はじめに
ファインチューニングは、学習済みのAIモデルを自分のデータで追加学習させて、特定のタスクに強くする技術です。「はじめてのClaude Code」「はじめてのCodex」「はじめてのDocker」「はじめてのバイブコーディング」に続く、「はじめての〇〇シリーズ」第5弾です。
前回まではAIを使う側の話でした。今回からはAIを作る側に入ります。シリーズの転換点です。

研究室あるある、こんな経験ありませんか?
あるある① — ChatGPTが専門用語を理解してくれない
「このXRDパターンからペロブスカイト相を同定して」と聞いたら、一般的な説明が返ってきて、自分の実験データに即した回答がまったく出てこない。ChatGPTは汎用的に賢いけど、あなたの研究分野の専門家ではない。
あるある② — 論文PDFをOCRしたらボロボロ
先行研究の論文から表やグラフのキャプションを抽出したい。無料のOCRツールを試したら、数式は崩れるし、二段組のレイアウトは無視されるし、日本語と英語が混在すると文字化けする。
あるある③ — 実験画像の説明を自動化したい
顕微鏡画像が毎日100枚以上溜まっていく。手動で記録を書くのは限界。画像を入れたら「SEM像、倍率5000倍、粒径約200nmの球状粒子が確認される」みたいな説明を自動生成してほしい。
これらの問題に共通する解決策が、ファインチューニングです。汎用モデルを自分の研究データで追加学習させれば、あなたの研究分野の専門家に変えることができます。
この記事で学ぶこと
この記事では、Macでの初体験からスタートして、GPUサーバーでのVLM・OCRファインチューニング、そしてモデルの配布まで、レベル別に解説します。
| レベル | 内容 | できるようになること |
|---|---|---|
| Lv.1 | ファインチューニングとは | 概念を理解し、手法を選べる |
| Lv.2 | MacではじめてのLoRA | Apple SiliconでLLMを追加学習できる |
| Lv.3 | GPUサーバーでLoRA | NVIDIA GPUで本格的に学習できる |
| Lv.4 | VLMのファインチューニング | 画像+テキストのモデルを学習できる |
| Lv.5 | OCRモデルのファインチューニング | 文書認識を自分のドメインに特化できる |
| Lv.6 | マージ・量子化・デプロイ | 作ったモデルを研究室で共有できる |
Lv.3まで到達すれば、テキストLLMのファインチューニングは一通りできるようになります。Lv.6まで行けば、自分で作ったモデルをOllamaに載せて研究室のみんなに配るところまでできます。
それでは、Lv.1から始めましょう。
Lv.1 — ファインチューニングとは?
「学習済みモデル」のおさらい
ChatGPTやClaude、Llamaなどの大規模言語モデル(LLM)は、インターネット上の膨大なテキストデータを使って**事前学習(Pre-training)**されています。この事前学習には、数千台のGPUで数ヶ月かかります。コストは数億〜数十億円。個人で再現することは不可能です。
でも、この学習済みモデルを自分のデータで少しだけ追加学習させることはできます。これが**ファインチューニング(Fine-tuning)**です。
料理でたとえると
ファインチューニングを料理でたとえましょう。
| 料理のたとえ | AIモデルの世界 | |
|---|---|---|
| 事前学習 | 料理学校で何万種類もの料理を学ぶ | 大量のテキストで基礎知識を学習 |
| 学習済みモデル | 卒業したシェフ(何でも作れる) | GPT、Claude、Llama等 |
| ファインチューニング | 「うちの店は和食専門だから」と和食を集中特訓 | 自分のデータで追加学習 |
| 特化モデル | 和食の達人シェフ | 特定タスクに強いモデル |
ポイントは、ゼロから料理学校に通い直す(事前学習をやり直す)必要はないということです。既に基礎ができているシェフに、得意分野を伸ばす特訓をするだけ。だから速くて安い。
ファインチューニングの3つの手法
ファインチューニングにはいくつかの手法があります。主要な3つを比較しましょう。
| 手法 | 説明 | メモリ使用量 | 速度 | たとえ |
|---|---|---|---|---|
| フルファインチューニング | モデルの全パラメータを更新 | 非常に多い | 遅い | シェフの全技術を再訓練 |
| LoRA | 少数の追加パラメータだけを学習 | 少ない | 速い | 和食の技術だけを追加で教える |
| QLoRA | LoRA + モデルを4bit量子化 | さらに少ない | 速い | 教科書を要約版にしてから特訓 |
結論から言うと、ほとんどの場面でLoRA(またはQLoRA)を使います。 フルファインチューニングは7Bモデルでも60GB以上のGPUメモリが必要で、個人の環境では現実的ではありません。LoRAなら同じモデルを8GB程度でファインチューニングできます。
LoRAとは? — 論文から理解する
LoRA(Low-Rank Adaptation) は2021年にMicrosoftの研究チームが発表した手法で、ファインチューニングの世界を一変させました(Hu et al., 2021)。ここでは、研究室に配属されたばかりの新入生でもわかるように、段階的に説明します。
まず「重み行列」って何?
