最近、Arxiv Sanity Preserverで上位にランクインしていた、Facebookから20/5/27に公開のObject Detection論文 DETRについて解説する。
概要
NMSやRPN等のごちゃごちゃした仕組み無しで、CNN+Transformerの極めてシンプルな構成で真にEnd to Endな物体検出を実現する。
その上で、最近の最前線クラスの物体検出器に匹敵する性能を達成している。
(テクニカルに色々してるが、新規性は従来のRNNをTransformerに置き換えている所)
このシンプルな構成のおかげで拡張が容易で、この論文ではDETR物体検出器をSegmentationタスクにも拡張し、SOTA級のアーキテクチャを上回る性能を叩き出している。

NMSをなくして、Transformer化に至るまでの背景
現在よく使われてる物体検出器では、処理の途中過程にあるNMS(Non Maximum Suppression)等を人手でチューニングする必要があり、その人手チューニングの必要性のために実質的なEnd to Endが実現されていない。
NMSを学習する手法(Learnable NMS)で多少は楽になるが、その手法も人手チューニングの部分が結構ある。
そこで、NMSを排除した手法が提案されているが、RNNがボトルネックとなって振るった性能が出せていない。(この手法が本手法のベースライン手法に相当する。)
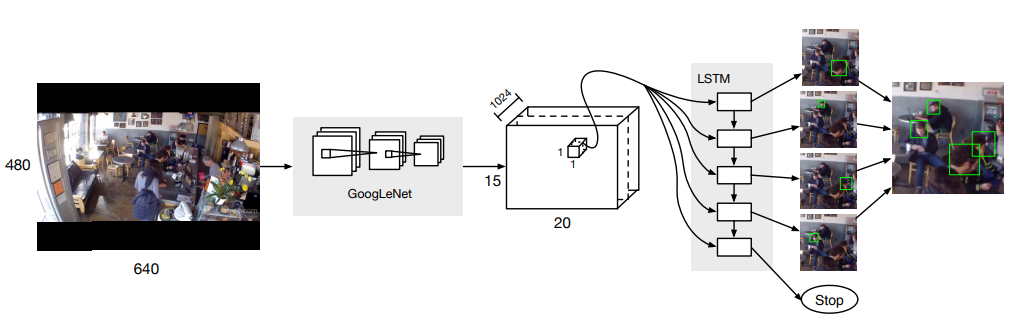
この論文のDETRアーキテクチャでは、RNNをTransformerに置き換えることで性能問題を解決し、高性能&シンプル&End-to-Endをすべて実現している。
DETR
DETRアーキテクチャの技術的なポイント
-
全体感 NMSなしで、画像内のオブジェクト全部を一括して直接的に推論する。(=Direct set prediction)
- 従来:候補をたくさん推論➡NMSで絞り込む というNMSを介した間接的な推論をする。
-
直接推論の課題1 画像内の全推論結果と全正解ラベルをどう対応付ければ良いのかわからない。
- ➡ ハンガリアン法で一意かつ適切な対応付けを定義する。
-
直接推論の課題2 RNNだと性能が振るわない。
- ➡ Transformer+細かな細工で高性能な物体検出する。
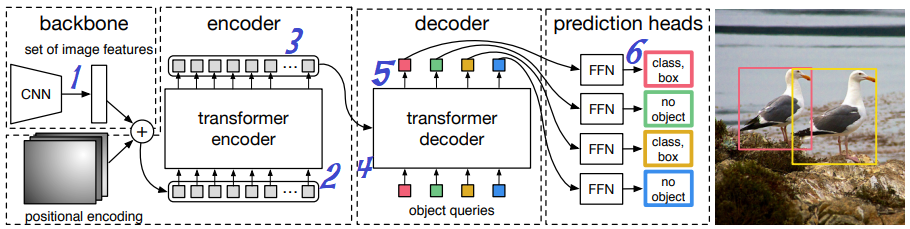
DETRの推論フロー

すごくシンプル
- 画像をCNNに入力する
- 特徴マップがd個生成される
- Transformerにd個の特徴マップを入力する
- N個のオブジェクト情報(クラス・位置・サイズ)が出力される(=全オブジェクトの一括推論)
※ dは中間特徴マップ数。実験ではd=256。性能に影響する。
