TensorFlow Object Detection APIで教師データを作るためのツールlabelImgと使い方とTFRecordフォーマットへの変換方法の紹介です。
「Preparing Inputs」を参考にしています。
2019/8/29追記:**VoTTというアノテーションツールは非常に良く、そちらの方がおすすめ。**TFRecord形式で直接出力でき、インストールもお手軽です。簡単すぎて記事に書く気もしません。Windowsでしか試しておらず、MacやLinuxでも簡単かはわからないです。
関連記事
- TensorFlow Object Detection APIをUbuntuにインストール
- Object Detection APIを使って堀川君を検知
- Object Detection APIのsaved_model出力
- Access Tokenを取得してGoogle Cloud MLでオンライン予測
環境
| 種類 | バージョン | 内容 |
|---|---|---|
| OS | Ubuntu18.04.01 LTS | Windows8.1からOracle VirtualBoxを使って動かしています |
| Python | 3.5.6 | Python3.5.6をpyenvで動かしています。最新の3.7.xを使わなかったのは、深い意味はなく、面倒だったからです。 |
| labelImg | 1.8.1 | 2019/1/4時点で1.8.1が最新でした。 |
手順
1. labelImgインストール
1.1. pyqt5インストール
apt-getでpyqt5をインストールします。
sudo apt-get install pyqt5-dev-tools
1.2. venv仮想環境作成
"label"という名前のvenv仮想環境作成し有効化。pipを最新化。
python -m venv label
source ~/Documents/python/venv/label/bin/activate
pip install --upgrade pip
1.3. labelImgのクローン
GitHubからlabelImgをクローン。
git clone https://github.com/tzutalin/labelImg.git
1.4. Pythonライブラリインストール
Pythonの必要なライブラリをインストールし、コンパイルも実行。
cd labelImg
pip install -r requirements/requirements-linux-python3.txt
make qt5py3
2. 画像アノテーション
画像をカメラで集めるにしてもネット上から集めるにしても、アノテーション前に以下の2点は済ませておきましょう。
- 画像サイズ(解像度)の縮小:画像サイズが大きいと、TensorFlow Object Detection APIでは消費メモリが大きくて全然終わりません。リサイズして再実行するにしても、アノテーションもやり直す必要があるので注意が必要です。100kb程度にしています。
- 画像向きの調整:縦横の向きは調整しておきましょう。
2.1. 準備
こんなフォルダ構成にしました。今回は、Object Detection APIに付属しているプログラムをそのまま使っているためフォルダ名・階層やファイル名に自由がきかないことも多いです。そのため、一見するとフォルダ構成が冗長的です。
.
├── data
│ ├── label_map.pbtxt
└── images
├── JPEGImages
│ └── JPEGImages
│ ├── <画像ファイル>
└── VOC2007
├── Annotations
│ ├── <アノテーションファイル>
└── ImageSets
└── Main
├── aeroplane_train.txt
└── aeroplane_val.txt
2.2. プログラム起動
labelImg.pyを起動します。
python labelImg.py
"Open Dir"で画像ファイルが入っているフォルダ(「2.1. 準備」の"JPEGImages"フォルダ)を選択して、"Change Save Dir"でアノテーションファイルを入れるフォルダ("Annotations"フォルダ)を選択します。
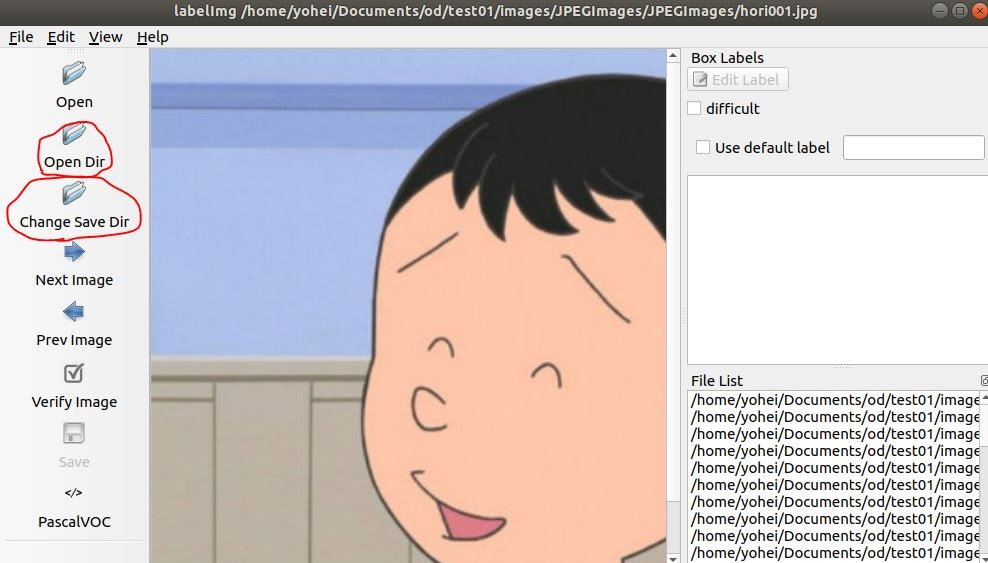
あとは、地味にアノテーションをしていきます。効率化のためにShortcut Keyを使いましょう。

2.3. ラベルテキスト作成
