本書は時系列データを別の時系列データに変換するSeq2Seqについて、RNN、LSTMからAttentionまで説明します。また、Attentionを用いた最新の様々な自然言語モデルのベースとなっているTransFormerについても説明します。(CNNの基礎を理解している前提で記載しています。まだ理解していない方は別冊のCNNの基礎を先に読んでください)
Seq2Seqを基礎から理解するために、本書では以下の順番で説明を行います。最初に時系列データを扱うシンプルな構造であるRNN(Recurrent Neural Network)からはじめ、RNNを性能改善したLSTM(Long Shot Term Memory)、Encoder-Decoderモデル、そして本書の目的であるSeq2Seqの順に説明を行います。さらにSeq2Seq に劇的な進化を起こすディープラーニングにおける重要なアーキテクチャの1つであるAttentionについて説明を行います。そして、昨今の大幅に性能を向上させた自然言語処理モデルであるBERTやGTP2/GTP3のベースとなっているAttentionを活用したTransFormerモデルについて説明を行います。
本書は筆者たちが勉強した際のメモを、後に学習する方の一助となるようにまとめたものです。誤りや不足、加筆修正すべきところがありましたらぜひご指摘ください。継続してブラッシュアップしていきます。 © 2021 [NPO法人AI開発推進協会](https://sites.google.com/deepaelurus.com/aboutus/home)【参考文献、サイト】
- ゼロから作るDeep Learning2(自然言語処理編)
- LSTMネットワークの概要
- 作って理解するTransFormer/Attention
- 自然言語処理の必須知識TransFormerを徹底解説!
- Google AI Blog Transformer: A Novel Neural Network Architecture for Language Understanding
