この記事はエーピーコミュニケーションズ Advent Calendar 201823日目の記事になります。
はじめに
弊社では最近まで社内研修でKubernetesを勉強しており、その中でKubernetesの監視ってどうやるんだろうねということが気になりました。調べてみると、Prometheus, Datadogといったアプリケーションの名前や使い方は色々と出てきますが、そもそも何を監視するのだろうか、これまでの監視の観点と何が違うのか、といった基本的なことはあまり出てこないように見えました。
そこで、コンテナやKubernetesを監視する際の考え方や気をつけること、それを踏まえてどう設定するかを調べ、まとめたいと思いこの記事を書きました。内容としてはDatadog公式ページの和訳に加えて、幾つか追加情報を乗せただけですが、Kubernetesの監視におけるポイントを確認する上でも読んでいただければと思います。
また解釈が異なる点などありましたら是非教えていただければ幸いです。
Kubernetesとシステム監視
Kubernetesによって構築されたシステムを安定的に稼働させるには、クラスター上にデプロイしたアプリケーションやコンテナだけでなく、Kubernetesそのものの監視も必須になります。
監視する際に必要となる観点は、コンテナ監視をする際に必要となる観点に加え、Kubernetesを監視することでさらに追加されます。コンテナ監視のポイントはこちらのページで紹介されてますが、ざっと以下のような点がポイントになります。
- ホストやメトリクスの数が爆発的に増加し、またそれらの変化も急速に起こる。これによりシステムの複雑さが増し、運用の負荷も増加する。
- これまでのホスト中心の監視では複雑なシステムで何が起こっているかを明らかにするのが困難になるため、監視対象をレイヤーごとに分けるのでなく、すべてのレイヤーを一括に監視することでシステムを包括的に監視することができる。またその際はタグ付けをすることでより効率的に監視できる。
KubernetesはPodなどの基本オブジェクトやReplicaSetなどのControllerによってシステムの抽象化を促進するため、システムの包括的な監視を助ける面もあります。
伝統的なシステムの監視との違い
Kubernetesを監視する際、これまでのオンプレ・VMで構築されたシステムを監視するのとは大きく異なる点が幾つかあります。記事内では大きく4つの違いを挙げています。
タグとラベルが必須
コンテナ以前の監視システムでも、効率よく監視を行うため、メトリクスや監視対象に対してタグ付け・ラベル付けを行います。そのような目印を付けることで監視対象やメトリクスのグループ化をし、インフラ全体のパフォーマンス推移の監視や問題点の探索が容易になるためです。
コンテナ、Kubernetesを導入したシステムでは、タグやラベルの意味合いが大きく変わり、コンテナ・Podを判別する「唯一の手段」となります。Kubernetesではデプロイされたコンテナを、クラスターのリソース等を見て適切な場所にデプロイしてくれるのが強みですが、デプロイされたコンテナがどこに存在するかを判断するのが難しくなってしまうことがあるからです。
特にユーザーがラベルを独自に付けることで、あらゆる観点からコンテナによるインフラの監視をすることが可能になります。
ラベルの例
* フロントエンド/バックエンド
* アプリケーションごと
* 環境ごと(開発環境、本番環境など)
* チームごと
* バージョンごと
