
*こちらの記事は、英語から日本語へ翻訳をしています。
English Original Text
GIFTech Craft × Data Science: Lessons from Building AI for a 400-Year Craft
Hello data scientists!
I’m Anshika Kankane, and I’ve been working as the data scientist behind the GIFTech JAPAN NEXT CRAFT project.
This has been one of the most unusual and eye-opening projects of my career—because I found myself building AI systems not for a typical tech product, but for a world rooted in centuries-old Japanese silversmithing traditions.
If you’re curious about other aspects of this project, I’ve linked related articles at the end.
For now, let me take you through the data science journey—what worked, what didn’t, and the lessons I wish someone had told me before I started.
Where It All Began: A Craft Without Digital Footprints
GIF Techcraft was created with a simple mission:
help a Tokyo-based master silversmith use AI not just as a tool, but as a creative partner.
On paper, the goals looked straightforward:
- Generate new product ideas
- Refine design variations
- Predict overseas buyer interest
In reality, I quickly learned something humbling.
The biggest challenge wasn’t model selection, RAG architecture, or system integration.
The real problem was the complete absence of usable data.
Traditional crafts rarely live online in structured, reliable digital form.
And global buyer preference data for a niche category like Japanese silverware?
Almost nonexistent.
The entire technical strategy had to be rebuilt around this single truth.
Phase 1: Suggestion AI — Inventing Ideas With No Real Data
My first task was to help the artisan explore fresh creative directions.
But how do you train a system to ideate when the domain itself barely has a digital trace?
When I searched online for references, what I found were fragments — maybe a product image, a product name, a vague mention of a technique — but never enough to build a meaningful knowledge base. No clarity on:
- which silversmithing technique was used
- whether the product was authentically Japanese
- what function the craft served
- what different global audiences valued in such pieces
Very quickly, it became obvious:
There wasn’t enough data to power even the simplest retrieval system, let alone a generative one.
And that’s how synthetic data became not just helpful — but necessary.
Why synthetic data was unavoidable
- No digital archives or datasets about Japanese silver techniques.
- Existing references lacked detail, authenticity, or reliability.
- No insights on what different countries look for when buying crafts.
- Interviews alone couldn’t scale into a training corpus.
- LLMs hallucinated heavily without context or grounding.
So, I built a carefully engineered synthetic knowledge corpus — but with one strict rule: every synthetic entry had to be validated by the craftsman himself. Nothing entered the system without cultural and technical approval.
Once validated, this corpus finally allowed us to build a functioning RAG pipeline powered by a vector database.
It became the backbone for generating new product concepts grounded in real craft principles.
If you’re curious about the detailed process, here’s a deeper breakdown:
https://qiita.com/GIFCat/items/cdfa2f161f7595d45175
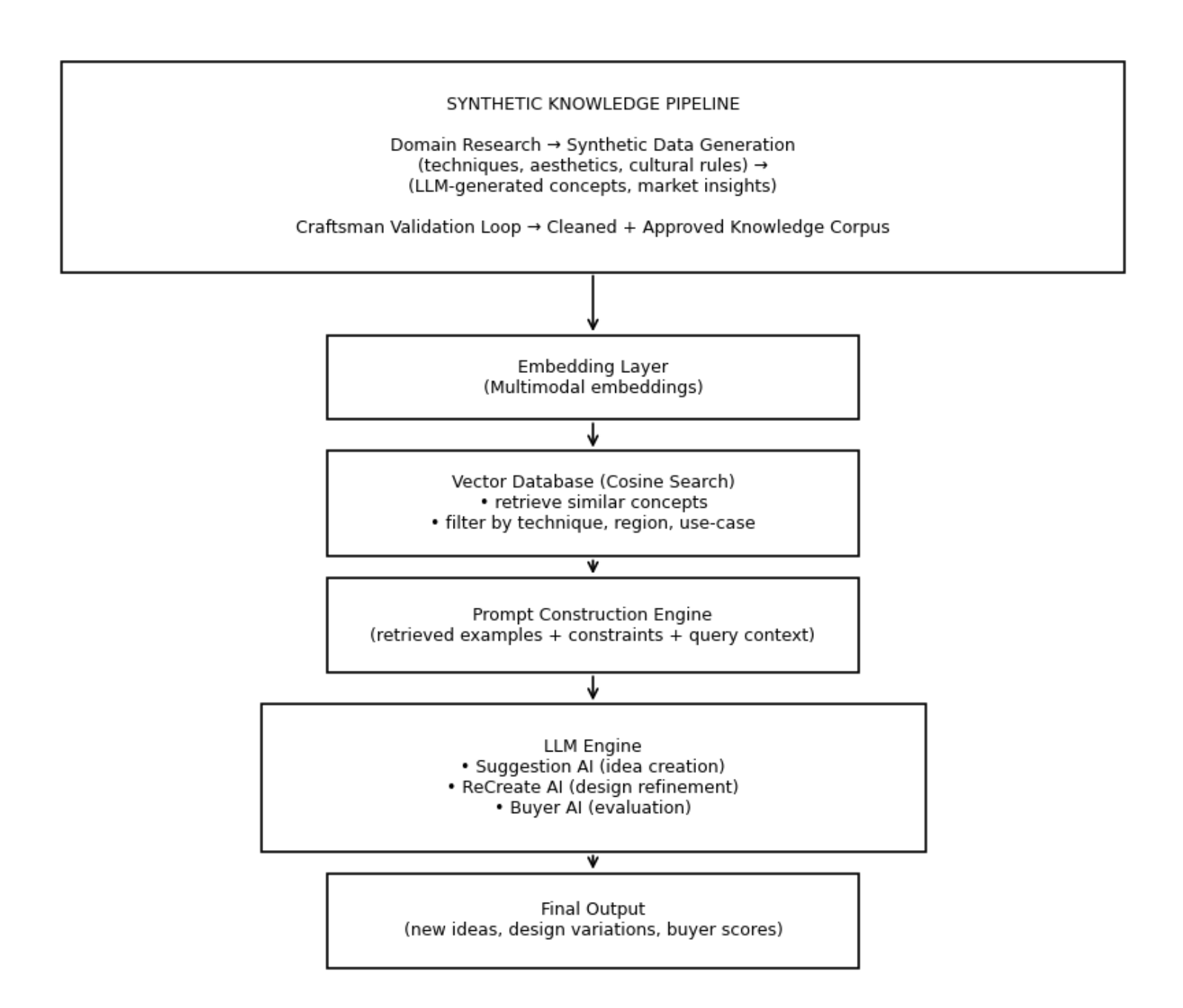
