はじめに
個人サイトが作りたくなって、バックエンドとしてHeadlessCMSを検討した結果、オープンソースのStrapiが良さそうだったので構築してみました。
Strapiはプラグインを追加することでRESTのエンドポイントだけでなくGraphQLのエンドポイントも生成してくれるので、せっかくならとGraphQLも採用してみることにしました。
Strapiをlocalで環境構築してherokuにデプロイするまでの一通りの手順をまとめましたので、HeadlessCMSとしてStrapiを検討してる方の参考になればと思います。
目次
Strapiとは
Node.jsがベースのオープンソースのHeadlessCMSです。
データ型やテーブルなどを定義したらデータを入稿できる管理画面を提供してくれて、かつ、データをAPI経由で取得できるようにエンドポイントまで自動で作ってくれる便利なやつの、オープンソース版って感じです。
最近は色々なHeadlessCMSがあるみたいですが、個人開発でsaasにデータを貯めていくとどこかで料金プランを上げる必要が出てきたりとかで、saas側の事情によって悩まされるのが嫌だったので、オープンソースでサーバの選択も自由なstrapiが魅力的に見えました。
ただ、自前でawsのRDSとか立ててもたぶん月4千円とかかかってウゲってなるんで、結局筆者は最終的にherokuのPostgreSQLアドオンの無料プランを使うことに決めました(無料で容量1GB、容量上げたくなったら月額9$で10GB)。
ちなみにClearDB MySQLアドオンは、無料で容量5MB、月額9.99$で容量1GBだったのでやめました。
herokuがキツくなってきたらてきとうな安めのレンタルサーバー借りてstrapiとDB構築してデータ移行すりゃいいやって安心できます。
GraphQLってなに
簡単にいうと、クエリとレスポンスの構造が似ている、型安全なWebAPIの規格、ですかね。
なんにも知らない状態でもこの記事読むとなんとなく分かりました。
開発環境構築
公式ドキュメントの導入手順に従います:https://strapi.io/documentation/3.0.0-beta.x/installation/cli.html
