はじめに
こんにちは。
GIFTechの伝統工芸×AIプロジェクトで開発をしている佐藤です。
皆さんは開発をしていて、AIが出す「それっぽい答え」の信頼性に疑問を感じたことはありませんか?
LLMの登場で情報収集は劇的に進化しましたが、その出力が本当に現実に即しているのか、根拠となるデータは信頼できるのか、という課題は常に付きまといます。
今回ご紹介するのは、私たちが開発した職人向け創作プロダクトに搭載されている「海外消費者AI」機能です。この機能は、オープンソースの情報だけに頼らず、自分たちの足で集めた一次データを心臓部に組み込むことで、AIの信頼性の壁を乗り越えようとする挑戦の記録です。
※実装部分はsampleです
🎯 対象読者
* AIの精度や信頼性に課題を感じている開発者の方
* FastAPI, Next.js, Google Cloudを使ったモダンな開発に興味がある方
* データに基づいたプロダクト開発のリアルな事例を知りたい方
開発したアプリケーションの概要
私たちが作っているのは、東京銀器などの日本の伝統工芸品を、AIの力で現代の海外市場に向けて再デザイン・提案するためのプロダクトです。
今回の主役は「海外消費者AI」機能。AIが生成した商品のデザインや価格について、「海外の富裕層から見てどう映るか?」を評価し、具体的なフィードバックと国別の購入確率を算出します。
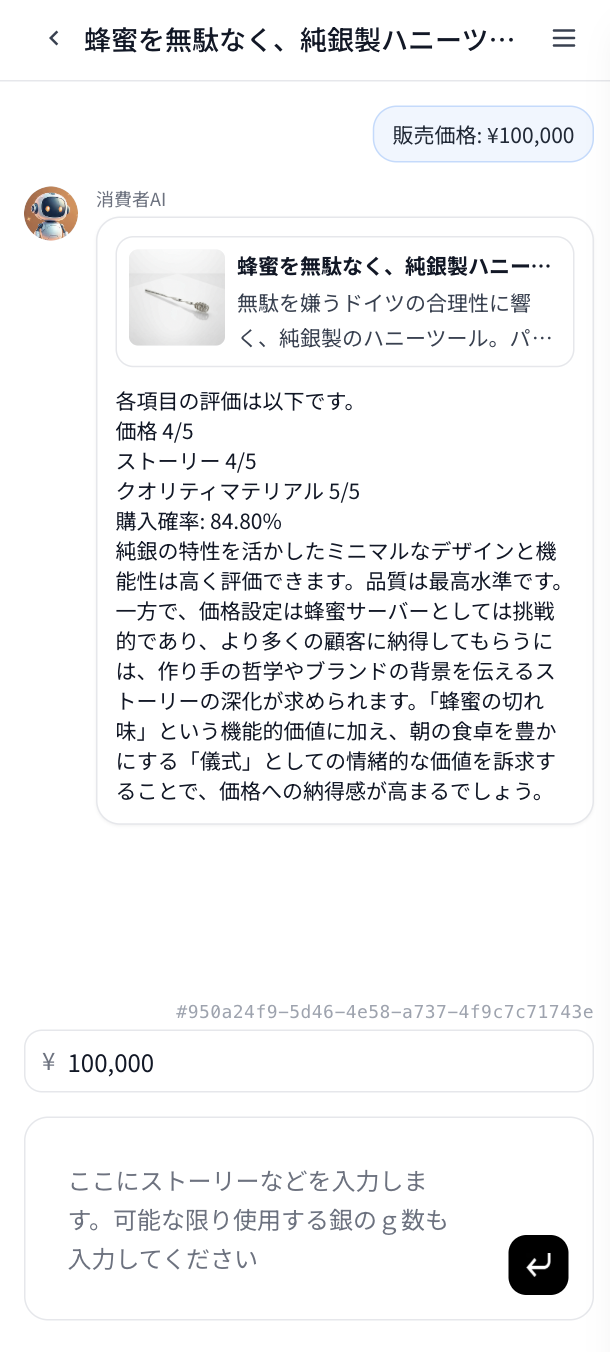
🚀 AIの信頼性を支える実装の裏側
1. 現場インタビューから生まれた、独自の購入確率予測アルゴリズム 📈
LLMに商品を評価させるだけでは、その評価が本当に市場の感覚と合っているのか、確信が持てません。私たちは「AIの言うこと」の信頼性を担保するため、オープンソースの情報だけに頼らない、独自のデータ収集から始めました。
Step 1: 泥臭く、リアルな一次データを収集する
まず、データサイエンティストと協力し、実際に日本の伝統工芸品を購入した海外の消費者へ街頭インタビューを実施しました。数十時間をかけて現場に張り込み、20名の貴重な生の声を集めることに成功しました。
