前回はCampaignのRowNum()関数を利用して「順位」を求めるクエリーを取り上げました。しかしひとつ、困ったことがあるのです。
ベストテンということで上位10件まで絞り込んだのですが、それをせずに下位まで見てみると:
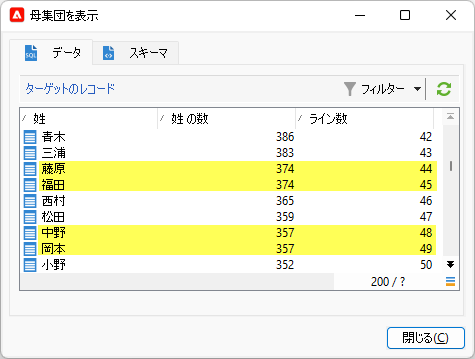
「姓の数」が並んで同着なのに、「ライン数」は異なるところがありますね。RownNum()関数はレコード行にユニークな番号を振るためのもので、それは厳密には「順位」ではないからです。
SQLならばRank()という関数があり、同着を考慮した順位を返します。しかしCampaignには残念ながら相当するものがありません。だから同じことをCampaign上でやろうと思ったら、ちょっと工夫が必要になるのです1。
そこで今回は、同着には同順位を与えるシン順位づけをやってみましょう。引き続き受信者の姓だと数が多くてわかりにくいので、以下の簡略化した「製品」スキーマを作って例に使います:
| キー (@fid) | 品名 (@name) | 価格 (@price) |
|---|---|---|
| 1 | かけ | 700 |
| 2 | 鴨南蛮 | 1700 |
| 3 | きつね | 900 |
| 4 | 卓袱 | 1100 |
| 5 | たぬき | 900 |
| 6 | 月見 | 900 |
| 7 | 天麩羅 | 1500 |
| 8 | 花巻 | 1100 |
これに価格の高さで順位をつけていきましょう。
なにげにステップが多いので、まず全体像をお見せします:
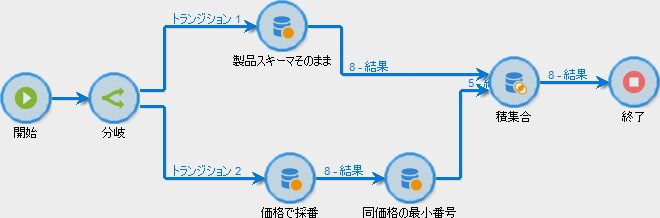
アクティビティごとに主要な点に絞って説明していきましょう。
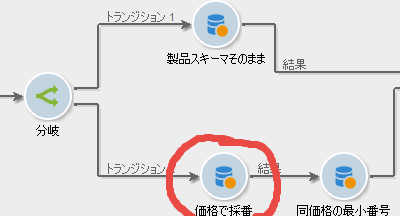
分岐
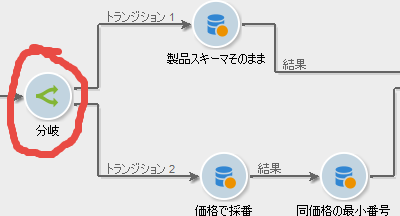