strapi自体のインスコはコマンド1行で終了します。
$ yarn create strapi-app strapi-asakawa-family --quickstart
--quickstartオプションを使った場合は対話形式のインストールが省略され、DBが自動的にsqliteで構築されます。
なのでpostgresが使いたい場合は先にpostgresをインストールしたあとに下記コマンドを実行します。
$ yarn create strapi-app strapi-asakawa-family
# 対話形式
# DBはpostgreSQLを選択
補足:postgreSQLのインスコ
# postgresをbrewで入れる
$ brew install postgresql
# version確認
$ psql --version
psql (PostgreSQL) 13.0
# utf8にする
$ initdb /usr/local/var/postgres -E utf8
# DB作成
$ createdb strapi-asakawa-family
# DB指定してログイン
$ psql -d strapi-asakawa-family
# なんかエラーがでる場合はサーバーが起動してなかったりする
psql: error: could not connect to server: could not connect to server: No such file or directory
# 起動
$ postgres -D /usr/local/var/postgres &
# ジョブ表示
$ jobs
Job Group State Command
1 31154 running postgres -D /usr/local/var/postgres &
# 削除
$ kill %1
# DB一覧
$ psql -l
普段mysqlしか触らないから、postgres全然わかりません。
次にDB接続用の設定ファイルを用意します。
jsonでもjsでも読み込んでくれるので、localと本番で値を使い分けたいときはjsで書きます。
あとで本番環境用の環境変数を設定するので、envに値があったらそっちから読み込むようにしてます。