A High-Level Look at the GIFTechCraft Architecture
Before explaining how retrieval actually works, it helps to see how all components fit together.
Here’s the high-level system I designed, showing the flow from synthetic knowledge to final output:
This is the entire system in motion: synthetic data grounds everything, retrieval keeps the model honest, and different AI modules carry creativity, refinement, and buyer evaluation.
Why I Chose Gemini’s Multimodal Embedding Model
For the embedding stage, I needed something that could understand far more than text.
The synthetic knowledge corpus included:
- descriptions of metalworking techniques
- references to texture and surface finish
- cultural cues
- subtle design language
- visual motifs
A text-only embedding model would have failed to represent this richness.
So I chose Gemini’s multimodal embedding model, which let me encode both textual and visual semantics into a unified high-dimensional space.
For similarity search, I used cosine similarity — and it turned out to be the most stable choice for high-dimensional multimodal embeddings.
Cosine similarity:
- handles mixed visual-text embeddings elegantly
- avoids distortions caused by vector magnitude
- stayed consistent even with a relatively small dataset
- returned results that “felt” semantically aligned with the artisan’s intentions
In real usage, this meant the retrieval engine brought back the right kind of examples — designs that matched not only in words, but in aesthetic and cultural relevance.
How Retrieval Actually Works in Suggestion AI
With the architecture and embedding system in place, this is how Suggestion AI actually functioned:
- The craftsman selects a target customer segment.
- The system embeds the query and performs similarity search.
- The closest-matching synthetic examples are retrieved.
- These examples are appended strategically to the prompt (token budgeting became a daily puzzle).
- The LLM generates new product ideas grounded in training knowledge and the retrieved context.
Once we fine-tuned the prompt structure, the outputs began to consistently:
- match authentic silversmithing techniques
- reflect cultural sensibilities
- align with market preferences
- avoid hallucinations
This part almost felt magical — but only because the data groundwork was extremely deliberate.
Phase 2: ReCreate AI — Teaching AI to Respect an Artisan’s Aesthetic
Once ideas were generated, the next challenge was design refinement.
The craftsman wanted controlled variations — changes in shape, texture, surface finish — without losing the subtlety and calmness of traditional Japanese silverwork.
And subtlety is exactly where multimodal models struggle.
They tend to drift stylistically unless firmly guided.
Throughout this phase, I learned just how fragile multimodal prompting can be:
- Prompt order could completely shift the design language.
- Too much flexibility led to exaggerated transformations.
- Too much constraint flattened the creativity.
- Visual style cues had to be embedded gently to avoid overpowering tradition.
After many iterations, we built a prompt template that behaved like a safety rail — allowing controlled creativity, while respecting the essence of the craft.
It was the closest I’ve seen AI come to collaborating with a human craftsperson.