- Attention Is All You Need
1.RNN/LSTM
(1) RNN(Recurrent Neural Network)
RNNは、その名(Recurrent)の通りループする経路を持ち、時系列データである$x_t$を入力すると隠れ状態である$h_t$($h_t$には過去からの情報が記録される)を出力します。RNNの特徴は、このように1つ前の時刻の隠れ状態$h_{t-1}$を利用して過去の情報を引き継げることにあります。
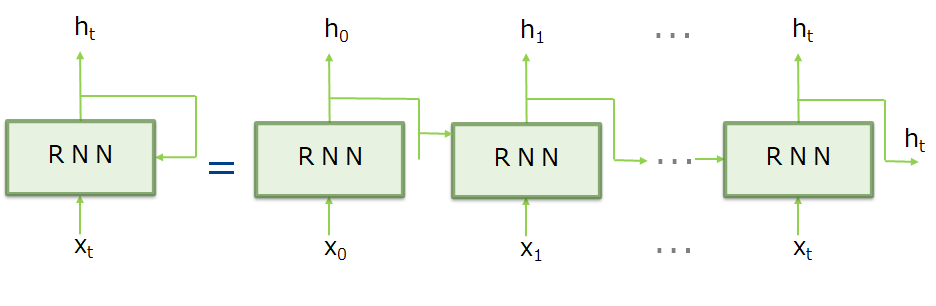

(2) RNNでの勾配消失および勾配爆発について
RNNでは勾配消失や勾配爆発が内在しています。これは何層ものレイヤの逆伝播計算時に、重み(w)や活性化関数(tanh)の微分を掛け合わせるからです。
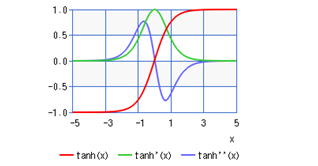
上図3の活性化関数の微分のグラフから分かるようにtanhの微分は「0~1.0」の範囲であり、xが0から遠ざかるとその値は小さくなります。したがって逆伝播において勾配がtanh活性化を通過するたびに勾配の値はどんどん小さくなっていくため、勾配消失が発生します。
一方全結合の逆伝播($W_x、W_h$)では、以下の図のように(この例では隠れ層であるhの勾配を示す)、上流から伝わってきた勾配$d_h$が重みWとの行列積で伝わっていきます。

RNNでも数十ステップの短期依存(short-term dependencies)には対応できますが、数千ステップ以上のような長期の系列になると、活性化関数にtanhを使っているとはいえ(sigmoidよりは勾配消失・爆発が起こりにくい)、無視できないくらい勾配が小さく(もしくは大きく)なってしまい、勾配消失(爆発)が発生します。
(3) 勾配爆発への対策
