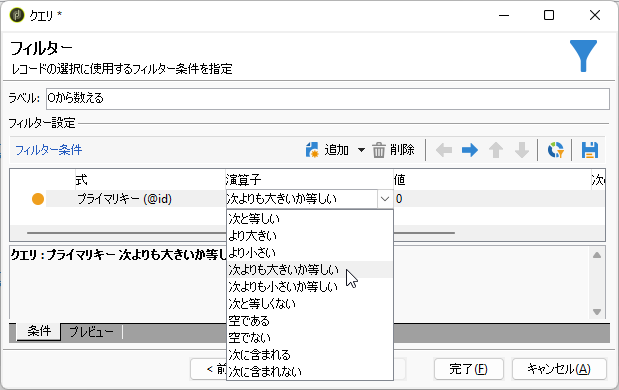
「追加データ」画面では上側と同じ設定をしましょう。ただし、プライマリキーのラベルを「プライマリキー(0)」、エイリアスを「from0」とします:
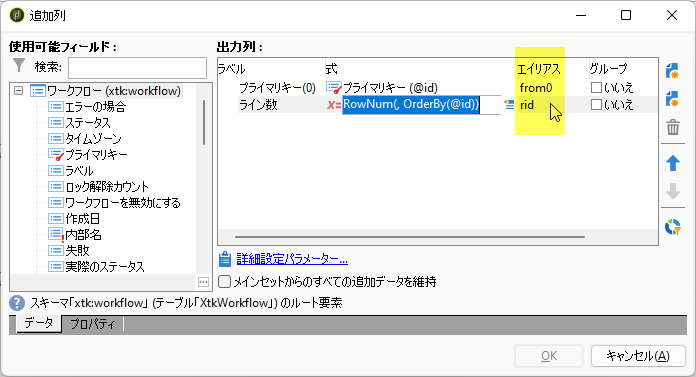
出力列2行めのエイリアス「rid」は変えちゃだめですよ。
そして! 「詳細設定パラメーター」。ここが重要です。「ターゲティングディメンジョンのプライマリキーの自動追加を無効にする」に加えて、「0 ID レコードの自動フィルターを無効にする」をチェックしてください:
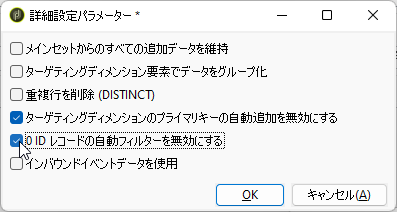
説明しましょう。「ワークフロー」などの製品標準スキーマにはプライマリキーが0のレコードがデフォルトで存在します。内部ロジックの都合で作られたダミーレコードなのでユーザーが意識することは通常ありません。しかし今回、あえてそのダミーレコードをクエリーに含めたいのです。そのためフィルター条件を0より大きいか等しいとしました。さらに、デフォルトではキー=0のダミーレコードが自動的に排除されているので、「詳細設定パラメーター」で「0 ID レコードの自動フィルターを無効にする」と明示的に指定したのです。
ではなぜ、そんなことを? 謎が謎呼ぶ事件の結末は?!
積集合
ひとまず先に進めますね。ふたつの支流を「積集合」アクティビティにつなげ、分岐を合流させます:
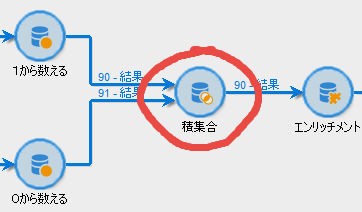
「紐付け」の「列の選択」をティック、「プライマリセット」に「1から数える」を選びます。そして「結合に使用する列」で「追加」をクリックし「フィールド」に「rid」と入力してください:
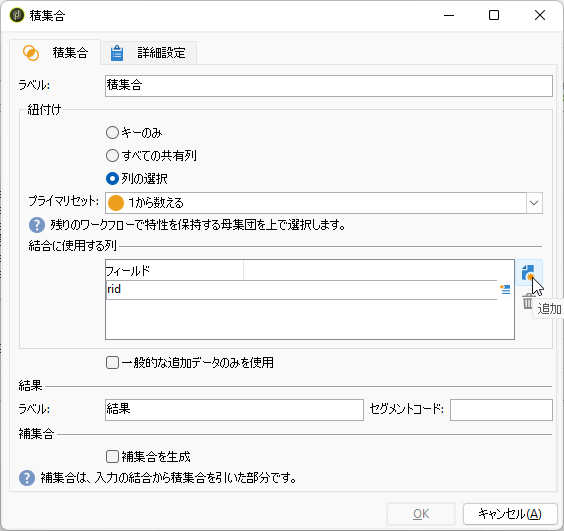
「積集合」の設定はこれだけ。いよいよ感動のフィナーレへ!
