これは何?
出勤前にXを巡回していたら面白い投稿に出会った。
それがコレ
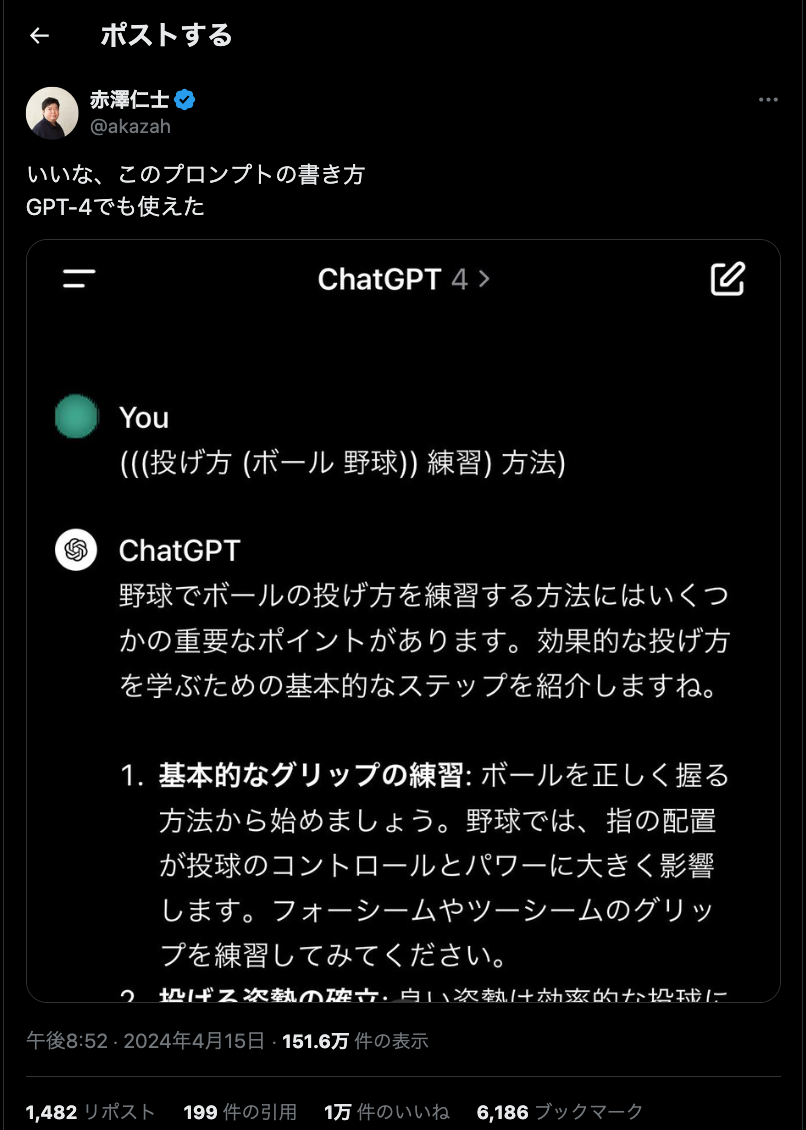
プロンプトを書く際に、LISP形式の()で区切るやり方が使えるとのこと。
上記に挙げたpostだと、
(((投げ方 (ボール 野球))練習) 方法)
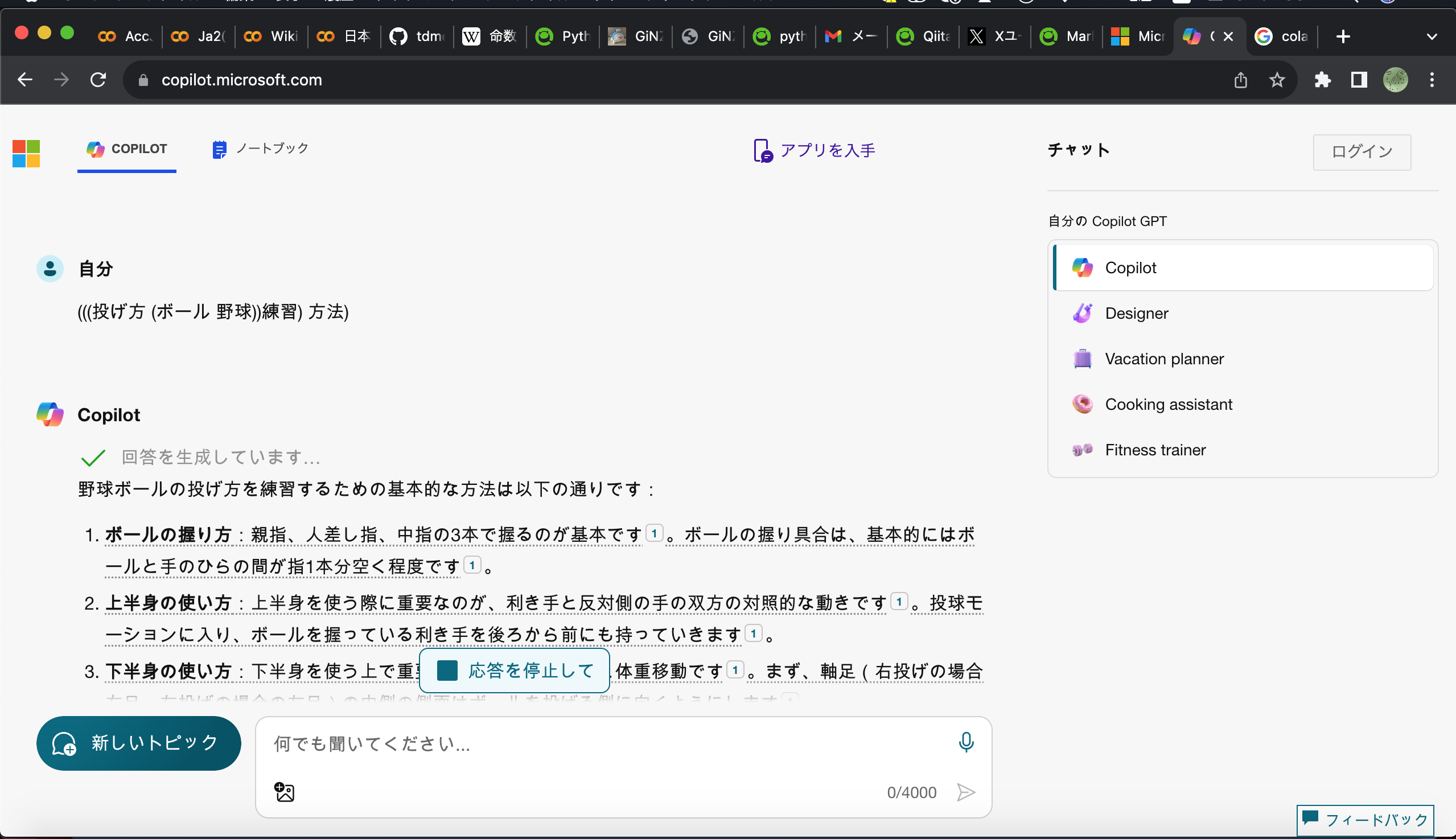
ログインしなくても使えるCopilot君でもそれっぽい回答になる。(なんか回答をずっと生成して止まらなくなったけど)
(#・_・#) <この()書きのやつ出力するプログラムが欲しい。
免責事項
- 筆者が分かっていないこと(責任を取らないこと)
- ChatGPTをはじめとする大規模言語モデルが上記に挙げたようなLISP記法を用いた構造を理解しているか。
- どのLLMモデルでも同じ挙動をするかどうか。またはモデルごとに挙動が違うのか。
→どちらもコーパスからデータを取ってきて比較するなり実験するなりすべきと思われ(知らんけど) - 本記事に記載の解析方法がポストの方の想定している考え方かどうかは確認していない。
- この出力を使って生成AIに投げた際の成果物等に関することは一切責任を取らない。(これでAIのVtuberとかいじめるのはやめてくりょ)
- 筆者が責任を取ること
- 特になし。
TL:DR
#必要なものをpip
!pip install -U ginza ja_ginza_electra
!pip install nltk
#普通のpython
import spacy
from nltk import Tree
drop_nest = ["case","cc","clf","dep","det","expl","discourse","goeswith","list","punct","reparandum"]
text = "東京で月10万円で1LDKに住める地域"
nlp = spacy.load('ja_ginza_electra')
doc = nlp(text)
# tree表示する関数
def to_nltk_tree(node):
if node.n_lefts + node.n_rights > 0:
return Tree(node.orth_, [to_nltk_tree(child) for child in node.children])
