背景
- Google Analytics の データを利用し、いろんな切り口でraw データを解析したいですが、Google Analytics無料版だとraw data (集計されていないの生データ)の取得ができません。参考記事
- 直接公開されているGoogle Analytics APIを利用し、raw データの取得ができましたので、ノーハウをこの記事に書きました。
- また、解析するため、取得したrawデータをBigQueryまでのエクスポートの方法も書きました。
プロセス・事前用意
- Google Analytics Reporting APIを有効にする
- Google Cloud Platform (GCP)にて、サービスアカウントを作成し、秘密鍵をダウンロードする
- Google Analytics 管理画面で、そのサービスアカウントに権限を付与する
- 開発し、Python script を書く
- 必要なライブラリーをインストールする
- Google Analytics APIを利用し、データをダウンロードする
- Google Cloud Storageへアップロードする
- Google BigQueryにエクスポートし、テーブルを作成する
詳細
1. Analytics Reporting APIを有効にする
-
Google API Consoleにて、
広告のカテゴリに、「Google Analytics Reporting API」を有効にします。 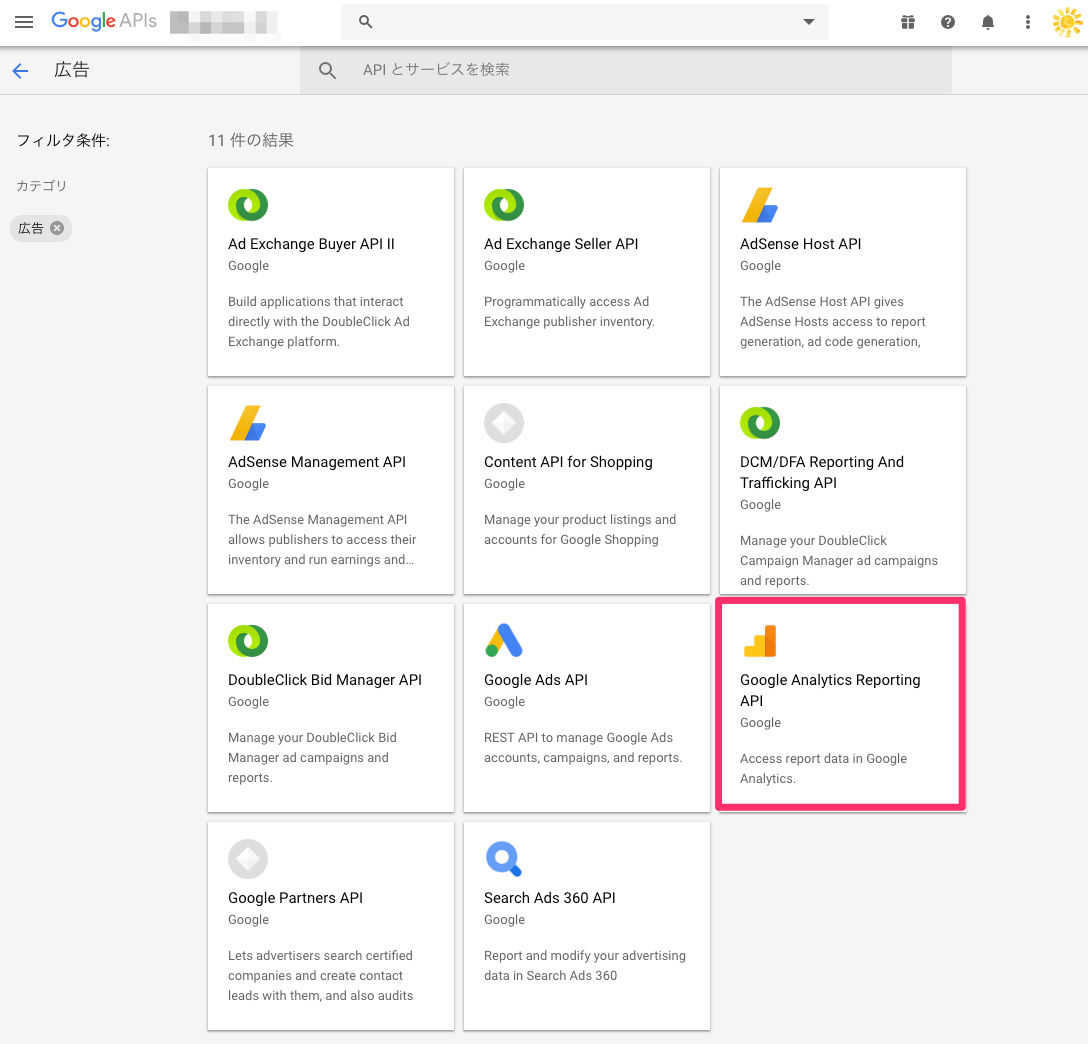
2. サービスアカウントを作成し、秘密鍵をダウンロード
- 公式サイトに記載されている「認証情報を作成する」を参考しながら、サービスアカウントを作成します。
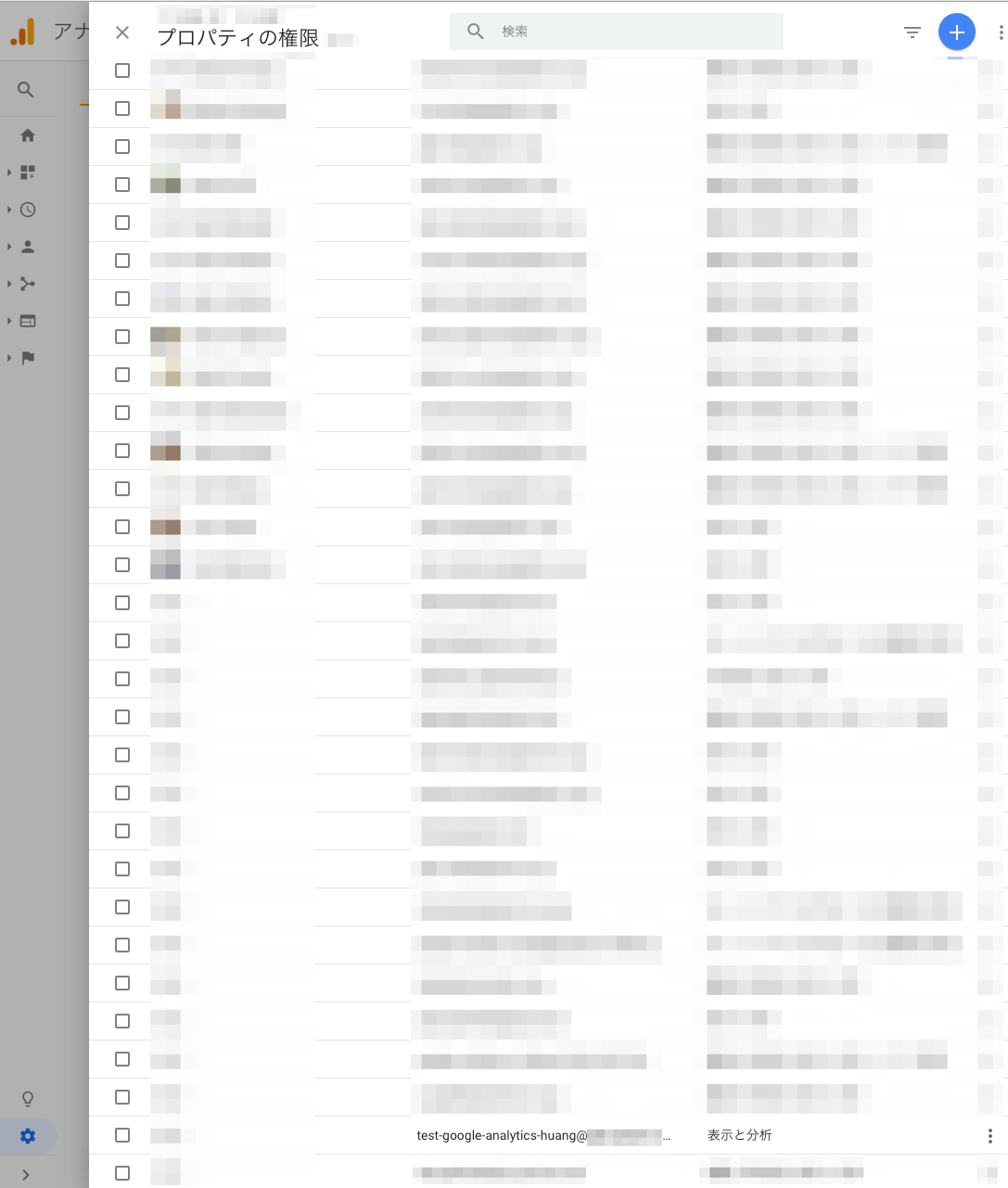
3. サービスアカウントに権限を付与
- Google Analytics 管理画面 → 管理 → アカウント → ユーザー管理にて、先ほど作ったサービスアカウントに
表示と分析の権限を付与します。
4. 開発 (Python)
必要なライブラリーをインストールする
pip install --upgrade google-api-python-client
pip install oauth2client
pip install google-cloud-storage