config/database.js
module.exports = ({ env }) => ({
defaultConnection: 'default',
connections: {
default: {
connector: 'bookshelf',
settings: {
client: 'postgres',
host: env('DATABASE_HOST', '127.0.0.1'),
port: env.int('DATABASE_PORT', 5432),
database: env('DATABASE_NAME', 'strapi-asakawa-family'),
username: env('DATABASE_USERNAME', 'hiroshi.asakawa'),
password: env('DATABASE_PASSWORD', '******'),
ssl: env.bool('DATABASE_SSL', false),
},
options: {}
},
},
});
これだけでブラウザで確認できます。
http://localhost:1337/admin
環境構築が楽チンすぎてめっちゃよかったです。
データモデル作成
試しにデータを表示してみたいので、Contents-Types-Buildersを開いてモデルを作成します
本の名前と画像を格納するモデルをてきとうにポチポチ作ります。
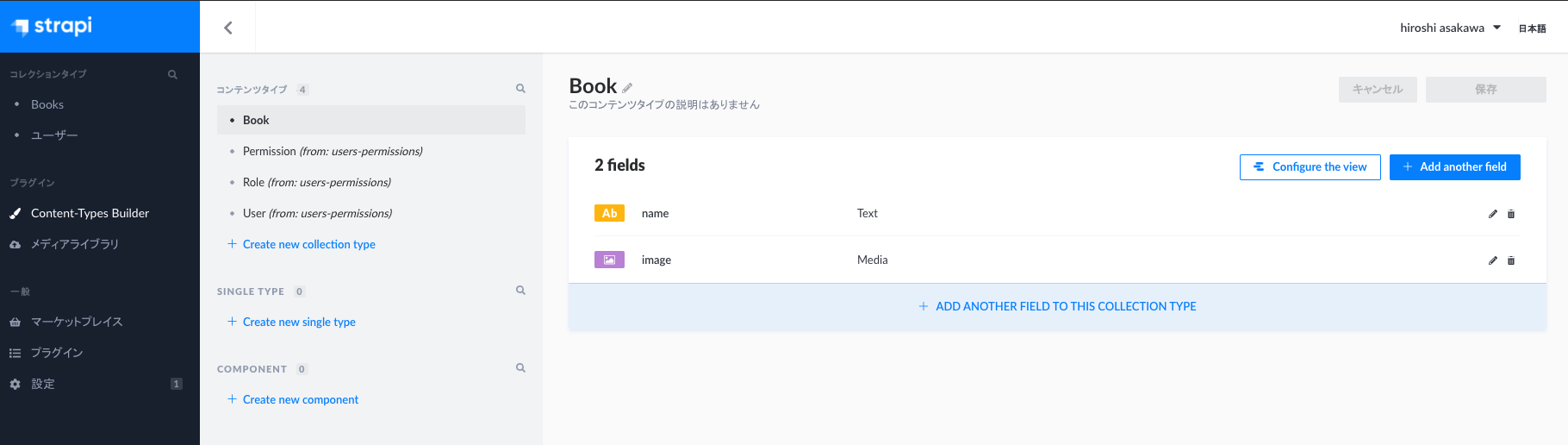
このポチポチ作業がmigrationになるんですが、本番環境ではContents-Types-Buildersは使用できません。
localでmigrationしておいて、その状態を本番にデプロイすると反映される仕様です。
なのでlocalでテーブルを作成して、本番ではデータを入稿するという使い分けになります。
コレクションタイプってところに新しく定義したモデルが表示されてるので、そこからデータを入稿します。
画像ファイルは先にメディアライブラリってところからアップロードしておくこともできます。
(画像のアップロード先は最終的にS3を設定しました)
