はじめに
-
Kubernetesクラスターを運用するうえでは様々な要素を考えないといけないですが、その一つにNodeのアップデートがあります。Kubernetesが動作するサーバーそのもののセキュリティを担保するのは、定期的なサーバー・OSのアップデートが大切で、特にオンプレ環境などで運用者がNodeアップデートを実行する必要がある場合、アップデートに向けた戦略を考えることが重要になります。
-
Nodeのアップデートを行う場合、以下のようなことを考える必要があります。
- アップデート情報の検知
- クラスター上に動くPodの一時的な退避
- アップデートの実行
これらを踏まえたアップデート運用方法を考える手間を省くことができるかもしれないのが、Kuredというツールです。
Kuredとは
Kured (KUbernetes REboot Daemon)はWeaveworks社が開発しているツールで、大まかに以下のような特徴を備えています。
- デフォルトでは
/var/run/reboot-requiredファイルが存在するか否かを検知し、存在する場合は対象のNodeを再起動する(/var/run/reboot-requiredについてはこちらから)。 - 再起動する際は一度に1つのNodeずつしか行わなず、再起動前後でcordon/uncordon・drainすることで、事前にPodの退避を行ったうえでNodeの再起動を行う。
Kuredを使ってみる
今回は以下のような環境で実行しました。なお、Kuredの対応バージョンはgithubに記載されており、まだkubernetes ver.1.15には対応していないように見えますが、一応は動作することが確認できました(ただしKuredのすべての機能が正しく動作するかは保証できないため、そこは十分検証したうえで本番利用してください)。
検証環境
- Kubernetesバージョン:1.15
- 構築環境:virtualbox(デプロイではvagrantを利用)
- 構築方法:kubeadm
- 1master + 2 node
-
kube-master01: 172.16.33.10 -
kube-worker01: 172.16.33.20 -
kube-worker02: 172.16.33.30
-
Kuredのデプロイ
それではKuredをデプロイします。デプロイ方法はgithubページに書かれており、kubectlコマンドでYAMLファイルをデプロイして利用します。またHelmチャートも公開されており、そちらを利用することもできます。
[root@kube-master01 ~]# kubectl apply -f https://github.com/weaveworks/kured/releases/download/1.2.0/kured-1.2.0-dockerhub.yaml
clusterrole.rbac.authorization.k8s.io/kured created
clusterrolebinding.rbac.authorization.k8s.io/kured created
role.rbac.authorization.k8s.io/kured created
rolebinding.rbac.authorization.k8s.io/kured created
serviceaccount/kured created
daemonset.apps/kured created
[root@kube-master01 ~]#
デプロイ後は以下の通り、kube-systemNamespaceにkuredPodがデプロイされています。
[root@kube-master01 ~]# kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-7bd78b474d-sftn7 1/1 Running 2 7d4h 192.168.237.73 kube-master01 <none> <none>
calico-node-ksl4b 1/1 Running 2 7d4h 172.16.33.30 kube-worker02 <none> <none>
calico-node-mqpss 1/1 Running 5 7d4h 172.16.33.20 kube-worker01 <none> <none>
calico-node-wfws8 1/1 Running 2 7d4h 172.16.33.10 kube-master01 <none> <none>
coredns-5c98db65d4-4j67d 1/1 Running 2 7d4h 192.168.237.72 kube-master01 <none> <none>
coredns-5c98db65d4-zsqkt 1/1 Running 2 7d4h 192.168.237.71 kube-master01 <none> <none>
etcd-kube-master01 1/1 Running 2 7d4h 172.16.33.10 kube-master01 <none> <none>
kube-apiserver-kube-master01 1/1 Running 3 7d4h 172.16.33.10 kube-master01 <none> <none>
kube-controller-manager-kube-master01 1/1 Running 2 7d4h 172.16.33.10 kube-master01 <none> <none>
kube-proxy-mzfm4 1/1 Running 5 7d4h 172.16.33.20 kube-worker01 <none> <none>
kube-proxy-t8sld 1/1 Running 2 7d4h 172.16.33.30 kube-worker02 <none> <none>
kube-proxy-zsrgb 1/1 Running 2 7d4h 172.16.33.10 kube-master01 <none> <none>
kube-scheduler-kube-master01 1/1 Running 2 7d4h 172.16.33.10 kube-master01 <none> <none>
★ kured-5qvrc 1/1 Running 0 5m41s 192.168.247.239 kube-worker02 <none> <none>
★ kured-9s9m9 1/1 Running 0 5m54s 192.168.132.32 kube-worker01 <none> <none>
★ kured-n82kt 1/1 Running 0 5m43s 192.168.237.76 kube-master01 <none> <none>