インタビューの目的は、購入の動機を直接的かつ定量的に把握することです。そのために、以下のような構造化されたアンケートを設計しました。
インタビュー項目(実際のアンケートより抜粋)
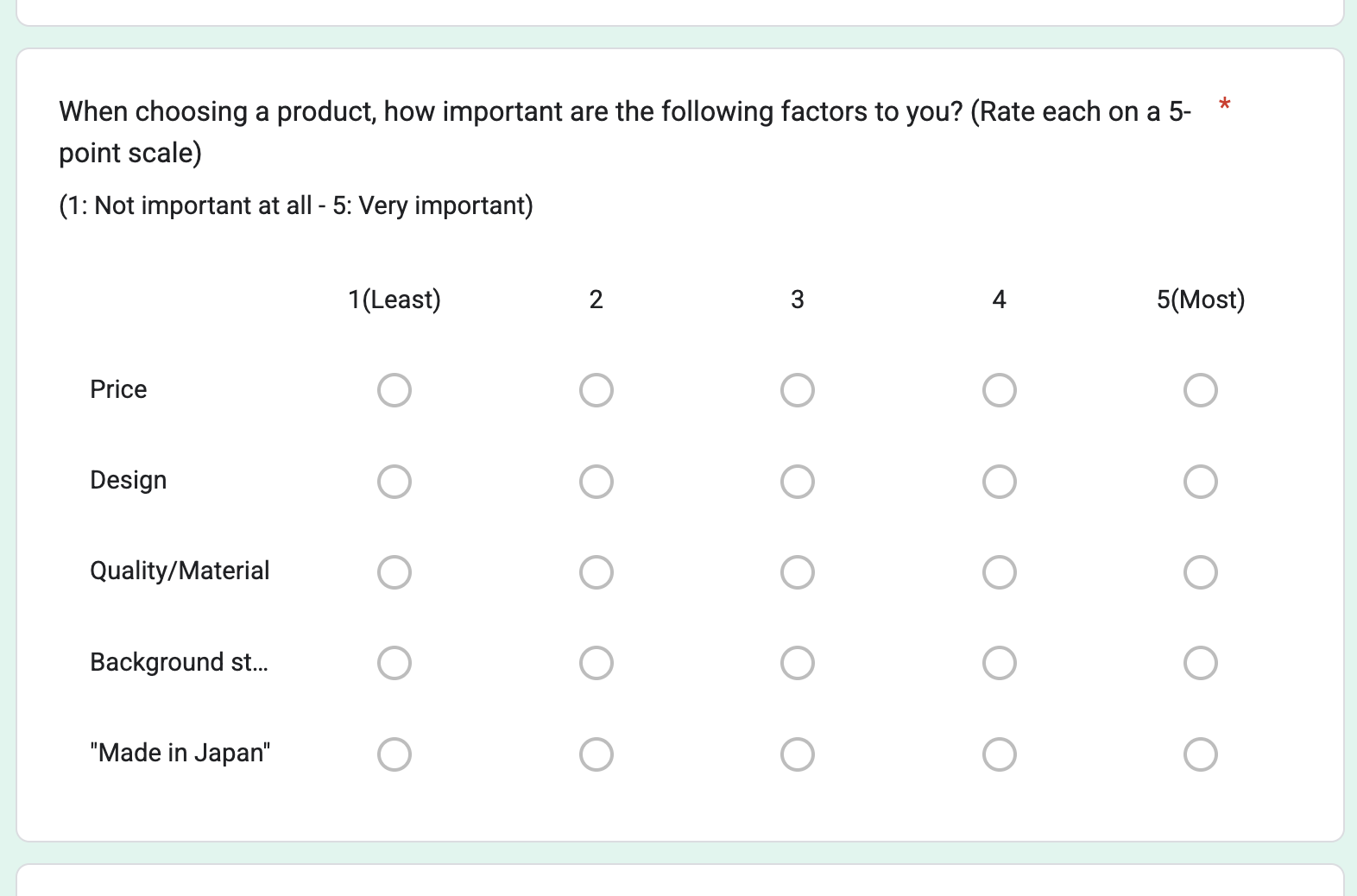
このアンケートの狙いは、単に感想を聞くことではありません。
どこの国の方がどの伝統工芸品を何の目的でいくらで購入し、実際にどう使うのか。
購入の決め手となった最も大きな理由などをインタビューし、購入の動機を直接的かつ定量的に把握し、「デザイン」が強みなのか、「ストーリー性」が響くのか、といったプロダクトの価値の源泉を特定するロジックを組んだ質問を設計しました。
これらの構造化された質問を通じて、定性的な感想をアルゴリズムが扱える定量的なデータへと変換する基盤を築きました。
Step 2: データを数値化し、アルゴリズムに落とし込む
この一次データと公開情報を基に、11カ国の市場特性(価格重視度、品質重視度など)を数値化。そして、単なるスコアの足し算ではなく、「ペナルティ(減点)方式」という独自のロジックで確率を計算するアルゴリズムを開発しました。
def calculate_probability(price_evaluation, quality_evaluation, story_evaluation, country="America"):
# 街頭インタビュー等から導き出した11カ国の市場特性データ
country_scores = {
"America": {"price": 0.5625, "quality": 0.9375, "story": 0.7500},
"Italian": {"price": 1.0000, "quality": 1.0000, "story": 0.7500},
# ... 他9カ国の詳細データ
}
S = country_scores.get(country, country_scores["America"])