models/research/object_detection/data/pascal_label_map.pbtxtを参考にラベルテキストファイル"label_map.pbtxt"を作ります。今回はラベルの種類は1つだけです。"data"フォルダ直下に格納しています。
item {
id: 1
name: 'horikawa'
}
2.4. リストファイル作成
"Main"フォルダ直下に訓練用のファイル一覧の"aeroplane_train.txt"と評価用の"aeroplane_val.txt"を作成します。
以下は少しだけの例ですが、テキストファイル内でアノテーションファイルの拡張子を除外したファイル名を羅列しています。
hori031
hori032
2.5. TFRecord変換
TFRecord変換のために、TendorFlow Object Detection APIに付属しているプログラムを実行します。前処理として、環境変数の設定とvenv仮想環境の有効化をします。
# From tensorflow/models/research/
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
source ~/Documents/python/venv/clml-od/bin/activate
訓練データのTFRecord変換は以下のように実行しています。これで"output_path"の/home/yohei/Documents/od/test01/data/train.recordが作成されています。
# From tensorflow/models/research/
$ python object_detection/dataset_tools/create_pascal_tf_record.py \
--data_dir=/home/yohei/Documents/od/test01/images \
--year=VOC2007 \
--output_path=/home/yohei/Documents/od/test01/data/train.record \
--label_map_path=/home/yohei/Documents/od/test01/data/label_map.pbtxt \
/home/yohei/Documents/python/models/research/object_detection/utils/dataset_util.py:75: FutureWarning: The behavior of this method will change in future versions. Use specific 'len(elem)' or 'elem is not None' test instead.
if not xml:
警告が出たが無視しています(調べてもいません)。
評価用も似たようなコマンドオプションで実行します。
# From tensorflow/models/research/
$ python object_detection/dataset_tools/create_pascal_tf_record.py \
--data_dir=/home/yohei/Documents/od/test01/images \
--set=val \
--year=VOC2007 \
--output_path=/home/yohei/Documents/od/test01/data/eval.record \
--label_map_path=/home/yohei/Documents/od/test01/data/label_map.pbtxt \
/home/yohei/Documents/python/models/research/object_detection/utils/dataset_util.py:75: FutureWarning: The behavior of this method will change in future versions. Use specific 'len(elem)' or 'elem is not None' test instead.
if not xml:
コマンドオプション
- data_dir: インプット元データのディレクトリ
- year: 今回は特に意味をなさないが必須なので"VOC2007"を入れておく
- output_path: 作成するTFRecordのパスとファイル名
- labep_map_path: ラベルファイル
- set: 訓練/評価ファイルを識別。評価ファイルは"val"を指定。訓練時はデフォルト値の"train"を使うので指定していない。