pip install google-cloud-bigquery
Google Analytics APIを利用し、データをダウンロード
公式サイトにあるサンプルを活用しながら、python scriptを書きます。
まず、必要なライブラリーをインポートし、認証情報を埋めます。
from apiclient.discovery import build
from oauth2client.service_account import ServiceAccountCredentials
import pandas as pd
import numpy as np
import copy
from datetime import datetime, date, timedelta
import pytz
import os
from google.cloud import storage, bigquery
SCOPES = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = '<path/to/client_secrets.json>' ## ここ入れ替える
VIEW_ID = '<GA管理画面にあるビューのID>' ## ここ入れ替える
ここに書いているscriptは、前日分のGoogle Analyticsのデータを取得しますので、日付の変数も定義します。
# 日付を指定用 (確実に日本時間)
today = datetime.now(pytz.timezone('Asia/Tokyo'))
yesterday = today - timedelta(days=1)
# 日付フォーマットの指定
today = today.strftime("%Y-%m-%d")
yesterday_yymmdd = yesterday.strftime("%Y%m%d")
yesterday = yesterday.strftime("%Y-%m-%d")
Google Analytics API取得に関連するパラメーターの設定もします。
例えば、デフォルトが一回につき1000行しかできないですが、最大1万行に設定します。
データの期間も設定できますので、ここでは「昨日」に設定します。
# Google Analytics API取得用 parameter initialization
pageSize=10000 # デフォルトが1000行ずつですけど、ここでは一万行ずつ
startDate=yesterday
endDate=yesterday
Google Analytics APIを利用し、データをダウンロード
先ほど定義していた認証情報を使って、Google Analytics APIを通して、初期化します。
def initialize_analyticsreporting():
"""Initializes an Analytics Reporting API V4 service object.
Returns:
An authorized Analytics Reporting API V4 service object.
"""
credentials = ServiceAccountCredentials.from_json_keyfile_name(
KEY_FILE_LOCATION, SCOPES)
# Build the service object.
analytics = build('analyticsreporting', 'v4', credentials=credentials)
return analytics
取得したデータを、二次元のリスト型にする関数を定義します。
def data_write(response, raw_datas=None):
'''
Input:
response: The Analytics Reporting API V4 response.
raw_datas: 2-D List of GA hit data, in which one want to insert new data into.
If not specified, just creating whole new data list from "response" file.
Output:
raw_datas: 2-D List of GA hit data, including the originnal GA data (original raw_datas) and new data that is extracted from "response" file.
column_names: column names of GA hit data, including dimension names and metric names.
nextPageToken: the starting point of the next page.