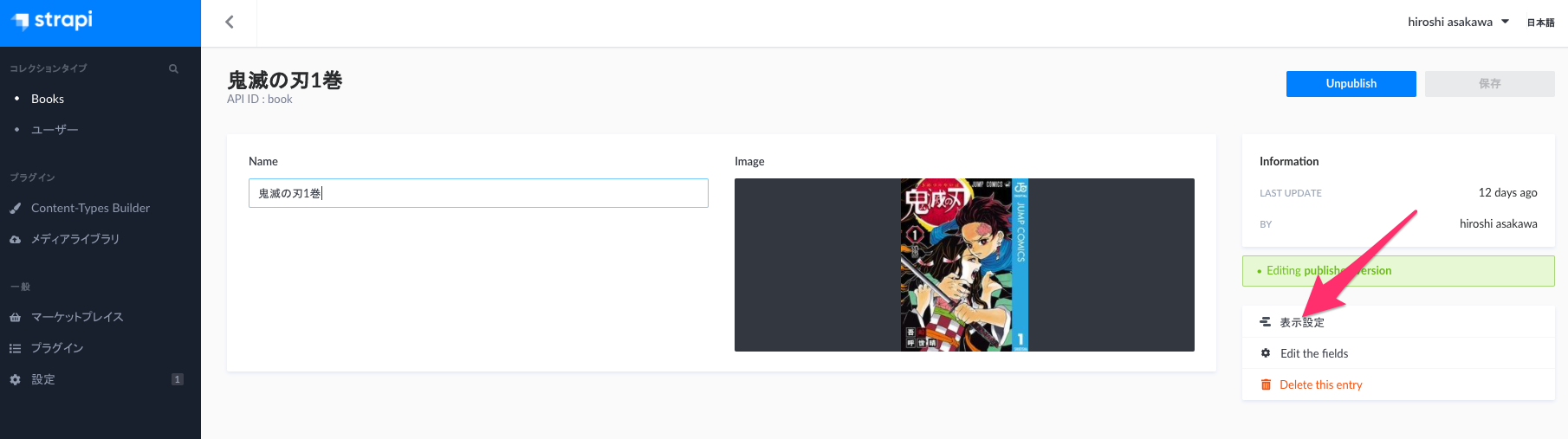
詳細ページ
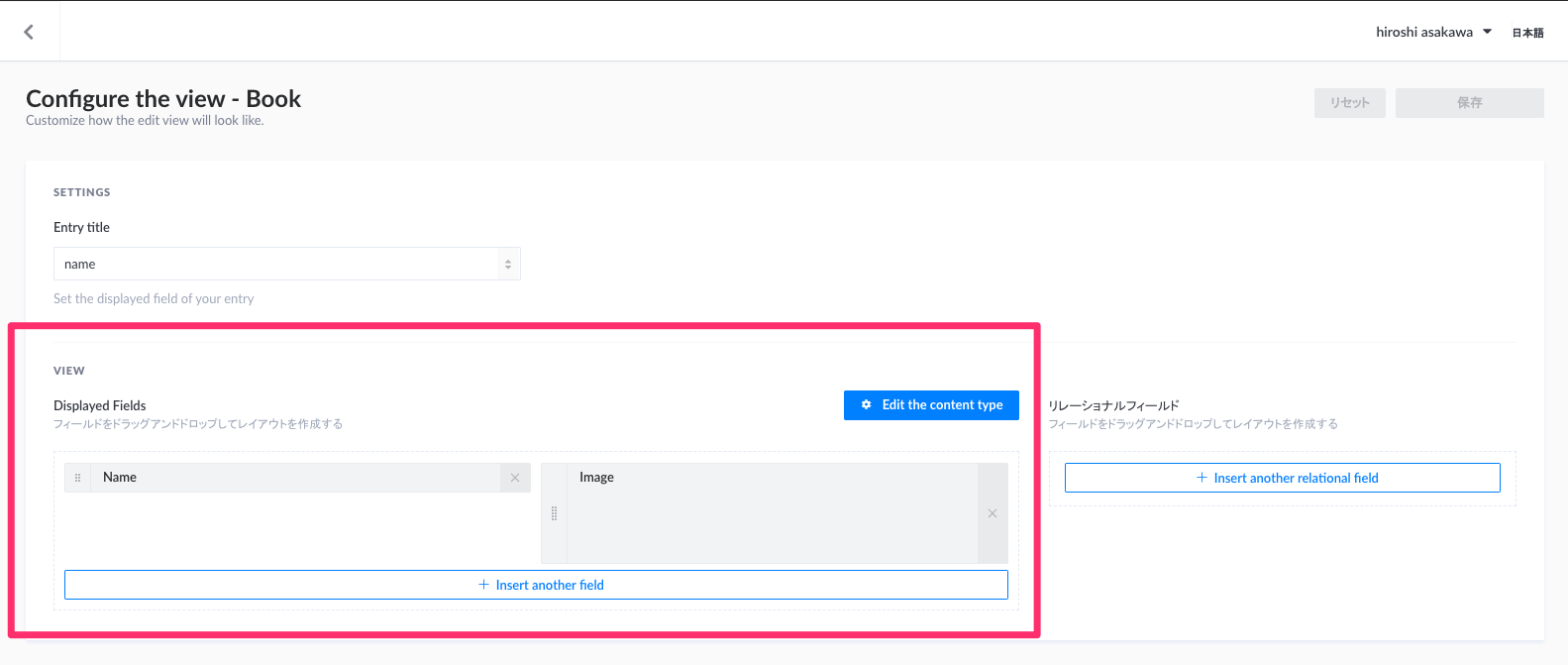
入稿画面での項目並び順はここでカスタマイズできます。
一覧ページ
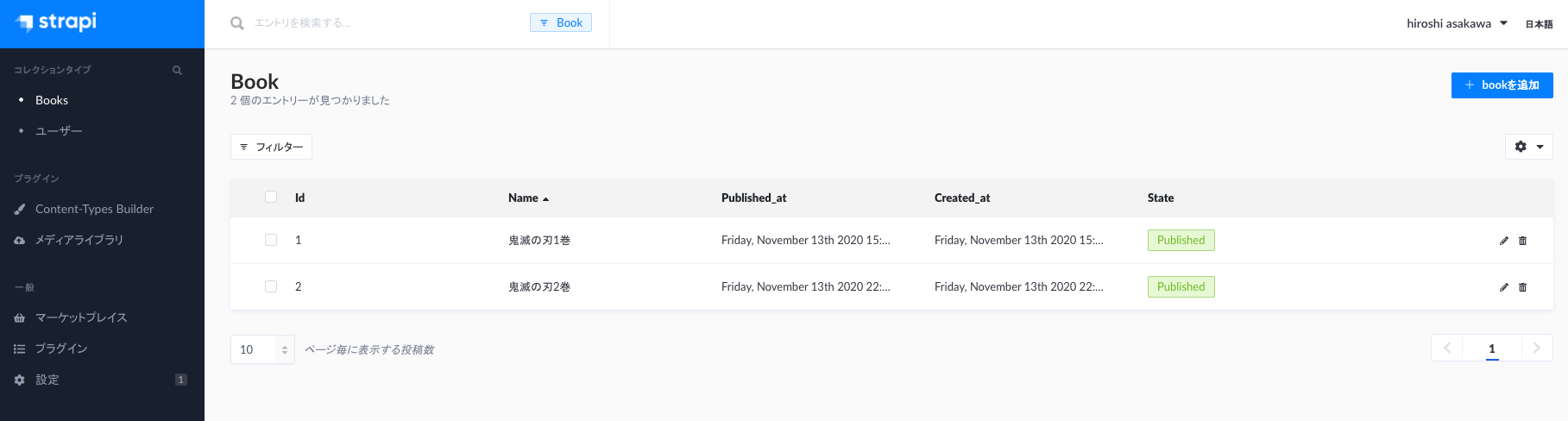
リレーションとか簡単に貼れそうなのと、複数モデルで同じカラムを使いそうな場合はそれらをグループ化して再利用できたりする機能が付いてるのが便利そうな印象です。
エンドポイント作成
次に、APIリクエストに対してjsonを返すエンドポイントを作ります。
使用したいmethodとアクセス権限を設定します。
設定 > ロールと権限 > Public
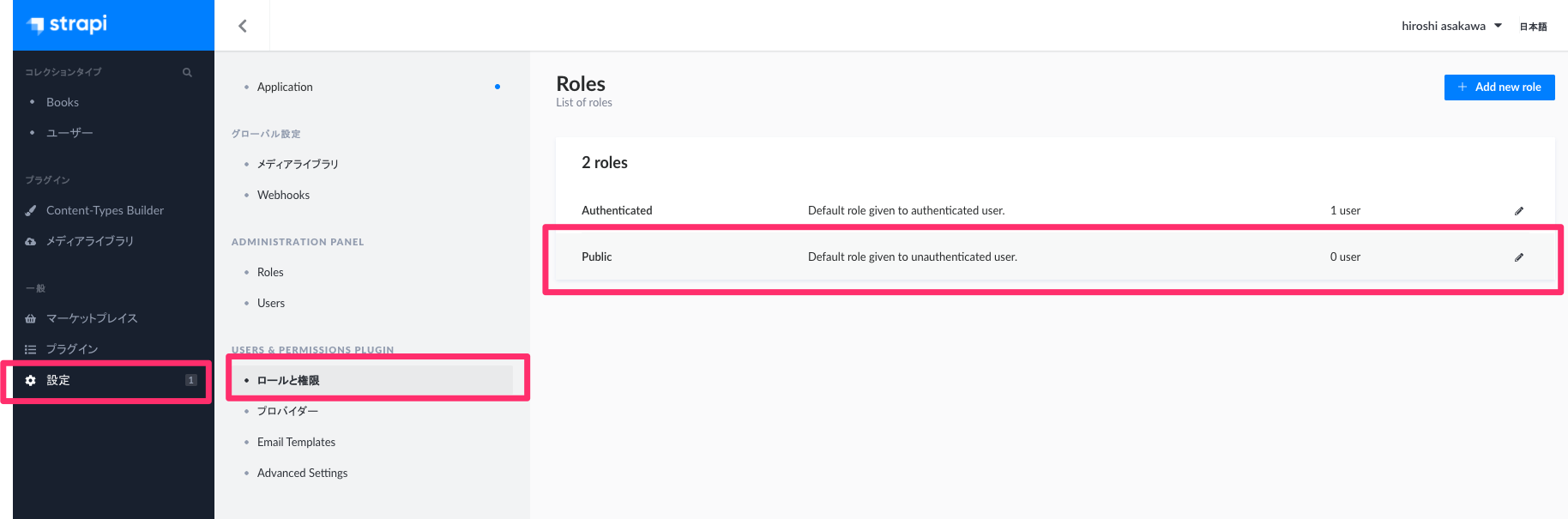
権限 > APPLICATION > BOOK
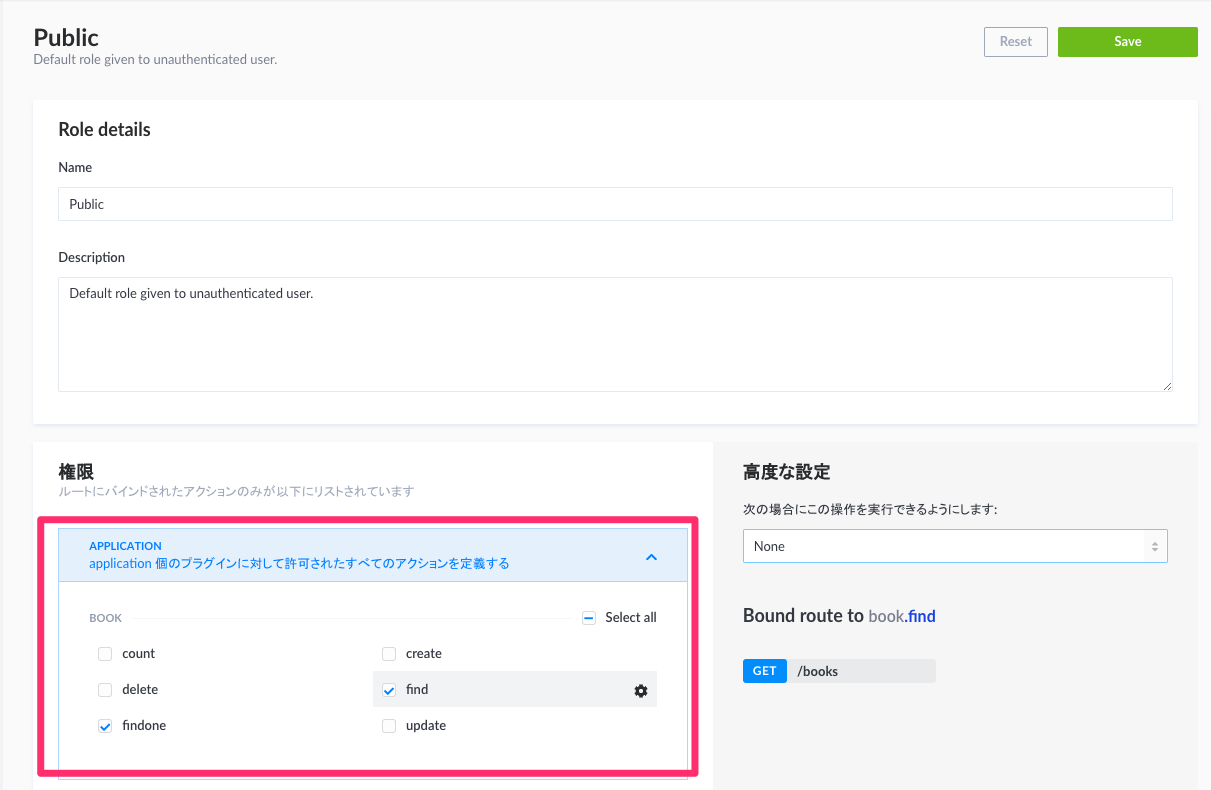
これでhttp://localhost:1337/books や http://localhost:1337/books/1 にリクエスト送るとjsonデータが返ってくるようになりました。
次はGraphQLを使ってみます。
GraphQLを使う場合はプラグインを追加します。
$ yarn strapi install graphql
そして設定ファイルを用意します。
プラグイン周りの設定ファイルはextensions/以下に配置する仕様です。
extensions/graphql/config/settings.json
{
"endpoint": "/graphql",
"tracing": false,
"shadowCRUD": true,
"playgroundAlways": true, # defaultはfalseだが本番でもGraphQLエディターが使いたいのでtrueにしておく
"depthLimit": 7,
"amountLimit": 100,
"federation": false
}
上記の設定が完了したら、以下のurlにアクセスします。
http://localhost:1337/graphql