※ Nは出力オブジェクト情報数。実験ではN=100。1画像に含まれるオブジェクト数より十分に多い値を選ぶ。
※ クラス出力は「オブジェクト見つからず」を意味するno object(=φ)も含まれる。(というか大半はこれ)
推論結果と正解ラベルの対応付けたい➡ハンガリアン法で解決
DETRでは、画像入力する度に100個のオブジェクト推論結果が毎回出てくるが、この推論を学習させるにはこれらと正解ラベルを突き合わせてロスを計算する必要がある。
例えば、下図の2羽の鳥の画像で推論して100個のオブジェクト推論結果を得た場合、100個のロスを計算する必要がある。その際、1個の推論結果は左の鳥1の正解ラベルと突き合わせてロス計算し、1個の推論結果は真ん中の鳥2の正解ラベルと突き合わせてロス計算し、残る98個の推論結果はクラス=φ(no object)と突き合わせてロス計算する。
(詳細は後述するが、ロス計算にはクラスロスとbboxの回帰ロスを使う)

しかし、下図のような学習初期のめちゃくちゃな推論時(100個は書き切れないので10個にした)に、どのオブジェクト推論結果(=バウンディングボックス)を鳥1と対応付け、どのオブジェクト推論結果を鳥2と対応付け、どのオブジェクト推論結果をφ(no object)と対応付ければ良いのかの機械的な判断は難しい。
人が対応付けを判断するならば、黒枠が左の鳥1、灰枠が右の鳥2、それ以外の8個をφ(no object)に対応付けるのが一番ましそうな対応付けであると判断できるのだが。(正解ラベルに一番近い矩形が適切そうなので)

DETRでは、その機械的で一意な対応付けにハンガリアンアルゴリズムを用いる。ハンガリアンアルゴリズムは下図のように最も効率の良いマッチング(ペア)パターンを見つける手法であり、愚直に全探索すると$O(n!)$の計算量が必要なところを最悪$O(n^3)$で計算できる。この手法を用いてオブジェクト推論結果(100個)と正解ラベル(100個。不足分はすべてno object)の対応付けを行う。
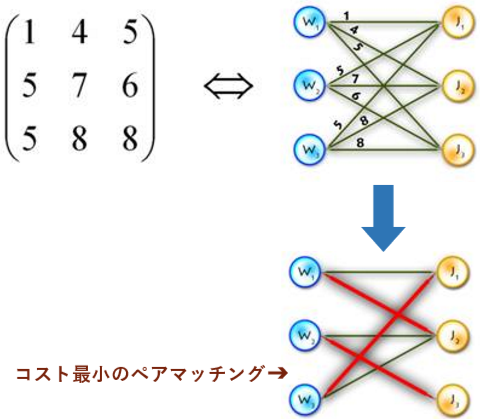
(図の引用元)
実際の対応付けは以下のような感じになる。
- まず正解ラベル$y$と推論結果$\hat{y}$を突き合せて、コスト行列(100x100行列に、各ペアのロスが入る)を作る
- ハンガリアンアルゴリズムでこのコスト行列を解いて、総和最小なマッチングパターン$\hat{σ}$(重複なしの100ペア)を求める
このマッチングパターン$\hat{σ}$が正解ラベル$y$(2個はオブジェクト、98個はno object)と推論結果$\hat{y}$の対応付けになる。
参考:ハンガリアンアルゴリズムについては配属の数理(1)の20~32ページ辺り
ハンガリアンアルゴリズムを用いたロスの算出
最終的にハンガリアンアルゴリズムを用いたロス計算は以下の流れとなる。
