本書はTransformerを使った物体検出モデルであるDETRを説明します。(Transformerを理解している前提で記載しています。まだ理解していない方は当法人で作成している別冊「Seq2Seq&Transformer」を先に読んでください。)
【参考文献、サイト】
- 論文 End-to-End Object Detection withTransformers
- End-to-End Object Detection with Transformers(DETR)の解説
- Transformerを物体検出に採用!話題のDETRを詳細解説!
1.はじめに
DETRはFacebook AI Research(FAIR)が2020年5月に公開した、Transformerを使った初めての物体検出モデルです。これまでの物体検出は、NMS(Non Maxinum Suppression)、Anchor boxの数、アスペクト比、Bounding boxのデフォルト座標等を人手でチューニングする必要があり実質的にEnd to Endが実現されていませんでした。
※物体検出モデルの詳細は別冊のSSDまたはFaster R-CNNを参照してください。
DETRは、物体検出問題を直接集合予測問題(a direct set prediction problem)として捉え、NMSやRPN等の複雑な仕組みや上記人手のチューニングをなくした「CNN + Transformer」のシンプルな構成でEnd to Endな物体検出を実現します。
※(筆者のイメージでは)DETRでのTransformerのシーケンス(時系列)は「画像内のオブジェクトの関連性」を把握するために使われていると思われます。例えば、馬がいればその上に乗っているオブジェクトは人間である可能性が高い等です。
DETRはTansformerを活用することでシンプルな構成ながらFaster R-CNN等に匹敵する性能を達成しています。
2.DETRアーキテクチャ
従来の物体検出モデルは、複数の物体を検出してNMSで絞り込むというプロセスを介していましたが、DETRでは入力した画像内に写っているすべてのオブジェクトを一括して推論します。また、画像内の推論したすべてのオブジェクトとすべての正解ラベルとをハンガリアン法(後述、推論と正解を比べ最も当てはまりの良いペアを見つけてそれらに対して損失をとるものです)で対応付けを実施しています。
(1) DETRの推論フロー
推論フローは図1のように非常にシンプルです。

- 画像をCNN(ResNet等)に入力する。
CNNで出力されたチャネル数(ex.2048)を1×1畳み込みでチャネル数をより小さい次元d(ex.256)に縮小する。 - 特徴マップが生成される(d個)
- Transformerにd個の特徴マップを入力する
- N個のオブジェクト情報(クラス、位置、サイズ)が出力される
※N個が一括して推論されます。なお、Nは100個等入力画像に含まれるよりも十分に多い数を選びます
(2) ハンガリアン法(推論結果と正解ラベルの自動対応付け)
直接集合予測問題を解く上で、推論と正解とのマッチングが正しく行われているのか正しく判断できる必要があります(人手でなく機械で)。DETRでは、二部マッチング問題として考え、ハンガリアン法で適切な対応付けを行います。
-
二部マッチング問題
異なる2つの集合の要素をどのように組み合わせると目的を最大値で達成することができるの
かを解くものです。 -
ハンガリアン法
二部マッチング問題を効率的に解くための手法。全検索すると n! の計算量が必要になるとこを n3 で計算できます。 DETRではこの手法を用いてオブジェクトの推論結果(N、 ex.100)と正解ラベル(Nとの差分はすべてNo Object)の対応付けを行います。