else:
if node.dep_ not in drop_nest:
return node.orth_
for sent in doc.sents:
ki = to_nltk_tree(sent.root).pformat_latex_qtree()
print(ki.replace("\\Tree","").replace("None","").replace("[.","(").replace("]",")"))
実装方法
0.見通しを立てる
実装環境:Colaboratory
実装言語;python
使うライブラリ:Ginza,spacy,nltk
(#・_・#) <これならGPUなんて持っていない自分でも作れる。
1.Ginzaに投げる
ライブラリ導入方法は各々作成時に公式HPを確認すべし。
import ginza
import spacy
from spacy import displacy
nlp=spacy.load("ja_ginza_electra")
doc=nlp("野球ボールの投げ方の練習の方法")
for sent in doc.sents:
for token in sent:
print(
token.i,
token.orth_,
token.lemma_,
token.norm_,
token.morph.get("Reading"),
token.pos_,
token.morph.get("Inflection"),
token.tag_,
token.dep_,
token.head.i,
)
print('EOS')
displacy.render(doc, style='dep', jupyter=True)
0 野球 野球 野球 ['ヤキュウ'] NOUN [] 名詞-普通名詞-一般 compound 1
1 ボール ボール ボール ['ボール'] NOUN [] 名詞-普通名詞-一般 nmod 3
2 の の の ['ノ'] ADP [] 助詞-格助詞 case 1
3 投げ方 投げ方 投げ方 ['ナゲカタ'] NOUN [] 名詞-普通名詞-一般 nmod 5
4 の の の ['ノ'] ADP [] 助詞-格助詞 case 3
5 練習 練習 練習 ['レンシュウ'] NOUN [] 名詞-普通名詞-サ変可能 nmod 7