どうやらstrapiはGraphQLPlaygroundっていうGraphQLのIDEを組み込んでいるようです。
このIDE上でスキーマを確認しながらクエリを作成し、結果のjsonデータをチェックしていく作業となります。
触ってみた感想としては、型チェックしてくれたり、入力補完が効くためストレスなく書けるのが凄く良い体験でした。楽しいです。
Book(id: 1)の取得失敗の図
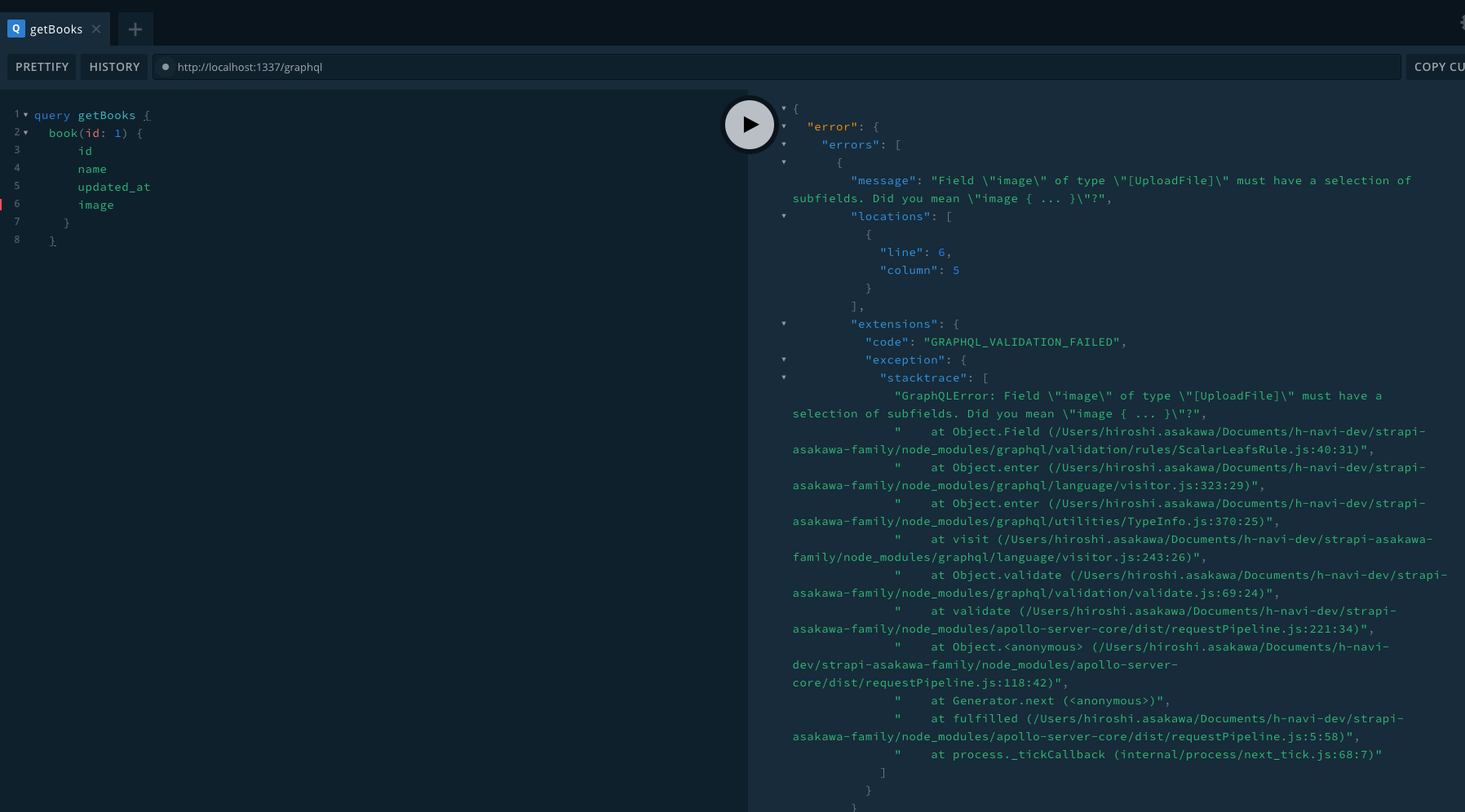
imageカラムの指定をミスした場合、親切なエラーメッセージが返ってくる
"message": "Field \"image\" of type \"[UploadFile]\" must have a selection of subfields. Did you mean \"image { ... }\"?",
GraphQLのクエリを書く体験は、BigqueryとかでSQL書く感覚に少し近いのかもしれないなと思ったり..。
右側のタブにあるDocsってとこを開くと、どんなデータ構造とデータ型なのかが一目瞭然になっててとても使いやすいです。
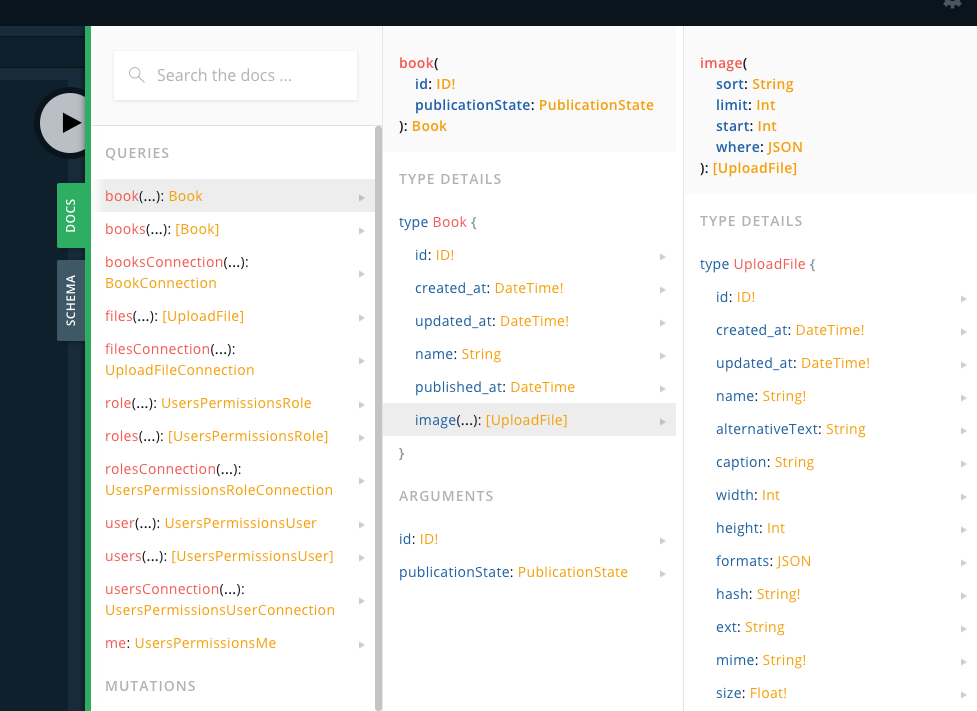
→UploadFile型のサブフィールドなので、追加項目を指定しないといけなかった。
Book(id: 1)の取得に成功の図
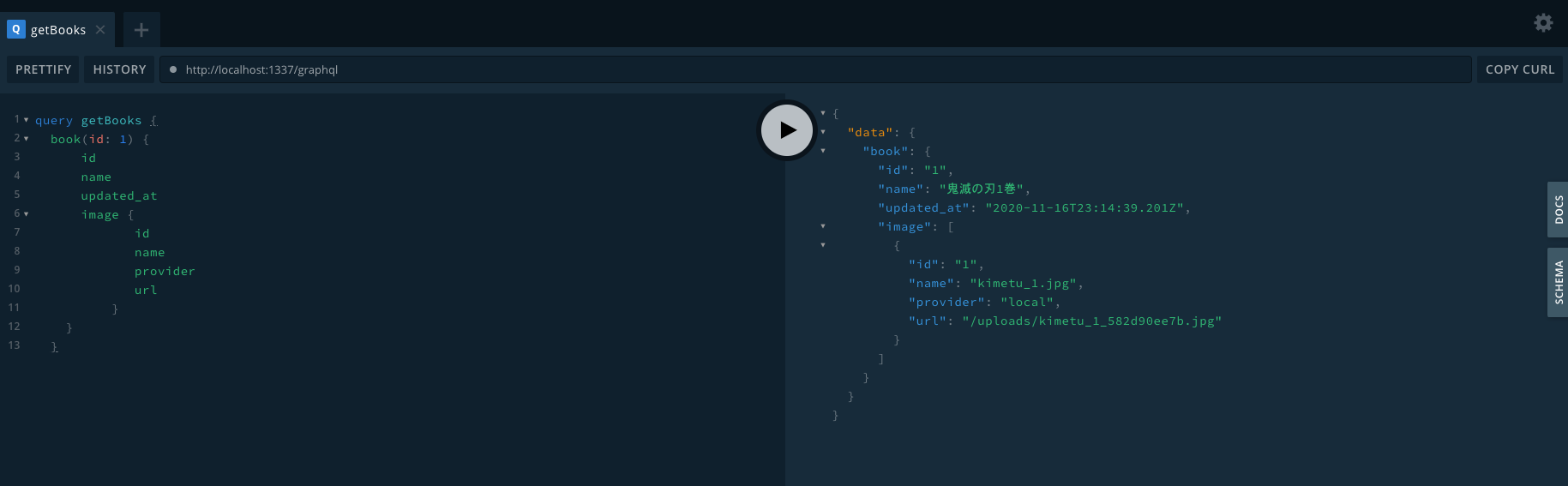
バックエンドがこれだけ直感的な作業だけでできちゃうって凄いですね。
好き勝手に個人サイトを作るという目的なので、ページ作成やDB設計などの本質的部分に開発時間を割きたいです。
なのでバックエンド作業工数が少なく、見通しもよさそうな点はとても助かりそうです。
本番環境構築
localでの環境構築と動作確認は終わったので、これを本番でも使えるようにします。
そこで、strapiを動かすサーバーを選定してデプロイします。
さて、サーバーどうしようってところなんですが、結局herokuにしました。
理由は、githubとの連携やデプロイが一瞬で終わるのと、postgresSQLが無料プランで1GB使えたからです。
最初はひとまずこれで動きゃいいかなって感じです。