LLMの中身は、巨大な行列(重み行列, weight matrix)の集まりです。行列というのは、数字が縦横に並んだ表のようなもの。LLMが「次にどの単語を出力するか」を決めるとき、入力を行列に掛け算して変換しています。
入力ベクトル x → [ 重み行列 W ] → 出力ベクトル h
W は d×d の巨大な行列(例:4096×4096 = 約1600万個の数字)
LLMにはこの行列が何十層もある → 合計で数十億パラメータ
フルファインチューニングでは、この巨大な行列 W を丸ごと書き換えます。7Bモデルなら70億個の数字を全部更新するので、メモリも計算量も膨大です。
LoRAの核心アイデア — 「小さな行列を横に足す」
LoRAの発想はシンプルです。「行列 W を書き換える必要なんてない。小さな行列を横に足せばいい」。
論文のFigure 1がこれを端的に表しています。
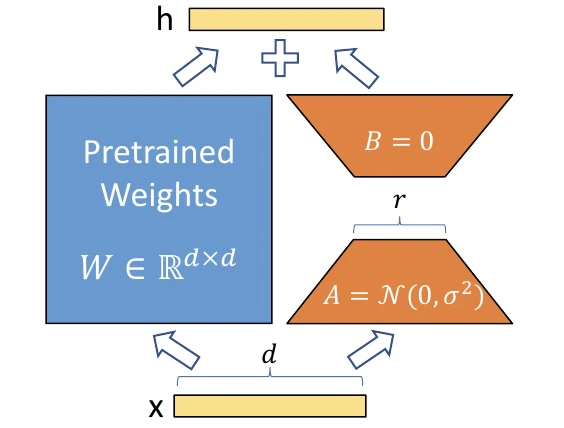
出典:Hu et al., "LoRA: Low-Rank Adaptation of Large Language Models", 2021, Figure 1
この図を読み解きましょう。
| 図の要素 | 意味 |
|---|---|
| x(下の黄色バー) | 入力(ある層に入ってくるデータ) |
| h(上の黄色バー) | 出力(次の層に渡すデータ) |
| Pretrained Weights W(左の青い四角) | 元の重み行列。凍結して一切変更しない |
| A(下のオレンジ台形) | LoRAで追加する小さな行列。d → r に圧縮(r は rank) |
| B = 0(上のオレンジ台形) | LoRAで追加する小さな行列。r → d に復元。初期値はゼロ |
| + | W の出力と BA の出力を足し合わせる |
数式で書くと、こうなります:
通常の推論: h = W × x
LoRA適用後: h = W × x + B × A × x
↑ 凍結 ↑ ここだけ学習
ポイントは r(rank)が非常に小さい ことです。元の行列 W が 4096×4096(約1600万パラメータ)なのに対して、A は 4096×8、B は 8×4096 で、合計わずか 65,536パラメータ(0.4%)。この「小さな迂回路」だけを学習するので、メモリも計算も圧倒的に少なくて済みます。
「rank(ランク)」をもう少し直感的に。 rank は「追加する知識の幅」だと思ってください。rank=8 は「8個の新しい視点を追加する」ようなもの。研究分野の専門用語を覚えさせる程度なら rank=8〜16 で十分です。rank=64 にすると表現力は上がりますが、学習データが少ないと過学習(覚えすぎ)のリスクが上がります。通常は 8〜32 で十分です。
なぜ「低ランク」で十分なのか?
「たった0.4%の追加で本当に効果があるの?」という疑問は当然です。LoRA論文では、モデルを新しいタスクに適応させるとき、重みの変化量は実は低ランク(少数の方向にしか変化しない) ことを実験的に示しています。つまり、タスクの適応に必要な情報は、巨大な行列全体を動かさなくても、少数の「方向」を追加するだけで十分に表現できるのです。
これは料理のたとえに戻ると、「和食専門シェフになるのに、全ての料理技術を再訓練する必要はない。出汁の取り方と包丁の使い方という数本の軸を追加すれば十分」ということです。
何に使えるのか?
ファインチューニングの応用例をいくつか紹介します。
| 用途 | 入力 | 出力 | モデルの種類 |
|---|---|---|---|
| 専門Q&A | 質問テキスト | 専門的な回答 | LLM(テキスト) |
| 論文要約 | 論文テキスト | 要約文 | LLM(テキスト) |
| 画像キャプション | 実験画像 | 説明テキスト | VLM(画像+テキスト) |
| 文書OCR | 論文PDF画像 | 抽出テキスト | OCRモデル |
| コード生成 | 自然言語の指示 | コード | LLM(テキスト) |
LLM(テキストだけ)、VLM(画像+テキスト)、OCR(画像→テキスト)—— この記事ではこの3種類すべてのファインチューニングを実際にやります。
ここまでで概念の理解はOKです。Lv.2からは実際に手を動かしていきましょう。
Lv.2 — MacではじめてのLoRA
まずはMacのApple Silicon(M1/M2/M3/M4/M5)で、小さなモデルのLoRAファインチューニングを体験します。「動いた!」をまず感じるのが目的です。
使うもの
| 項目 | 内容 |
|---|---|
| ツール | mlx-lm(Apple公式のMLXフレームワーク) |
| モデル | Qwen2.5-3B-Instruct(30億パラメータ、軽量) |
| データ | 日本語の指示データ(kunishou/databricks-dolly-15k-ja) |
| 環境 | Mac(Apple Silicon、メモリ16GB以上推奨) |
なぜmlx-lm? Apple社が開発した機械学習フレームワークMLXのLLM特化パッケージです。WWDC 2025でも3セッション使って紹介されたAppleの本命技術で、Apple Siliconのユニファイドメモリを最大限に活かせます。CUDAは不要です。
mlx-lmのインストール
Python環境が必要です。前回までの記事でpythonは入っている前提で進めます。
# 仮想環境を作る(推奨)
python3 -m venv ~/finetuning-env
source ~/finetuning-env/bin/activate
# mlx-lmをインストール
pip install mlx-lm
バージョンを確認しましょう。
python3 -c "import mlx_lm; print('mlx-lm installed successfully')"
mlx-lm installed successfully と表示されればOKです。
データセットの準備
ファインチューニングには学習データが必要です。今回は、日本語の指示-応答データセットを使います。
まず、必要なライブラリをインストールします。
pip install datasets
次に、データセットをダウンロードして、mlx-lmが読める形式(JSONL)に変換するスクリプトを書きます。
# prepare_data.py
from datasets import load_dataset
import json
# 日本語の指示データセットをダウンロード
dataset = load_dataset("kunishou/databricks-dolly-15k-ja")
# 学習用と検証用に分割
split = dataset["train"].train_test_split(test_size=0.1, seed=42)
def format_conversation(example):
"""mlx-lmのチャット形式に変換"""
messages = []
# システムプロンプト
messages.append({
"role": "system",
"content": "あなたは親切で正確な日本語アシスタントです。"
})
# ユーザーの指示
instruction = example["instruction"]
if example.get("input") and example["input"].strip():
instruction += f"\n\n参考情報:\n{example['input']}"
messages.append({"role": "user", "content": instruction})
# アシスタントの応答
messages.append({"role": "assistant", "content": example["output"]})
return {"messages": messages}
# JSONL形式で保存
for split_name, data in [("train", split["train"]), ("valid", split["test"])]:
output_path = f"data/{split_name}.jsonl"
import os
os.makedirs("data", exist_ok=True)
with open(output_path, "w", encoding="utf-8") as f:
for example in data:
formatted = format_conversation(example)
f.write(json.dumps(formatted, ensure_ascii=False) + "\n")
print(f"{split_name}: {len(data)} examples → {output_path}")
python3 prepare_data.py
train: 13500 examples → data/train.jsonl
valid: 1500 examples → data/valid.jsonl
データの中身を1件見てみましょう。
head -1 data/train.jsonl | python3 -m json.tool
{
"messages": [
{
"role": "system",
"content": "あなたは親切で正確な日本語アシスタントです。"
},
{
"role": "user",
"content": "ヴァージン・オーストラリア航空はいつから運航を開始しましたか?"