6 の の の ['ノ'] ADP [] 助詞-格助詞 case 5
7 方法 方法 方法 ['ホウホウ'] NOUN [] 名詞-普通名詞-一般 ROOT 7
EOS
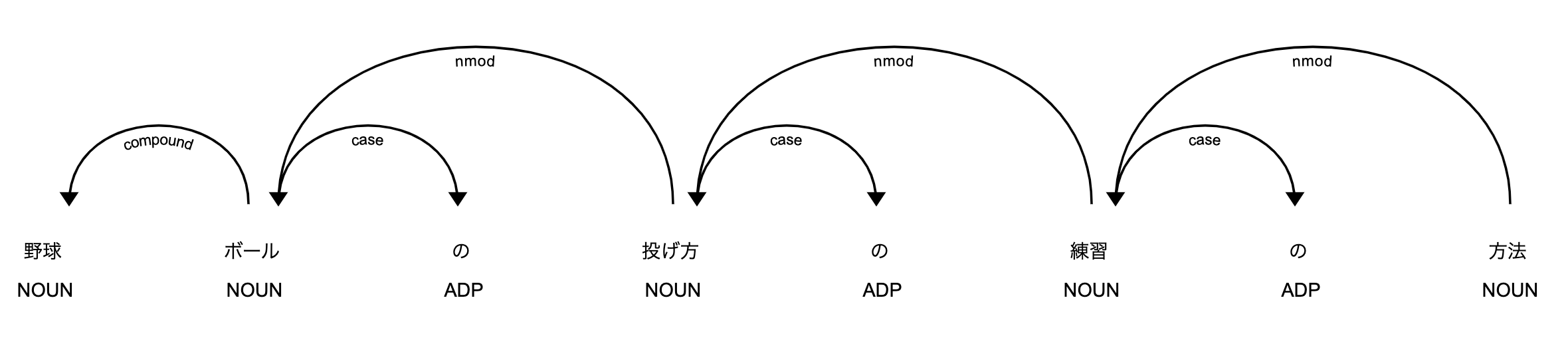
(#・_・#) <野球ボールは硬くて怖い。
2.Ginzaから受け取ったデータをどうにかこうにかする。
ルールを考える。
(((投げ方 (ボール 野球))練習) 方法)をよく見てみる。
(#・_・#) <よく見た。
【脳内思考】多分こうだろうというルールを作る。
- 係り受けの矢印は絶対に左から右になるように記述する。
(つまり「野球ボール」みたいな「ボール」compound→「野球」みたいな関係を記述したかったら「ボール 野球」と元の自然な文で出現する順序とは逆になる。) - Ginzaで解析した際のROOT(今回は「方法」)から関係性をたどる形で()を記述する。
(方法)((練習) 方法)(((投げ方) 練習) 方法)(((投げ方 (ボール)) 練習) 方法)(((投げ方 (野球 ボール)) 練習) 方法) - 助詞みたいなやつ(今回の解析結果だと「case」になるやつ)は表示させないことにする。
(#・_・#) <この解釈が正しいかは知らん。
Universal Dependenciesの係り受けタグから必要なやつとそうでないやつを判断する。
日本語文から()の形式にする当たって想定される処理は3つ。(と考えていたけど増えた。)
(処理内容)
- 無視(記述しない)
- 同一階層に記載
- 階層を分ける
- 係り元のみ残す
- 結合する
参考資料をもとに筆者が独断で以下のルールを作成。
具体的には参考資料の英文と筆者が勝手に和訳したものとのDependency Relationsを比較して判断。(一部和訳だと日本語で同じ関係性が出現しなかったので筆者が独断で作った文章で比較)
| Dependency Relations | 日本語での例 | 今回での処理内容 |
|---|---|---|
| acl | 「名付けられた鸚鵡」の 「鸚鵡」→「名付け」間 |
階層を分ける |
| advcl | 「アカウントを保護するために彼に話しかけた」の 「話しかけ」→「保護」間 |
階層を分ける |
| advmod | 「今どこへ行きたい?」の 「行き」→「今」間 |