勾配爆発への対策として、定番の方法として勾配クリッピング(gradients clipping)があります。 [Pascanu+ 12]において、BengioらのチームはRNNにおける勾配爆発問題が起こる必要条件がリカレント重み行列w_recの最大の特異値にあることを証明し、その明快な回避方法として以下のアルゴリズムに従う勾配クリッピングを提案しています。
$\hspace{20mm} if \parallel\hat{g}\parallel \hspace{3mm}\geqq\hspace{3mm} threshold(しきい値): $
$ \hspace{30mm} \hat{g} = ( threshold \hspace{3mm}/ \hspace{3mm}\parallel\hat{g}\parallel) × \hspace{3mm}\hat{g} $
ここで「g^」は、ニューラルネットワークで使われるすべてのパラメータに対する勾配を一つにまとめているものです。上記の式はシンプルに言えば、
$ \hspace{30mm} -threshold < \hspace{3mm}\parallel gradient \parallel \hspace{3mm}< threshold $
を実施すことを意味しています。
(4) 勾配消失への対策
勾配消失に対処するには、RNNレイアのアーキテクチャを根本から変える必要があります。この対応アーキテクチャが「ゲート付きRNN」で、様々なアーキテクチャが提案されていますが、その代表的なものが「LSTM(Long Short Term Memory)」です(他に代表的なものとしてLSTMをもう少しシンプルにしたGRU(Gated Recurrent Unit)があります)。
(5) LSTMの入出力
RNNとLSTMとの違いは、下図に示すように記憶セル(c)の入出力有無の違いです。記憶セルはLSTM専用の記録部に相当しLSTM層間のみで入出力します(上下層には渡さない)。この記憶セルが勾配消失を防ぐ鍵となっています。
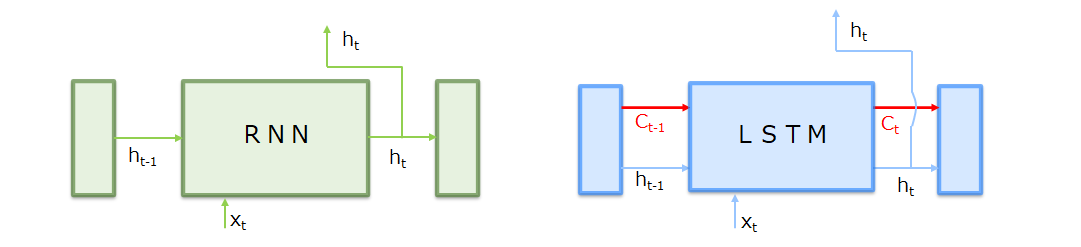
