はじめに
関連リンク一覧:
・大元ネタ
東京の夏が「昔より断然暑い」決定的な裏づけ-過去140年の日別平均気温をビジュアル化 - 東洋経済ONLINE
・元記事
@haltaro さん
[あまりに暑いので,140年分の気温をProphetで分析した] (https://qiita.com/haltaro/items/9c68f0914677bb3a629c)
・時系列分析とProphetがより詳細に述べられているページ
@s_katagiri さん
あまりに暑いので、ごく簡単に Prophet の分析の質を向上させる方法を書いた
@s_katagiri さんによる更に詳細な時系列分析のお話(外部サイト)
[R] fb Prophet の解剖で学ぶベイズ時系列モデリング - ill-identified diary
・Prophet ホームページ
Prophet - Forecasting at scale
GitHub
論文 - Forecasting at Scale
リファレンスマニュアル(最終更新:2018.6.15)
・Prophet 説明
@hoxo_m さん
Prophet入門【R編】Facebookの時系列予測ツール - SlideShare
Prophet入門【理論編】Facebookの時系列予測ツール - SlideShare
・気象庁 過去の気象データについて
気象庁HP - 過去の気象データ・ダウンロード
概要
東洋経済ONLINEのニュースに、
東京の夏が「昔より断然暑い」決定的な裏づけ-過去140年の日別平均気温をビジュアル化
というものがありました。
過去140年における、東京の6~9月の平均気温をヒートマップにしたものです。
データ元になっている気象庁のHPにアクセスすると、6-9月以外のデータも取得することができます。また、地域も様々ですね。
先日業務でFacebookのリリースしている時系列分析ライブラリProphetを使う機会があり、この気温データはいいネタになりそうだと思ったのですが...
@haltaro
[あまりに暑いので,140年分の気温をProphetで分析した] (https://qiita.com/haltaro/items/9c68f0914677bb3a629c)
全く同じ内容で、見事に先を越されてしまいました。
一歩及ばなかったようです。