},
{
"role": "assistant",
"content": "ヴァージン・オーストラリア航空は2000年8月31日にVirgin Blueとして、..."
}
]
}
これが1件の学習データです。「ユーザーがこう聞いたら、アシスタントはこう答える」というペアの集まりです。
LoRAの設定ファイル
mlx-lmのLoRA設定を書きます。
# lora_config.yaml
# LoRAの基本設定
lora_layers: 16 # LoRAを適用するレイヤー数(モデルの後ろから16層)
lora_rank: 8 # ランク(小さいほど軽量、8で十分)
lora_scale: 16.0 # スケーリング係数(alpha)
# 学習パラメータ
batch_size: 1 # バッチサイズ(メモリに合わせて調整)
iters: 1000 # 学習ステップ数
val_batches: 25 # 検証に使うバッチ数
learning_rate: 1e-5 # 学習率
steps_per_report: 10 # 何ステップごとにログを出すか
steps_per_eval: 100 # 何ステップごとに検証するか
adapter_path: "adapters" # LoRAアダプタの保存先
save_every: 200 # 何ステップごとに保存するか
設定のポイント:
-
lora_rank: 8— 初めてなら8で十分。品質を上げたければ16や32にする -
iters: 1000— 13500件のデータに対して1000ステップは少なめ。まずは動作確認が目的 -
batch_size: 1— メモリ16GBのMacなら1が安全。32GB以上あれば2〜4に上げられる
いよいよファインチューニング実行
準備ができました。以下のコマンドでLoRAファインチューニングを開始します。
mlx_lm.lora \
--model mlx-community/Qwen2.5-3B-Instruct-4bit \
--data ./data \
--train \
--config lora_config.yaml
mlx-community/Qwen2.5-3B-Instruct-4bit とは? Hugging Faceのmlx-communityが公開している、MLX用に変換済みの4bit量子化モデルです。4bit量子化されているので、QLoRA相当の省メモリ学習になります。初回実行時にモデルが自動ダウンロードされます(約2GB)。
実行すると、以下のようなログが流れ始めます。
Loading pretrained model
Fetching 6 files: 100%
Loading model from mlx-community/Qwen2.5-3B-Instruct-4bit
Total parameters: 3086.385M
Trainable parameters: 1.573M (0.051%)
Starting training..., iters: 1000
Iter 10: Train loss 2.413, It/sec 1.52, Tokens/sec 312.4
Iter 20: Train loss 2.187, It/sec 1.48, Tokens/sec 305.1
...
Iter 100: Val loss 1.892, Val took 12.3s
...
Iter 1000: Train loss 1.234, It/sec 1.45, Tokens/sec 298.7
Iter 1000: Val loss 1.456, Val took 12.1s
Saved adapter weights to adapters/adapters.safetensors
注目してほしい数字があります。
| 項目 | 意味 |
|---|---|
Total parameters: 3086.385M |
モデル全体は30億パラメータ |
Trainable parameters: 1.573M (0.051%) |
学習するのはたった0.051%(157万パラメータ) |
Train loss 2.413 → 1.234 |
ロス(誤差)が下がっている=学習が進んでいる |
30億パラメータのうち、たった157万(0.051%)だけを学習する。これがLoRAの威力です。
学習にかかる時間の目安: M3 MacBook Pro(メモリ36GB)で約30〜60分、M1 MacBook Air(メモリ16GB)で約2〜3時間です。気長に待ちましょう。途中でMacを閉じないように注意してください。
ファインチューニング前後で比較する
学習が終わったら、ファインチューニング前後のモデルを比較してみましょう。
ファインチューニング前(ベースモデル)
mlx_lm.generate \
--model mlx-community/Qwen2.5-3B-Instruct-4bit \
--prompt "量子コンピュータについて簡潔に説明してください。"
ファインチューニング後(LoRAアダプタ適用)
mlx_lm.generate \
--model mlx-community/Qwen2.5-3B-Instruct-4bit \
--adapter-path ./adapters \
--prompt "量子コンピュータについて簡潔に説明してください。"
違いは --adapter-path ./adapters を付けるかどうかだけです。LoRAアダプタは元のモデルとは別ファイルなので、アダプタを外せばいつでも元のモデルに戻れます。
LoRAアダプタのサイズを見てみましょう。
ls -lh adapters/
アダプタファイルは数MB〜数十MB程度です。30億パラメータのモデル本体が2GBあるのに対して、LoRAアダプタはわずか数MB。このコンパクトさも、LoRAの大きなメリットです。アダプタだけを共有すれば、同じベースモデルを持っている人なら誰でも使えます。
Macで「LoRAファインチューニングって、こういうことか」と感覚が掴めましたね。Lv.2はこれで完了です。次のLv.3では、GPUサーバーに移動して、より大きなモデルをより速くファインチューニングします。
Lv.3 — GPUサーバーでLoRA(Unsloth)
MacのLoRAでは3Bモデルで30分〜数時間かかりました。GPUサーバーなら、7Bモデルでも数分で終わります。ここからはNVIDIA GPUを使った本格的なファインチューニングです。
使うもの
| 項目 | 内容 |
|---|---|
| ツール | Unsloth(高速LoRAライブラリ) |
| モデル | Qwen2.5-7B-Instruct(70億パラメータ) |
| データ | Lv.2と同じ日本語指示データ |
| 環境 | NVIDIA GPU搭載サーバー(VRAM 16GB以上) |
なぜUnsloth? Hugging Faceの標準ライブラリ(PEFT + Transformers)でもLoRAはできますが、Unslothは2倍高速・70%少ないVRAMで同じことができます。500以上のモデルに対応しており、2026年現在のNVIDIA GPU向けLoRAの事実上の標準です。
GPUサーバーにSSH接続
「はじめてのDocker」で学んだSSH接続を使います。
ssh username@gpu-server-address
GPUが見えるか確認しましょう。
nvidia-smi
GPUの名前とメモリが表示されればOKです。
Docker環境の準備
「はじめてのDocker」のLv.5で学んだGPUサーバーのDockerを使います。PyTorchのGPUコンテナ内で作業しましょう。
docker run -it --gpus all \
-v $(pwd):/workspace \
-w /workspace \
nvcr.io/nvidia/pytorch:25.12-py3 \
bash
コマンドの意味:
-
--gpus all— コンテナ内からGPUを使えるようにする(Docker編Lv.5で学びましたね) -
-v $(pwd):/workspace— 現在のディレクトリをコンテナ内の/workspaceにマウント -
