シリーズ前後5つ
- まだ
- まだ
- まだ
- Day001 : Botterまでの道のり(LSTMについてぼんやり理解する)
- Day002 : Botterまでの道のり(使っているライブラリのメモ)
- Day003 : Botterまでの道のり(PyTorchのCONV2Dを理解する) <- 今ここ
- まだ
- まだ
- まだ
- まだ
- まだ
動機
モデルをどうやって作ろうかなと思ったときに,まずなんとなくでも理解する必要があると思って・・・。
シリーズ全体が200記事くらい書ければB級Botterにはなれるはず・・・。
CONV2Dについて
例えば初期化するときに
self.conv1 = nn.Conv2d(1,16,3)
ってあるとするじゃないですか。
公式ページを確認すると,
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
out(N_i ,C_{\mathrm{out}_j})=bias(C_{\mathrm{out}_j})+\sum_{k=0}^{C_{\mathrm{in}}-1} weight(C_{\mathrm{out}_j} ,k) ⋆ input(N_i ,k)
みたいな数式も出てきて
torch.nn.Conv2dは第一引数から順に
-
入力のチャンネル数
-
出力のチャンネル数
-
カーネルのサイズ
-
stride 畳み込みの適用間隔
-
padding 入力に適用されるパディングの量を制御する。文字列 {'valid', 'same'} あるいは int のタプルで、 両側に適用される暗黙のパディングの量を指定
-
dilation カーネルポイント間の間隔を制御する。à trousアルゴリズムとしても知られているらしい。これを説明するのは難しいらしく、このリンク先には、dilationが何をするのかを視覚化した素晴らしい図があるとのこと。わからん。
-
group 入力と出力の接続を制御する。in_channels と out_channels はともにグループで分割可能である必要がある。
-
groups = 1 は,すべての入力がすべての出力に畳み込まれる。
-
groups = 2 は,2つのConv層を並べて、それぞれが半分の入力チャンネルを見て半分の出力チャンネルを生成し、その後に両者を連結することと同じになります。はい!わからん!
-
groups= in_channels は,各入力チャンネルは、それぞれのフィルターセットで畳み込まれる。出力サイズは,出力チャネル/入力チャネル
となるらしいですが,
self.conv1 = nn.Conv2d(1,16,3)
self.conv1 = nn.Conv2d(16,32,3)
となったときに最後Linearで結合しますよね?
これ計算できるらしいんですけど,まったくイミフ!!!
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
- in_features – 各入力サンプルの大きさ
- out_features – 各出力サンプルの大きさ
- bias – Falseに設定すると、レイヤーは加算バイアスを学習しない。デフォルトは True
入力されたデータに線形変換を適用するようですが,
y = xA^T + b
待て待てm手
yなんてどこにもないし,x A T Bも出てこないぞ・・・。
(書いてて気づいたけど,これ内積求めてんのね・・・)
聖杯きたこれー
これ見てください。
めっちゃわかりやすい。
ありがとうございます。
PyTrochにおける
MaxPool2d(2, 2)
の答えがありました。
上記ページからの引用です。
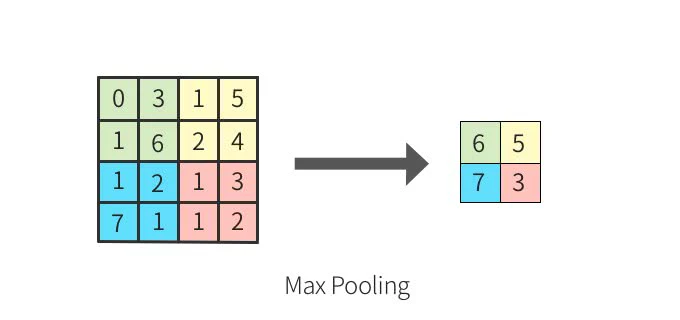
公式にも書いてあるじゃんしたの方に・・・。
OUT = \frac{IN + 2 * padding - dilation * (kernel_size - 1) -1}{stride} + 1
っていうのをひたすら計算していけばよいのですね!
例題
画像サイズとコードが既知のサイトを見つけましたのでそれを参考に致します!
self.conv1 = torch.nn.Conv2d(3, 16, 5)
self.pool1 = torch.nn.MaxPool2d(2, 2)
self.conv2 = torch.nn.Conv2d(16, 32, 5)
self.pool2 = torch.nn.MaxPool2d(2, 2)
入力画像は320x240みたいなので,
| conv1 | pool1 | conv2 | pool2 | |
|---|---|---|---|---|
| IN | 320 | 316 | 158 | 154 |
| padding | 0 | 0 | 0 | 0 |
| dilation | 1 | 1 | 1 | 1 |
| kernel_size | 5 | 2 | 5 | 2 |
| stride | 1 | 2 | 1 | 2 |
| out | 316 | 158 | 154 | 77 |
| conv1 | pool1 | conv2 | pool2 | |
|---|---|---|---|---|
| IN | 240 | 236 | 118 | 114 |
| padding | 0 | 0 | 0 | 0 |
| dilation | 1 | 1 | 1 | 1 |
| kernel_size | 5 | 2 | 5 | 2 |
| stride | 1 | 2 | 1 | 2 |
| out | 236 | 118 | 114 | 57 |
結合部の1個目を見ると57と77っていう数字が出てるので,
計算あってますよね!
self.fc1 = torch.nn.Linear(32 * 57 * 77, 512)
だいぶタイトルとは脱線しましたが,
これで任意画像でも使えるようになったので,
実装が進められそうです!
REFERENCEs
Botterの定義
Have a good Botter Life!!!