というわけで、一番乗りになれなかったものの、供養の気持ちを込め、@haltaroさんの記事から派生して、ちょっとした補足や考察を加えて記事を書きたいと思います。
環境
- mac OS High Sierra, 10.13.3
- Python, 3.6.3
- Prophet, 0.3
Prophet
Prophetについては、@haltaroさんが説明してくださっているので、詳細は割愛します。
本手法の長所として、元論文では「スケールすること」が推されています。
具体的には以下の2点です。
- 人的にスケール(時系列分析の知識がない人も分析を行える)
- データ量的にスケール(計算時間が短い)
また、時系列分析の知識がなくても扱える、という観点で言うと、分析対象の分野に対する経験的な知識(ドメイン知識)を持っているが、時系列分析の知識は持っていない人も分析が行えるので、ドメイン知識を反映したモデルにできる、というのも推しポイントのようです。
データ
こちらも、@haltaroさんが説明してくださっているので、詳細は割愛します。
ちょっと悲しくなってきた
データは1872年からあるので、私の場合は1872-1881, 1882-1891と10年区切りでダウンロードしました。気温は、平均気温(average)、最高気温(max)、最低気温(min)です。
また、データには品質情報(quality)と均質番号(homogeneity)が付与されています。
csvファイルの数も限られていたので、私はcsvファイルを開き、直接上記のようなカラム名に修正してから読み込みましたが、ファイル数が膨大になったら現実的ではないですよね。その点、@haltaroさんの処理方法は参考になりました。
import pandas as pd
import glob
df = pd.DataFrame(index=[], columns=['ds', 'average', 'average_quality', 'average_homogeneity',
'max', 'max_quality', 'max_homogeneity',
'min', 'min_quality', 'min_homogeneity'])
for path in sorted(glob.glob('./data/*.csv')):
temp_df = pd.read_csv(path)