nvcr.io/nvidia/pytorch:25.12-py3— NVIDIAが提供するGPU対応PyTorchイメージ
Unslothのインストール
コンテナ内でUnslothをインストールします。
pip install unsloth
学習スクリプトを書く
Unslothの学習スクリプトは、mlx-lmよりも少し構造的です。1つのPythonファイルにまとめましょう。
# train_unsloth.py
from unsloth import FastLanguageModel
from trl import SFTTrainer
from transformers import TrainingArguments
from datasets import load_dataset
# --- 1. モデルの読み込み ---
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/Qwen2.5-7B-Instruct",
max_seq_length=2048,
load_in_4bit=True, # 4bit量子化で読み込み(QLoRA)
)
# --- 2. LoRAの設定 ---
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRAのランク
target_modules=[ # LoRAを適用する層
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha=16, # スケーリング係数
lora_dropout=0, # ドロップアウト(0が推奨)
bias="none",
use_gradient_checkpointing="unsloth", # メモリ節約
)
# --- 3. データセットの準備 ---
dataset = load_dataset("kunishou/databricks-dolly-15k-ja", split="train")
def format_prompt(example):
"""Qwen2.5のチャット形式に変換"""
instruction = example["instruction"]
if example.get("input") and example["input"].strip():
instruction += f"\n\n参考情報:\n{example['input']}"
messages = [
{"role": "system", "content": "あなたは親切で正確な日本語アシスタントです。"},
{"role": "user", "content": instruction},
{"role": "assistant", "content": example["output"]},
]
text = tokenizer.apply_chat_template(messages, tokenize=False)
return {"text": text}
dataset = dataset.map(format_prompt)
# --- 4. 学習の設定と実行 ---
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=2048,
args=TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=10,
num_train_epochs=1,
learning_rate=2e-4,
fp16=True,
logging_steps=10,
output_dir="outputs",
seed=42,
),
)
print("Starting training...")
trainer.train()
# --- 5. 保存 ---
model.save_pretrained("qwen25-7b-ja-lora")
tokenizer.save_pretrained("qwen25-7b-ja-lora")
print("Done! Adapter saved to qwen25-7b-ja-lora/")
学習を実行する
python3 train_unsloth.py
🦥 Unsloth: Loading Qwen2.5-7B-Instruct with 4bit quantization
Trainable parameters: 41,943,040 / 7,615,616,000 (0.55%)
Starting training...
{'loss': 1.823, 'learning_rate': 2e-4, 'epoch': 0.01}
{'loss': 1.456, 'learning_rate': 1.9e-4, 'epoch': 0.12}
...
{'loss': 0.892, 'learning_rate': 5e-5, 'epoch': 0.89}
{'loss': 0.834, 'learning_rate': 1e-5, 'epoch': 1.0}
Training completed in 8 minutes 32 seconds
Done! Adapter saved to qwen25-7b-ja-lora/
8分で完了です。Macで30分以上かかったのが、GPUサーバーなら8分。しかもモデルは3B→7Bと2倍以上大きくなっています。
Mac vs GPUサーバーの比較
| 項目 | Lv.2(Mac) | Lv.3(GPUサーバー) |
|---|---|---|
| ツール | mlx-lm | Unsloth |
| モデル | Qwen2.5-3B(4bit) | Qwen2.5-7B(4bit) |
| 学習時間 | 30分〜数時間 | 約8分 |
| バッチサイズ | 1 | 4 |
| VRAM/メモリ | 〜8GB(ユニファイドメモリ) | 〜12GB(VRAM) |
GPUの圧倒的な並列処理性能が、この差を生んでいます。研究用途で本格的にファインチューニングするなら、GPUサーバーを使いましょう。Macは「手元で試す」用途です。
ファインチューニング後のモデルをテストする
学習したアダプタを読み込んで、推論してみましょう。
# test_model.py
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="qwen25-7b-ja-lora", # アダプタのパス
max_seq_length=2048,
load_in_4bit=True,
)
FastLanguageModel.for_inference(model)
messages = [
{"role": "system", "content": "あなたは親切で正確な日本語アシスタントです。"},
{"role": "user", "content": "機械学習と深層学習の違いを簡潔に説明してください。"},
]
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_tensors="pt"
).to("cuda")
outputs = model.generate(input_ids=inputs, max_new_tokens=256)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
python3 test_model.py
日本語で流暢な回答が返ってくれば成功です。ベースモデルと比較して、日本語の指示に対する応答品質が向上しているはずです。
Lv.3はここまでです。テキストLLMのLoRAファインチューニングを、MacとGPUサーバーの両方で体験しました。次のLv.4では、**画像を理解するモデル(VLM)**のファインチューニングに挑みます。
Lv.4 — VLMのファインチューニング
**VLM(Vision-Language Model)**は、画像とテキストの両方を理解できるマルチモーダルモデルです。「画像を見て質問に答える」「画像の説明を生成する」といったことができます。
Lv.3まではテキストだけのモデルでした。ここからは画像+テキストの世界に入ります。
VLMとは?