階層を分ける |
| amod | 「サムは綺麗肉を食べた」の 「肉」→「綺麗」間 |
階層を分ける1 |
| appos | - 2 | 係り元のみ残す(?)2 |
| aux | 「逃げるべきだ」の 「逃げる」→「べき」間と 「べき」→「だ」間 |
結合する |
| case | 「Chairのオフィス」の 「Chair」→「の」間 |
無視(記述しない) |
| cc | - 3 | 無視(記述しない)3 |
| ccomp | 「彼はあなたは泳ぐのが好きだと言っていたよ」の 「言っ」→「好き」間 |
階層を分ける |
| clf | 「このCLFバス」の 「バス」→「この」間 |
無視(記述しない) |
| compound | 「アクセント辞典」の 「辞典」→「アクセント」間4 |
同一階層に記載 |
| conj | - 5 | 同一階層に記載5 |
| cop | 「イバンはいいダンサーだ」の 「ダンサー」→「だ」間 |
結合する |
| csubj | 「夜遅くに出かけるのがとても苦手だ」の 「苦手」→「出かける」間 |
階層を分ける |
| dep | ここに書くのが難しいレベルの不明な関係 | 無視(記述しない) |
| det | 「その男はここにいる」の 「男」→「その」 |
無視(記述しない) |
| discourse | 表現できなかった | 無視(記述しない) |
| dislocated | 「象は鼻が長い。」の 「長い」→「象」 |
階層を分ける |
| expl | 日本語にはないらしい6 | 無視(記述しない) |
| fixed | 「あなたのせいではない」の 「で」→「は」間と 「で」→「ない」間 |
隣接するhead.iで結合する。 head.iが隣接でなければiで比較して直前と結合(?) |
| flat | 「栗田氏はマロンだ」の 「氏」→「栗田」 |
結合する7 |
| goeswith | 表現できなかった」 | 無視(記述しない) |
| iobj | 「北京大に留学し、帰国後に出産」の 「留学」→「大」 |
階層を分ける5 |
| list | 多分出てこないと思う | 何もしない |
| mark | 「働いている」 「働い」→「て」 |
結合する |
| nmod | 「魚と猫が走る」 「猫」→「魚」 |
同一階層に記載 |
