はじめに
統計開始以来最も暑い夏を生きる皆様,お疲れ様です.あまりに暑くてムシャクシャしたので,気象庁から約140年分(1872年1月1日-2018年7月21日)の東京の気温データを入手し,Prophetで分析しました.
以下は,過去365日分の最高気温の実測値と,2018年7月22日から1ヶ月先までの予測値を表したものです.
また,以下は,最高気温のトレンドと年単位の周期性を表したものです.

分析の結果,平均・最高・最低気温の全てに関して,1920年付近から上昇し続けており,そのトレンドを考慮してもなお,ここ数日は特に暑いことを確認しました.分析に用いたNotebookはこちらです.
注:本記事は,2018年7月22日に個人サイトに投稿した記事を,Qiita向けに再構成したものです.
環境
- macOS Sierra, 10.12.6
- Python, 3.6.6
- Prophet, 0.3
Prophet
特徴
Prophetは,Facebookが開発したオープンソースの時系列解析ライブラリです.Prophetで想定するモデルは:
y(t) = g(t) + s(t) + h(t) + \epsilon(t)
ここで,$y(t)$は時刻$t$における予測値,$g(t)$は時点$t$におけるトレンド成分,$s(t)$は時点$t$における周期成分,$h(t)$は時点$t$における週末などのイレギュラーな成分,そして$\epsilon(t)$は時点$t$における誤差を表します.各成分のパラメータをStanで推定し,モデルを学習します.詳細なモデルは,原論文(Sean J. Taylor and Benjamin Letham, Forecasting at Scale)を参照してください.
Prophetに関する日本語の記事としては,以下のようなものがあります.とても参考になりました.
- Prophet: forecasting at scale - Facebook
- Prophet入門【Python編】Facebookの時系列予測ツール - SlideShare
- Facebookの予測ライブラリProphetを用いたトレンド抽出と変化点検知 - Gunosyデータ分析ブログ
Prophetの大きな特徴の一つは,時系列解析の前提知識がなくても,誰でも簡単に一定水準の分析をできることです.
インストール
今回はPythonからProphetを使います.pipを使う場合は,pip install fbprophetで,condaを使う場合は,conda install -c conda-forge fbprophetでインストールできます.
準備
データの入手
過去の気象データ・ダウンロード - 気象庁からcsvデータをダウンロードします
- 地点:東京
- 項目:
- 日別値
- 気温(平均気温,最高気温,最低気温)
- 期間:1872年1月1日 - 2018年7月21日(53528日)
まず,以下の画面で都道府県および地区を選択します.

次に,以下の画面で項目を選択します.降水量や湿度も興味深いですが,一度にダウンロードできるデータ量に制限があるため,今回は気温(平均気温,最高気温,最低気温)のみを選択します.

最後に,以下の画面で期間を選択します.一度にダウンロードできるデータ量に制限があるため,10年ごとに刻んでダウンロードします.

Downloadフォルダのdata.csvを年代ごとに改名し,data/raw/以下に次のように保存します.
data_1870.csvdata_1880.csvdata_1890.csvdata_1900.csvdata_1910.csvdata_1920.csvdata_1930.csvdata_1940.csvdata_1950.csvdata_1960.csvdata_1970.csvdata_1980.csvdata_1990.csvdata_2000.csvdata_2010.csv
モジュールのインポート
import numpy as np # 数値計算
import pandas as pd # DataFrame
import matplotlib.pyplot as plt # グラフ描画
import seaborn as sns # グラフ描画設定
from tqdm import tqdm # forループの進捗状況確認
import codecs # Shift-JIS読み込み用
from fbprophet import Prophet # prophet
sns.set_style(style='ticks') # グラフスタイルの指定
データの前処理
years = range(1870, 2020, 10)
read_path = 'data/raw/'
all_data = pd.DataFrame()
for year in tqdm(years):
data_file = 'data_{}.csv'.format(year)
# 補足1:普通にpd.read_csvすると読み込めない
with codecs.open(read_path+data_file, "r",
"Shift-JIS", "ignore") as f:
# 補足2:先頭数行のデータは使用しない.
# また,不要なカラムは除外して利用する.
data = pd.read_table(
f, delimiter=",", skiprows=5, index_col=0,
usecols=[0, 1, 4, 7])
# datetime形式に変換
data.index = pd.to_datetime(data.index)
# カラム名を変更
data.columns = ['average', 'high', 'low']
# all_dataを更新
all_data = pd.concat([all_data, data])
# 補足3:すべてNanの行は削除
all_data = all_data.dropna(how='all')
以下で,詳細を補足します.
codecs.open
Shift-JISで作成されているため,普通にpandas.read_csv()を使っても,ファイルを読み込めません.pandasでread_csv時にUnicodeDecodeErrorが起きた時の対処 (pd.read_table()) - Qiitaを参考に,codecs.open()を利用します.
2018年7月25日追記:@skotaroさんのご指摘の通り,
pandas.read_csv(encoding='Shift-JIS')で普通に読み込めました.私の不勉強でした.ご指摘ありがとうございました!
不要な行・列を除外
元データをそのまま読み込むと,以下のように不要な行・列が含まれてしまいます.