df = pd.concat([df, temp_df])
気象庁HP ダウンロードファイルの形式にも説明がありますが、品質情報とは観測データに欠損があるかを示しています。
また、均質番号が同じ区間は観測条件が同じであることを表します。
これらを集計しました。かなりお粗末なコードですが...
# aggregate quality
grouped = df.groupby('average_quality')
print(grouped.size())
grouped = df.groupby('max_quality')
print(grouped.size())
grouped = df.groupby('min_quality')
print(grouped.size())
# aggregate homogeneity
grouped = df.groupby('average_homogeneity')
print(grouped.size())
grouped = df.groupby('max_homogeneity')
print(grouped.size())
grouped = df.groupby('min_homogeneity')
print(grouped.size())
'''
# output
average_quality
1 16
5 3
8 52254
dtype: int64
max_quality
1 12
5 3
8 52258
dtype: int64
min_quality
1 15
8 52258
dtype: int64
average_homogeneity
1 50944
2 1329
dtype: int64
max_homogeneity
1 50944
2 1329
dtype: int64
min_homogeneity
1 50944
2 1329
dtype: int64
'''
品質情報は、今回は1,5,8の3種類があるようです。上記HPを参照すると、8は欠損なしの正常値、5は欠損が20%以下の準正常値、1は欠測にあたります。
実際に、NaNの個数を集計してみると、
# count NaN in each column
print(df.isnull().sum())
'''
# Output
ds 0
average 16
average_quality 0
average_homogeneity 0