あとawsはRDSのオンデマンドインスタンスの料金が、趣味サイトに使うには少し高いなと感じたため利用は控えました。
レンタルサーバ等は環境構築が面倒だったので使いませんでしたが、HDDの容量や料金に対するパフォーマンスなどを考慮すると一番現実的で良い選択肢になるかもなと思っています。
とりあえず、strapi公式ドキュメントにherokuデプロイのやり方があるのでこれに従います
参考:https://strapi.io/documentation/3.0.0-beta.x/deployment/heroku.html
まずはDBを用意します。
postgresのアドオンをherokuアプリにインスコします。GUIでもCLIでもどっちでもいいです。
その後、strapiとpostgresを繋ぐために、herokuの環境変数にDBのhost情報等を追加します
なお、herokuのpostgresアドオンの料金はこちら
ちなみにmysql(clearDB)は無料だと容量が5MBしかないので、容量気にするならpostgresのがオススメです。
$ heroku config
# 下記形式のDBのhostやpassが出てきます。
(This url is read like so: *postgres:// USERNAME : PASSWORD @ HOST : PORT : DATABASE_NAME*)
# 上記の値をherokuの環境変数に設定
$ heroku config:set DATABASE_USERNAME=yapamaclplqlfn
$ heroku config:set DATABASE_PASSWORD=*************
$ heroku config:set DATABASE_HOST=ec2-52-44-235-121.compute-1.amazonaws.com
$ heroku config:set DATABASE_PORT=5432
$ heroku config:set DATABASE_NAME=dcb7t3g7adaodt
上記設定後、herokuにデプロイ
$ cd strapi-asakawa-family
$ heroku git:remote -a strapi-asakawa-family