Phase 3: Overseas Buyer AI — When Synthetic Data Isn’t Enough
This phase shattered a common myth:
you cannot infer human behavior from synthetic data.
Buyer intent requires real signals.
So we conducted surveys with international visitors — both buyers and non-buyers. That blend was essential. We collected insights about:
- demographics
- motivations and hesitations
- how much design, story, material, or price mattered
- cultural differences in purchasing preferences
- discovery channels (store, guidebooks, social media)
Once cleaned and normalized, we built a model capable of:
- predicting purchase probability
- identifying what lowered the score
- generating actionable suggestions (e.g., “European buyers value story-based products more than Americans at this price range”)
Even here, the generative reasoning layer needed RAG grounding to avoid cultural generalization or misinterpretation.
Engineering Lessons I Learned the Hard Way
This project taught me far more about applied AI than any competition or traditional dataset ever could.
1. Data scarcity reshapes every technical decision
The real engineering was in constructing context, not selecting models.
2. RAG and prompt engineering matter as much as model choice
Tiny retrieval or prompt changes could swing the model output dramatically.
3. Synthetic data must be validated by domain experts
Otherwise, it becomes structured hallucination.
4. Human behavior cannot be synthesized
Prediction requires real, messy, diverse human data.
5. Traditional domains require multiple AI layers
We weren’t building “one model.”
We were building a conversation between:
- ideation
- refinement
- evaluation
And they needed each other to work.
Closing Thoughts
Working on GIFTechCraft reminded me that AI isn’t here to replace timeless craftsmanship — it’s here to extend it. Carefully, respectfully, and intelligently.
Even in a domain where datasets barely exist, and cultural rules are subtle and sacred, AI can still open meaningful new paths when you engineer:
- the right synthetic knowledge
- the right retrieval system
- the right prompts
- and the right human-in-the-loop validation
What we built wasn’t automation.
It was a partnership — between a craftsman and an AI system designed to understand, respect, and amplify his creative world.
For any data scientist stepping into a low-data domain, I hope this gives you clarity, caution, and confidence.
And believe me: the challenge never lies in the model.
The challenge is everything around the model.
▼ See what artisans created with this app ✨
こんにちは。
GIFTech JAPAN NEXT CRAFT プロジェクトでデータサイエンス部分を担当した Anshika Kankane です。
今回のプロジェクトは、私のキャリアの中でも特にユニークで、学びの多い経験でした。
なぜなら、私は「典型的なテック製品のAI開発」ではなく、400年以上続く日本の銀細工の世界(東京銀器)に、AIを導入するという、まったく異なる領域に飛び込んだからです。
この記事では、私が実際に直面したデータの課題、技術的な工夫、そしてデータサイエンティストとして得た知見をまとめています。
最初の壁:デジタル化されていない世界
GIF Techcraft プロジェクトのミッションはとてもシンプルでした。