max 12
max_quality 0
max_homogeneity 0
min 15
min_quality 0
min_homogeneity 0
dtype: int64
'''
各気温において、品質情報1の個数とNaNの個数が一致していることが確認できます。
品質5は準正常値なのでそのまま使い、1は削除します。
次に、均質情報は1が50944、2が1329とあります。つまり、途中で観測条件が変わったということですね。実際2に変わった時点のデータを見てみると、
print(df[df.average_homogeneity==2].head(10))
'''
# Output
ds average average_quality average_homogeneity max \
1066 2014/12/2 10.8 8 2 14.4
1067 2014/12/3 8.2 8 2 13.6
1068 2014/12/4 8.8 8 2 13.2
1069 2014/12/5 8.3 8 2 13.4
1070 2014/12/6 5.1 8 2 9.8
1071 2014/12/7 6.2 8 2 10.8
1072 2014/12/8 6.6 8 2 11.6
1073 2014/12/9 7.3 8 2 12.4
1074 2014/12/10 7.3 8 2 10.8
1075 2014/12/11 9.6 8 2 16.2
max_quality max_homogeneity min min_quality min_homogeneity
1066 8 2 5.9 8 2
1067 8 2 3.0 8 2
1068 8 2 5.9 8 2
1069 8 2 3.9 8 2
1070 8 2 1.7 8 2
1071 8 2 2.0 8 2
1072 8 2 3.2 8 2
1073 8 2 2.8 8 2
1074 8 2 3.6 8 2
1075 8 2 5.3 8 2
'''
2014/12/2から観測条件が変わったようですね。
上記の気象庁HPにもありますが、観測条件が変わったデータ同士を単純に比較することはできない、とのことです。今回は、一旦これを気にせず連結しました。分析結果がおかしい場合、この点を考慮しなければなりませんね。
モデルのフィッティング