- DETRに画像入力し、推論結果$\hat{y}$(N個のオブジェクト推論)を出力する
- 正解ラベル$y$と推論結果$\hat{y}$を基に、ハンガリアンアルゴリズムで最適なマッチングパターン$\hat{σ}$を見つけ出す
- 正解ラベル$y$と推論結果$\hat{y}$の最適なマッチングパターン$\hat{σ}$におけるロスを計算する
1.の補足:yが持つ情報
$y_i$はクラス情報$c_i$と矩形情報$b_i$を持つ。
2.の補足:σ^の計算
-
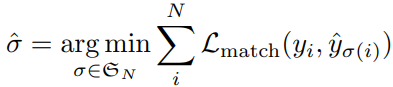
- 各マッチングパターン$\sigma\in\mathfrak{S}$N において、各ペア(正解ラベル$y_i$と推論結果$\hat{y_i}$)のロス $L_{\textrm{match}}$の総和が最小となるマッチングパターン$\hat{σ}$を求めている(ハンガリアンアルゴリズムを使用する)
-
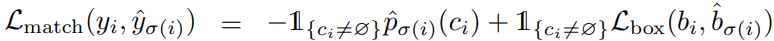
- クラスロス(そのクラスである確率 × -1)と矩形ロス($L_{\textrm{box}}$)の和を$L_{\textrm{match}}$としている
-
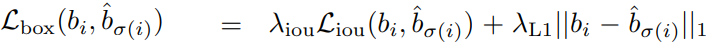
- Generalized IoUロスと回帰ロス(位置・サイズ)の和を矩形ロス($L_{\textrm{box}}$)としている
- Generalized IoU:IoUに距離の概念を追加したもの
- 回帰ロス(位置・サイズ)はスケール変化に弱いため、IoUロスを追加している
- Generalized IoUロスと回帰ロス(位置・サイズ)の和を矩形ロス($L_{\textrm{box}}$)としている
3.の補足:σ^を用いた最終的なロス計算
-
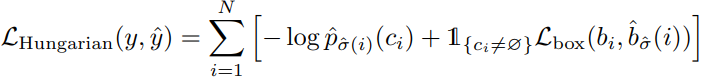
- クラスロスと矩形ロス($L_{\textrm{box}}$)の和 の全オブジェクト総和を$L_{\textrm{Hungarian}}$としている
- 2.のクラスロスと少しだけ違う理由:$L_{\textrm{box}}$とのバランシングが目的のようで、性能が上がるらしい
- no object(φ)のクラス不均衡対策のため、$c_i = φ$のときは固定値でクラスロス=10としている
ロス計算ができれば、あとは誤差逆伝播して、ネットワークを学習できる。
Transformer部
上図はDETRのTransformer部を詳細化したフロー図で、具体的な流れは以下のような感じとなる。
- CNN出力の特徴マップ(ResNetだと2048チャネル)を、1x1 convolutionでdチャネルに圧縮する
- Transformer encoderへ、サイズ$HW$の特徴マップd個を、$HW$個のd次元特徴として入力する
