はじめに
この記事では機械学習における各種の正則化手法の概要とシンプルな問題設定で使用してみた結果をまとめています。
記事対象者として、
- 正則化手法としてどのようなものがあるかざっと見てみたい人
- どの正則化手法を採用するか検討してる人
- 機械学習初学者
などを想定してます。
使用したコードは以下のJupyter Notebookに全て載せています。pytorchを用いた実装。
https://colab.research.google.com/drive/1Po5OsyBSxaVECpgMBoTiUfSvx1kAWe4j?usp=sharing
正則化(Normalization)とは
ニューラルネットを学習する際に訓練データに対する性能(損失関数、分類正答率)が良い一方、テストデータに対する評価指標が悪いことを過学習と呼ぶ。機械学習において過学習を抑制し、訓練データに対する性能とテストデータに対する性能の乖離を小さくすることで汎化性能を高めるための方法は正則化手法と呼ばれる。
本記事で紹介する正則化手法
- L2正則化 (L2 normalization)
- ドロップアウト (Dropout)
- ラベル平滑化 (Label smoothing)
- バッチ正則化 (Batch normalization)
各手法の概要とCNNによるCIFAR-10画像分類タスクに対して各種正則化手法を導入してみた結果を紹介する。
性能評価
CNNによるCIFAR-10画像分類モデルの学習を行う。

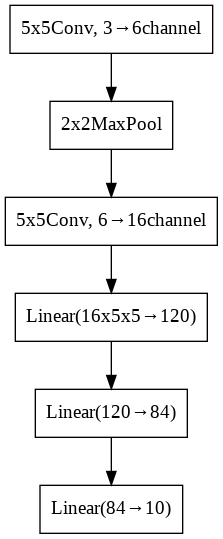
正則化手法無し
概要
毎Epoch終了時に検証用データを用いて性能を評価し、最も性能が良かったモデルを採用する。
使用結果
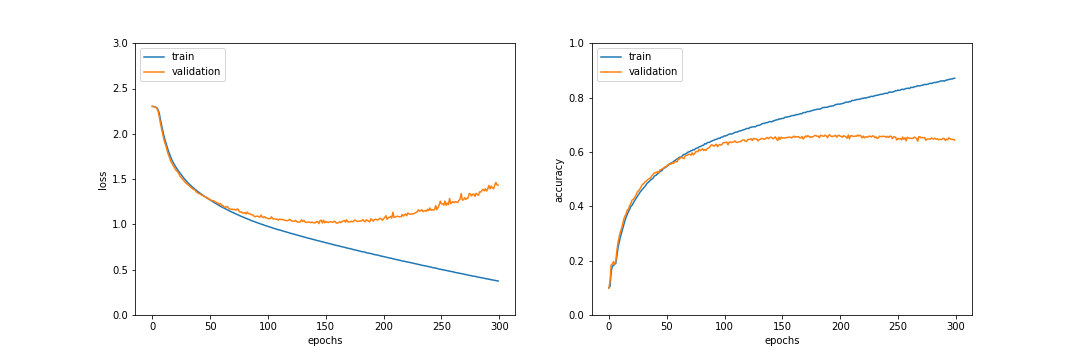
191epochで検証データでの正答率が最大になり、テストデータでの正答率は64.4%であった。
L2正則化 (L2 normalization)
概要
各層における重みパラメータの2乗を損失関数に加算する。線形回帰問題などでよく用いられるが今回扱うような多層ニューラルネットの正則化ではあまり使われていない印象。
参考: https://toeming.hatenablog.com/entry/2020/04/03/000925
使用結果
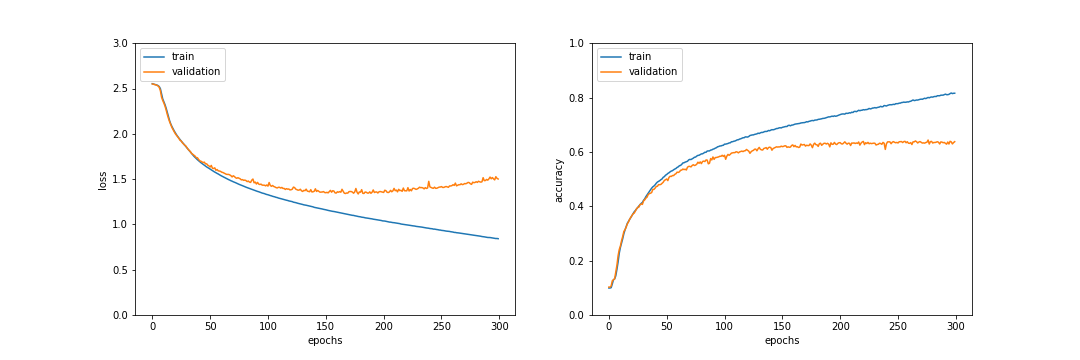
276epochで検証データでの正答率が最大になり、テストデータでの正答率は63.9%であった。正則化無しと比較すると訓練データと検証データの乖離が小さく過学習が抑制されているのがわかるが、テストデータにおける正答率は0.5%下がってしまった。