Prophetではトレンド、周期性、イベントの3つの成分によってモデルが表現されます。これらはモデル生成時に様々に調整することができます。詳細はProphetのDocumentationやTutorialを参照ください。
コメントアウトしている部分では、トレンドの変化点がドメイン知識から予想される場合(例えば今回では、観測条件の変化によりトレンドが変化するだろう、と予想できる)、changepointsの引数に日付のリストを与えることで指定できます。
または、n_changepointsでトレンドの変化点の個数を指定することもできます。指定した数が、データの期間中に等間隔で配置されます。実際に各点が変化点となるかどうかは、フィッティングの過程で判断されるようです。
さらに、changepoint_rangeを指定すると、データの先頭から何割の範囲に変化点を配置するか、指定できます。デフォルトでは0.8となっており、例えば140年分のデータがあるとすると、先頭から112年分のデータ範囲に変化点を等間隔に配置することになります。
今回のデータは@haltaroさんが言及しているように、1875/6/10-2018/7/23まで、約143年分のデータがあります。(私のほうがダウンロードが一日遅かったようなので、7/23のデータがありました。)
下記の例では、143年分のデータ全域(changepoint_range=1.0)に対して、年ごとにトレンドが変化するとして、142個の変化点を指定しています。
model = Prophet(weekly_seasonality = False)
'''
# explicitly set trend change points
model = Prophet(weekly_seasonality = False,
changepoints=['2014-12-02'])
# set the number of potential change points uniformly
model = Prophet(weekly_seasonality = False,
n_changepoints=142,
changepoint_range=1.0)
'''
average_df = pd.DataFrame()
average_df['ds'] = df['ds']
average_df['y'] = df['average']