'''
if raw_datas is None:
raw_datas = []
for report in response.get('reports', []):
columnHeader = report.get('columnHeader', {})
dimensionHeaders = columnHeader.get('dimensions', [])
metricHeaders = columnHeader.get('metricHeader', {}).get('metricHeaderEntries', [])
nextPageToken = report.get('nextPageToken')
for row in report.get('data', {}).get('rows', []):
raw_data = []
dimensions = row.get('dimensions', [])
dateRangeValues = row.get('metrics', [])
for header, dimension in zip(dimensionHeaders, dimensions):
raw_data.append(dimension)
for i, values in enumerate(dateRangeValues):
for metricHeader, value in zip(metricHeaders, values.get('values')):
raw_data.append(value)
raw_datas.append(raw_data)
# カラム名を作成: dimension names & metric names
column_names = copy.deepcopy(dimensionHeaders)
column_names.append(metricHeader.get('name'))
return raw_datas, column_names, nextPageToken
取得したいGoogle AnalyticsにおけるメジャーやディメンションをreportRequestsの中に書きます。
また、ここのsamplingLevelの設定によって、全てのデータを取得するか、サンプリングされたデータを取得するか設定できます。詳細はここのAPI説明:batchGetを参考してください。
def get_report_all_pages(analytics, pageToken=None, pageSize=None, startDate='7daysAgo', endDate='today'):
"""Queries the Analytics Reporting API V4.
Args:
analytics: An authorized Analytics Reporting API V4 service object.
pageToken: indicates the starting point of the next page
pageSize: indicates the number of rows per page
Returns:
The Analytics Reporting API V4 response.
"""
return analytics.reports().batchGet(
body={
'reportRequests': [
{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': startDate, 'endDate': endDate}],
'metrics': [{'expression': 'ga:pageviews'}],
# dimensions: only 9 are allowed
'dimensions': [{'name': 'ga:pagePath'},
{'name': 'ga:previousPagePath'},
{'name': 'ga:dimension1'},
{'name': 'ga:dimension2'},
{'name': 'ga:dimension3'},
{'name': 'ga:dimension4'},
{'name': 'ga:dimension5'},
{'name': 'ga:date'},
{'name': 'ga:minute'}
], ## ここ入れ替える
'pageToken': pageToken,
'pageSize' : pageSize, # Default = 1000行, 最大 100,000 行。 Project: 1 日 50,000 件のリクエスト; ビュー 1 日 10,000 件のリクエスト,
'samplingLevel': 'LARGE' # samplingの設定によって、GA 管理画面との差分が生じるみたい (確認中)
}]
}
).execute()
Google Cloud Storageへアップロードする
ローカルのファイルを、Google Cloud Storageにアップロードする関数を書きます。
def to_gcs(bucket_name, date_string=yesterday):
'''
Input:
bucket_name: gdp_data プロジェクトにおける バケット名
date_string: uploadするデータの該当日付
Output:
file_name_full: バケットにアップロードされたファイルのパス (バケット名を除く)
また、ファイルが指定された場所にアップロードされる
'''
client = storage.Client()
bucket = client.get_bucket(bucket_name)
file_name_full = date_string + '/' + date_string + '.csv'
blob = bucket.blob(file_name_full)
# blob = bucket.blob('バケット内のパス/ファイル名') でも可能
local_file_absolute_path = os.path.abspath('data/' + date_string + '.csv')
blob.upload_from_filename(local_file_absolute_path)
return file_name_full
Google BigQueryへインポートし、テーブルを作成する
Google Cloud Storageのデータを、BigQueryにエクスポートする関数も書きます。
def to_bq(schema, uri, dataset_id, table_name):
'''
INPUT:
schema: 各カラムの該当するschema
uri: GCSのロードするファイルの絶対パス。 ex: gs://abc/def.csv
dataset_id: 入れ込むdataset名
table_name: 作成するテーブル名
OUTPUT:
なし。指定されたファイルがBigQueryのテーブルに入れ込む。
'''
try:
client = bigquery.Client()
dataset_ref = client.dataset(dataset_id)
job_config = bigquery.LoadJobConfig()
job_config.schema = schema
job_config.skip_leading_rows = 1
job_config.write_disposition = 'WRITE_TRUNCATE'