ドロップアウト (Dropout)
概要
一定割合の前方伝播を消去する (0にする)。
参考: https://qiita.com/shu_marubo/items/70b20c3a6c172aaeb8de
使用結果
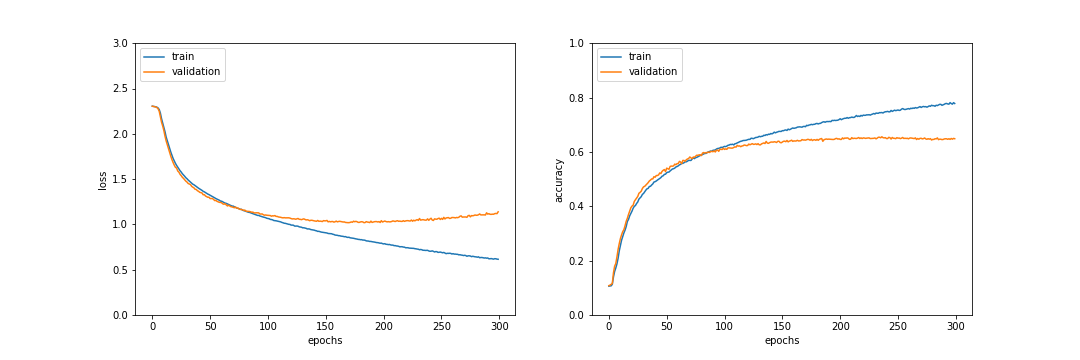
2番目の全結合層の前方伝播の20%をドロップアウトした結果、236epochでテストデータ正解率64.9%となった。正答率は0.5%ほどの改善であり、過学習が抑制されている。
ラベル平滑化(Label Smoothing)
概要
多クラス分類において訓練データの正解出力として与えるone-hotベクトルに変更を加え、正解ラベルと不正解ラベルの差を少し緩和する。
参考: https://build-medical-ai.com/2021/02/21/label-smoothing%EF%BC%88%E3%83%A9%E3%83%99%E3%83%AB%E3%82%B9%E3%83%A0%E3%83%BC%E3%82%B8%E3%83%B3%E3%82%B0%EF%BC%89%E3%82%92pytorch%E3%81%A7%E5%AE%9F%E8%A3%85%E3%81%99%E3%82%8B/
使用結果
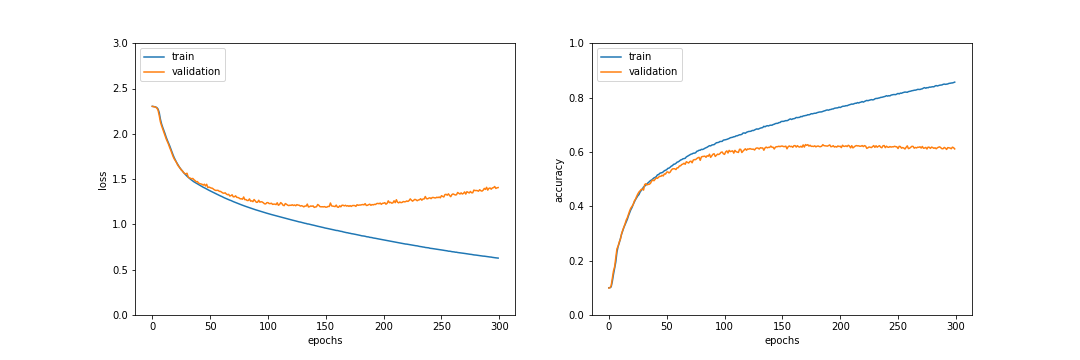
eps=0.03として学習を行なった結果、170epochでテストデータ正答率63.0%となり、改善率は-1.4%となった。今回の検証では過学習の抑制は確認できなかった。epsの設定をもう少し大きくすると変わるかも知れない。
バッチ正則化 (Batch normalization)
概要
前方伝播の際に各ノード出力のバッチ分布が平均0分散1になるように正規化を行う。
参考: https://yaakublog.com/batch-normalization
使用結果
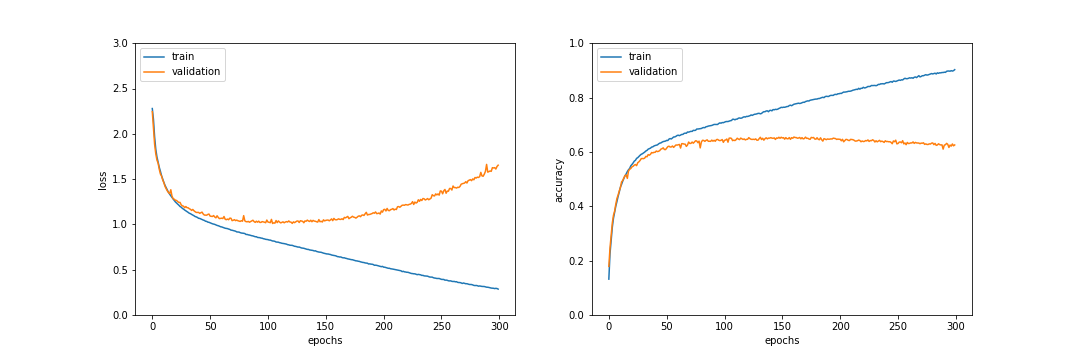
2つの畳み込み層の後にバッチ正則化層を入れ学習を行なった。236epochでテストデータ正答率64.9%となり、改善率は0.5%ほどであった。また、0~50epochの学習初期では学習が比較的速く進んでいることが確認できた。
まとめ
今回の問題設定ではドロップアウト、バッチ正則化により汎化性能の改善が見られた。多層ニューラルネットの正則化を行う場合はまずこれらを試すと良さそうだなと感じた。