[root@kube-master01 ~]#
kubectl logsでKuredのPodが出力したログを確認すると、以下のように出力されます。Kuredのバージョン情報や再起動のトリガーとなるファイル、検知周期などが出力されています。
[root@kube-master01 ~]# kubectl logs -n kube-system kured-9s9m9
time="2019-08-10T14:34:02Z" level=info msg="Kubernetes Reboot Daemon: 1.2.0"
time="2019-08-10T14:34:02Z" level=info msg="Node ID: kube-worker01"
time="2019-08-10T14:34:02Z" level=info msg="Lock Annotation: kube-system/kured:weave.works/kured-node-lock"
time="2019-08-10T14:34:02Z" level=info msg="Reboot Sentinel: /var/run/reboot-required every 1h0m0s"
time="2019-08-10T14:34:02Z" level=info msg="Blocking Pod Selectors: []"
[root@kube-master01 ~]#
今回は事前に以下のDeploymentファイルをデプロイしておき、サーバーのアップデート時にどのような挙動をするか見てみます。
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-deployment
spec:
replicas: 4
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: nginx-container
image: nginx:1.12
ports:
- containerPort: 80
[root@kube-master01 ~]# kubectl apply -f sample-deployment.yaml
deployment.apps/sample-deployment created
[root@kube-master01 ~]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
sample-deployment 4/4 4 4 12s
[root@kube-master01 ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
sample-deployment-7bb5fc6bc6 4 4 4 16s
[root@kube-master01 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
sample-deployment-7bb5fc6bc6-8m9fj 1/1 Running 0 22s 192.168.247.241 kube-worker02 <none> <none>
sample-deployment-7bb5fc6bc6-bx566 1/1 Running 0 22s 192.168.247.240 kube-worker02 <none> <none>
sample-deployment-7bb5fc6bc6-c7vvn 1/1 Running 0 22s 192.168.132.34 kube-worker01 <none> <none>
sample-deployment-7bb5fc6bc6-g8jjn 1/1 Running 0 22s 192.168.132.33 kube-worker01 <none> <none>
[root@kube-master01 ~]#
テスト用Podをデプロイしたので、Kuredのテストを行います。ここではkube-worker01に/var/run/reboot-requiredファイルを配置することで、Kuredによる再起動を誘導します。
[root@kube-worker01 ~]# touch /var/run/reboot-required
[root@kube-worker01 ~]# ls -l /var/run/reboot-required
-rw-r--r-- 1 root root 0 Aug 10 14:41 /var/run/reboot-required
[root@kube-worker01 ~]#
デフォルトの設定では1時間ごとに/var/run/reboot-requiredファイルがないか確認しますので、しばらくしてからKuredのPodのログを確認すると、再起動したのがわかります。ここでは周辺のリソースも含めて見ています。
# NodeのCordon/Uncordon、Drainの検知
[root@kube-master01 ~]# kubectl get nodes -o wide -w
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
kube-master01 Ready master 7d5h v1.15.1 172.16.33.10 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
kube-worker01 Ready <none> 7d5h v1.15.1 172.16.33.20 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
kube-worker02 Ready <none> 7d5h v1.15.1 172.16.33.30 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
## kube-worker01がスケジューリングから外れたのち、再びスケジュール対象となっているのがわかります
kube-worker01 Ready <none> 7d5h v1.15.1 172.16.33.20 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
★ kube-worker01 Ready,SchedulingDisabled <none> 7d5h v1.15.1 172.16.33.20 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