ユーザー独自のラベル付けをすることで、異なるレイヤーにまたがって起こるイベントやメトリクスを細かく監視することができます。
またラベリングする際のポイントとして、ロジカルで簡単に理解できるスキーマを定義すること、そして簡潔なラベルを作成することをあげています。ここでいうロジカルとはフィジカルと対比的な意味で使われており、インフラの物理的な部分(CPUやメモリなど)に対して論理的な部分(ここではnamespaceやreplicatio controllerなど)を指しています。また簡潔なラベルは、複雑な名前をつけることでわかりにくくなってしまうことを避けることを指していると考えられます。
監視対象のコンポーネントが増加する
ホスト中心のインフラシステムでは、「アプリケーション」と「稼働中のホスト」という2つのレイヤーを監視すればよかったですが、コンテナはそれら2つの間に新たな層として存在し、またKubernetesはさらに上のレイヤーとして存在します。つまり従来と比べて2つの監視すべきレイヤーが追加されるということです。
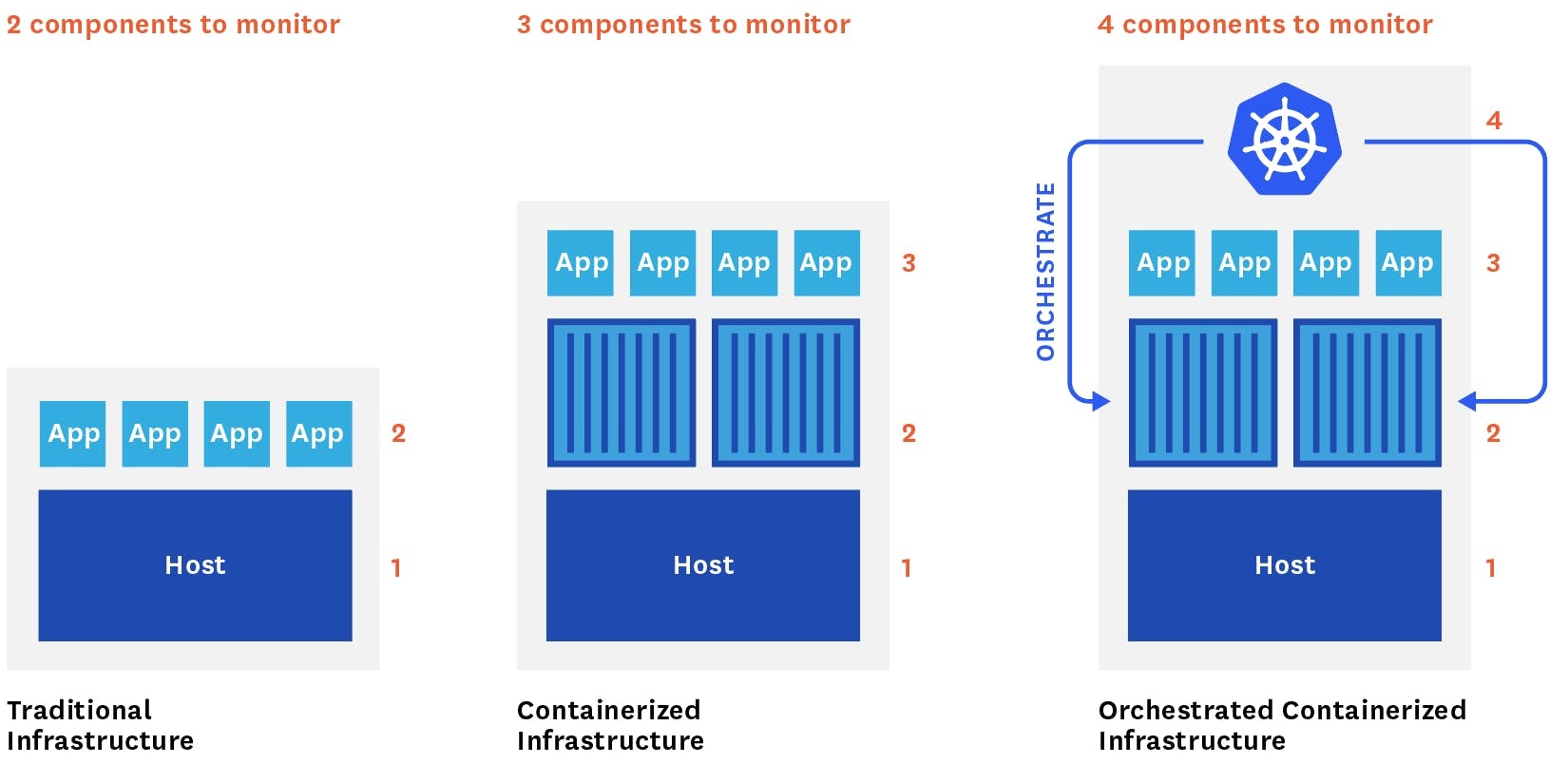
さらにコンテナの導入による監視の問題点でも紹介されているように、ホストやメトリクスが急激に増加することもあり、従来のシステムと比べて監視対象が大幅に増加します。
常に動くアプリを追跡する必要性
上でも少し書きましたが、Kubernetesは自動でコンテナのスケジューリングを行うことが強みですが、一方でユーザーが操作できる範囲が限定的であり、実際に稼働しているアプリケーションを追跡することが難しくなってしまいます。
これを解決する方法として、Service Discoveryを用いる監視ツールを使用することを挙げています。これによりコンテナやPodの設定変更を検知し、収集するメトリクスを自動で最適化することで、インフラが拡張したり異常を抱えたりホストをまたいで移動したりしても継続して監視し続けることができるようになります。そのようなツールの代表が、DatadogでありPrometheusであると言えるでしょう。
オンプレからマルチクラウドまで様々な環境のクラスターに最適化する
Kubernetes 1.3から、様々な環境をまたいでクラスターを作成しアプリケーションをデプロイできるようになりました。これによって複数の環境の中から最適な環境に対してアプリをデプロイできるようになり、また単一のプロバイダによる単一障害点を回避できるようになりました。
しかし一方で監視の面では、複数のインフラ環境からメトリクスを収集することは簡便になっているにもかかわらず、何らかの問題を発生する可能性があると述べています。そのため、マルチクラウド環境やオンプレとクラウドが混在するようなインフラ構成の場合は注意が必要です。
例えば、マルチクラウド環境でのKubernetes Best Practiceを紹介するこちらの記事では、「アプリケーションがそれぞれ異なる環境で稼働することがあるため、ノイズを切り離しアプリケーションインスタンスに集中する方法が必要である。そのためメトリクス、状態、イベントがアプリケーションと紐付いている必要がある」と記述しています。
ここまでで、従来のシステム監視とコンテナ・Kubernetesで構成されたシステムの監視との違いが整理されました。次章では実際にどのようなメトリクスを収集するべきかが説明されています。
重要な監視対象メトリクス