- Transformer encoderは、$H*W$個の中間オブジェクト特徴(各d次元)を出力する
- Transformer decoderへ、$H*W$個の中間オブジェクト特徴とN個のobject query(後述)を入力する
- Transformer decoderは、N個のオブジェクト特徴(各d次元)を出力する
- N個のオブジェクト特徴それぞれをFFN (Feed Forward Network) へ通して、N個のオブジェクト推論結果(クラス、矩形)が出てくる
※図のpositional encodingについては後述
Transformerを使うことで、各層でグローバルに全オブジェクト特徴を考慮した推論ができるため、上手いこと分離されたオブジェクトの一括推論(direct set prediction)を実現できる。
アーキテクチャは基本的には通常のTransformerであるが、少々細工がされており、以下で簡単に説明する。
アーキテクチャ
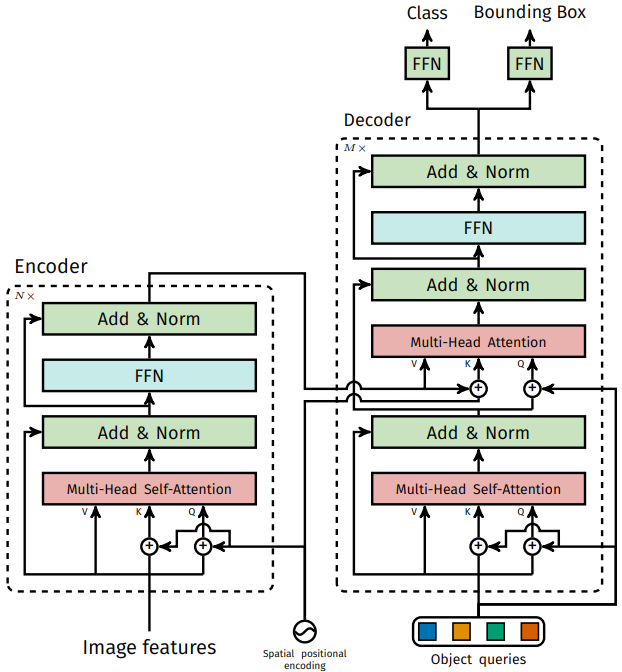
encoderへの入力は、d個の特徴マップの各画素をチャネル方向に結合したもの($HW$個のd次元特徴)が入る。出力も同じ形($HW$個のd次元特徴)である。
decoderへの入力は、encoderの出力に加え、N個のd次元のobject query(=learnt positional encoding)が入る。このobject queryはネットワーク重みと同様の学習パラメータであり、学習して決まるパラメータである。
このように機械翻訳タスクと違って、decoder入力(=N個のobject query)を事前に用意できるため、N個の推論すべてを同時に走らせることが可能である。(parallel decoding)
またpositional encoding(=object queryとspatial positional encoding)を1層目だけでなく各層で使用するようにしており、さらに上図のようにobject query(学習値)とspatial positional encoding(固定値)の両方を場所毎に使い分けることで精度を上げている。(詳細は後述の実験で説明)
Auxiliary decoding loss
オブジェクトの識別性能を上げるために、学習時は補助ロスを用いる。
デコーダの各層の出力にFFN(最終層のコピー)を設けて、各層で最終層と同様の推論をする。
そして、各層でロス計算も同様にして、各層から誤差逆伝播を走らせる。
実験
データセットはCOCO 2017を使い、
モデルは以下を比較する。
- DETR
- NP=100, d=256
- Transformer: encoder層数=decoder層数=6層、head数=8