★ kube-worker01 Ready,SchedulingDisabled <none> 7d5h v1.15.1 172.16.33.20 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
kube-master01 Ready master 7d5h v1.15.1 172.16.33.10 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
kube-worker02 Ready <none> 7d5h v1.15.1 172.16.33.30 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
★ kube-worker01 Ready,SchedulingDisabled <none> 7d5h v1.15.1 172.16.33.20 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
★ kube-worker01 Ready,SchedulingDisabled <none> 7d5h v1.15.1 172.16.33.20 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
kube-master01 Ready master 7d5h v1.15.1 172.16.33.10 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
kube-worker02 Ready <none> 7d5h v1.15.1 172.16.33.30 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
kube-worker01 Ready,SchedulingDisabled <none> 7d5h v1.15.1 172.16.33.20 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
★ kube-worker01 Ready <none> 7d5h v1.15.1 172.16.33.20 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
★ kube-worker01 Ready <none> 7d5h v1.15.1 172.16.33.20 <none> CentOS Linux 7 (Core) 3.10.0-957.27.2.el7.x86_64 docker://17.3.2
# Kured Podのログ確認
[root@kube-master01 ~]# kubectl logs -n kube-system kured-9s9m9
time="2019-08-10T15:49:11Z" level=info msg="Kubernetes Reboot Daemon: 1.2.0"
time="2019-08-10T15:49:11Z" level=info msg="Node ID: kube-worker01"
time="2019-08-10T15:49:11Z" level=info msg="Lock Annotation: kube-system/kured:weave.works/kured-node-lock"
time="2019-08-10T15:49:11Z" level=info msg="Reboot Sentinel: /var/run/reboot-required every 1h0m0s"
time="2019-08-10T15:49:11Z" level=info msg="Blocking Pod Selectors: []"
★ time="2019-08-10T15:49:11Z" level=info msg="Holding lock"
★ time="2019-08-10T15:49:11Z" level=info msg="Uncordoning node kube-worker01"
★ time="2019-08-10T15:49:11Z" level=info msg="node/kube-worker01 uncordoned" cmd=/usr/bin/kubectl std=out
★ time="2019-08-10T15:49:11Z" level=info msg="Releasing lock"
[root@kube-master01 ~]#
# /var/run/reboot-requiredは削除される
[root@kube-worker01 ~]# ls -l /var/run/reboot-required
ls: cannot access /var/run/reboot-required: No such file or directory
[root@kube-worker01 ~]#
またテスト用PodをWatchすると、別のNodeに新たなPodが作成されることがわかります。
# テスト用Podのwatch
[root@kube-master01 ~]# kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
sample-deployment-7bb5fc6bc6-8m9fj 1/1 Running 0 63m 192.168.247.241 kube-worker02 <none> <none>
sample-deployment-7bb5fc6bc6-bx566 1/1 Running 0 63m 192.168.247.240 kube-worker02 <none> <none>
sample-deployment-7bb5fc6bc6-c7vvn 1/1 Running 0 63m 192.168.132.34 kube-worker01 <none> <none>
sample-deployment-7bb5fc6bc6-g8jjn 1/1 Running 0 63m 192.168.132.33 kube-worker01 <none> <none>
## kube-worker01上のPodが削除され、kube-worker02に新たなPodが作成される
★ sample-deployment-7bb5fc6bc6-c7vvn 1/1 Terminating 0 69m 192.168.132.34 kube-worker01 <none> <none>
★ sample-deployment-7bb5fc6bc6-g8jjn 1/1 Terminating 0 69m 192.168.132.33 kube-worker01 <none> <none>