普通のLLMとVLMの違いを整理しましょう。
| LLM(Lv.2-3で使用) | VLM(今回) | |
|---|---|---|
| 入力 | テキストのみ | テキスト + 画像 |
| 出力 | テキスト | テキスト |
| できること | 質問応答、要約、翻訳 | 画像の説明、画像Q&A、図表の読み取り |
| 例 | Qwen2.5-7B, Llama 3 | Qwen2.5-VL, LLaVA, Gemma 3 |
VLMの内部構造は、画像エンコーダ + LLMの2つで構成されています。
画像 → [画像エンコーダ(ViT等)] → 画像の特徴ベクトル
↓
テキスト → [LLM] ← 画像の特徴ベクトルも入力として受け取る → 回答テキスト
ファインチューニングでは、この全体(または一部)を自分のデータで追加学習させます。
使うもの
| 項目 | 内容 |
|---|---|
| ツール | Unsloth(VLMのLoRAにも対応) |
| モデル | Qwen2.5-VL-7B-Instruct |
| データ | 画像+説明のペアデータ |
| 環境 | NVIDIA GPU(VRAM 24GB以上推奨) |
データセットの準備
VLMのファインチューニングには、「画像 + 質問 + 回答」のセットが必要です。今回はHugging Faceで公開されているデータセットを使います。
# prepare_vlm_data.py
from datasets import load_dataset
import json, os
# 画像キャプションデータセットを使用
dataset = load_dataset("lmms-lab/LLaVA-OneVision-Data",
"cauldron_science_qa", split="train[:1000]")
os.makedirs("vlm_data", exist_ok=True)
formatted = []
for i, example in enumerate(dataset):
# 画像を保存
img_path = f"vlm_data/img_{i:04d}.jpg"
example["image"].save(img_path)
formatted.append({
"messages": [
{
"role": "user",
"content": [
{"type": "image", "image": img_path},
{"type": "text", "text": example["question"]},
]
},
{
"role": "assistant",
"content": example["answer"],
}
]
})
with open("vlm_data/train.jsonl", "w") as f:
for item in formatted:
f.write(json.dumps(item, ensure_ascii=False) + "\n")
print(f"Saved {len(formatted)} examples")
VLMのデータ形式はLLMと違います。 ユーザーメッセージの content がテキストだけでなく、[{"type": "image", ...}, {"type": "text", ...}] のようにマルチモーダルになっています。画像とテキストを組み合わせて入力するためです。
学習スクリプト
# train_vlm.py
from unsloth import FastVisionModel
from trl import SFTTrainer
from transformers import TrainingArguments
from datasets import load_dataset
import json
# --- 1. VLMの読み込み ---
model, tokenizer = FastVisionModel.from_pretrained(
model_name="unsloth/Qwen2.5-VL-7B-Instruct",
max_seq_length=2048,
load_in_4bit=True,
)
# --- 2. LoRAの設定 ---
model = FastVisionModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
finetune_vision_layers=True, # 画像エンコーダもファインチューニング
finetune_language_layers=True, # 言語モデルもファインチューニング
finetune_attention_modules=True, # アテンション層を含める
finetune_mlp_modules=True, # MLP層を含める
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
)
# --- 3. データセットの読み込み ---
# Unslothのチャット形式に変換
from unsloth.chat_templates import standardize_sharegpt
# データを読み込み
with open("vlm_data/train.jsonl") as f:
data = [json.loads(line) for line in f]
from datasets import Dataset
dataset = Dataset.from_list(data)
# --- 4. 学習 ---
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
num_train_epochs=1,
learning_rate=2e-4,
fp16=True,
logging_steps=5,
output_dir="vlm_outputs",
remove_unused_columns=False,
),
)
print("Starting VLM training...")
trainer.train()
# --- 5. 保存 ---
model.save_pretrained("qwen25-vl-7b-lora")
tokenizer.save_pretrained("qwen25-vl-7b-lora")
print("Done! VLM adapter saved.")
LLMのスクリプト(Lv.3)との違い:
-
FastLanguageModel→FastVisionModelに変更 -
finetune_vision_layers=Trueで画像エンコーダも学習対象にしている - データ形式が画像を含むマルチモーダル
これ以外の構造は、Lv.3とほぼ同じです。
学習の実行
python3 train_vlm.py
🦥 Unsloth: Loading Qwen2.5-VL-7B-Instruct with 4bit quantization
Trainable parameters: 54,329,344 / 8,291,645,440 (0.66%)
Starting VLM training...
{'loss': 2.156, 'learning_rate': 2e-4, 'epoch': 0.02}
...
{'loss': 0.712, 'learning_rate': 1e-5, 'epoch': 1.0}
Training completed in 15 minutes 48 seconds
Done! VLM adapter saved.
VLMはLLMより少し時間がかかります。画像の処理が加わるためです。