# 各評価を正規化 (0-1)
price_norm = (price_evaluation - 1) / 4
quality_norm = (quality_evaluation - 1) / 4
story_norm = (story_evaluation - 1) / 4
# ペナルティベースの確率計算
penalty = (1 - price_norm) * S["price"] + \
(1 - quality_norm) * S["quality"] + \
(1 - story_norm) * S["story"]
P_B = max(0, 1 - penalty) # 確率がマイナスにならないように
return P_B * 100
このように、自分たちの足で稼いだデータがアルゴリズムの心臓部になっている点が、この機能の最大の特徴です。
2. AIに商品画像とともに評価させる 🚀
AIに商品の価格やストーリーのテキストだけではなく、画像と共に評価させるため、技術的にBase64形式のエンコードはメモリ使用量の増大やパフォーマンスの低下を招きます。
私たちは、フロントエンドにはGCS上の画像への安定URLだけを返し、バックエンドがそのURLを解釈して直接GCSから画像データをバイト形式でダウンロードするアーキテクチャを採用しました。
from google.cloud import storage
def download_asset_bytes(asset_url: str) -> bytes:
"""安定URLから直接GCSのオブジェクトをバイトデータとして取得"""
# asset_urlからオブジェクト名を解決 (省略)
object_name = resolve_object_name_from_url(asset_url)
client = storage.Client()
bucket = client.bucket(get_gcs_bucket_name())
blob = bucket.blob(object_name)