sample-deployment-7bb5fc6bc6-2b7ld 0/1 Pending 0 0s <none> <none> <none> <none>
★ sample-deployment-7bb5fc6bc6-2b7ld 0/1 Pending 0 0s <none> kube-worker02 <none> <none>
sample-deployment-7bb5fc6bc6-vb5bg 0/1 Pending 0 0s <none> <none> <none> <none>
★ sample-deployment-7bb5fc6bc6-vb5bg 0/1 Pending 0 0s <none> kube-worker02 <none> <none>
★ sample-deployment-7bb5fc6bc6-2b7ld 0/1 ContainerCreating 0 0s <none> kube-worker02 <none> <none>
★ sample-deployment-7bb5fc6bc6-vb5bg 0/1 ContainerCreating 0 0s <none> kube-worker02 <none> <none>
sample-deployment-7bb5fc6bc6-g8jjn 0/1 Terminating 0 69m 192.168.132.33 kube-worker01 <none> <none>
sample-deployment-7bb5fc6bc6-c7vvn 0/1 Terminating 0 69m 192.168.132.34 kube-worker01 <none> <none>
sample-deployment-7bb5fc6bc6-vb5bg 0/1 ContainerCreating 0 0s <none> kube-worker02 <none> <none>
sample-deployment-7bb5fc6bc6-2b7ld 0/1 ContainerCreating 0 1s <none> kube-worker02 <none> <none>
★ sample-deployment-7bb5fc6bc6-2b7ld 1/1 Running 0 1s 192.168.247.243 kube-worker02 <none> <none>
★ sample-deployment-7bb5fc6bc6-vb5bg 1/1 Running 0 1s 192.168.247.242 kube-worker02 <none> <none>
sample-deployment-7bb5fc6bc6-c7vvn 0/1 Terminating 0 69m 192.168.132.34 kube-worker01 <none> <none>
sample-deployment-7bb5fc6bc6-c7vvn 0/1 Terminating 0 69m 192.168.132.34 kube-worker01 <none> <none>
sample-deployment-7bb5fc6bc6-g8jjn 0/1 Terminating 0 69m 192.168.132.33 kube-worker01 <none> <none>
sample-deployment-7bb5fc6bc6-g8jjn 0/1 Terminating 0 69m 192.168.132.33 kube-worker01 <none> <none>
^C[root@kube-master01 ~]#
[root@kube-master01 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
★ sample-deployment-7bb5fc6bc6-2b7ld 1/1 Running 0 4m45s 192.168.247.243 kube-worker02 <none> <none>
sample-deployment-7bb5fc6bc6-8m9fj 1/1 Running 0 74m 192.168.247.241 kube-worker02 <none> <none>
sample-deployment-7bb5fc6bc6-bx566 1/1 Running 0 74m 192.168.247.240 kube-worker02 <none> <none>
★ sample-deployment-7bb5fc6bc6-vb5bg 1/1 Running 0 4m45s 192.168.247.242 kube-worker02 <none> <none>
[root@kube-master01 ~]#
# kube-system NamespaceのPodをwatch
[root@kube-master01 ~]# kubectl get pods -n kube-system -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-7bd78b474d-sftn7 1/1 Running 2 7d5h 192.168.237.73 kube-master01 <none> <none>
calico-node-ksl4b 1/1 Running 2 7d5h 172.16.33.30 kube-worker02 <none> <none>
calico-node-mqpss 1/1 Running 5 7d5h 172.16.33.20 kube-worker01 <none> <none>
calico-node-wfws8 1/1 Running 2 7d5h 172.16.33.10 kube-master01 <none> <none>
coredns-5c98db65d4-4j67d 1/1 Running 2 7d5h 192.168.237.72 kube-master01 <none> <none>
coredns-5c98db65d4-zsqkt 1/1 Running 2 7d5h 192.168.237.71 kube-master01 <none> <none>
etcd-kube-master01 1/1 Running 2 7d5h 172.16.33.10 kube-master01 <none> <none>
kube-apiserver-kube-master01 1/1 Running 3 7d5h 172.16.33.10 kube-master01 <none> <none>
kube-controller-manager-kube-master01 1/1 Running 2 7d5h 172.16.33.10 kube-master01 <none> <none>
kube-proxy-mzfm4 1/1 Running 5 7d5h 172.16.33.20 kube-worker01 <none> <none>