| nsubj | 「部屋には幽霊がいる」 「いる」→「幽霊」 |
階層を分ける |
| nummod | 「100円払った」 「円」→「100」 |
結合する |
| obj | 「給料を上げる」 「上げる」→「給料」 |
階層を分ける |
| obl | 「子供達にあげたおもちゃ」 「あげ」→「子供達」 |
階層を分ける |
| orphan | 表現できなかった | 階層を分ける |
| parataxis | 表現できなかった | 階層を分ける |
| punct | 句読点 | 無視(記述しない) |
| reparandum | 言い直しだから プロンプトに入れないで |
無視(記述しない) |
| root | 「フライドポテトが大好き」 「大好き」→「大好き」 |
階層を分ける こっから解析する |
| vocative | 「へい!、楽に行こうぜ"」 「へい」→「行こうぜ」 |
階層を分ける |
| xcomp | 日本語にはないらしい6 | 階層を分ける |
参考資料:Qiitaのこの記事-「自然言語処理におけるPOSタグと係り受けタグ一覧」
Universal Dependencies 日本語コーパス
(#・_・#) <まぁGiNZAでも他の構文解析器でも納得いくように解析できてたなら研究題材にならんしなぁ。思ったよりも日本語でうまく表現できないUDがあるのはしゃーない。って勝手に思っているなう。
ソースコードに落とし込む。
階層が分かれるやつはSpacyできっとよしなにやってくれると思うので、省略したいものだけ定義する。また、自分の力で実現できそうにない実装は諦めた。
drop_nest=["case","cc","clf","dep","det","expl","discourse","goeswith","list","punct","reparandum"]
今回は「助詞」(名詞にくっつく「の」)を表示させない感じで作ったけど、用途に合わせて各々弄ってね。
ROOTから遡る方法を実装する。
【脳内思考】多分こうだろうというルールを作る(その2)
- まずROOTを探す
- ROOTから伸びる子ノードを近い順から1個ずつ探索して入れていく
- 格納する
import spacy
from nltk import Tree
nlp = spacy.load('ja_ginza_electra')