model.fit(average_df)
フィッティングが終わったあとは、この先1年分の日付でデータフレームを生成し、予測を行います。
future = model.make_future_dataframe(periods=365)
forecast = model.predict(future)
fig1 = model.plot(forecast)
fig2 = model.plot_components(forecast)
plt.show()
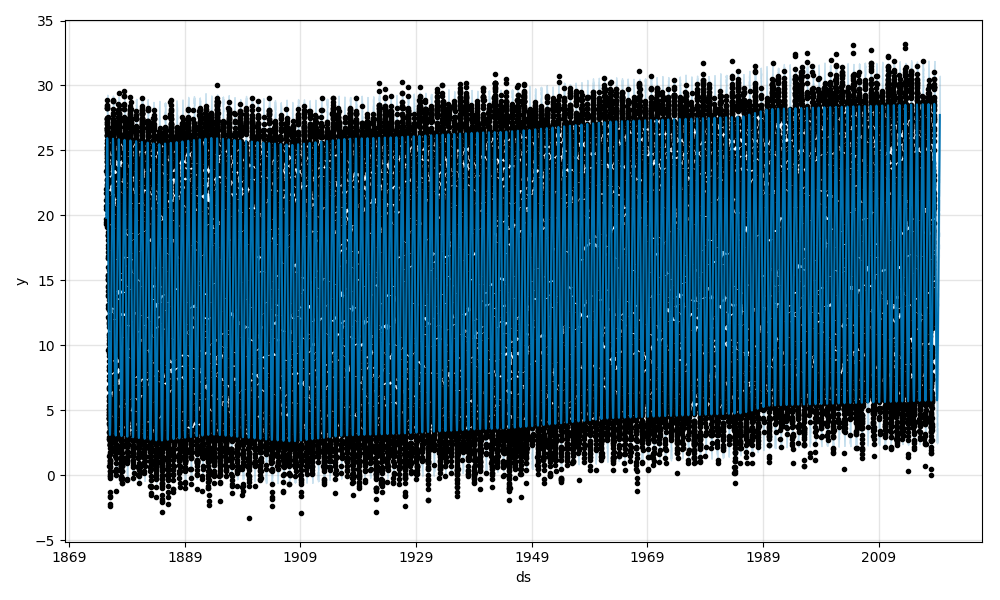
まずは、平均気温の予測結果です。黒点がフィッティングに用いたデータ、青線がフィッティング結果の波形、水色の領域が80%信頼区間です。
1900年以降、緩やかに気温が上昇していますね。
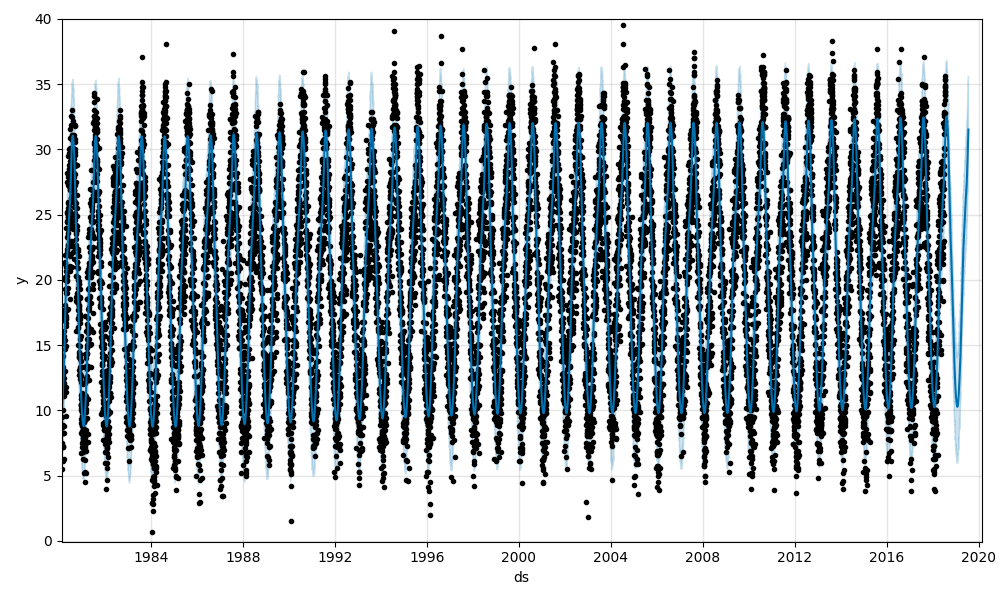
予測部分の拡大です。
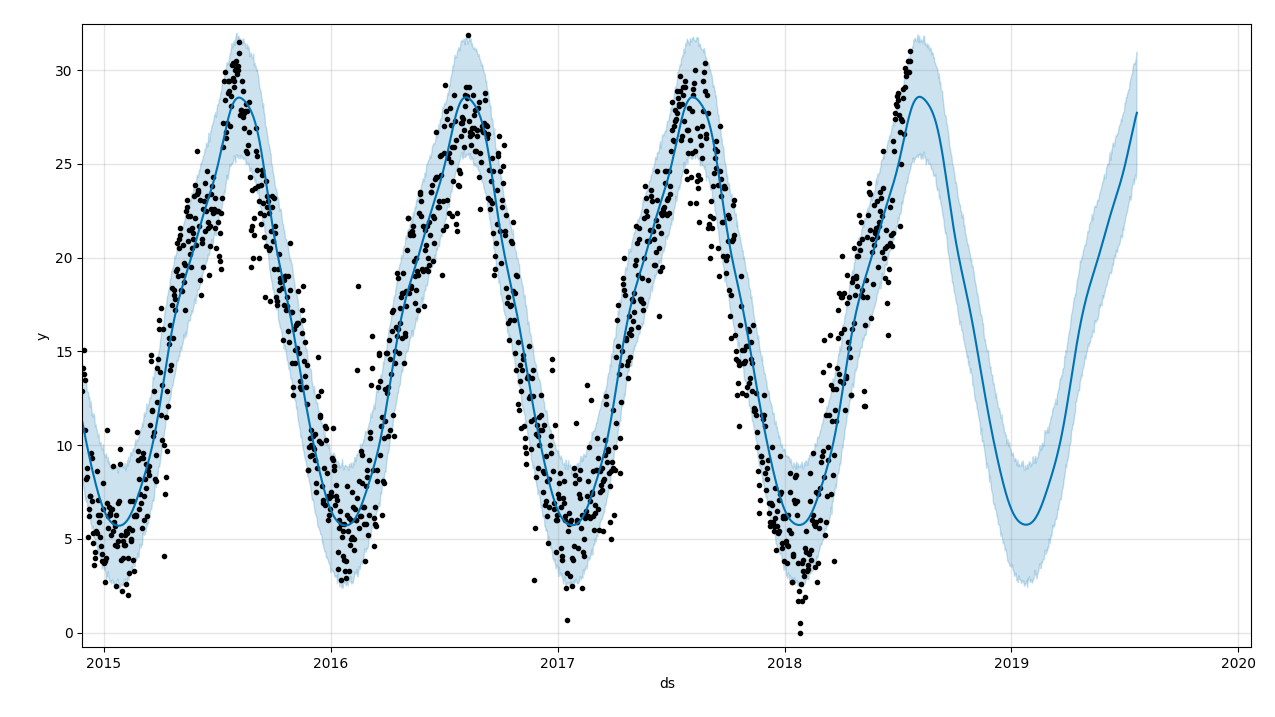
今年の夏は予測よりも高く推移していますね。
2016年に一日だけかなり暑かった日があったようです。
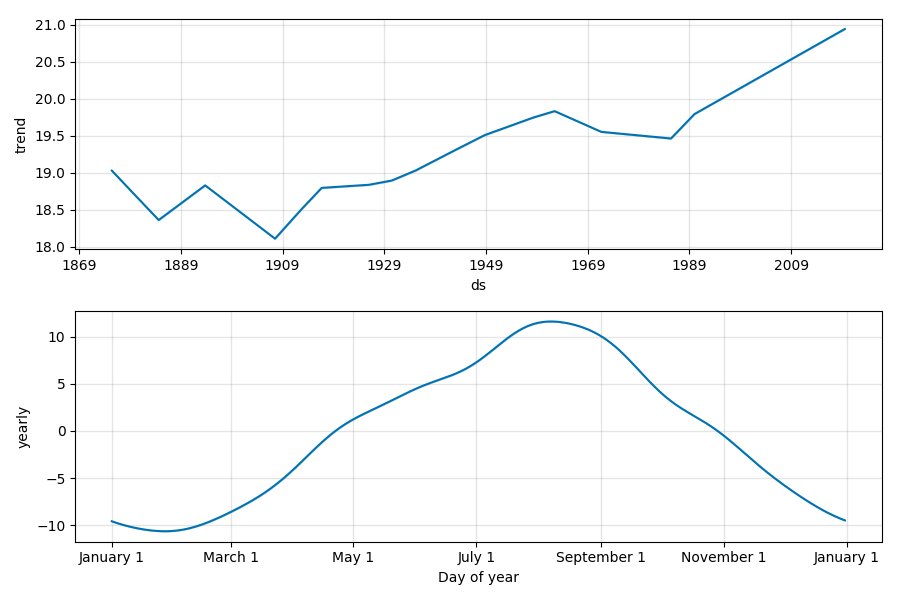
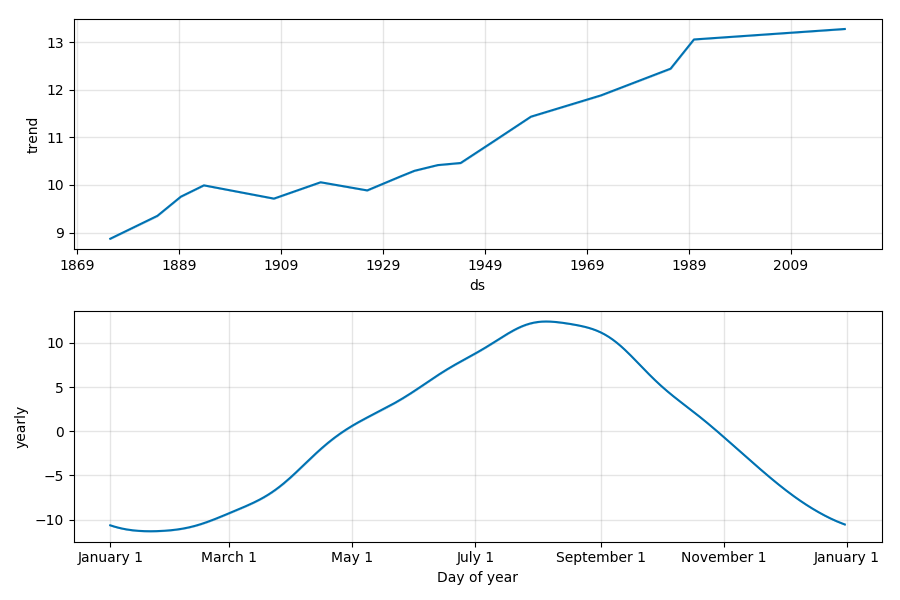
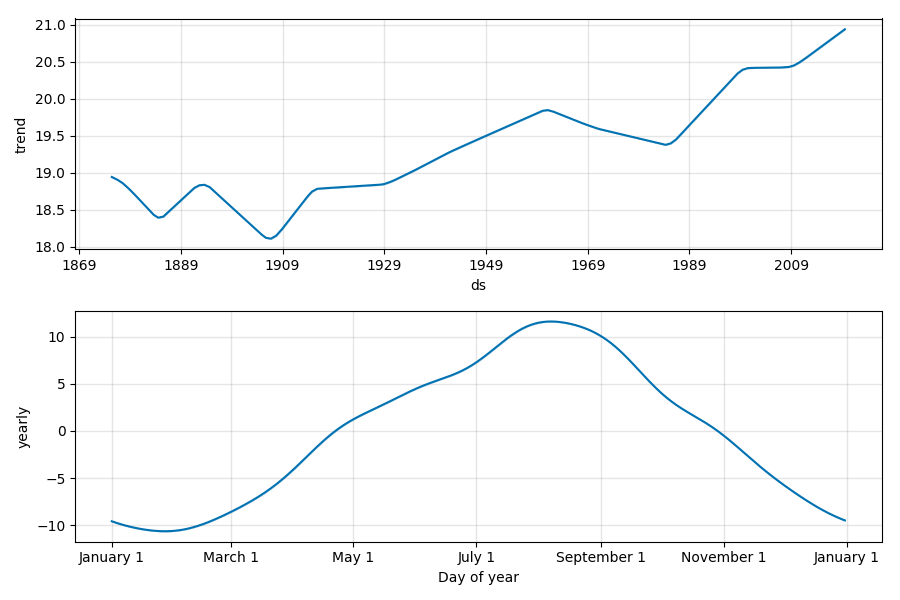
波形の構成要素です。
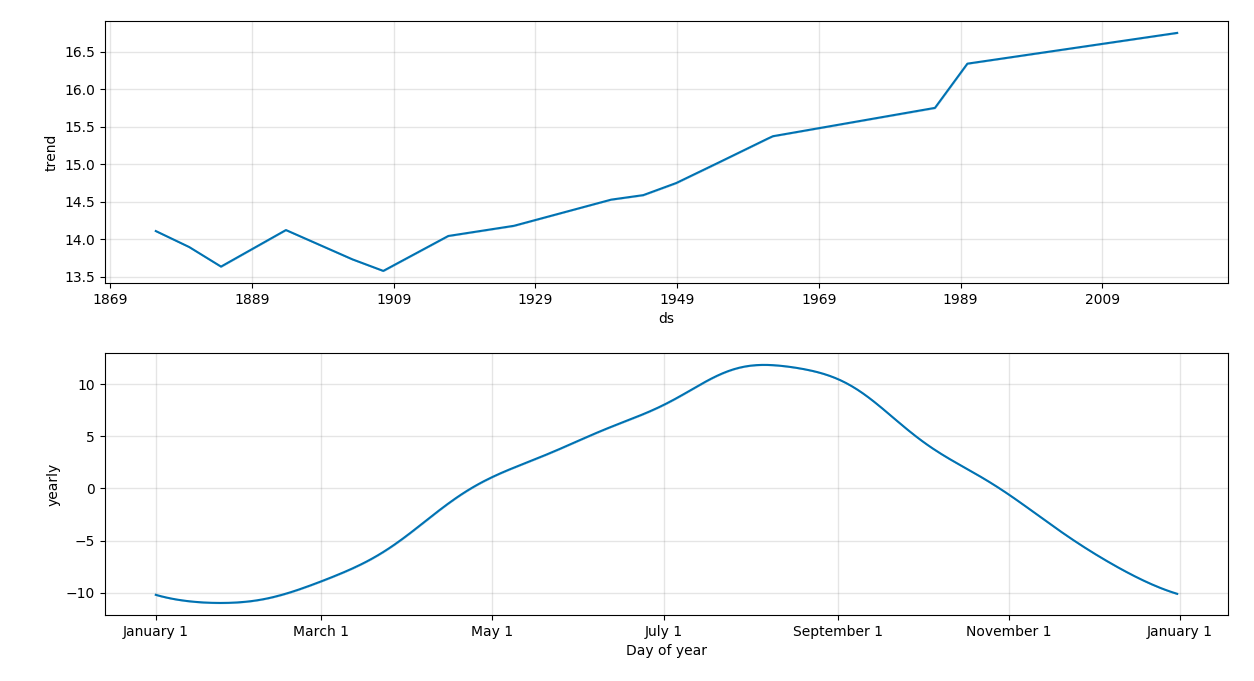
トレンドとしては、やはり1900年から上昇傾向にあります。
1980年代の急激な上昇は何事でしょうか。
年ごとの周期性としては、8月にピークが訪れます。直感とも合致しますね。
次に、最高気温の予測結果です。
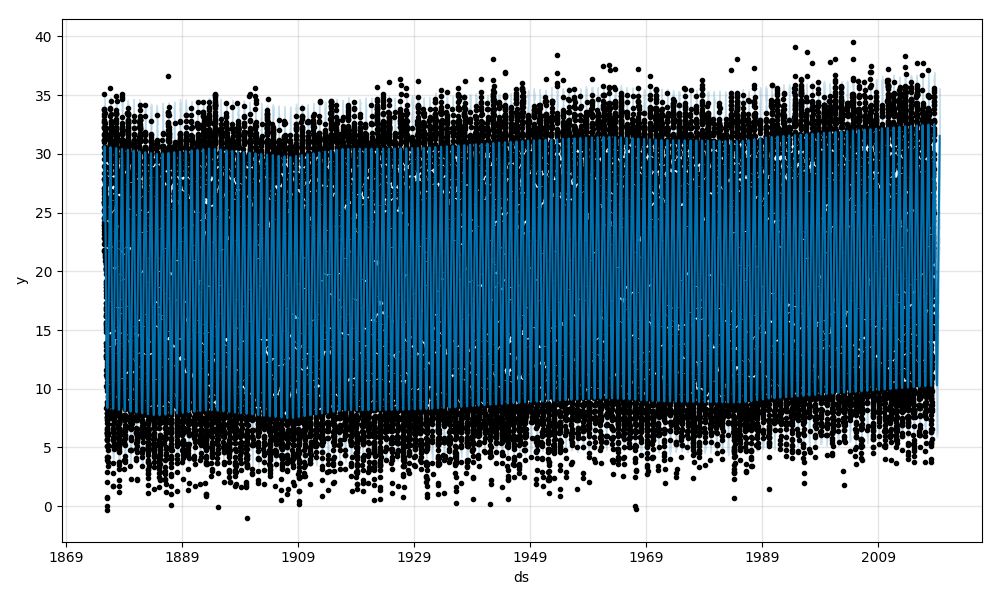
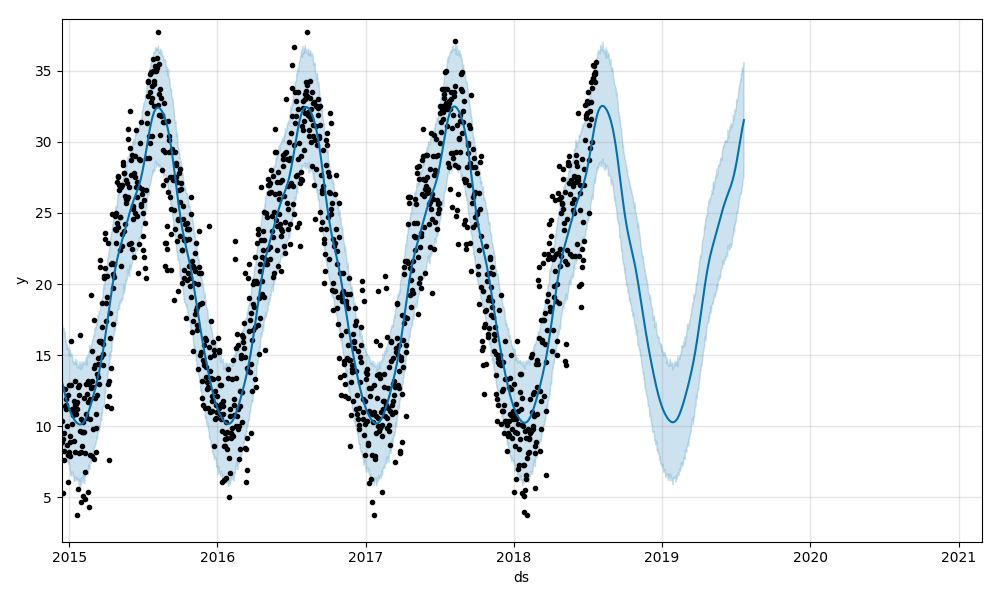
最後に、最低気温の予測結果です。
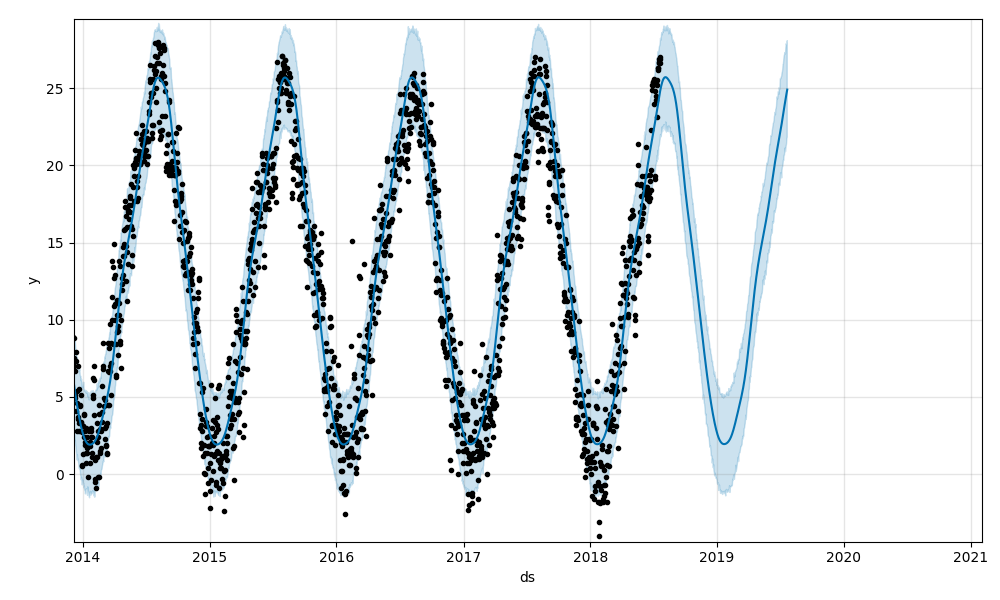
@haltaroさんの記事と、同じ結果だと思います。
トレンド変化点をちょっと改良
さて、各予測結果のトレンド成分を見ると、データの先頭(1875年)からおよそ8割進んだ地点(1989年)以降のトレンドが直線になっているのが気になります。