- Transformerを使っているため、学習epoch数はかなりかかる
- Detectron2 + GIoU(Faster RCNN)
- 学習量の不公平を避けるために、通常の3倍または9倍のepoch数で学習させる(9倍版は
+表記される)
- 学習量の不公平を避けるために、通常の3倍または9倍のepoch数で学習させる(9倍版は
- 共通で使われるバックボーンCNN
- ResNet-50/101
- 特徴マップの解像度2倍版も用意 (DC5)
- 最初の層のstrideを 2→1 に変更
- 最終CNN層をdilated化(=atrous convolution)
- これらの変更により、DETRでは全体の計算量は約2倍に増加する
性能比較
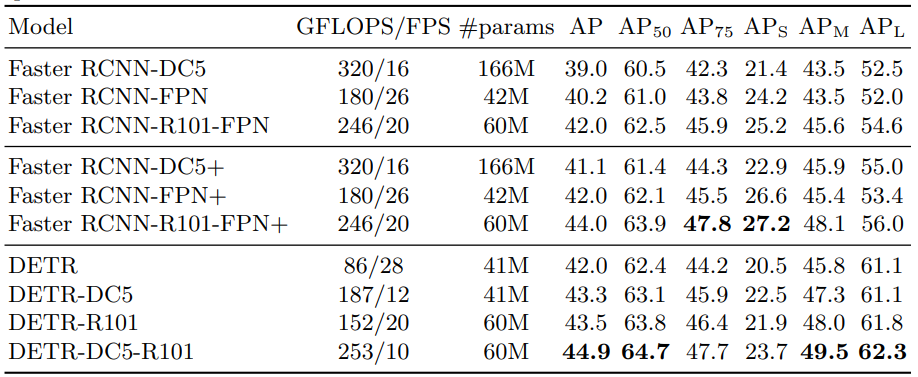
各指標毎に最高性能は太字で表記されている。
全体の結果 ‥‥ DETRは全体的には勝ち。ただし$AP_S$は大きく負け、$AP_L$は大きく勝ってる。
Transformerのおかげでglobalな情報に強い一方で、小さな物体は捉えきれなかった模様である。
NMSなしのアーキテクチャで、最新のアーキテクチャに匹敵する性能を出せたといえる。
(ただ、ResNet-101だと、けっこうFPSが低い。一方で、DC5なしだと同じFPSだが、性能やや負け。)
小物体に対して性能が振るわないが、DETRはシンプルでまだまだ拡張の余地が大きいアーキテクチャであるため、既存の小物体適応技術を適用する等の多くの発展可能性があるはずである。
Ablation study
ResNet-50版のDETRで色んな実験をしている。
Encoder層数

増やすほどに性能向上➡Encoder層数はDETRの重要なファクターである。
Decoder層数
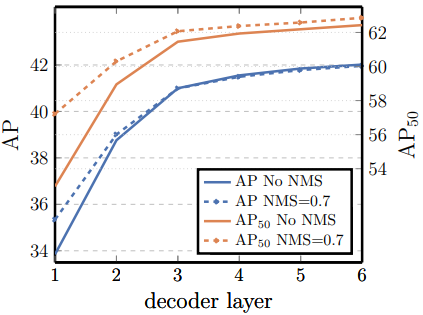
横軸がdecoder層数、縦軸が性能である。
増やすほどに性能向上➡Decoder層数はDETRの重要なファクターである。
また、点線はNMSを付けた結果である。DETRは自動で各オブジェクトを分離してそれぞれ直接推論するので、NMSは不要であるが、それでも同じオブジェクトを2つの別のオブジェクトとして誤って推論する可能性がある。NMSを付けると一応それを防げるので、NMS有無を比較している。
結果としては、decoder層数が少ない(=decoder性能が低い)と、NMSによって性能は上がるが、decoder層数増やすほどにDETR単体で十分になり、NMSの効果は薄まっていくことがわかる。AP評価の6層目ではついに、NMSが別々であるオブジェクトを誤って統合してしまい、NMSが無い方が性能が高いという状況にまで達した。
Positional encoding