AIを「道具」ではなく「創造のパートナー」として、東京銀器の職人を支援する。
プロジェクトで目指したのは以下の3つ:
- 新しいプロダクトアイデアの生成
- デザインバリエーションの提案
- 海外バイヤーの購買傾向予測
しかし、すぐに気づきました。
最大の課題はモデル選択でもRAG構築でもなく…
そもそも使えるデータが存在しないことでした。
伝統工芸の世界は、ほとんどデジタル化されていません。
さらに、ニッチな銀細工の海外購買データなんてほぼゼロ。
ここから、私たちの技術戦略の全てが変わっていきます。
Phase 1: Suggestion AI — データゼロの状態からアイデア生成を行う
最初の課題は、職人が新しい方向性を探索できるように、AIからアイデアを提案する仕組みをつくること。
しかし、ネット上で集められる情報は断片的で、こんな状態でした:
- 写真だけ
- 商品名だけ
- 技法名が曖昧
- 本当に日本の銀器なのか不明
- 国ごとのデザイン嗜好に関する情報は皆無
つまり…
最も簡単な検索システムすら成立しないほど、データが足りない。
そこで、避けて通れなかったのが 合成データ(synthetic data) の構築でした。
なぜ合成データが必須だったのか
- 日本の銀器に関する体系的なデータセットが存在しない
- Web情報は浅く、真偽も不明瞭
- 国別の購買嗜好を知る手がかりが少なすぎる
- インタビュー情報だけではスケールしない
- 文脈が欠けると LLM は簡単に幻覚(hallucination)を起こす
そこで私は、技法・素材・文化・市場情報を含む合成知識コーパスを構築。
ただし大事にしたのは、
合成データを職人が確認し、文化的・技術的に正しいと承認するプロセス。
この「人間によるバリデーション」を挟んだことで、初めてAIが信頼できる出力を生成できるようになりました。
詳細プロセスはこちらにまとめています:
GIF Techcraft のアーキテクチャ概要
合成データ → ベクトル検索 → プロンプト構築 → 出力
という流れを図解すると、以下のようになります。
これは、合成データが AI を支え、検索が文脈を補強し、
複数の AI モジュールが創造・改良・評価を担う流れを示しています。
Gemini マルチモーダル埋め込みを採用した理由
合成データには、以下のような情報が混在していました:
- 金属加工技法の説明
- 表面の質感や仕上げの特徴
- 文化的文脈
- ストーリー性
- 写真の視覚的特徴
テキストだけの埋め込みでは限界があるため、
私は Gemini のマルチモーダル埋め込みモデル を採用しました。
さらに、類似検索には コサイン類似度 を使用しました。
その理由は:
- 高次元のマルチモーダルベクトルと相性が良い
- ベクトルの長さに左右されず、方向性に基づく類似度がとれる
- 小規模データセットでも安定して動作
- デザイン的・文化的に「近い」ものを取得できた
これにより、検索精度は圧倒的に高まりました。
Suggestion AI の実際の仕組み
アーキテクチャと埋め込みが整ったら、Suggestion AI は次のように動きます。
- 職人がターゲット国・客層を選ぶ
- クエリを埋め込みベクトル化
- ベクトルDBから最も近い合成データを検索
- 取得データをプロンプトに追加(トークン制限との戦い…)
- LLM が文脈を理解した状態で新しいアイデアを生成
この仕組みがうまく回り出すと、
- 技法の誤解が減り
- 文化的背景に沿った提案が可能になり
- 市場嗜好に合うアイデアも出せる
まさに「AIの創造性が正しく導かれた瞬間」でした。
Phase 2: ReCreate AI — 職人の美意識を壊さないデザイン生成
次は、アイデアを視覚化・微調整するステップです。
東京銀器(特に今回のパートナー工房である日伸貴金属のデザイン)はとても繊細で控えめな美が特徴。
しかし、マルチモーダルモデルは油断すると「派手」「作りすぎ」になりやすい。
そこで学んだのは、プロンプトの繊細さ。
- プロンプトの順番が変わるだけで仕上がりが激変
- 制約が弱いとデザインが暴走
- 制約が強いと均一でつまらない
- 「美の方向」をやさしく示す必要がある
何十回もの試行錯誤の結果、
職人の美意識を壊さずに、創造性を拡張するテンプレートが完成しました。
Phase 3: Overseas Buyer AI — 合成データでは代替できない「人の行動」
最後の課題は「海外の人が買うかどうか?」を予測すること。
ここで大きな前提が崩れました。
人間の購買行動は、合成データでは絶対につくれない。
そこで私たちは、実際の海外観光客を対象にアンケート調査を実施しました。
購買・非購買の両方を聞くことで、よりリアルなパターンが見えてきます。
例えば:
- デザイン重視? 価格重視?
- 物語性をどれだけ重要視するか
- 国ごとに違う価値観
- 「なぜ買わないのか?」という否定情報
- SNS・店舗・旅行ガイドなどの認知経路
これを正規化・特徴量整理し、スコアモデルを構築。
- 購買確率
- マイナス要因
- 改善の方向性(例:欧州はストーリーを強く求める)
などを返す仕組みを作りました。
ここでも、生成AI部分は RAG で文脈補強しないと文化的誤解を起こすため、慎重さが必要でした。
詳細はこちらにまとめています:
エンジニアリングで学んだ5つの教訓
1. データ不足は全ての判断を変える
このプロジェクトは、モデル選択より「文脈づくり」が本体だった。
2. RAG とプロンプトエンジニアリングはモデル選択と同じくらい重要
少しの調整で出力が大きく変わる。
3. 合成データは専門家の承認なしでは意味がない
専門知識のないAIは自信満々に間違える。
4. 人間行動の予測は絶対にリアルデータが必要
購買行動は合成では再現できない。
5. 伝統領域では「単一AIモデル」ではなく「複合AIレイヤー」が必要
創造 → 可視化 → 評価
の順番がすべて重要。
最後に
GIF Techcraft を通して、私は AI が伝統工芸を「置き換える」のではなく、
本質を尊重しながら拡張する存在になれることを実感しました。
データが少なくても、文化的な制約が多くても、
正しいデータ設計・検索・プロンプト構築・人間の知恵を組み合わせれば、
AI は職人にとって頼れるパートナーになり得る。
そしてこれは、低データ環境に挑む全てのデータサイエンティストに伝えたいことです。
本当の課題は「モデルそのもの」ではなく、
その周りをどう設計するか。
これが、400年続く工芸の世界でAIを開発して得た最大の教訓でした。
▼ 職人がこのアプリで創作した商品はこちらからチェックできます✨