これはひょっとすると、先程述べたデフォルト設定の影響で、直近のデータにトレンド変化点が設定されていないことが原因かもしれません。
そこで、先程コメントアウトした条件でフィッティングを行ってみます。
# set the number of potential change points uniformly
# trend may change in every year
model = Prophet(weekly_seasonality = False,
n_changepoints=142,
changepoint_range=1.0)
average_df = pd.DataFrame()
average_df['ds'] = df['ds']
average_df['y'] = df['average']
model.fit(average_df)
そして、平均気温のフィッティング、予測結果と成分が以下の図です。
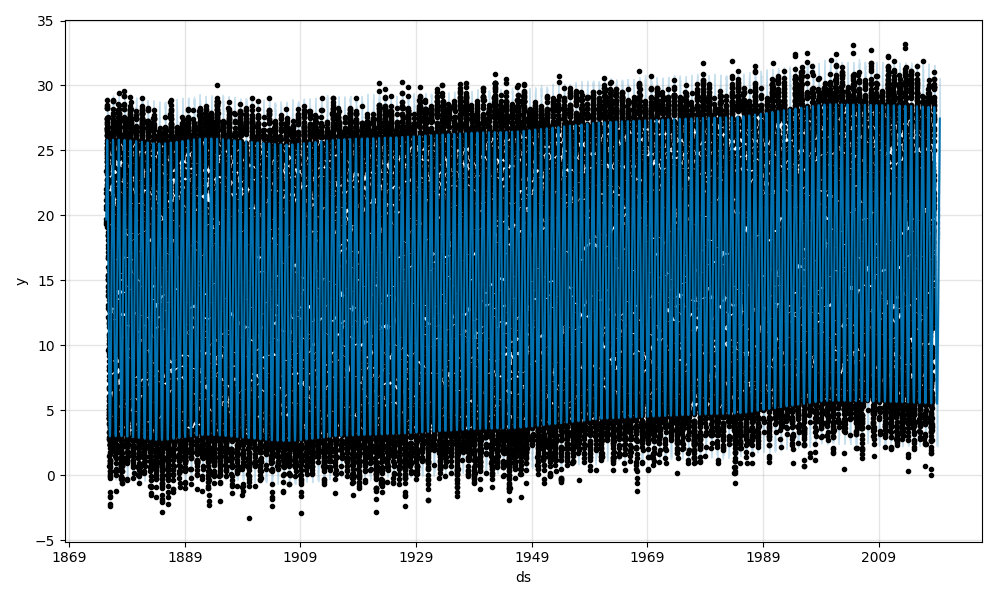
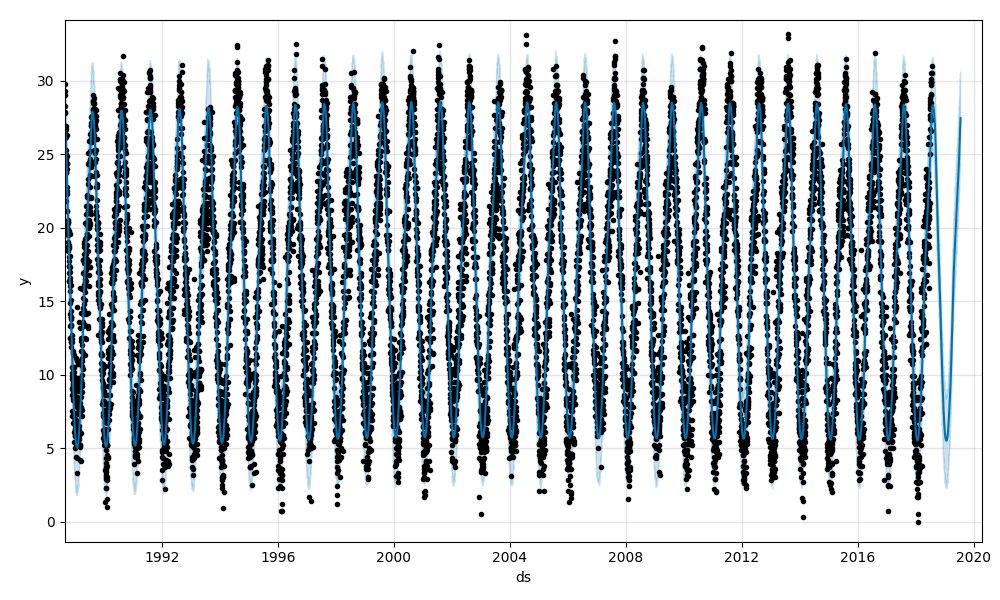
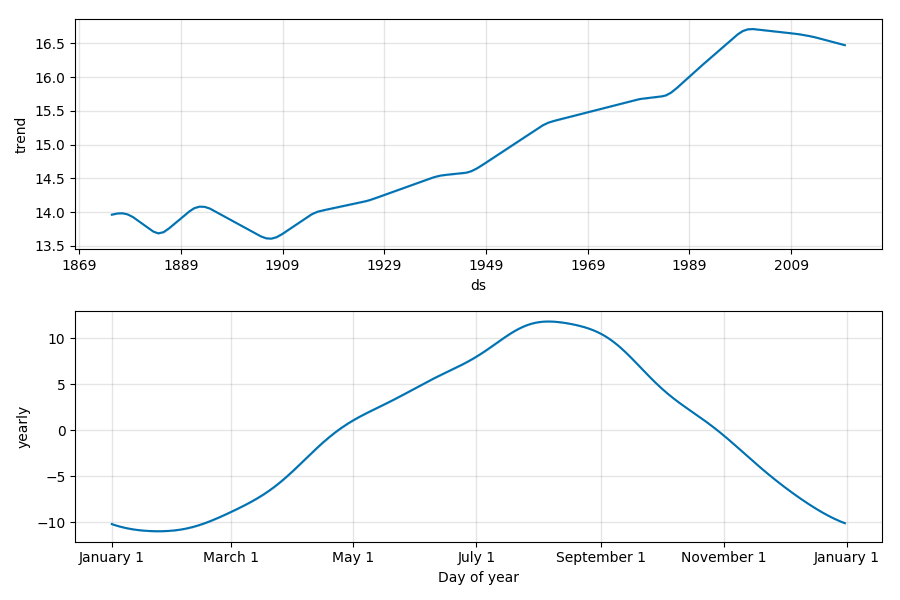
データの全期間について年ごとにトレンド変化が起こりうる設定にしたところ、先ほどと異なる結果が出ました。
2000年以降、平均気温の観点からは少々減少傾向にあるようです。
先述のように、2014/12/2から観測条件が変わっていますが、トレンド変化は観測条件の変化よりも10年以上前に生じているので、今回は観測条件による影響ではないとして話を進めます。
「最近の夏は暑い!」という話をきっかけに分析を始めたのに、平均気温が減少傾向とは、直感に反する気がしてしまいます。現に、東洋経済ONLINEの記事に示されたヒートマップからも、6-9月の平均気温が上昇傾向にあることは明らかです。
夏はますます暑く、冬はますます寒くなっている?
このズレは、今分析したのが平均気温であることがポイントではないかと考えました。
平均気温とは、名の通り、一日の気温の推移について平均を取った結果です。
「最近の夏は暑い!」が正しく、
かつ直近数年の平均気温が減少傾向であるのも正しいとすると、
- 直近数年では最高気温が上昇傾向、最低気温が減少傾向にある