LSTMレイヤ内での記憶セルは以下のように、一種のコンベア・ベルトのようにLSTMの層(時間軸)をまっすぐに走り、情報を連鎖します。
ではなぜこの記憶セルによる勾配消失を抑止できるのか、それは学習時の逆伝播を見ればわかります。
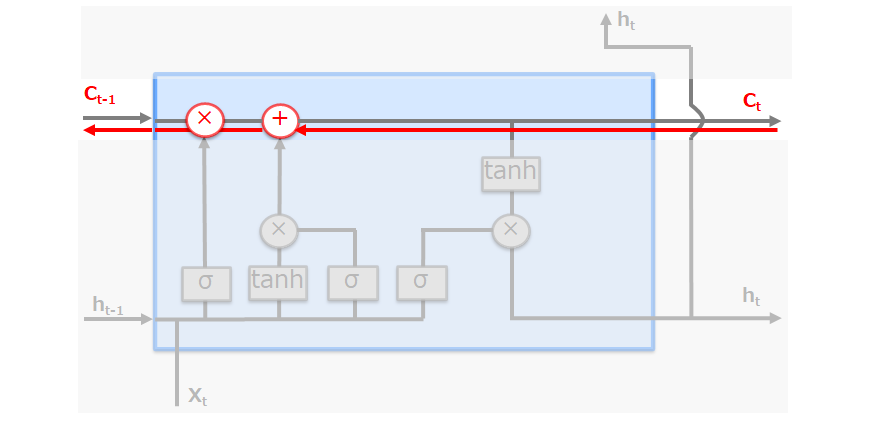
記憶セルの逆伝播では、上図のように「+」と「×」ノードだけを通ることになります。「+」の逆伝播(微分)では上流から伝わる勾配をそのまま流すだけです。残る「×」ノードは、RNNと違い「行列の積」ではなく「アダマール積(要素ごとの積)」で、毎時系列で異なるゲート値によって要素ごとの積の計算が行われるため、勾配消失を起こさない・起こしにくくなっています。勾配消失は多層でシグモイド関数やtanh関数が重なることで起こる (例えばシグモイド関数の値域は 0 ~ 1/4 なので掛ける回数が増えると勾配が 0 に近づく) ので、非線形変換を持たない記憶セルは勾配を残しやすくなります。
記憶セルを含め、LSTMのモデル中身は下図のようになっています。
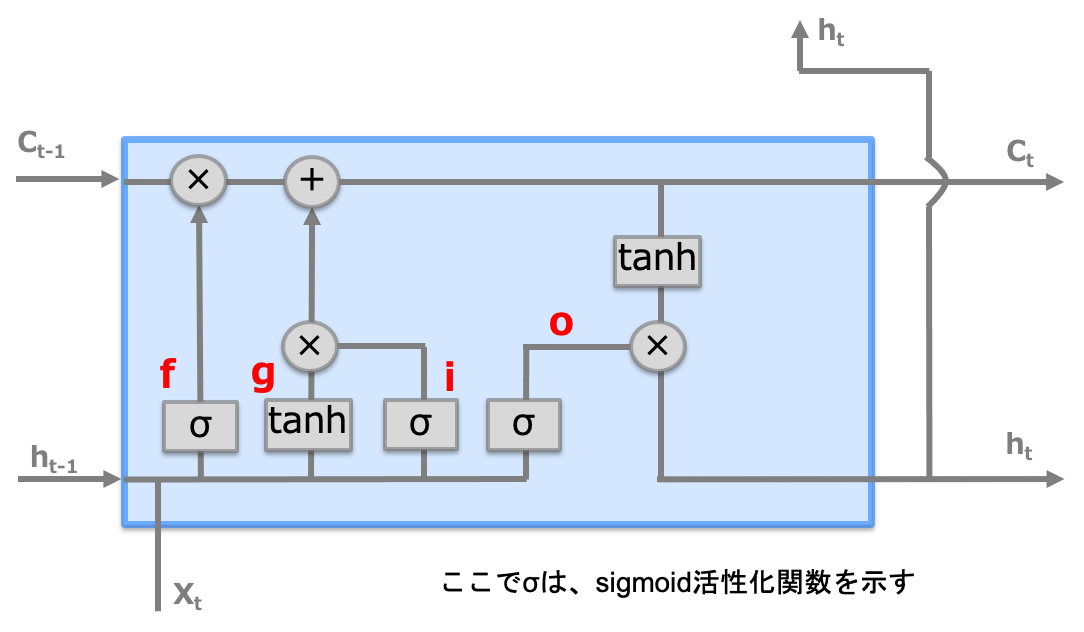
① f(forgetゲート)
記憶セルに対して「何を忘れるのか」を明示的に指示します。
$\hspace{20mm} f = \sigma(x_{t}W_x^f + h_{t-1}W_h^f + b^f) $
② g(新しい記憶セル)
forgetゲートだけでは忘れることしかできないため、あたらしく覚えるべき情報を記憶セルに追加します。
$\hspace{20mm} g = \tanh(x_{t}W_x^g + h_{t-1}W_h^g + b^g) $
③ i(Inputゲート)
g(新しい記憶セル)の各要素が新たに追加する情報としてどれだけ価値があるのかを判断(追加する情報の取捨選択)します。
$\hspace{20mm} i = \sigma(x_{t}W_x^i + h_{t-1}W_h^i + b^i) $
④ O(Outputゲート)