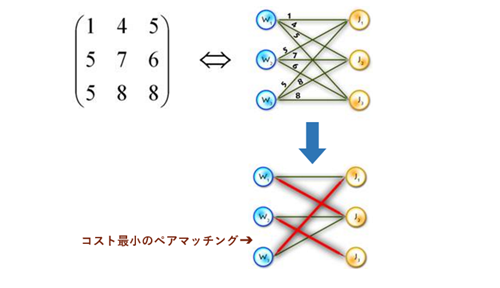
実際の対応付けイメージは下記にようになります。
-
まず正解ラベル y と推論結果 y^ を突き合わせて、コスト行列(ex. N=100であれば、100×100行列に各ペアのロスが入る)を作ります。
-
ハンガリアンアルゴリズムでこの行列を解いて、総和が最小なマッチングパタンσ^(重複なしのN(100)ペア)を求めます。
このマッチングパターン σ^ が正解ラベル y (n個はオブジェクト、「N-n」個はNo Object)と推論結果 y^ の対応付けになります。
(3) ハンガリアンアルゴリズムを用いたロスの算出
ロス計算は以下の流れになります。
- DETRに画像を入力し、推論結果y^(N個分(ex.100個)のオブジェクト推論)を出力
※yiには分類クラス情報ciと矩形情報biを持つ - 正解ラベルyと推論結果y^をもとに、ハンガリアンアルゴリズムで最適なマッチングパターンσ^を見つけ出す
- 正解ラベルyと推論結果y^の最適なマッチングパターンσ^におけるロスを計算する
マッチングパターンσ^の計算は以下になります。
-
Lbox : Generalized IoUロス(IoUに距離の概念を追加したもの)と回帰ロス(位置・サイズ)を足したものです。回帰ロス(位置・サイズ)はスケール変化に弱いため、IoUロスを追加しています。
Generalized IoUロスと回帰ロス(位置・サイズ)の和を矩形ロス(Lbox)としています。
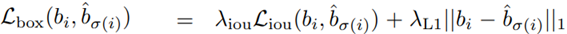
-
Lmatch : 予測と正解ラベルをマッチングしたときに生じるロスです。
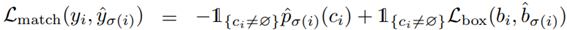
クラスロス(そのクラスである確率 X - 1 )と、矩形ロス( Lbox )の和をLmatchとしています。 -
σ^ : Lmatchをすべて計算し、その結果から物体の対応関係一覧を得ます。
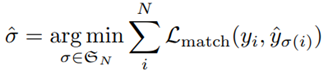
各マッチングパターン σ∈ €Nにおいて、各ペア(正解ラベル yi と推論結果 yi^ )のロス Lmatch の総和が最小となるマッチングパターン σ^を求め
ています -
LHungarian : σ^によって得た物体の対応関係一覧から最適な予測と正解ラベルのマッチングを算出します。
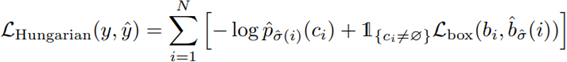
クラスロスと矩形ロス(Lbox)の和の全オブジェクト総和を LHungarian としています。
3.DETRアーキテクチャ
DETR全体のアーキテクチャは図3のようにシンプルで、「CNNバックボーン」、「エンコーダー・デコーダートランスフォーマ」、最終的な検出予測をシンプルな「FFN(フィードフォワードネットワーク)の3つのコンポーネントで構成されています。
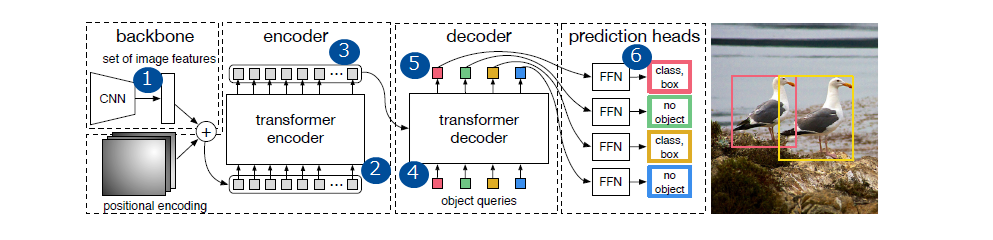
(1) 処理の流れ
- CNN出力の特徴マップ(ResNetだと2048)を、 1 × 1 Convolutionでdチャネルに圧縮する
- Transformer encoderへ、サイズH * Wの特徴マップd個を、H * W個のd次元特徴として入力する。このときpositional encodingで位置情報を補足する。
- Transformer encoderは、H * W個の中間オブジェクト特徴(各d次元)を出力する