この章ではまずHeapsterについての紹介がされていますが、Kubernetes 1.13からHeapsterはRetired扱いとなるため、ここでは触れません。
ここでは幾つかのカテゴリに分けながら説明していきます。
Pod deployment
Kubernetesが適切に動いているかを判断するために、まず最初に見るのがPod deploymentでしょう。Deploymentを開始する時、Kubernetesはまずアプリケーションを走らせるために要求されたpod数を決定し、そして必要な数のpodをデプロイします。この時新しいPodが立ち上がり、現在稼働中(current)のPodとして計算されます。しかしcurrentのPodは必ずしもすぐに利用可能な状態(available)とは限りません。
ユーザーがPodをデプロイする時、一部のPodは待機状態のままにしておきたい場合があります。記事内ではJenkinsを例として挙げ、JenkinsのslaveがPodにあり、起動までの間はPodをunavailableな状態にしておきたいことがある、と説明しています。
ユーザはPodSpecなどを利用することでPodの立ち上がる個数やタイミングを制御することが可能であり、ユーザの望む個数のPod(desired pod)を立ち上げることが可能です。そのため、ユーザはavailableな状態のPodとdesiredなPodの数が常に等しいことを監視するべきだと述べます。
また、Podの状態を確実に知りたければreadiness checkを利用する方がより良い方法だとも述べています。
稼働中のPod
上記のcurrent podと対応します。現在稼働中のPodの数を監視し、インフラ全体の動きを監視します。またPodの稼働数とリソースへの影響との関係性を理解するために、Running PodとResource utilizationとのメトリクスを関係付けるべきだと述べています。
リソース利用量
リソース監視をすることで、クラスターとアプリケーションが健全な状態かを確認できます。ここではリソースに関する様々なメトリクス(CPU、メモリ、ディスクI/O、ネットワーク等)の監視について紹介しています。
例えばNodeのCPU・メモリのキャパシティについてはkube-state-metricsの利用を推奨しています。kube-state-metricsはKubernetes APIをlistenしてオブジェクトの状態に関するメトリクス(deploymentやnode, podなど)を生成します。現在は20種類のオブジェクトに対して使用することができ、各オブジェクトの個数や状態などをメトリクスとして監視できます。
またリソース監視の注意点として、実際のリソース使用率ではなく、ノード上にある各コンテナの最小要求リソース量の合計を監視すべきと述べています。その理由として、NodeのLimit(上限)とコンテナのrequest(最低限必要な量)との関係を述べています。あるノード上に存在するコンテナのrequestの合計がNodeの上限を超えなければ、当然コンテナは正常に稼動します。しかし、もしコンテナがNode上の利用可能なリソースを100%使用していても、Kubernetesは別のPodをNodeにデプロイするような余地を作ることができます。Kubernetesはシンプルに既存のPodの利用可能なリソース量を低下させ、新しいPodをデプロイできるようにします。これはすべてのコンテナの最低限必要なリソース量を満たしている限り続きます。そのため、Node上のrequest総量がそのNodeのlimitを超えていないかを確認することは、単純にCPUやメモリの使用量を監視するよりずっと大事なことなのです。