# The source format defaults to CSV, so the line below is optional.
job_config.source_format = bigquery.SourceFormat.CSV
load_job = client.load_table_from_uri(
uri, dataset_ref.table(table_name), job_config=job_config
) # API request
print("Starting job {}".format(load_job.job_id))
load_job.result() # Waits for table load to complete.
print("Job finished.")
destination_table = client.get_table(dataset_ref.table(table_name))
print("Loaded {} rows.".format(destination_table.num_rows))
except:
# BigQuery Import エラーチェック
print('load_job.errors : {}'.format(load_job.errors))
全て巻き込んで、メイン関数を書く
- 取得したデータを、二次元のリスト型にし、pandasを使ってDataFrame型に変換します。
- その後、csvフォーマットでoutputして、GCSにあげてBigQueryにエクスポートします。
- 【注意】 ここで指定しているGoogle Analyticsの関数(指標のディメンションとメジャー)は、自分の好みで設定してください。それに応じて、BigQueryの
schemaと先ほど述べていたreportRequestsの部分は、適宜で変更してください。
def main():
# toGCS/toBQ の 認証
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]=KEY_FILE_LOCATION
# to GCS用
bucket_name = '<GCS側、アップロードする先のバケット名>' ## ここ入れ替える
# to BigQuery用
dataset_id = '<BigQuery側、アップロードする先のデータセット名>' ## ここ入れ替える
table_name = 'ga_api_' + yesterday_yymmdd ## ここ入れ替える
schema = [
bigquery.SchemaField("pagePath", "STRING"),
bigquery.SchemaField("previousPagePath", "STRING"),
bigquery.SchemaField("cusd1", "STRING"),
bigquery.SchemaField("cusd2", "INT64"),
bigquery.SchemaField("cusd3", "STRING"),
bigquery.SchemaField("cusd4", "STRING"),
bigquery.SchemaField("cusd5", "TIMESTAMP"),
bigquery.SchemaField("date", "STRING"),
bigquery.SchemaField("minute", "INT64"),
bigquery.SchemaField("pageviews", "INT64")
] ## ここ入れ替える
# 1回目request (initialization)
analytics = initialize_analyticsreporting()
response = get_report_all_pages(analytics, pageSize=pageSize, startDate=startDate, endDate=endDate)
data_output = data_write(response)
# 2回目request から、繰り返し処理
# nextPageTokenがあれば、データをattachする
i = 2
while data_output[2] is not None:
print('これから {} 回目request。 取得済のデータ件数は {} 件です。 nextPageToken は {} です。'.format(i, len(data_output[0]), int(data_output[2]) + 1))
response = get_report_all_pages(analytics, pageToken=data_output[2], pageSize=pageSize, startDate=startDate, endDate=endDate)
data_output = data_write(response, raw_datas=data_output[0])
i += 1
# List to DataFrame
ga_data = pd.DataFrame(data=data_output[0], columns=data_output[1])
print('取得したデータ行数は{}行です。'.format(ga_data.shape[0]))
# DataFrame to csv
filename = 'data/' + yesterday + '.csv'
ga_data.to_csv(filename, index=False)
print('データの取得&csv化完了しました。ファイルは {} です ^0^ '.format(filename))
# to_gcs
print('前日のファイルをGCSにimport中...')
file_name_full = to_gcs(bucket_name, date_string=yesterday)
# to BQ
print('GCSのファイルをBigQueryにimport中...')