そこで,pandas.read_table()のパラメータskiprowsとusecolsを用いて,分析に必要な部分のみ抽出します.
すべてnp.nanの行を削除
気象庁のサイト上では1872年1月1日から指定可能でしたが,最初の数年分はデータが含まれていませんでした.pandas.DataFrame.dropna(how='all')で,すべての値がnp.nanの行を削除します.これにより全体の約2%にあたる1272日分のデータが除外されます.
- 地点:東京
- 項目:
- 日別値
- 気温(平均気温,最高気温,最低気温)
- 期間:1875年6月10日 - 2018年7月21日(52266日)
分析
平均気温,最高気温,および最低気温の分析を行します.
平均気温
まず,すべての点を散布図でプロットしてみます.
plt.figure(figsize=(8, 6))
plt.plot(all_data.index, all_data.average, 'o', alpha=.1)
plt.xlabel('Date')
plt.ylabel('Average temparature')
plt.show()

140年間で平均気温がじわじわ上がっていく様子がわかります.Prophetでより詳細に分析します.
# Prophet用DataFrameを生成
ave_data = pd.DataFrame()
ave_data['ds'] = all_data.index
ave_data['y'] = all_data.average.values
# Prophetモデルの構築
m = Prophet(weekly_seasonality=False)
# 学習
m.fit(ave_data)
Prophetで時系列解析を行うためには,以下のカラムを持つpandas.DataFrameを生成する必要があります.
-
ds:日付カラム. -
y:予測対象カラム.
また,Prophetではデフォルトでyearly_seasonalityとweekly_seasonalityを仮定して学習します.気温は曜日に依存しないと考えられるため,weekly_seasonalityを除外します.
以上で学習したモデルmを使い,将来30日間の平均気温を予測します.以下のように,m.make_future_dataframeでDataFrameを生成すると楽です.
# 将来30日間を予測
future = m.make_future_dataframe(periods=30)
forecast = m.predict(future)
予測結果をm.plot()でプロットします.約140年分プロットするとわけがわからないので,直近1年分のみを表示するようにします.
m.plot(forecast)
plt.xlim(future.ds.iloc[-365-30], future.ds.iloc[-1])
plt.xlabel('Date')
plt.ylabel('Average')