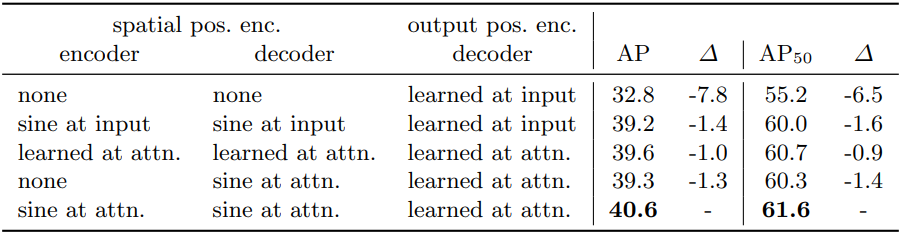
positional encodingの種別(sapatial/learnt)の様々組み合わせを実験している。
最終的な結果としては、Transformerアーキテクチャで説明した図の通りの構成が最高性能となった。
また、両方noneだと性能がかなり下がるが、encoderはnoneでdecoderにだけ用意するだけでも、そこそこの性能が得られることがわかる。つまり、位置情報は性能上極めて重要だが、decoder側だけでも何とかならないこともない。
矩形ロス

GIoUと回帰ロス($l_1$)の有無を組み合わせて実験している。
GIoUは性能への寄与がかなりある。回帰ロスは性能への寄与は僅かだが、あるに超したことはない。
FFN
decoderの外側のFFNを排除してみた。
➡41.3Mから10.8Mにまでパラメータ数を落とせたが、精度も2.3落ちた。
➡FFNも重要なファクターである。
分析
Encoder最終層のattentionマップ

これはEncoderの256スロットの中から、顕著なattentionマップを持つ4スロットを可視化した図である。
Encoderの段階で既にオブジェクト分離できてるのがわかる。
Decoder最終層のattentionマップ

これはDecoderの100スロットの中から、顕著なattentionマップを持つ2スロットを可視化している。
Encoderで大まかなオブジェクト分離は完了しているため、Decoder側ではオブジェクト境界(足や鼻先)を集中して見ることで、精密なオブジェクトの境界線を判断している。
Decoderの各スロット

Decoder出力の100スロットの中から20スロットを可視化している。すべての画像入力毎にこのスロットが推論したオブジェクト位置座標(正方形に正規化)をプロットしている。色はサイズを表しており、緑がsmall・赤が大きい横長・青が大きい縦長である。
結果を見ると、オブジェクトの位置やサイズ毎に、各スロットが役割分担を持っていることがわかる。図の左上のスロットは画像左下の小さなオブジェクト検出用で、図の右上のスロットは画像中央の小さなオブジェクト検出用で、図の左から2番目の下のスロットは画像中央付近のやや大きめのオブジェクト検出用の役割を持っている。
Out-of-distributionの検出

訓練データには1画像中に最大でもキリンは13匹だが、24匹の合成画像を用意して実験している
➡訓練データにないタイプの画像にも対応できた→過学習していない。
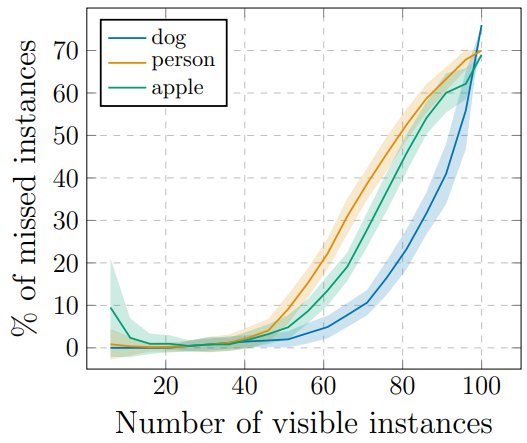
10x10の画像をコピペで貼り合わせて、いくつのオブジェクトまで検出できるか実験している(N=100)
➡50までは上手くできる。それを超すとミス率が一気に増えるが、50までできるのならば上々。