まずいきなり、「分岐」アクティビティから始めます。ロジックの流れを二分するアクティビティです。条件設定などはなく、キャンバスにドラッグ&ドロップするだけ。操作は簡単ですね。でも、どういう意味? ──おいおいわかってきます。ついてきてください。
製品スキーマそのまま
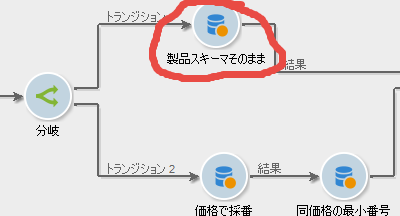
上側の分岐に「クエリ」アクティビティを置きます。このアクティビティでは上記の「製品」スキーマを左から右へそのまま受け流します。つまり、ディメンジョンには「製品」を指定し:
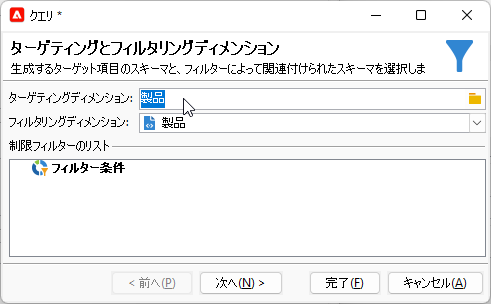
フィルター条件はキーが0より大きい、すなわち全レコードが選択されるようにします:
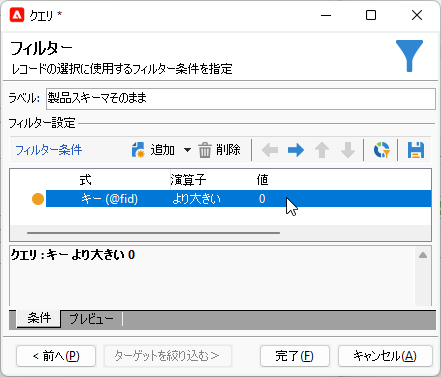
これだけです。わざわざふたつに分けておいて何もせず素通しとは──いよいよ謎が深まりますね。
価格で採番
分岐のもう片方ですが、やはり「クエリ」アクティビティです。「製品」をディメンジョンに取り、フィルター条件はキーが0より大きいとして全レコードを得る。さっきと同じです。変化はここから。「クエリ」画面で「データを追加...」:
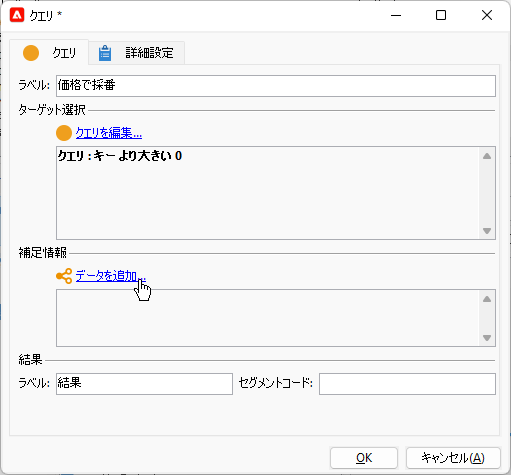
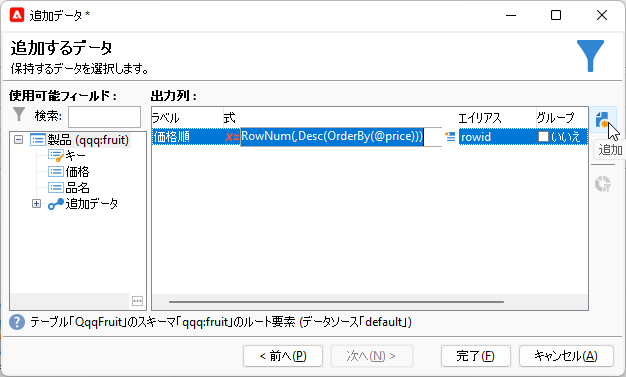
例によっておなじみの手順、「フィルタリングディメンジョンにリンクされたデータ」>「フィルタリングディメンジョンのデータ」>「追加するデータ」で「追加列」画面へ遷移。右ペインの「追加」ボタンで「出力列」に新規行を追加し、以下の式を入力します:
RowNum(,Desc(OrderBy(@price)))
「ラベル」は「価格順」、「エイリアス」は「rowid」としておきましょう:
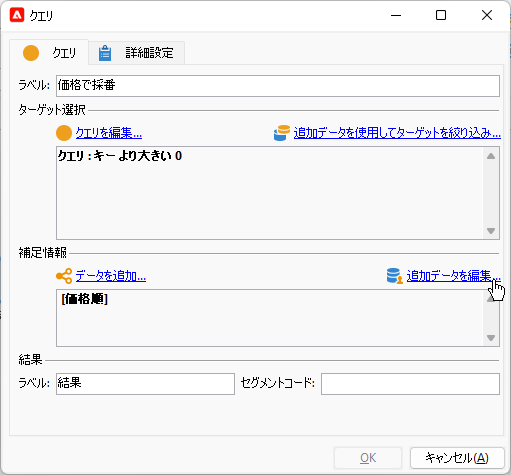
「完了」していったん戻った「クエリ」画面で「追加データを編集...」:
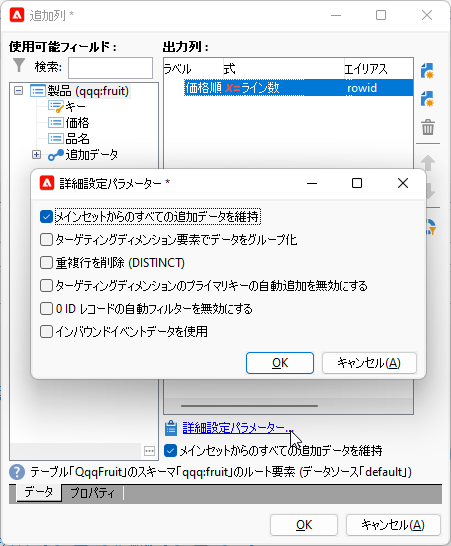
再びの「追加列」画面で「詳細設定パラメーター...」をクリックして「メインセットからのすべての追加データを維持」をチェック、「重複行を削除 (DISTINCT)」をアンチェック:
このアクティビティはこれで出来上がりです。
同価格の最小番号
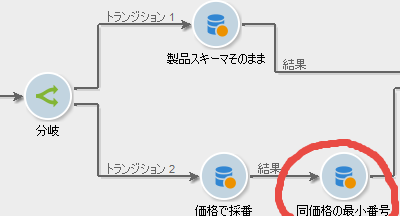
続いてまた「クエリ」アクティビティを置きます。ディメンジョンには前アクティビティの出力結果を指定しましょう:
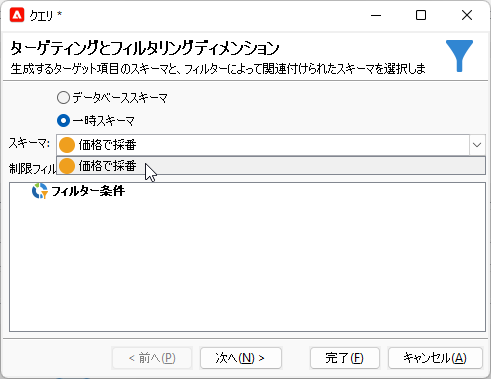
フィルター条件はやはり、順位をつけたい全レコードが選択されるようにします:
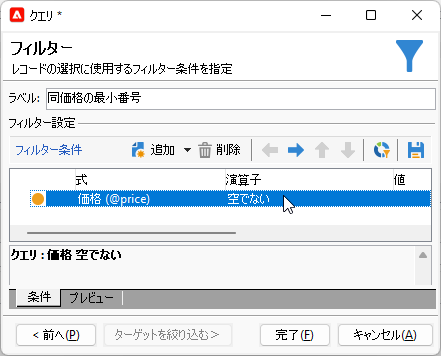
「完了」して「クエリ」画面に戻り「データを追加...」。いつものように「追加列」画面へ進み、左ペイン「出力可能フィールド」で「価格」をダブルクリックしてください。すると「出力列」に追加されるので、その「グループ」をチェックです:
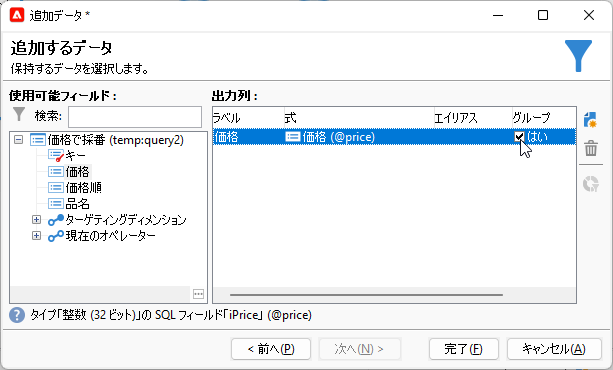
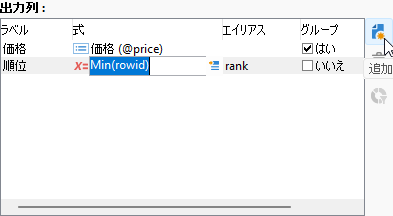
続いて「出力列」ペイン横の「追加」ボタンをクリックし、できた新規行に以下の式を入力します:
Min(rowid)
「ラベル」は「順位」、「エイリアス」は「rank」としましょう:
「完了」して「クエリ」画面に戻り「追加データを編集...」、「追加列」画面で「詳細設定パラメーター...」。