コンテナのヘルスチェック
Kubernetes標準のメトリクスでアプリケーションのヘルスチェックもできます。ヘルスチェックにはliveness probeとreadiness probeの2種類を利用します。
Liveness probeはそのアプリケーションが利用できない状態、デッドロックな状態でないかをチェックしています。Liveness probeが失敗している場合はkubeletが該当のコンテナを殺し、再起動させます。
Readiness probeはトラフィックを受け取れる状態かをチェックします。Readiness probeが失敗している場合はエンドポイントコントローラがPodのIPアドレスを除き、該当するコンテナにトラフィックが流れないようにします。
コンテナ本来のメトリクスで監視する
ここまでKubernetesのメトリクスに関する話がメインでしたが、この章ではコンテナメトリクスを監視する必要性について説明しています。その理由として、Kubernetesとコンテナとで同様の監視項目を見ているとしても、その値が異なる場合があるからです。Kubernetesはメトリクスをユーザーに伝える際にはcAdvisorではなくheapsterなどを利用します。そしてheapsterではKubernetesメトリクスを集める頻度がcAdvisorとは異なり、そのために本来の値との不一致を起こすことがあります。この結果、Kubernetesのメトリクス値とコンテナのメトリクス値との間に違いが生じることがあるのです。
アプリケーション特有のメトリクス
Kubernetesでできたシステムを正確に監視するためには、Kubernetesやコンテナなどのリソースメトリクスとアプリケーションの挙動とを関連づけることが推奨されています。アプリケーションによって監視すべきメトリクスは変わるでしょうが、スループット、レイテンシ、エラーに関するメトリクスは、様々なアプリケーションに共通して監視すべきメトリクスに含まれます。ここではMySQLとNginxの例を紹介した記事へのリンクを載せておきます。はそちらをご覧ください。
イベントと紐付ける
前段までで何度か出てきますが、Kubernetesのイベントとアプリケーションの挙動とを紐付けることで、障害や低パフォーマンスの要因を素早く特定することをサポートすることができます。
正しくアラートを上げる
PodはNode上を動き回るため、アラートもそれを追従しなければなりません。そのため、Podが動いても安定的なもの(ユーザー独自のラベル、サービス名、replication controllerやreplica setの名前など)を目印として付随させる必要があると述べています。
まとめ
記事では様々な紹介がされていますが、共通して言えそうなポイントとしては以下の2点かと思います。
- Kubernetesシステムを監視する際はラベル付けが必須である。またデフォルトで用意されたラベルだけでなく利用者が独自のラベルをつけることで監視をしやすくすることができる。
- 個々のリソース等のメトリクスだけでなく、それらとアプリケーションやKubernetesのオブジェクトの挙動とを紐付けて監視することができる。それにより障害や低パフォーマンスの要因に早く気づくことができる。
また記事内ではネットワーク周りやアラートなどあまり説明されない箇所もありましたので、今後はそのあたりを中心に調べていこうと思います。