uri = 'gs://' + bucket_name + '/' + file_name_full
to_bq(schema, uri, dataset_id, table_name)
if __name__ == '__main__':
main()
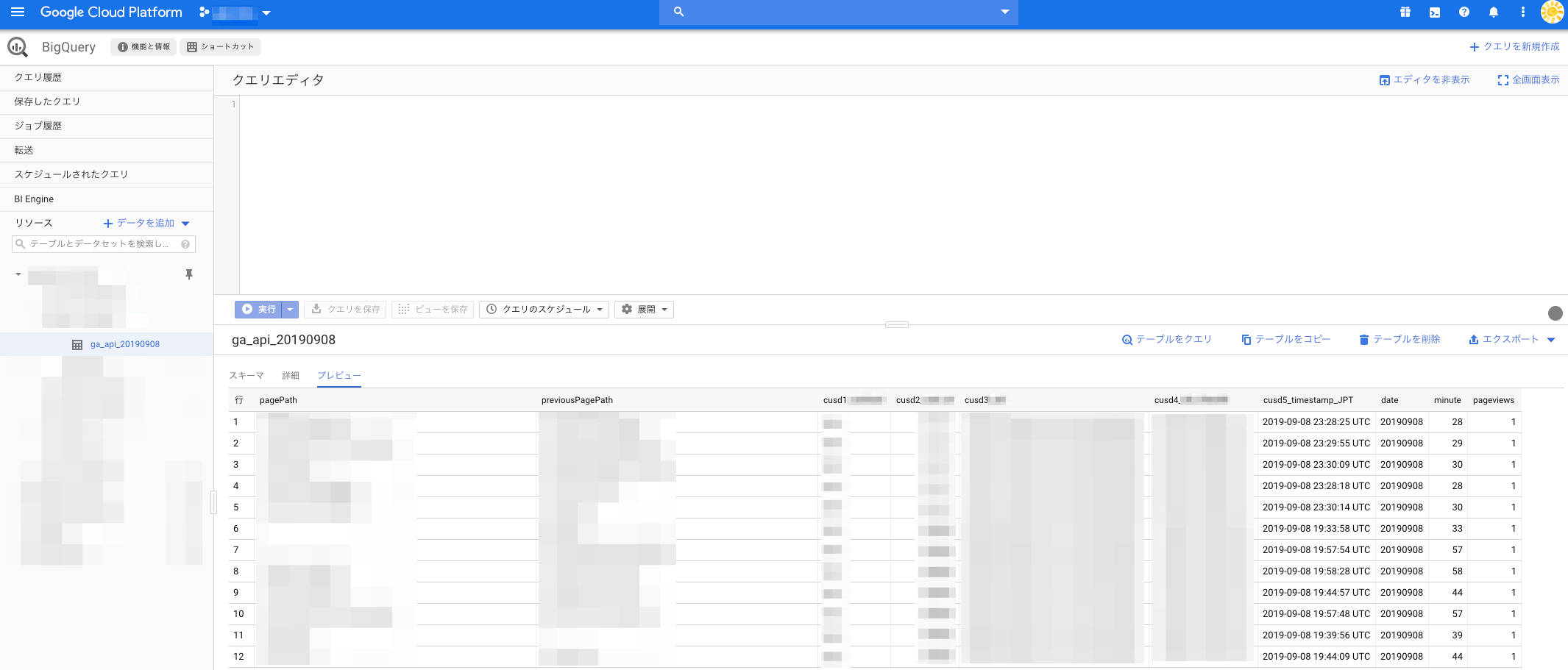
rawデータはこんな感じになります!
ちゃんとBigQueryに入っていて、一番細かい粒度でGoogle Analyticsのデータが解析できますね!
まとめ
- この記事を通じて、Google Analytics APIを利用し、rawデータの取得からBigQueryまでのエクスポートというプロセスをpython scriptとして説明してきました。
- Google Analyticsの無料版でもrawデータが取得できるので、細かいデータ解析をガンガンやっていきましょう!