# Base64エンコードなしで直接バイトデータを取得!
data = blob.download_as_bytes()
return data
この設計によりBase64を完全に排除し、メモリ効率を大幅に改善しました。
3. Gemini 2.5 ProのStructured Outputで実現する鉄壁のJSON出力 🛡️
LLMからのレスポンスは「出力の揺らぎ」が悩みの種です。これを解決するため、Gemini 2.5 Proが持つStructured Output機能を最大限に活用し、厳密なJSONスキーマを定義しました。
# LLMに渡すレスポンスのスキーマ定義
def _response_schema() -> dict:
return {
"type": "object",
"properties": {
"scores": {
"type": "object",
"properties": {
"price": {"type": "integer", "minimum": 1, "maximum": 5},
# ... 他のスコア定義
},
"required": ["price", "story", "qualityMaterial"],
},
"comment": {"type": "string"},
},
"required": ["scores", "comment"],
"additionalProperties": False, # スキーマにないプロパティは許可しない
}
これにより、LLMは100%(現時点まで)このスキーマに準拠したJSONを返すようになり、バックエンドでの複雑なパースやバリデーション処理が不要になりました。
4. スケーラビリティの鍵!ステートレス設計の軽量API ☁️
将来的なスケールを容易にするため、APIはセッション管理を行わない完全なステートレスとして設計しました。リクエストのたびに、AIのペルソナ設定や過去の会話履歴をクライアントから送信します。
# FastAPIのエンドポイント
@router.post("/evaluate", response_model=DCResponse)
async def evaluate_stateless(request: DCRequest):
# このリクエストだけで評価が完結する
# データベースでセッション情報を引く必要はない
...
🎨 フロントエンドのUXを支える技術
1. 体感速度を上げる(Optimistic Update)
ユーザーがメッセージを送信した際、バックエンドからの応答を待たずに、即座にUIを更新します。これにより、ユーザーはネットワークの遅延を感じることなく、サクサクと対話を進められます。
const handleSendMessage = (message: string) => {
const userMessage: ChatMessage = { role: 'user', parts: [{ text: message }] };
const newHistory = [...history, userMessage];
// 1. まずUIを即座に更新する(楽観的更新)
setHistory(newHistory);
setIsLoading(true);
// 2. その後、バックエンドにリクエストを送信
evaluateProduct(newHistory)
.then(response => {
// 3. 成功したらレスポンスでUIを更新
setHistory([...newHistory, response.aiMessage]);
})
.catch(error => {
// 4. 失敗したらUIを元に戻す(ロールバック)
setHistory(history);
showErrorToast("エラーが発生しました");
})
.finally(() => setIsLoading(false));
};
2. ステートレスなバックエンドと協調する巧妙なセッション管理
バックエンドはステートレスですが、ユーザー体験としては会話の履歴が保存されてほしいもの。このギャップをフロントエンドが埋めます。Firestoreとの非同期通信で会話履歴を永続化し、サーバーに負荷をかけないアーキテクチャの恩恵を受けつつ、優れたUXを実現しています。
const syncSessionToBackend = useCallback(
async (history: ChatMessage[], price: number) => {
// ...
try {
// フロントエンドのデータをFirestoreに永続化
await upsertOverseasConsumerChatSession({ sessionId, messages: history, ... });
// ...
} catch (error) {
console.error("Failed to sync session:", error);
// 同期に失敗してもUIは動作し続ける
}
},
[currentProduct, activeSessionId]
);
📊 パフォーマンス
* レスポンス時間: 平均2-3秒(画像処理込み)
* メモリ効率: Base64回避により50%削減
* 信頼性: 一次データに基づく信頼性の高いアウトプット
そして、このプロジェクトの技術的イノベーションは、単一の技術ではなく、その組み合わせにあります。
1. データサイエンス: 一次データ収集から始まる独自の確率計算アルゴリズム
2. クラウド最適化: GCS直接アクセスによる圧倒的な効率化
3. AI/ML: Structured Outputによる厳密な出力制御
4. UX設計: 楽観的更新によるストレスフリーなUI
5. アーキテクチャ: ステートレス設計による高いスケーラビリティ
さいごに
今回は、「海外消費者AI」機能の裏側にある、バックエンドからフロントエンドにまたがる技術的な工夫をご紹介しました。
実装者として、当たり前のことをやっただけだが・・・と思いつつも、AIと対話してこのポイントはシェアすべきです!と後押ししてくれてこの記事を書き切ることができました🥹w
一つひとつの技術は既存のものかもしれませんが、それらを「信頼性」という課題解決のためにどう組み合わせ、システム全体としてどう設計するかがエンジニアリングの醍醐味だと改めて感じています。
この記事が、皆さんの開発のヒントになれば幸いです。
最後までお読みいただきありがとうございました!
Xでは、リアルタイムに開発現場のことも投稿しているのでよければチェックしてくださいー!