- Transformer decoderへ、 H * W個の中間オブジェクト特徴とN個のobject query(※1)を入力する
- Transformer decoderは、N個のオブジェクト特徴(各d次元)を出力する
- N個のオブジェクト特徴をそれぞれFFNを通して、N個のオブジェクト推論結果(クラス、矩形)が出てきます
図4は原論文に記載されているN=100のときの内20個のボックスの予測を可視化したものです。画像サイズごとにポイントは色分けされており、緑の色が小さい画像、赤は大きな横長のボックス、青は大きな縦長のボックスを示します。各Nそれぞれで見方の傾向に違いがあることが見て取れます。この違いが適切に物体検出と分類を行うことを可能にしています。

(2) Auxiliary decoding loss
オブジェクトの識別性能をあげるために、補助(Auxiliary)ロスを用います。デコーダも各層の出力にFFN(最終層のコピー)を設けて、各層で最終層と同様の推論をします。そして、各層でロス計算を同様にして、各層で誤差伝搬を走らせます。
4.詳細なアーキテクチャ
DETRにおいて、各アテンション層に展開される位置エンコーディングを用いたトランスフォーマーの詳細は図5のとおりです。 CNNバックボーンからの画像特徴量は、トランスフォーマー・エンコーダーを通じて、空間位置エンコーダとともに渡されます。空間位置エンコーダ(図5のSpatial positional encoding)は、マルチヘッド・セルフアテンション層ごとにQueryとKeyに追加されます。
その後、デコーダはQuery(初期値はゼロに設定されています)、出力位置エンコーディング(オブジェクトクエリ)、エンコーダメモリを受信し、予測したクラスラベルとバウンディングボックスの最終的なセットを生成します。 この処理は、複数のマルチヘッドのセルフ・アテンションとデコーダエンコーダ・アテンションを介して行います。最終デコーダの最初のセルフアテンション層はスキップ可能です。
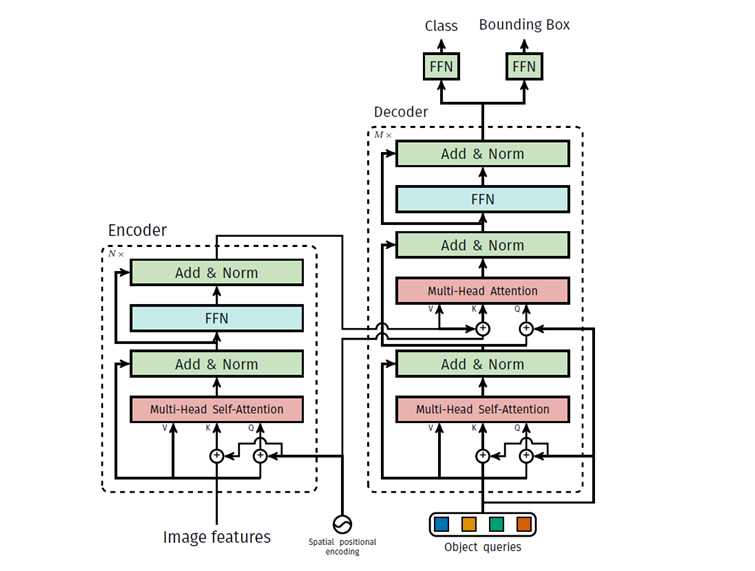
5.識別結果(論文より)
(1) Eecoder最終層のattentionマップ
図6は、Encoderの256スロットの中から、顕著なattentionマップを持つ4スロットを可視化した図です。これからEncoderの段階で既にオブジェクト分離できているのがわかります。

(2) Decoder最終層のattentionマップ
図7は、Decoderの100スロットの中から、顕著なattentionマップを持つ2スロットを可視化したものです。上述のようにEncoderで大まかなオブジェクト分離は完了しているため、Decoder側ではオブジェクト境界(足や鼻先)を集中して見ることで、精密なオブジェクトの境界線を判断しています。

6.シンプルさ
論文上に記載されているPytorchで記載された推論コードは下記のように約30行程度のコードになっています。
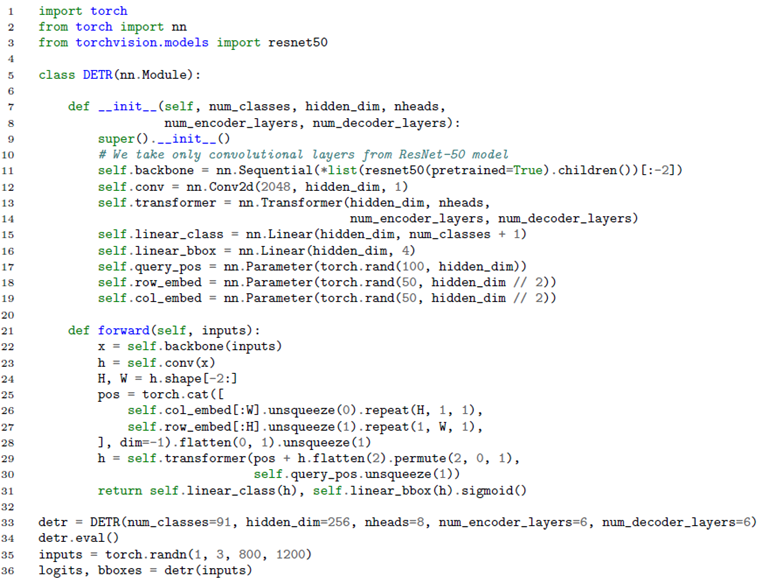
7.おわりに
本稿では、直接集合予測を行うためトランスフォーマーと二部マッチングを使い物体検出を行うDETRについて説明しました。DETRは実装が簡単でセグメンテーション領域への拡張も可能です。さらにFaster R-CNNよりもラージオブジェクトに対しては高い性能が出ます。一方でスモールオブジェクトの精度等では課題がありますが、今後改善がされていくものと思いますので継続して「注視」していきます。
物体検出(SSDやFaster-RNN)や、Transformerについても別冊で執筆しておりますので興味のある方は、ぜひ参照ください。