「インバウンドイベントデータを使用」がチェックされていることを確認してください。そして「重複行を削除 (DISTINCT)」をアンチェック、「ターゲティングディメンジョンのプライマリキーの自動追加を無効にする」をチェック:
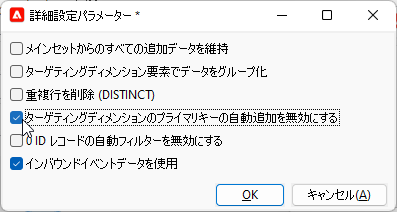
出来上がりです。ではいよいよ最後の仕上げといきましょう。
積集合
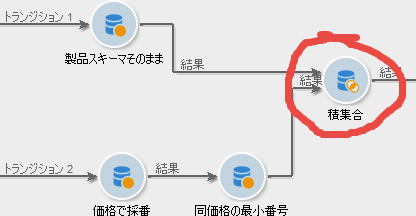
「積集合」アクティビティは、ふたつのスキーマをかけあわせたスキーマを得るものです。かけあわせるとは? ──あとで考えるとして、とりあえず手順を見てましょう。
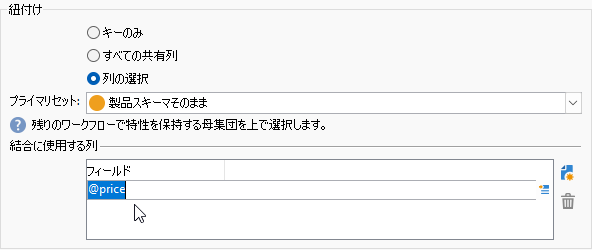
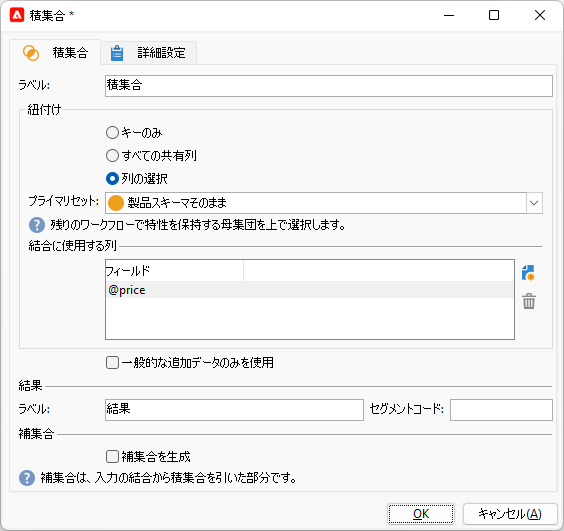
「積集合」アクティビティをキャンバスにドラッグ&ドロップし、両分岐のアクティビティから遷移矢印をつなげます。つないだ「積集合」をダブルクリックして開き、「紐付け」の「列の選択」をティックしてください:
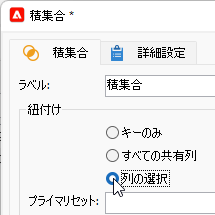
「プライマリセット」を選びます。今回どちらでもいいのですが、とりあえず上側分岐による出力のほうにしておきます:
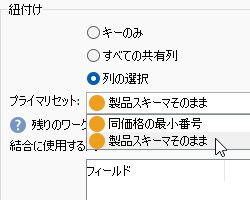
「結合に使用する列」ペインで「追加」ボタンをクリック。新規行の「フィールド」に「@price」と入力してください。「製品」スキーマの「価格」カラムのことです:
以上です! ワークフローを保存して、実行してみましょう2:
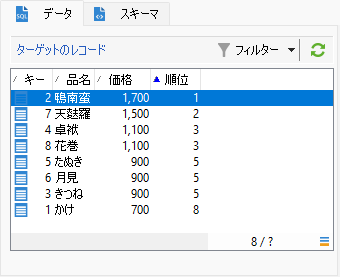
三番めに高い価格「1,100」を持つ2レコードが同着3位です。4位は飛んで、次に高い価格の3レコードが同着5位。6、7位が飛んで、最安が8位。求めていた結果が得られました!