doc = nlp("野球ボールの投げ方の練習の方法")
# tree表示する関数
def to_nltk_tree(node):
if node.n_lefts + node.n_rights > 0:
return Tree(node.orth_, [to_nltk_tree(child) for child in node.children])
else:
return node.orth_
ki=[to_nltk_tree(sent.root).pformat_latex_qtree() for sent in doc.sents]
print(ki)
['\\Tree [.方法 [.練習 [.投げ方 [.ボール 野球 の ] の ] の ] ]']
NLTKのTreeが素晴らしい。
あとは、条件に合うようにくっつけたり同じ階層に入れたりするとできあがる。
import spacy
from nltk import Tree
text="野球ボールの投げ方の練習の方法"
nlp = spacy.load('ja_ginza_electra')
doc = nlp(text)
# tree表示する関数
def to_nltk_tree(node):
if node.n_lefts + node.n_rights > 0:
return Tree(node.orth_, [to_nltk_tree(child) for child in node.children])
else:
if node.dep_ not in drop_nest:
return node.orth_
for sent in doc.sents:
ki=to_nltk_tree(sent.root).pformat_latex_qtree()
print(ki.replace("\\Tree","").replace("None","").replace("[.","(").replace("]",")"))
(方法 (練習 (投げ方 (ボール 野球 ) ) ) )
適当に無料で使えるCopilot君に投げてみる。
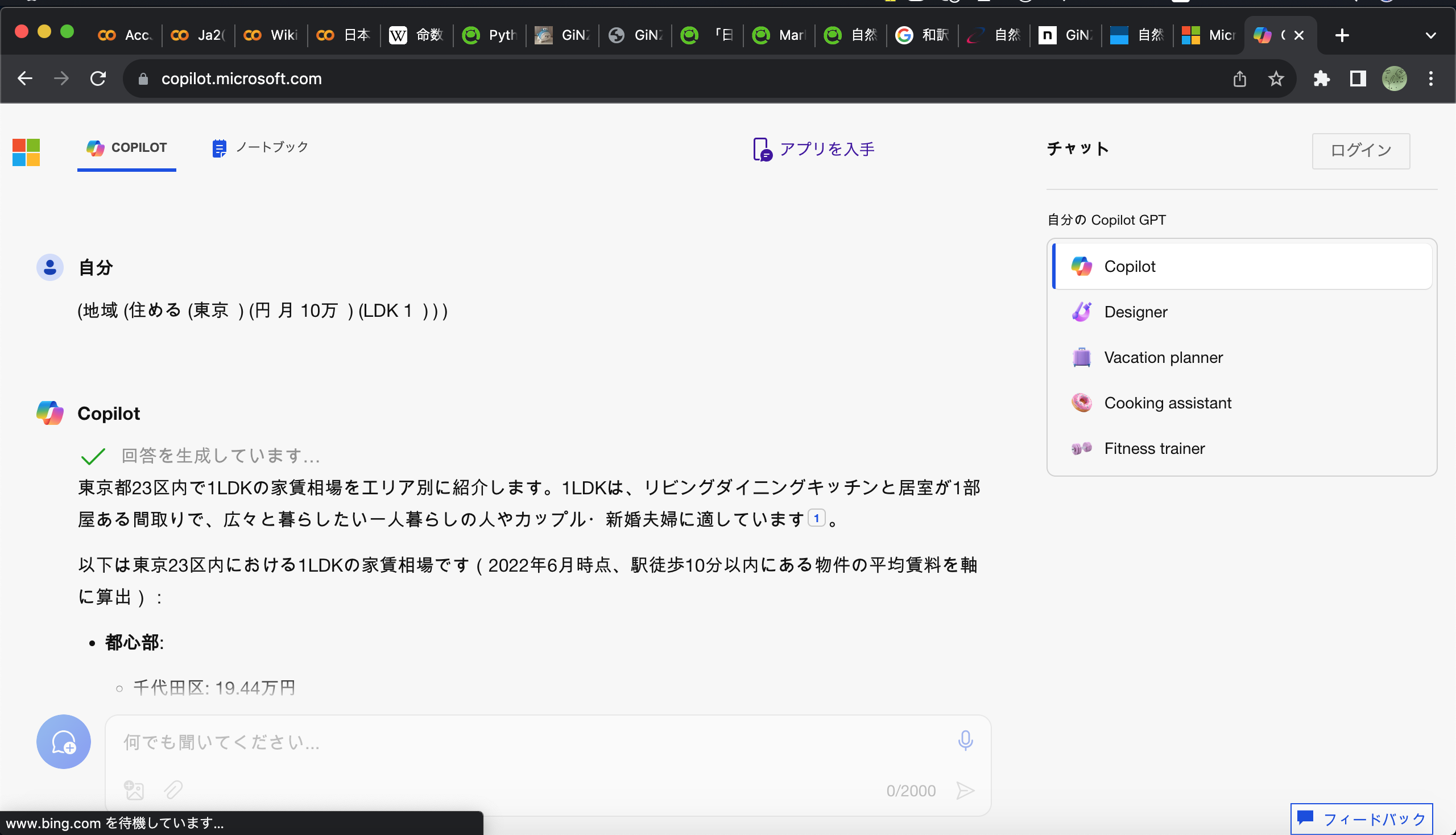
「1LDK」とか「10万円」レベルだとMecab-Neologdでもくっ付いているからくっつけてみたい気もするけど、今回は断念。
自然言語で入力する以上のメリットってある?