ファインチューニング後のテスト
画像を入力して、質問に答えさせてみましょう。
# test_vlm.py
from unsloth import FastVisionModel
from PIL import Image
model, tokenizer = FastVisionModel.from_pretrained(
model_name="qwen25-vl-7b-lora",
max_seq_length=2048,
load_in_4bit=True,
)
FastVisionModel.for_inference(model)
# テスト画像を読み込み
image = Image.open("test_image.jpg")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "この画像に何が写っていますか?詳しく説明してください。"},
]
}
]
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True,
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs, images=[image], max_new_tokens=256
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
ファインチューニングによって、特定ドメインの画像(実験装置、顕微鏡画像など)に対する説明の品質が上がります。
Lv.4はここまでです。テキスト(LLM)だけでなく、画像+テキスト(VLM)のファインチューニングもできるようになりました。次のLv.5では、OCRに特化したモデルをファインチューニングします。
Lv.5 — OCRモデルのファインチューニング
OCRとは? — 「画像から文字を読む」技術
OCR(Optical Character Recognition、光学文字認識) は、画像の中に写っている文字を、コンピュータが読めるテキストデータに変換する技術です。
身近な例から考えてみましょう。
| 場面 | 入力(画像) | 出力(テキスト) |
|---|---|---|
| スマホで名刺を撮影 | 名刺の写真 | 名前・電話番号・メールアドレス |
| 論文PDFをコピペ | PDFのページ画像 | 論文の本文テキスト |
| 手書きノートをデジタル化 | ノートの写真 | 書かれた文章 |
| レシートを家計簿に入力 | レシートの写真 | 商品名・金額 |
人間にとっては「画像を見て文字を読む」のは簡単ですが、コンピュータにとっては非常に難しい問題です。フォントの種類、文字サイズ、レイアウト、背景ノイズ、手書きの癖……これらすべてに対応しなければなりません。
従来のOCR vs 深層学習OCR
OCRの歴史は長く、技術は大きく進化してきました。
| 従来のOCR(パイプライン型) | 深層学習OCR(End-to-End型) | |
|---|---|---|
| 仕組み | ①レイアウト解析 → ②文字領域検出 → ③文字認識 と段階的に処理 | 画像を入れると、一気にテキストが出てくる |
| 代表例 | Tesseract, Google Cloud Vision | DeepSeek-OCR, GOT-OCR2.0, Nougat |
| 長所 | 処理が明確で制御しやすい | 複雑なレイアウトにも強い。数式や表にも対応 |
| 短所 | 段階ごとにエラーが蓄積する。複雑なレイアウトに弱い | 大量のデータで学習が必要 |
研究の現場では特に、論文PDFの読み取りが問題になります。論文には二段組レイアウト、数式、グラフ、表、図のキャプションなどが混在しており、従来のパイプライン型OCRでは精度がガクッと落ちます。
DeepSeek-OCRのアーキテクチャ — 論文から理解する
この記事で使うDeepSeek-OCR 2は、DeepSeek-AIが開発したEnd-to-End型のOCRモデルです(Wei et al., 2026)。まず初代DeepSeek-OCR(Wei et al., 2025)のアーキテクチャを見てみましょう。
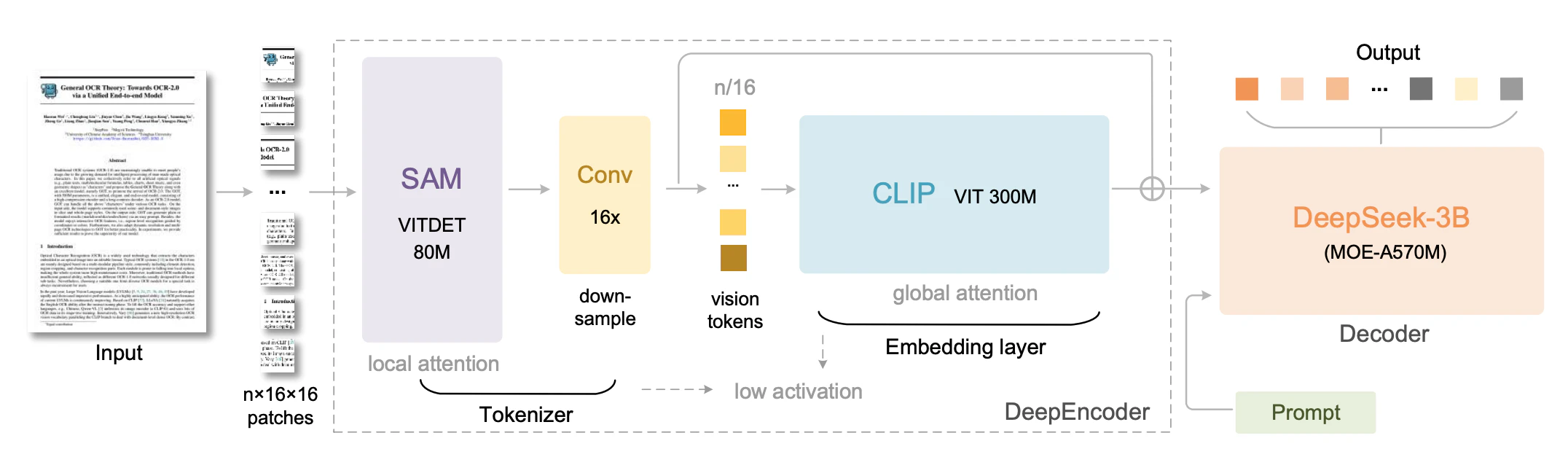
出典:Wei et al., "DeepSeek-OCR: Contexts Optical Compression", 2025, Figure 3
この図の流れを読み解きましょう。
| 図の要素 | 役割 | 新入生向けの説明 |
|---|---|---|
| Input(左の文書画像) | OCRに入力する画像 | 論文PDFのページなど |
| SAM (VITDET 80M) | 画像を小さなパッチに分割して特徴を抽出 | 画像の「下読み」をする目 |
| Conv 16x | パッチを16倍に圧縮 | 情報をギュッと凝縮する圧縮機 |
| CLIP (ViT 300M) | 圧縮された特徴を「意味のある表現」に変換 | 画像の内容を「理解」する脳 |
| DeepSeek-3B (Decoder) | 画像の特徴からテキストを生成 | 理解した内容を文字に書き起こす手 |
つまり、「目で見て → 圧縮して → 理解して → 書き起こす」 という人間の読書プロセスに似た流れです。
DeepSeek-OCR 2の革新 — 人間のように読む順序を学ぶ
DeepSeek-OCR 2は、初代からエンコーダ(画像を理解する部分) を大幅にアップグレードしました。

出典:Wei et al., "DeepSeek-OCR 2: Visual Causal Flow", 2026, Figure 1
| DeepEncoder(初代) | DeepEncoder V2(OCR 2) | |
|---|---|---|
| 画像理解の方法 | CLIP(ViT 300M)を使用 | LLM(Qwen2 500M)を画像エンコーダとして使用 |
| 読む順序 | 固定的(左上→右下のラスタースキャン) | 人間のように意味に基づいた順序で読む |
| トークン処理 | non-causal(全体を一度に見る) | causal flow query(因果的に順序を決めて読む) |
ポイントは 「人間のように読む」 という点です。人間は論文を読むとき、タイトル→著者→概要→本文と、意味的な順序で目を動かします。従来のOCRは画像を左上から機械的にスキャンしていましたが、DeepEncoder V2は**learnable query(学習可能なクエリ)**を使って、読むべき順序を自ら学習します。
全体のアーキテクチャはこうなっています。

出典:Wei et al., "DeepSeek-OCR 2: Visual Causal Flow", 2026, Figure 3
実際のOCR結果 — 論文のDeep Parsing
DeepSeek-OCRの「Deep Parsing」機能は、文書中のグラフや表を構造的に解析できます。以下は金融レポートをOCRした実例です。

出典:Wei et al., "DeepSeek-OCR: Contexts Optical Compression", 2025, Figure 7
入力画像(左上)の金融レポートから、テキストだけでなくグラフのデータポイントまで構造的に抽出できています。下段では、棒グラフを入力すると国名・年度・数値の表形式データとして出力されています。
このレベルのOCR精度があれば、「先輩の論文PDFから表やグラフのデータを自動抽出する」といった研究の自動化が現実的になります。
なぜOCRをファインチューニングするのか?