Panoptic segmentation task
DETRがpanoptic segmentation taskを解くように改造し、segmentationタスクでもこのアーキテクチャが効果的であることを実験している。
Segmentation用DETR
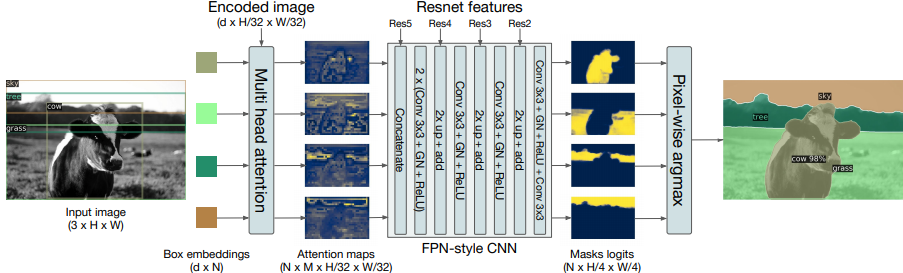
Segmentation用DETRは以下の流れでsegmentationを推論する。
- Decoder出力のオブジェクト特徴(d次元をN個)とEncoder出力の中間オブジェクト特徴(特徴マップ画素数をd個)をattention層に入力する
- attention層から出てきたattentionマップ(N * ヘッド数 個)をFPN-style ResNetに入力する
- FPN-style ResNetが2倍upsamplingを3回繰り返し、8*8倍の解像度になったsegmentation maskをN個出力する
- N個のmaskを統合し(各pixelでargmaxする)、最終的なsegmentation結果ができあがる
ざっくりと以下のような設計をされている。
- DETRと同様にbbox距離を使ってハンガリアンマッチングしてロス計算する
- Dice/F1ロス+Focalロスを使う
- 学習時、最初は通常のobject detectionで学習し、最後の25 epochsでmask学習を行う
定性結果

segmentationタスクへの適用は上手くできている。
定量結果
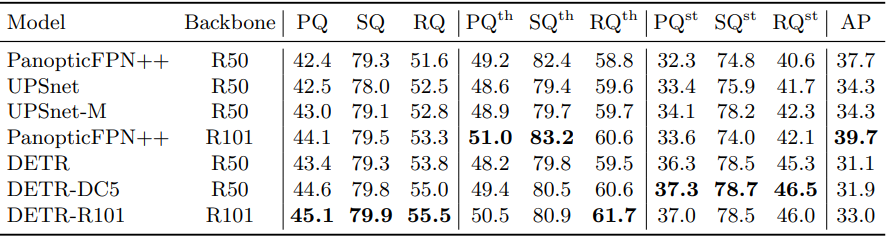
CVPR 2019のSOTAクラスのアーキテクチャであるPanopticFPNとUPSNetと比較されている。
(++は公平を期すために18倍のepoch数で学習している)
結果をまとめると、総合的(PQ)にはDETRが勝っている。
COCOの$AP_S$と同様の理由なためか$PQ^{\textrm{th}}$は僅かに負けているが、$PQ^{\textrm{st}}$ではtransformerのglobal性質の効果が出て大きくリードした結果である。
- 参考
- PQは総合的な性能:$PQ = SQ * RQ$
- SQはsegmentation的な性能
- RQはinstance segmentation的な性能
- th: Thingsクラス=人、車、等
- st: Stuffクラス=壁、空、等
- PQは総合的な性能:$PQ = SQ * RQ$
結論
要約と概ね同じなので省略
おまけ:シンプルなのでmodelは30行で書ける
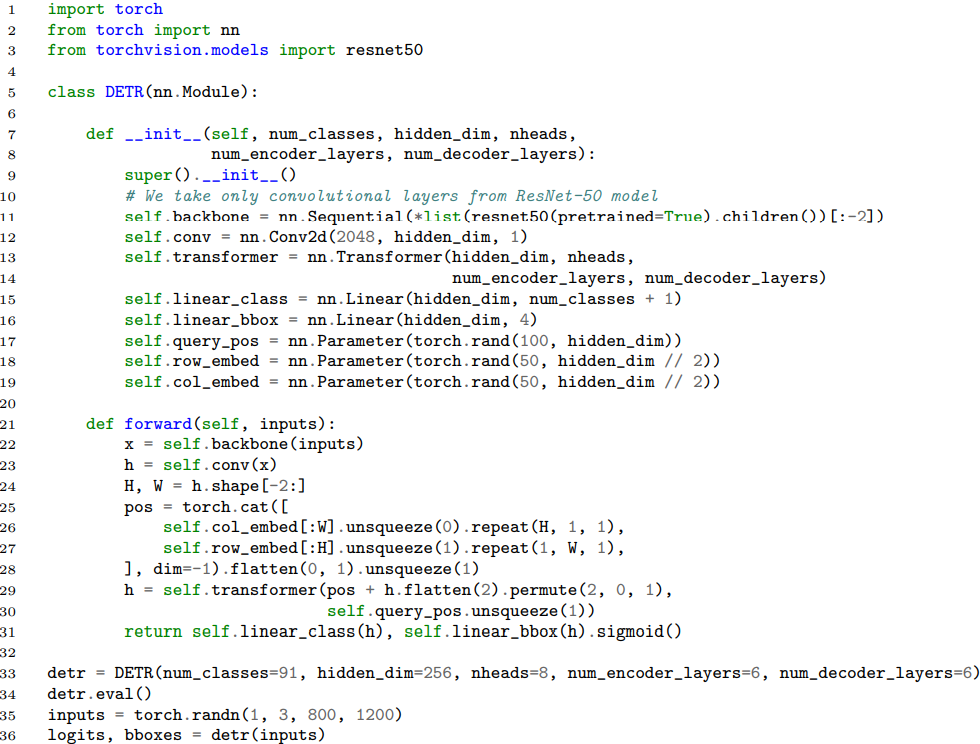
※実験構成と完全に同じではない。例えば、spatial positional encodingは存在しない。