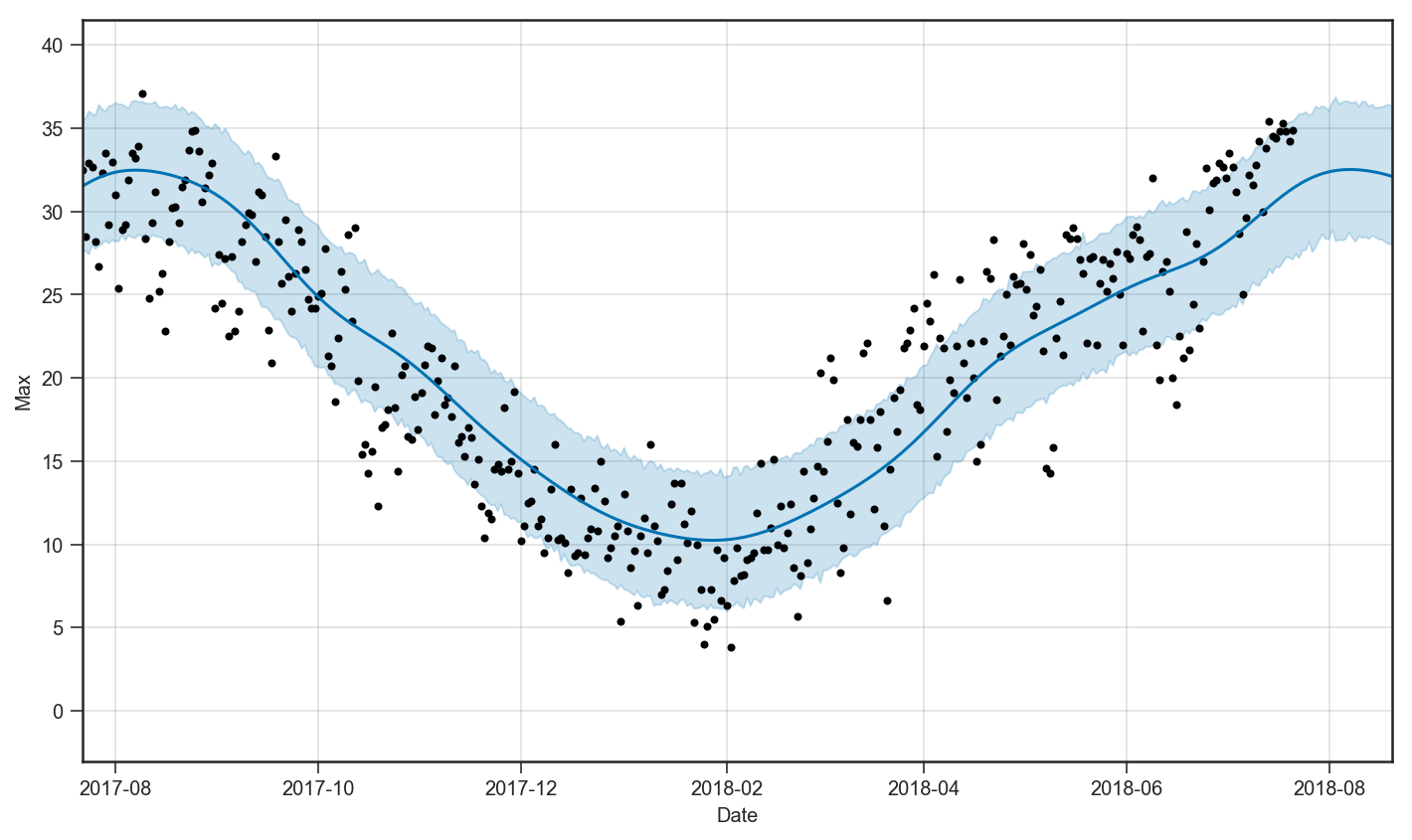
黒点が実測値,青線の実線が予測値,そして薄い青の塗りつぶしが80%信頼区間1を示します.ここ数日の平均気温は,信頼区間の上限ギリギリに張り付いていることが確認できます.例年から統計的に予測したとき,いかにここ数日の気温が高いかわかります2.また,例年の傾向を考慮すると,気温のピークは8月初旬であるという絶望的な事実がわかります.
次に,m.plot_components(forecast)で周期性とトレンドを確認します.
m.plot_components(forecast)