エンリッチメント
前回は分岐を積集合して終わりでしたが、今回は「エンリッチメント」アクティビティをつなげます。「エンリッチメント」は頻出なのでご存知かもしれませんが、ざっくりいえばデータを追加するアクティビティです5。
ダブルクリックした設定画面で「プライマリセット」が「積集合」なのを確認。「メインセットからのすべての追加データを維持」をアンチェックし、「データを追加...」をクリックします:
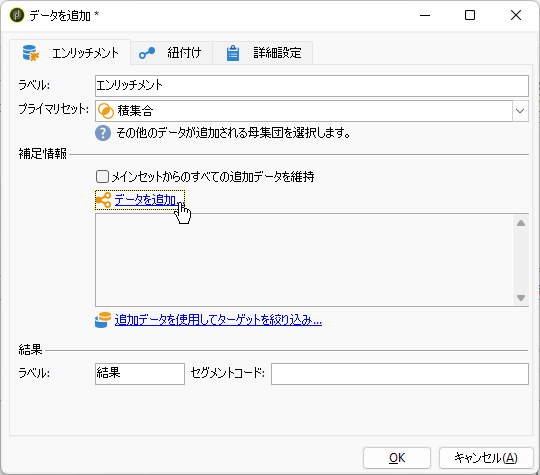
「フィルタリングディメンジョンにリンクされたデータ」をティック:
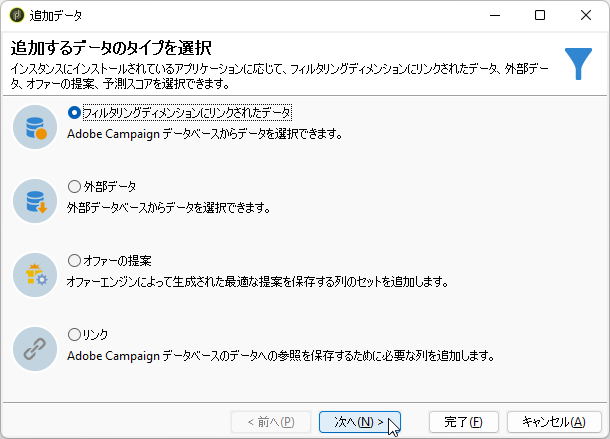
「フィルタリングディメンジョンのデータ」をティック:
「追加データ」画面に進みました。右ペイン「使用可能なフィールド」で「プライマリキー(0)」「プライマリキー(1)」をそれぞれダブルクリックして「出力列」へ追加:
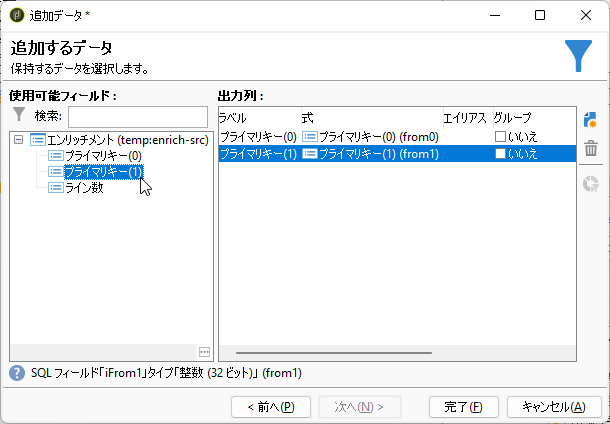
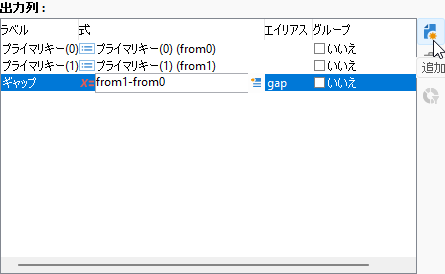
ペイン右横の「追加」ボタンをクリックし、「式」に以下を入力します:
from1-from0
「ラベル」は「ギャップ」、エイリアスは「gap」としましょう:
以上です! アクティビティ・ワークフローを保存してください。ワークフローを実行、「エンリッチメント」からの遷移矢印を右クリックして「ターゲットを表示」6:
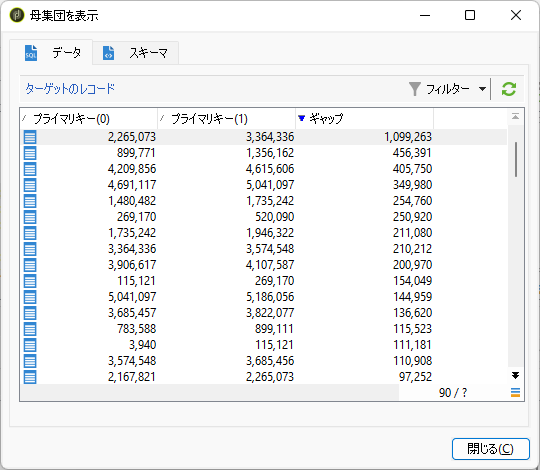
「ギャップ」カラムを適宜クリックし降順ソートさせると──なんということでしょう! キーとキーとの間隔が得られています。この環境では、「2,265,073」と「3,364,336」とが最も隔たっていることがわかりますね。念のためソーススキーマ画面でも見てみると:
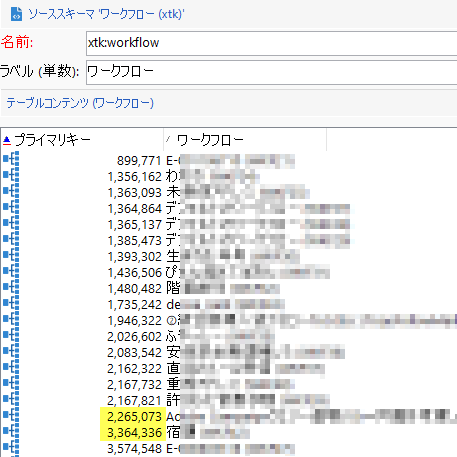
たしかにギャップが確認できます! でもどうしてこんな結果が得られるんでしょう?