- それらを含む一日の気温の平均を取った結果、全体として減少傾向となった
とは考えられないでしょうか。
これを確認するために、最高気温、最低気温も同様の条件でフィッティングしてみます。
まずは、最高気温の予測結果です。
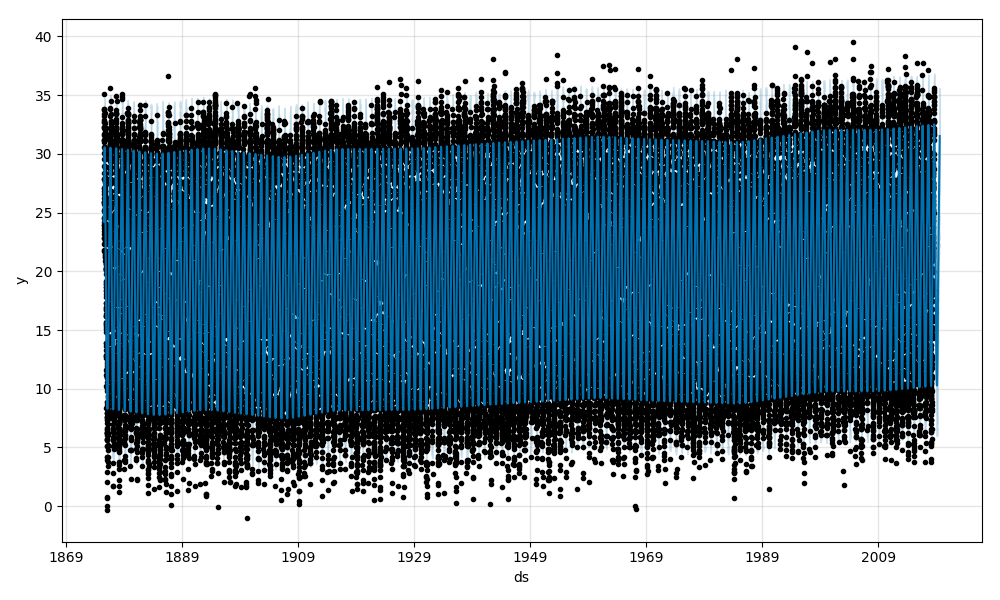
トレンド成分に注目すると、最高気温は1905年ころから1960年ころまで基本的に上昇傾向です。その後、1985年ころまで減少し、その後は急激に上昇しています。
1900年代半ばが減少傾向なのが気になりますね。
直近の数年については、最高気温は間違いなく上昇傾向にあります。
最後に、最低気温のフィッティング結果です。
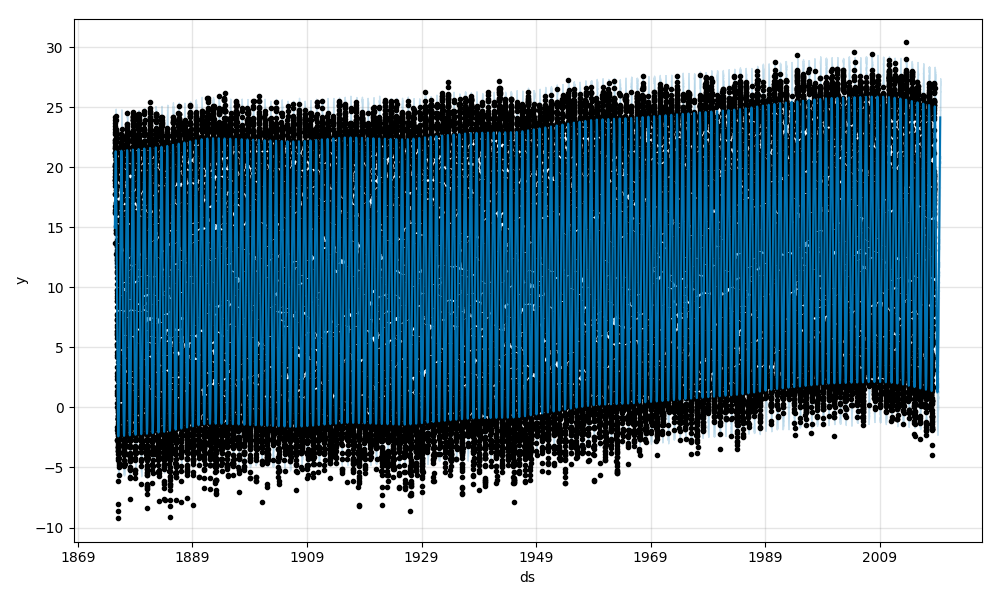
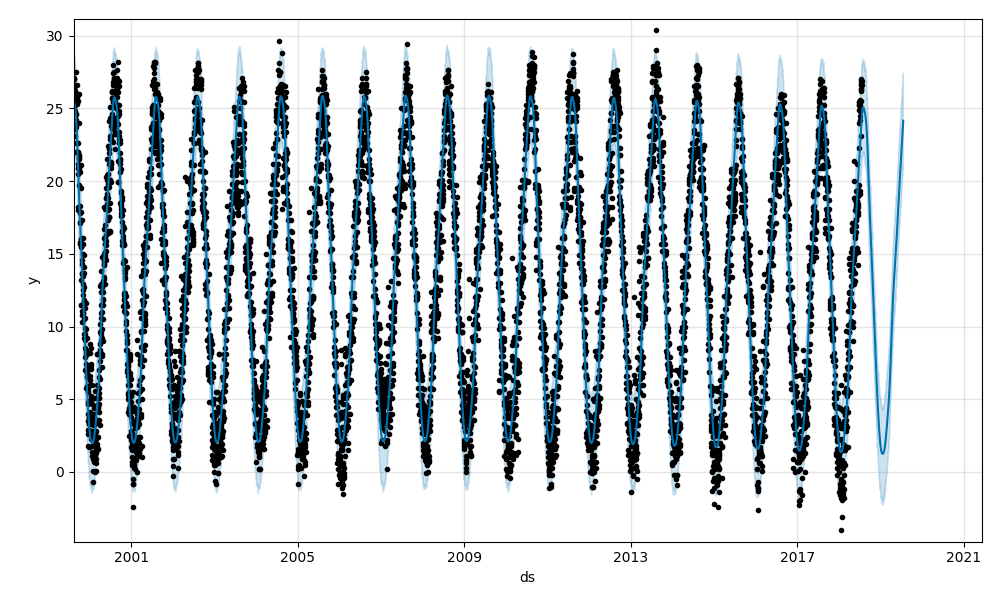
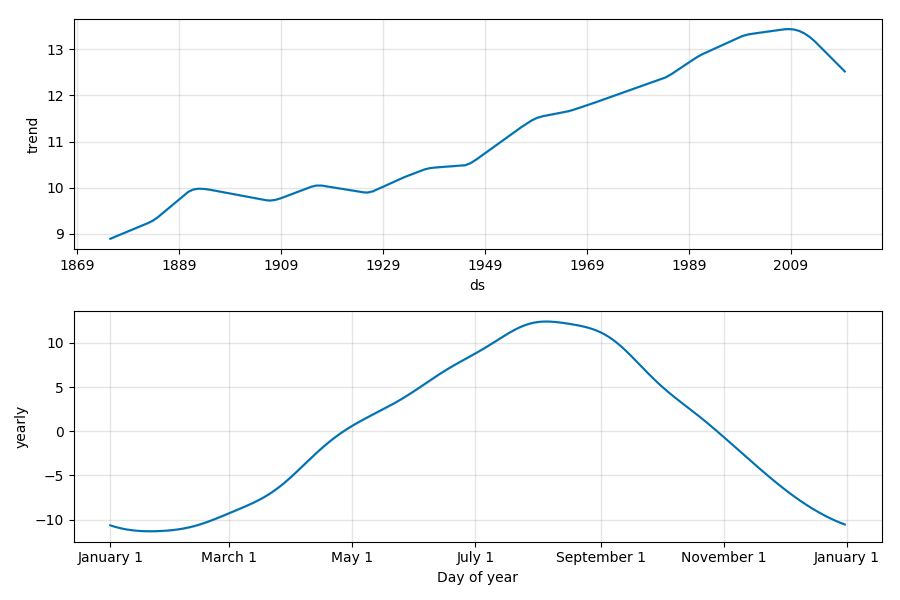
トレンド成分に注目すると、2009年頃を境にガクッと減少しているのが目立ちます。
平均気温が直近で減少傾向にあったのは、やはり
- 直近数年では最高気温が上昇傾向、最低気温が減少傾向にある
- それらを含む一日の気温の平均を取った結果、全体として減少傾向となった
ということではないでしょうか。
夏はますます暑く、冬はますます寒くなっているとは、輪をかけて辛い結果です。
だた、「夏はますます暑くなっていること」を確認するには、1年通しての最高気温を扱うよりは、東洋経済ONLINEの記事にあるように、夏季(6-9月)に注目したほうが妥当かもしれません。
同様に冬の寒さについては、冬季(12-3月)に注目すべきでしょうか。
本記事では1年を通しての気温を用いましたが、夏季や冬季に限定して分析をしてみても面白いかもしれませんね。
本記事は一旦ここまで
もともと、デフォルト設定の予測結果を掘り下げる記事にする予定でしたが、執筆中に思いついた予測を追加で行った結果、長くなってしまいました。
次は、本記事の結果現れた気温の推移を、できる範囲で考察した記事を書こうと思います。
To Be Continued.
少々長いですが、できる限りの考察を書きました。
よろしければこちらもご覧ください!
P.S
理解不足による分析ミスがあるかもしれません。
ささいなことでも疑問に感じたら、勉強になりますので、ぜひツッコミをください。