DeepSeek-OCR 2は汎用的に高精度ですが、あなたの研究分野特有の文書にはさらに精度を上げたいケースがあります。
| 苦手な場面 | 原因 |
|---|---|
| 数式($\int_0^\infty e^{-x^2}dx$) | 特殊記号・上付き下付き文字 |
| 二段組の論文 | レイアウト解析が不十分 |
| 手書きの実験ノート | 個人の筆跡に未対応 |
| 日本語+英語+数式の混在 | 言語切り替えが頻繁 |
ファインチューニングすれば、あなたの研究分野でよく出てくる文書形式に特化したOCRモデルを作れます。DeepSeek-OCR 2の論文では、ドメイン特化のファインチューニングで文字誤り率(Edit Distance)が大幅に改善されたことが報告されています。
使うもの
| 項目 | 内容 |
|---|---|
| ツール | Unsloth |
| モデル | DeepSeek-OCR 2(3Bパラメータ、Apache 2.0) |
| データ | 文書画像 + 正解テキストのペア |
| 環境 | NVIDIA GPU(VRAM 16GB以上) |
なぜDeepSeek-OCR 2? 2026年1月にリリースされた最新のOCR特化モデルです。従来のOCRがグリッド状にスキャンするのに対し、DeepSeek-OCR 2は人間のように意味に基づいた順序で読む(DeepEncoder V2)ため、複雑なレイアウトにも強い。OmniDocBench v1.5でOverall 91.09% を達成し、Gemini-3 Pro(Overall 85.82%)やQwen2.5-VL-72B(Overall 88.27%)を超えています。Unslothでのファインチューニングに公式対応しています。
データセットの準備
OCRのファインチューニングデータは、文書画像 + 正解テキストのペアです。
# prepare_ocr_data.py
import json, os
from datasets import load_dataset
# サンプルとして公開データセットを使用
# 実際には自分の研究分野の文書画像を用意する
dataset = load_dataset("naver-clova-ix/cord-v2", split="train[:500]")
os.makedirs("ocr_data", exist_ok=True)
formatted = []
for i, example in enumerate(dataset):
img_path = f"ocr_data/doc_{i:04d}.jpg"
example["image"].save(img_path)
# OCRの学習データ形式
formatted.append({
"messages": [
{
"role": "user",
"content": [
{"type": "image", "image": img_path},
{"type": "text", "text": "この文書の内容を正確に読み取ってください。"},
]
},
{
"role": "assistant",
"content": example["ground_truth"],
}
]
})
with open("ocr_data/train.jsonl", "w") as f:
for item in formatted:
f.write(json.dumps(item, ensure_ascii=False) + "\n")
print(f"Saved {len(formatted)} OCR training examples")
自分のデータを用意する場合: 文書画像をスキャンまたはスクリーンショットで撮影し、対応する正解テキストを手動で書き起こします。最初は50〜100ペアから始めて、精度を見ながらデータを追加していくのが効率的です。完璧なデータセットを最初から作ろうとしないこと。
学習スクリプト
構造はLv.4のVLMとほぼ同じです。モデル名が変わるだけ。
# train_ocr.py
from unsloth import FastVisionModel
from trl import SFTTrainer
from transformers import TrainingArguments
from datasets import Dataset
import json
# --- 1. DeepSeek-OCR 2の読み込み ---
model, tokenizer = FastVisionModel.from_pretrained(
model_name="unsloth/DeepSeek-OCR-2",
max_seq_length=4096, # OCRは長い出力になりやすいので大きめ
load_in_4bit=True,
)
# --- 2. LoRAの設定 ---
model = FastVisionModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
finetune_vision_layers=True,
finetune_language_layers=True,
finetune_attention_modules=True,
finetune_mlp_modules=True,
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
)
# --- 3. データの読み込み ---
with open("ocr_data/train.jsonl") as f:
data = [json.loads(line) for line in f]
dataset = Dataset.from_list(data)
# --- 4. 学習 ---
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
num_train_epochs=3, # OCRは少データなのでエポック数を増やす
learning_rate=2e-4,
fp16=True,
logging_steps=5,
output_dir="ocr_outputs",
remove_unused_columns=False,
),
)
print("Starting OCR training...")
trainer.train()
# --- 5. 保存 ---
model.save_pretrained("deepseek-ocr2-lora")
tokenizer.save_pretrained("deepseek-ocr2-lora")
print("Done! OCR adapter saved.")
Lv.4(VLM)との違い:
- モデルが
Qwen2.5-VL-7B→DeepSeek-OCR-2に変わった -
max_seq_length=4096— OCRは文書全体を出力するので長めに設定 -
num_train_epochs=3— データ数が少ないのでエポック数を増やして繰り返し学習
それ以外の構造はまったく同じです。LoRAの仕組みが同じなので、モデルの種類が変わってもスクリプトの骨格は変わりません。
学習の実行
python3 train_ocr.py
🦥 Unsloth: Loading DeepSeek-OCR-2 with 4bit quantization
Trainable parameters: 38,715,392 / 3,412,847,616 (1.13%)
Starting OCR training...
...
Training completed in 12 minutes 15 seconds
Done! OCR adapter saved.
OCR精度のテスト
# test_ocr.py
from unsloth import FastVisionModel
from PIL import Image
model, tokenizer = FastVisionModel.from_pretrained(
model_name="deepseek-ocr2-lora",
max_seq_length=4096,
load_in_4bit=True,
)
FastVisionModel.for_inference(model)
# テスト文書画像
image = Image.open("test_document.jpg")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "この文書の内容を正確に読み取ってください。"},
]
}
]
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True,
return_tensors="pt"
).to("cuda")
outputs = model.generate(input_ids=inputs, images=[image], max_new_tokens=2048)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
ファインチューニング前後で、特にドメイン固有の文書(論文の表、実験ノート等)での精度改善が期待できます。DeepSeek-OCR 2の公式レポートでは、ドメイン特化のファインチューニングでCER(文字誤り率)が57〜86%改善したとされています。
Lv.5はここまでです。LLM、VLM、OCR — 3種類のモデルをすべてLoRAでファインチューニングしました。次のLv.6では、これらのモデルを実際に使える形にして配布する方法を学びます。
Lv.6 — マージ・量子化・デプロイ
ファインチューニングで作ったLoRAアダプタを、誰でも使える形にして研究室で共有するのがこのレベルのゴールです。
全体の流れ
ファインチューニングしたモデルを配布するまでの流れは以下の通りです。
LoRAアダプタ + ベースモデル
↓ ① マージ(合体)
マージ済みモデル(フル精度)
↓ ② 量子化(圧縮)
GGUFファイル(軽量)
↓ ③ デプロイ
Ollama で誰でも使える
順番にやっていきましょう。ここではLv.3で作ったテキストLLM(Qwen2.5-7B + 日本語LoRA)を例にします。
① LoRAアダプタのマージ
LoRAアダプタは「本体+追加パーツ」の状態です。これを1つのモデルに合体(マージ)させます。
# merge_model.py
from unsloth import FastLanguageModel
# アダプタ付きモデルを読み込み
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="qwen25-7b-ja-lora",
max_seq_length=2048,
load_in_4bit=False, # マージ時はフル精度で読み込む
)
# マージして保存
model.save_pretrained_merged(
"qwen25-7b-ja-merged",
tokenizer,
save_method="merged_16bit", # 16bit精度で保存
)
print("Merged model saved!")