上の図がトレンド,下の図が年内の周期性を表します.東京の平均気温は1920年あたりから上がり続けていることがわかります.また,年内で見ると,気温のピークは7月下旬から8月上旬にあることがわかります.
最高気温
同様の分析を行います.詳細は割愛しますが,平均気温と同様の性質が確認できます.
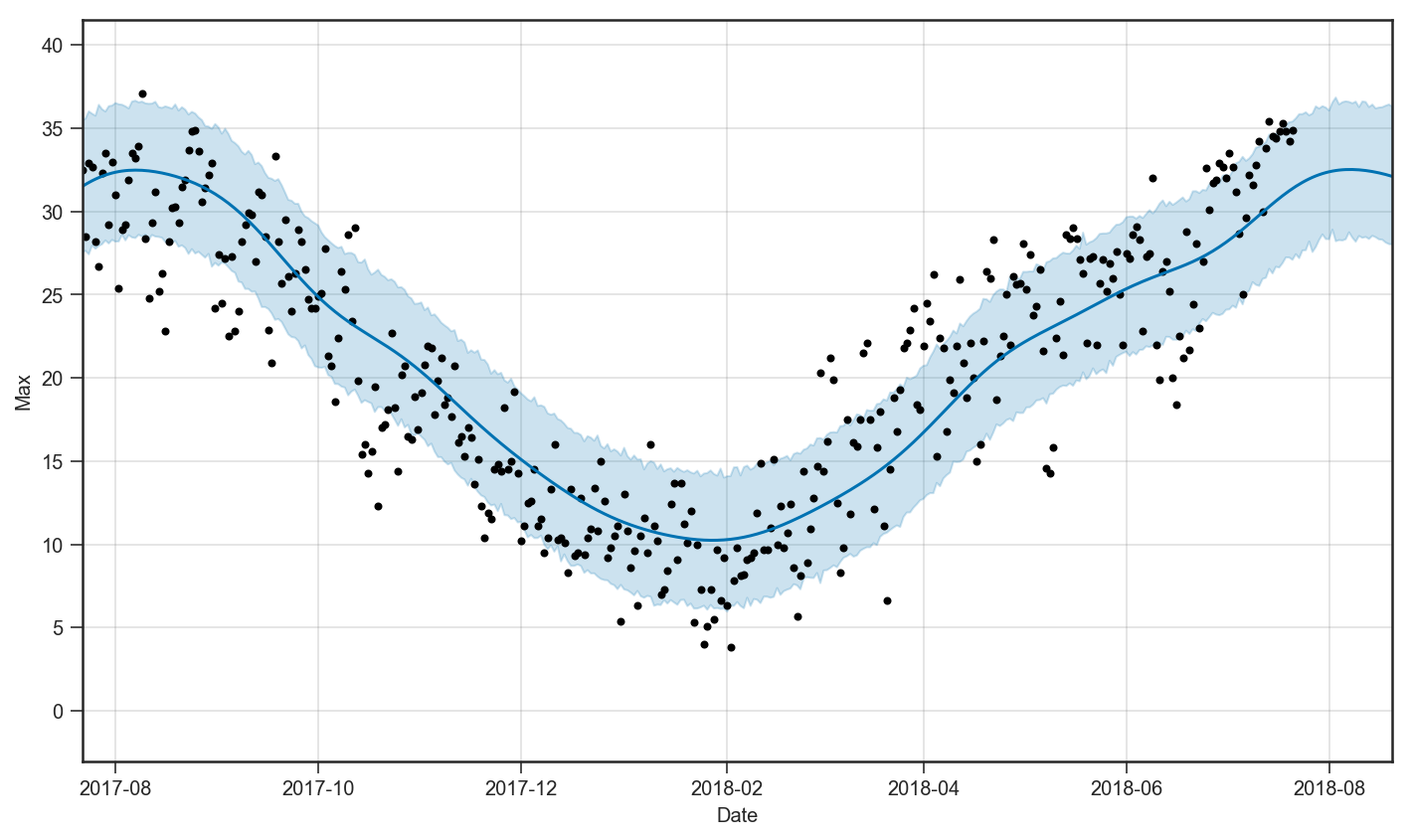

最低気温
同様の分析を行います.詳細は割愛しますが,平均気温と同様の性質が確認できます.


おわりに
地学の知識が中学理科で止まっている私でも,今年の夏はヤバイということがわかりました3.無理は禁物です.ご自愛くださいませ.
あと,この記事を書き終わるころ,東洋経済さんの素晴らしい記事を見つけました(東京の夏が「昔より断然暑い」決定的な裏づけ: 過去140年の最高気温をビジュアル化 - 東洋経済オンライン)4.こんなにわかりやすいヒートマップを初めて見ました.いつかこんなビジュアライゼーションをしてみたいです.
最後まで読んでくださり,ありがとうございました!