解説
振り返ってみましょう。
実は今回、SQLの世界で「自己結合」3と呼ばれるスーパーテクニックを応用してみました。自己結合とは? ──自分と自分とを、あたかも別物であるかのように結合させることです。その観点から今回の手順を見直してみると、いろいろ腑に落ちてきませんか。
まず冒頭に「分岐」アクティビティを置きましたね。のちに「結合」させるために2本の支流を作ったのです。そしてどちらの分岐にも「製品」スキーマをディメンジョンに取る「クエリ」アクティビティを置きました。「自分と自分と」を2つに分けたということです。
上側の分岐は「製品スキーマそのまま」つまり自分そのものでした。対して下側の分岐はちょっと加工しています。詳しく見返しましょう。
「価格で採番」では以下の式を使いました:
RowNum(,Desc(OrderBy(@price)))
前回紹介したRowNum()関数4です。「価格」(@price)の降順で番号を振っています。それにより「価格で採番」は以下の出力を得ました:
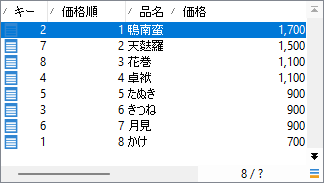
RowNum()で価格順が出ましたが、同着つまり同価格を同順位にしたいんでしたね。そこでこの結果を受け取る次アクティビティはどうするか。手順を思い出しましょう:
「同価格の最小番号」でまず価格によりグループ化しました。同価格に同順位を与えるためです。そして:
Min()関数5は過去回で紹介した集計関数のひとつ。グループの中で最小値を取るものです。引数の「rowid」はRowNum()で取った「価格順」のエイリアスでしたね。つまりこの行が得ているのは「同価格の最小番号」というわけです:
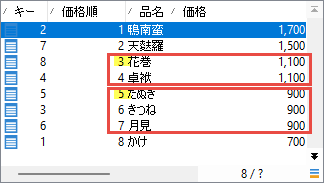
以上、価格でグループ化し、価格順の最小値を取った結果がこのアクティビティの出力になります:
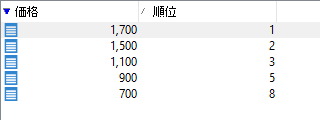
しかし。これだと、グループ化しちゃったことで、個別の品名がわからなくなっちゃってますね。そこであらためて、価格に対応する品名を元スキーマ「製品」から取得し直さなければなりません。──とすると、わざわざ分岐して「製品」スキーマをそのまま持ってきた意味がわかってきますね。価格で紐づけて品名を取り戻すためです:
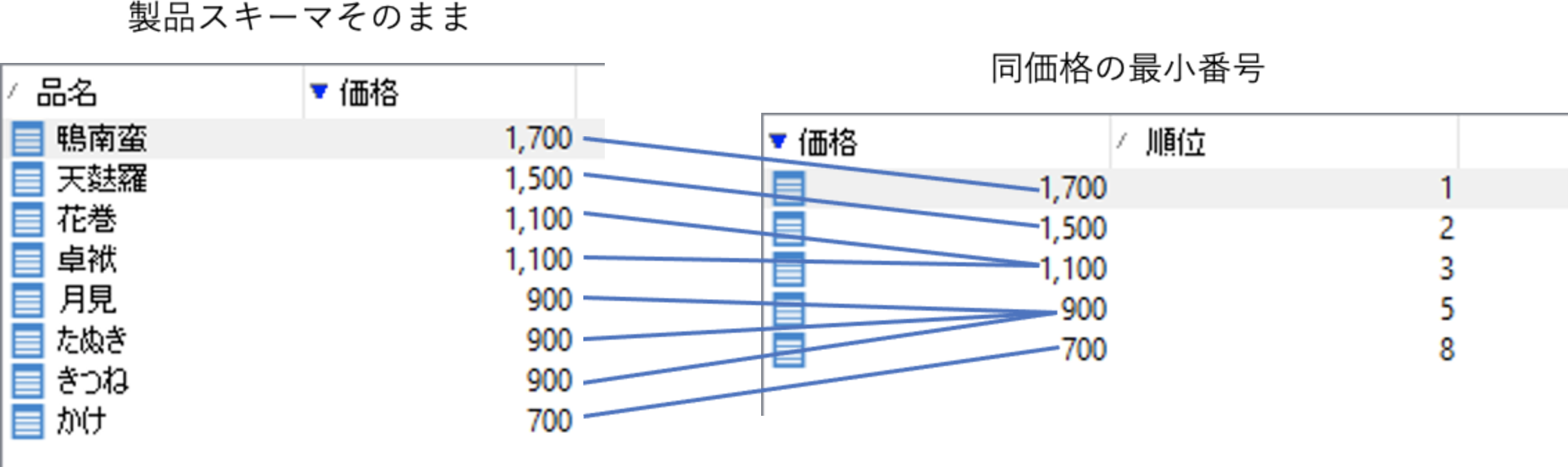
このとき紐づけあうスキーマはどちらも「製品」、そもそも同じもの。つまり自分と自分とをかけあわせることになり、これが自己結合というわけです。そして、その価格(@price)による紐づけで自己結合を実行するのが最後の「積集合」アクティビティでした:
以上により、同着を考慮した順位を得ることができるのです:
おつかれさまでした! 前回の内容から発展させ、複数アクティビティの組み合わせにより「自己結合」という上級テクニックを学んじゃいました。たとえこのとおりの要件はなくても、ここでの考え方を理解しておけば、できることはめちゃ広がりますよ。ぜひ本稿の手順を追って、そのアイディアを自分のものにしてください。
本稿の内容は筆者のオンプレミス型デモ環境(Adobe Campaign Classic 9359@c636bf3 PostgreSQL 14.9)上で実施した検証に基づきます。別環境における同様の動作を保証するものではありません。またデータは架空のものであり、既存の配信や実在の組織とはいっさい関係がありません。
-
この場合カスタム関数を作成するという手法もあります(追加の SQL 関数の定義)。しかし本稿では以下、さらに応用が利くような考え方・テクニックを紹介したいと思います。 ↩
-
ワークフロープロパティで「2つの実行間の中間母集団の結果を保持」をチェックしておくことが必要です。つねづね繰り返していますが、この設定は本番環境では行わないでください。 ↩
-
一般的にいう「自己結合」は、SQL1文のなかで自テーブルどうしをJOINすることを指します。Campaignで本要件に対応する場合、複数アクティビティに処理を分けるため異なる一時スキーマ(テーブル)間のJOINにならざるを得ず、その意味で生SQLレベルでの厳密な自己結合とはいえません。しかしワークフロー全体のロジックが自己結合に基づくものなので、そのアイディアを追って理解していただければと思います。 ↩