(#・_・#) <自分の書いた日本語と構文解析結果に差異がある人にはおすすめかも。自分とか。
(#・_・#) <でもGiNZAが解析失敗したらおじゃん。まぁ、そんな機械にとって難解な日本語は生成AIに投げない方がいいのかもしれない。
最後に(免責事項のコピペ+α)
- 筆者が分かっていないこと(責任を取らないこと)
- ChatGPTをはじめとする大規模言語モデルが上記に挙げたようなLISP記法を用いた構造を理解しているか。
- どのLLMモデルでも同じ挙動をするかどうか。またはモデルごとに挙動が違うのか。
→どちらもコーパスからデータを取ってきて比較するなり実験するなりすべきと思われ(知らんけど) - 本記事に記載の解析方法がポストの方の想定している考え方かどうかは確認していない。
- 日本語から()形式(LISPって呼んでいいのだ?)へ変換する手法やGiNZAの使い方、Universal DependenciesのDependency Relationsの解釈については正しいかどうか自信がない。
(#・_・#) <良きLLMライフを〜
「自然言語使える仕組みでなんでわざわざ面倒臭い表現を使うの?」
(#・_・#) <....
実装にあたり参考にさせていただいたサイト
https://qiita.com/makaishi2/items/eb43cfcef2ca0d9761bb
https://qiita.com/kei_0324/items/400f639b2f185b39a0cf
https://note.com/npaka/n/n5c3e4ca67956
https://virment.com/ginza-dependency-parse/
https://www.nltk.org/howto/tree.html
-
文を作りながら「複合語になるかもしれない」とか思ったけど分けといた。「綺麗な肉」とかにすると「肉」→「綺麗」でacl、「綺麗」→「な」でauxになるし。 ↩
-
「私の兄であるサムが来た」とかにすると「サム」→「兄」でaclになってしまう。「私の兄、サムが来た」は「サム」→「兄,」でnmodになってしまう。 ↩ ↩2
-
「billは偉くて正直です」の「偉く」→「て」はmarkになってしまう。「and」って感覚で「桜と菊」ってしても「桜」→「と」の間でcaseするので独断で判断。 ↩ ↩2
-
「電話帳」はunidic→sudachi→GiNZAでは一つの単語。「電話」+「帳」なのはいうまでもないけど、基本的に一文字の単位(この場合の「帳」)は短単位とせず複合させてしまうことになっているから。以上多分unidicのドキュメントより。 ↩
-
「Universal Dependencies 日本語コーパス」で登場する文をGiNZAにぶち込んでもうまくいかないことがある。 ↩ ↩2 ↩3
-
「Universal Dependencies 日本語コーパス」を設計するに当たってコーパスに入れていないらしいから、GiNZAで解析した時には出てこないと思われる。 ↩ ↩2
-
「栗田氏はマロンだ」ってGiNZAで解析した時に「氏」→「栗田」がcompoundしちゃったから、正直解析しても出てこないと思われる。 ↩