$ git push heroku master
CLIから毎回デプロイするのが面倒そうだったので、masterブランチがマージされたら自動的にデプロイするようにしました。
デプロイが完了したらherokuのデプロイ先のドメインが表示されるので、そこにアクセスするとheroku環境でproductionモードのstrapiが起動しているのが確認できます。
(5~10分かかる印象)
画像アップロード用にS3用意
今のままだと画像の保存先がherokuのDBになってるので、すぐ容量オーバーするはずです。
また、herokuはエフェメラルファイルシステムという特徴を持ち、再起動時にファイルを削除しているため、アップロードした画像ファイルも消えてしまうようです。
参考:https://devcenter.heroku.com/articles/dynos#ephemeral-filesystem
そこでメディアファイルの保存先は別途選定せざるを得なくなり、awsS3かcloudinaryで迷いましたが、S3はそこまで料金がかからないのでは?と思ったのでS3にしました。
awsの料金はざっくり分けて稼働時間課金と通信量課金があるけど、S3は後者の通信量課金寄りのリソースなためです。
(どうせ趣味の個人サイトのトラフィックなんて雀の涙なんや)
S3の導入は再び公式ドキュメントに従います:https://strapi.io/documentation/3.0.0-beta.x/plugins/upload.html#using-a-provider
ここまでの導入手順は全てstrapi公式に丁寧な手順書が記載されてます。
awsS3側の設定は自前でやらないといけないので手順を載せときます。
- S3バケット作成
- 該当S3バケットへのアクセス権を持つIAMユーザーを作成
- 該当IAMユーザーのアクセスキーとシークレットキー、プロバイダー名、リージョン名、バケット名を設定ファイルに記載
- バケットポリシーはご利用計画に応じて
S3の設定が終わったら新しいproviderをインストールします
$ yarn add strapi-provider-upload-aws-s3