kube-proxy-t8sld 1/1 Running 2 7d5h 172.16.33.30 kube-worker02 <none> <none>
kube-proxy-zsrgb 1/1 Running 2 7d5h 172.16.33.10 kube-master01 <none> <none>
kube-scheduler-kube-master01 1/1 Running 2 7d5h 172.16.33.10 kube-master01 <none> <none>
kured-5qvrc 1/1 Running 0 72m 192.168.247.239 kube-worker02 <none> <none>
kured-9s9m9 1/1 Running 0 72m 192.168.132.32 kube-worker01 <none> <none>
kured-n82kt 1/1 Running 0 72m 192.168.237.76 kube-master01 <none> <none>
## kube-worker01上のPodが一時的に利用不可となったのち、再び利用可能となる
kube-proxy-mzfm4 0/1 Error 5 7d5h 172.16.33.20 kube-worker01 <none> <none>
kured-9s9m9 0/1 Error 0 74m <none> kube-worker01 <none> <none>
kured-9s9m9 0/1 Error 0 74m <none> kube-worker01 <none> <none>
kured-9s9m9 1/1 Running 1 74m 192.168.132.35 kube-worker01 <none> <none>
calico-node-mqpss 0/1 Completed 5 7d5h 172.16.33.20 kube-worker01 <none> <none>
kube-proxy-mzfm4 1/1 Running 6 7d5h 172.16.33.20 kube-worker01 <none> <none>
calico-node-mqpss 0/1 Completed 5 7d5h 172.16.33.20 kube-worker01 <none> <none>
calico-node-mqpss 0/1 Completed 5 7d5h 172.16.33.20 kube-worker01 <none> <none>
calico-node-mqpss 0/1 Completed 5 7d5h 172.16.33.20 kube-worker01 <none> <none>
calico-node-mqpss 0/1 Running 6 7d5h 172.16.33.20 kube-worker01 <none> <none>
calico-node-mqpss 1/1 Running 6 7d5h 172.16.33.20 kube-worker01 <none> <none>
kured-9s9m9 0/1 Error 1 74m 192.168.132.35 kube-worker01 <none> <none>
kured-9s9m9 0/1 CrashLoopBackOff 1 75m 192.168.132.35 kube-worker01 <none> <none>
kured-9s9m9 1/1 Running 2 75m 192.168.132.35 kube-worker01 <none> <none>
^C[root@kube-master01 ~]#
その他オプション
Kuredには他にも利用できるオプションが存在します。特定のラベルが付与されたPodが存在する場合に再起動を阻止したり、PrometheusやSlackとの連携も可能です。
-
--blocking-pod-selector: 特定のラベルを指定し、それが付与されたPodが存在するNodeは再起動されない -
--prometheus-url: Prometheusを利用する際に指定するURL -
--slack-hook-url: 再起動の通知をslackから通知するためのWebhook URL
ここではslackの通知機能を試してみます。Kuredをデプロイ済みの場合は、kubectl edit等でコンフィグを編集します。
[root@kube-master01 ~]# kubectl get ds -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
calico-node 3 3 3 3 3 beta.kubernetes.io/os=linux 7d3h
kube-proxy 3 3 3 3 3 beta.kubernetes.io/os=linux 7d3h
kured 3 3 3 3 3 <none> 30m
[root@kube-master01 ~]# kubectl edit ds kured -n kube-system
(中略)
containers:
- command:
- /usr/bin/kured
- --slack-hook-url=<slackのWebhook URLを指定>
(中略)
daemonset.extensions/kured edited
[root@kube-master01 ~]#
上記の設定を入れておくと、再起動の際、以下のようにSlackに通知が飛んできます。
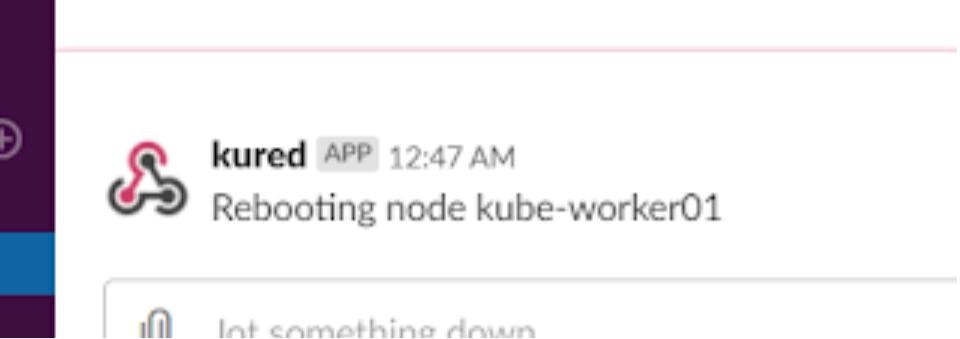
まとめ
- Kuredを使うことでKubernetesノードのアップデートを安全に行うことができます。アップデートは脆弱性への対策として必須であり、それをスムーズに実行できることは、Kubernetes環境のセキュリティを高めるうえで重要となります。
- ただし、Nodeアップデートを行う際には、一時的に別のNodeにPodが移動するため、アップデートするNode以外のNodeに対する負荷が増加します。そのため、負荷増加を見越したクラスター設計が必要となります(これはNodeアップデートに限らず、Kubernetesを本番環境で利用するうえでは、Nodeがダウンしたときに備えた設計が必要です)。
- また、Node上のリソースのアップデート方法を検討する必要もあります。今回は特に指定をせずにDeploymentを使用したため
RollingUpdateが実行されましたが、例えばPod単体でデプロイしている場合、Nodeアップデートに合わせて削除されてしまいます。そのためリソースの種類やアップデート戦略によっては、考え直す必要があるかもしれません。