python3 merge_model.py
なぜマージが必要? LoRAアダプタ単体では動きません。ベースモデルと組み合わせて初めて使えます。マージすると、アダプタの変更がベースモデルに統合されて、単体で動く1つのモデルになります。配布するときはマージ済みの方が圧倒的に楽です。
② GGUF形式に変換・量子化
マージしたモデルをGGUF形式に変換します。GGUFは、llama.cppやOllamaが読めるファイル形式です。
Unslothには、マージとGGUF変換を一発でやる機能があります。
# export_gguf.py
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="qwen25-7b-ja-lora",
max_seq_length=2048,
load_in_4bit=False,
)
# GGUF形式で保存(量子化も同時に行う)
model.save_pretrained_gguf(
"qwen25-7b-ja-gguf",
tokenizer,
quantization_method="q4_k_m", # 量子化方式
)
print("GGUF export complete!")
python3 export_gguf.py
量子化方式の選び方:
| 方式 | サイズ(7Bモデル) | 品質 | 用途 |
|---|---|---|---|
q8_0 |
約7.5GB | 高い | 品質重視 |
q5_k_m |
約5GB | 良い | バランス型 |
q4_k_m |
約4GB | 十分 | おすすめ |
q3_k_m |
約3GB | やや劣化 | メモリ制約が厳しいとき |
迷ったら q4_k_m を選んでください。サイズと品質のバランスが最も良い方式です。
変換が終わると、qwen25-7b-ja-gguf/ ディレクトリにGGUFファイルが生成されます。
ls -lh qwen25-7b-ja-gguf/
-rw-r--r-- 1 user user 4.1G ... qwen25-7b-ja-Q4_K_M.gguf
約4GBの単一ファイルになりました。元のモデル(16bitでマージすると約14GB)から大幅に圧縮されています。
③ Ollamaにデプロイ
GGUFファイルをOllamaに登録して、誰でも使えるようにしましょう。
まず、Ollamaの設定ファイル(Modelfile)を作ります。
# Modelfile
FROM ./qwen25-7b-ja-gguf/qwen25-7b-ja-Q4_K_M.gguf
TEMPLATE """{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
SYSTEM "あなたは親切で正確な日本語アシスタントです。"
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER stop "<|im_end|>"
Ollamaにモデルを登録します。
ollama create qwen25-7b-ja -f Modelfile
transferring model data
creating model layer
writing manifest
success
使ってみよう
ollama run qwen25-7b-ja
>>> こんにちは!量子コンピュータについて教えてください。
量子コンピュータは、量子力学の原理を利用して計算を行うコンピュータです。
従来のコンピュータが0と1のビットを使うのに対し、量子コンピュータは
量子ビット(qubit)を使い、0と1の重ね合わせ状態を利用できます...
自分でファインチューニングしたモデルが、Ollamaで動いています。
研究室での共有方法
GGUFファイルとModelfileを研究室メンバーに渡すだけです。
# 共有するファイル(合計約4GB)
qwen25-7b-ja-Q4_K_M.gguf # モデル本体
Modelfile # Ollama設定
# 受け取った人がやること
ollama create qwen25-7b-ja -f Modelfile
ollama run qwen25-7b-ja
USBメモリやネットワークドライブ経由で渡せば、インターネット不要で使えます。
MacでもGPUサーバーでも同じGGUFが動きます。 Ollamaはクロスプラットフォーム対応なので、GPUサーバーで作ったモデルをMacに持ってきて動かすこともできます。MacのApple SiliconのユニファイドメモリでQ4_K_Mの7Bモデルなら、メモリ8GBのMacでも動きます。
まとめ — ファインチューニングでできるようになったこと
この記事を通して、以下のことができるようになりました。
- Lv.1: ファインチューニングの概念(フル/LoRA/QLoRA)を理解した
- Lv.2: MacのApple Silicon上でmlx-lmを使いLoRAファインチューニングを体験した
- Lv.3: GPUサーバーでUnslothを使い、7Bモデルを数分で学習した
- Lv.4: VLM(Qwen2.5-VL)をファインチューニングし、画像+テキストのタスクに対応した
- Lv.5: OCRモデル(DeepSeek-OCR 2)をファインチューニングし、文書認識を特化させた
- Lv.6: LoRAマージ→GGUF量子化→Ollamaデプロイの流れで、モデルを研究室に共有した
Lv.1の「ファインチューニングって何?」から始めて、Lv.6では自分で作ったモデルをOllamaに載せて配布するところまで来ました。AIを使う側から、AIを作る側に一歩踏み出しました。
次に学ぶとよいこと
ファインチューニングの基本はこの記事でカバーしました。さらにステップアップしたい人は、以下のトピックに挑戦してみてください。
- DPO / RLHF — 人間のフィードバックを使ってモデルの出力品質を上げる手法。ファインチューニングの次のステップです。
- データセット設計 — 「どんなデータをどれだけ集めるか」がファインチューニングの品質を決めます。データの量より質が重要。
- 評価手法 — ファインチューニングの効果を定量的に測る方法。ロスの値だけでなく、実際のタスクでの精度(F1スコア、BLEU等)を計測しましょう。
- マルチGPU学習 — DeepSpeedやFSDPを使って複数GPUで並列学習。70B以上の大規模モデルのファインチューニングに必要です。
- 継続事前学習 — LoRAではなく、大量のドメインデータで事前学習を追加する手法。LoRAでカバーしきれない深い知識を入れたいときに。
シリーズの他の記事
「はじめての〇〇」シリーズでは、研究室の新入生が最初につまずきやすいツールを、ゼロから丁寧に解説しています。
- はじめてのClaude Code:インストールから最強環境構築まで
- はじめてのCodex:インストールからCloud Tasksまで
- はじめてのDocker:Macで覚えて研究室サーバーでも使えるようになる
- はじめてのバイブコーディング:PC本体設定から環境構築まで
シリーズは今後も追加予定です。お楽しみに!