extensions/upload/config/settings.json
{
"provider": "aws-s3",
"providerOptions": {
"accessKeyId": "*****************",
"secretAccessKey": "*****************",
"region": "ap-northeast-1",
"params": {
"Bucket": "strapi-asakawa-family-images"
}
}
}
上記設定後、local再起動、本番デプロイするとメディアライブラリの保存先がS3バケットに変わります。
本番でS3に画像をアップロードすると、large,medium,small,thumbnailの各サイズに変換後のファイルが保存されました。

参考動画:https://www.youtube.com/watch?v=7bjuFiESkJA

おわりに
これでGraphQLデータ返却マシーンが完成しました。
今回は非エンジニアでも気軽に入稿ができる環境が欲しかったんですが、実はひとつ落とし穴が。。
当初はスマホからも入稿ができることを想定してたんですが、mobileが未対応でした。
ガーン( ̄◇ ̄;)
レスポンシブル非対応の図
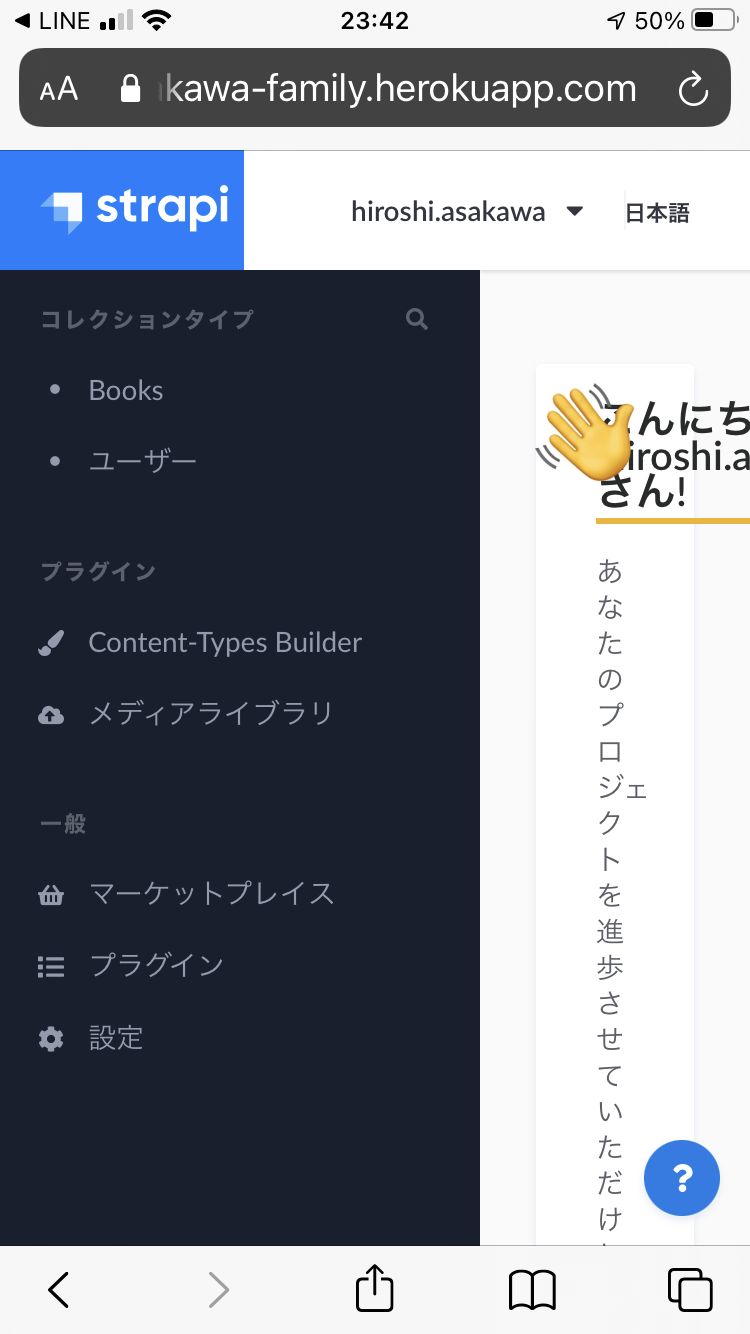
HeadlessCMSってどれもmobileからの利用って想定されてないものなんですかね!?
自分は構築し終わった後に気づいてちょっと残念でした。
あとNetlifyCMSはNetlifyでホスティングしてるサイトに入稿画面をくっつけることができるみたいなので、サイトと入稿画面が1つのドメインになるのも良いなと思いました。
ただ、NetlifyCMSもmobileは非対応のようです。ちなみにmicroCMSは対応してるみたい。
参考:https://jamstack.jp/blog/netlifycms_to_microcms/
mobile対応の有無はHeadlessCMSを比較する際の指標になると思います。
strapiはセットアップがとても簡単で公式ドキュメントの説明も丁寧だったので、興味がある方はぜひ作ってみてください〜。