解説
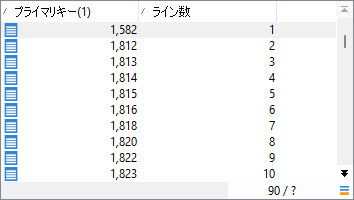
分岐後の両「クエリ」アクティビティで、RowNum()関数により番号を振りましたね。それによりまず上側分岐「1から数える」ではこんな結果を得ます:
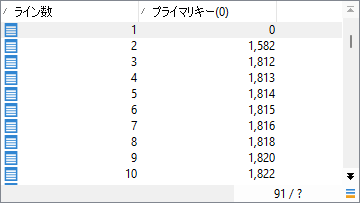
いっぽう下側分岐「0から数える」では、やはりRowNum()関数で番号を振りましたが、キー値0から始めているので、ひとつずれています:
これらは両方、「ワークフロー」スキーマでもともと同じもの。その二者を「積集合」により、RowNum()関数による番号「ライン数」(rid)で組み合わせます。自分と自分とを結合する「自己結合」ですね7。その結果が:
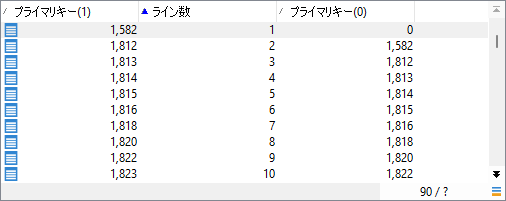
「ライン数」を介して、ある行とその前の行とが紐づいてます。0から数えてひとつずらした効果です8。
そして、「エンリッチメント」で:
from1-from0
と、あるキー値と「その前の行」のキー値との差を取り、「ギャップ」としてデータに追加しています:
数学で「階差数列」を習った方がいるかもしれませんが、そんな感じですね。この「ギャップ」がまさに、キーとキーとの間隔というわけです:
どうでしょう、なかなか華麗なるスゴ技じゃありませんでしたか? どや!
前回もそうでしたが、RowNum()関数と自己結合とはきわめて相性がいい技術です。自分自身を結合させるための紐づけキーを、RowNum()関数で要件に応じて作れるからですね。行間比較のために1ずらした番号を振った今回の解法はまさにその好例でした。
前後のレコード間で比較をしたい、間隔を取りたい、という要件は実戦で出てくることがあるんじゃないでしょうか。そんなときはぜひ、本稿を読み返してみてください。役に立ったらうれしいです!
本稿の内容は筆者のオンプレミス型デモ環境(Adobe Campaign Classic 9359@c636bf3 PostgreSQL 14.9)上で実施した検証に基づきます。別環境における同様の動作を保証するものではありません。またデータは架空のものであり、既存の配信や実在の組織とはいっさい関係がありません。
-
Campaign V7においてスキーマ定義が「autopk="true"」の場合、プライマリキーは32ビット符号付き整数となり、上限値は正領域の最大数で約21億です。万一その上限に達してしまうと、それ以上キーを採番できず新規レコードが作成不可能になってしまいます。作ってしまったレコードの削除やキー変更は反則なので、採番ポインターを移動させるため本稿のように大きな空間を探さねばならないことがあるのです。 ↩
-
「ワークフロー」スキーマを例としたのは、たまたま本稿検証環境でキー分布状況がわかりやすかったからというだけです。 「ワークフロー」スキーマでキー上限値が採番される状況は通常あり得ません。 ↩
-
前回・前々回ではDesc()関数による降順ソートを行っていました。しかし今回はDesc()関数なしなので昇順になります。 ↩
-
「エンリッチメント」アクティビティについてはQiita記事「Adobe Campaign Classic エンリッチメントアクティビティを利用した基本設定手順」も併せてお読みください。またヘルプ記事では本稿同様「積集合」アクティビティにつなげた使用例が紹介されています。 ↩
-
ワークフロープロパティで「2つの実行間の中間母集団の結果を保持」のチェックが必要。毎回いってますが、同設定は本番環境では行わないでください。 ↩
-
前回注3で指摘したのと同様、今回も生SQLレベルでは厳密な自己結合とはいえません。しかしワークフロー全体のロジックが自己結合に基づくものなので、そのアイディアを理解してください。 ↩
-
キー値0のダミーレコードを考えに入れることで、「その前の行」がないはずの最初の行から処理ができています。キー値0がひっそりながら存在している必然性が見えてきますね。 ↩