隠れ状態(ht)は記憶セル(Ct)に対してtanh関数を適用して算出されますが、これが次の時刻の隠れ状態としてどれだけ重要かを判断します。
$\hspace{20mm} o = \sigma(x_{t}W_x^o + h_{t-1}W_h^o + b^o) $
注意)f、i、oはゲートですが、gはゲートではないことに注意してください
2.Encoder-Decoderモデル
Inputデータ(画像やテキスト、音声等)を何かしらの特徴ベクトル(固定長)に変換する機能をEncoderといいます。また、Encoderで生成された特徴ベクトルをデコードして新しいデータ(Inputと同じである必要はなく画像やテキスト、音声等)を生成する機能をDecoderといいます。
Encoder-Decoderモデルは文字通りEncoderとDecoderを繋げたものであり、画像 -> テキスト、音声 -> テキスト、英語 -> 日本語等、様々な生成が行えます(いわゆる生成モデル)。

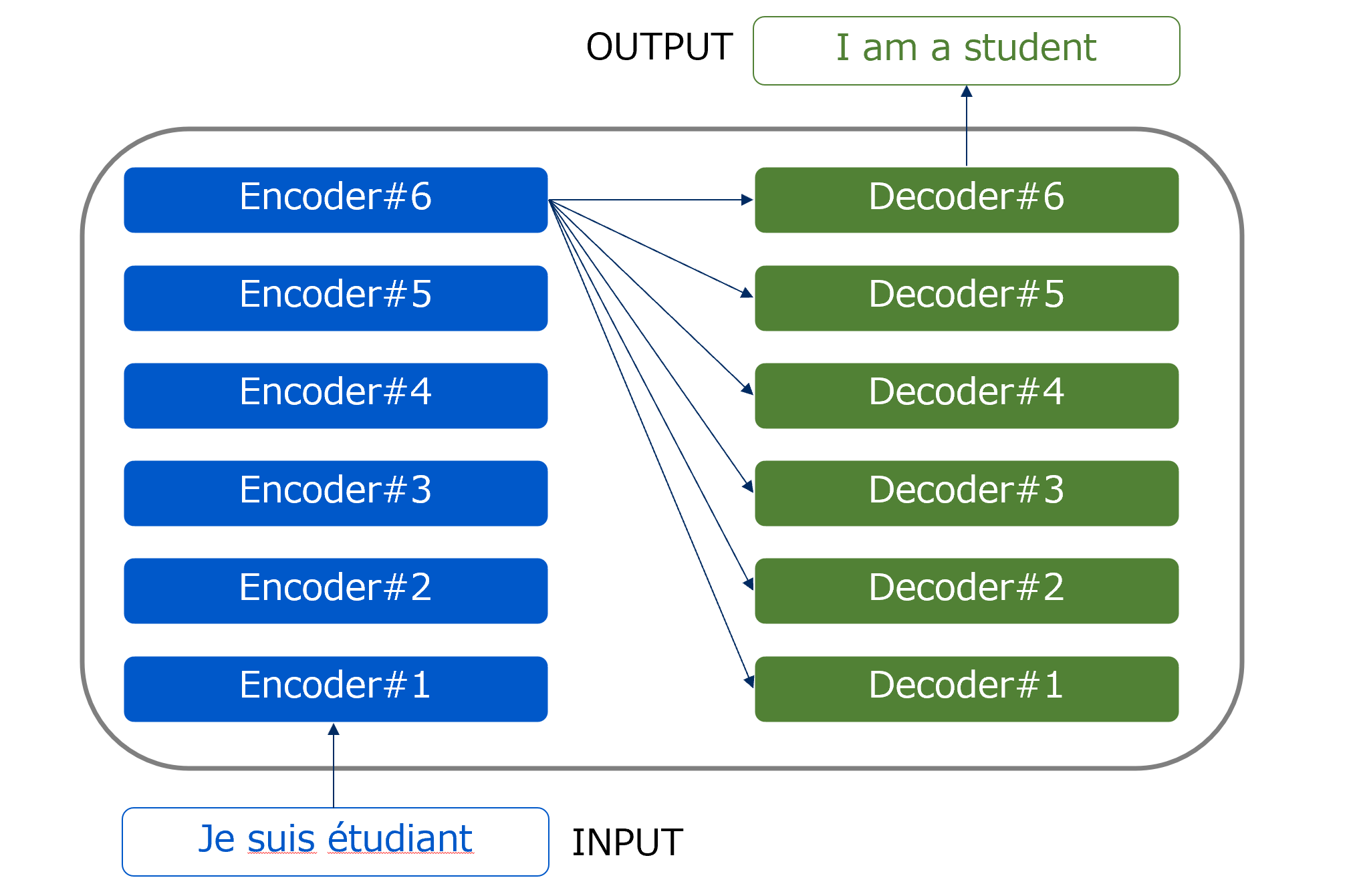
3.Seq2Seqモデル
Seq2Seqは「Encoder-Decoderモデル」を使って、系列データを別の系列データに変換するモデルである。適用例として、翻訳や対話モデル(チャット)の実装が可能になります。
(1) Encoder側
LSTMで最後の隠れ層のベクトルを生成するのみです。なお、LSTMでなくRNNやGRU等のモデルが使われる場合があります。
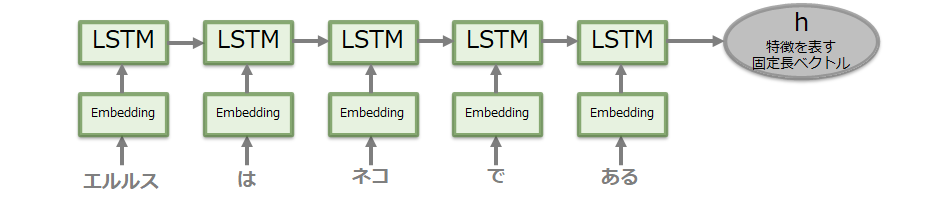
(2) Decoder側
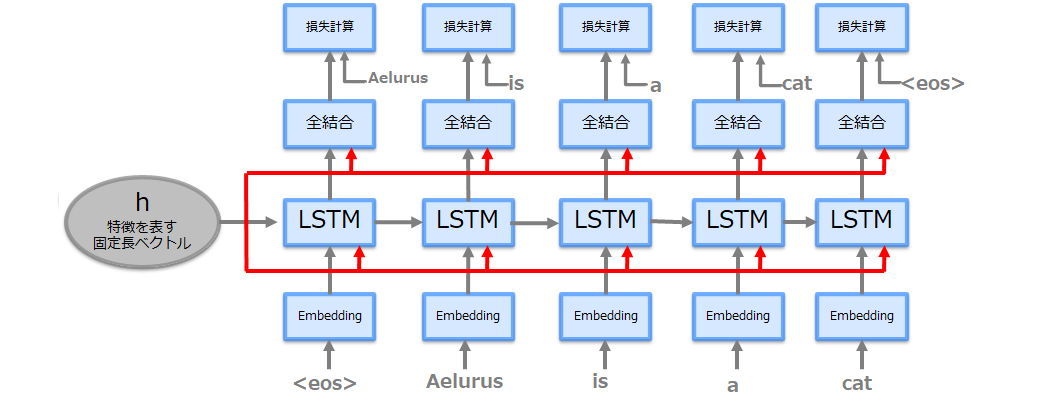
Encoderで生成された隠れ層と文字生成開始を知らせる特殊文字(下図では<eos>(他<go>、<start>、_(アンダースコア)、等何でも良い)を与え、以降は出力された文字を次のLSTM層へのインプットにして生成すべき文字の数だけ繰り返します。
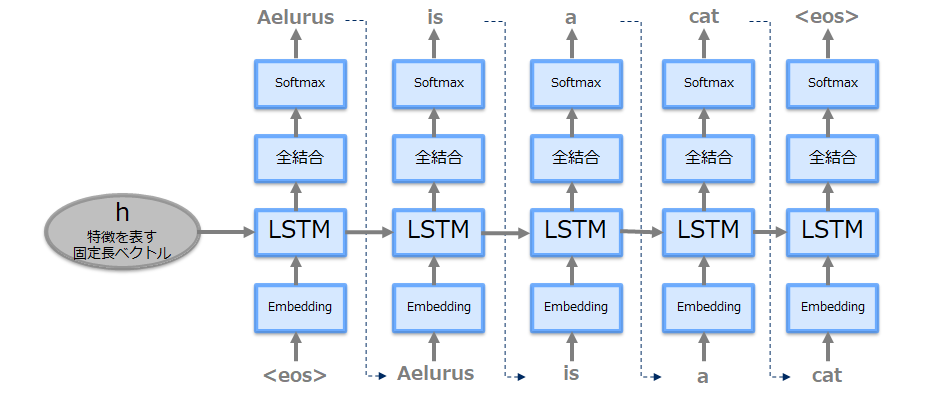
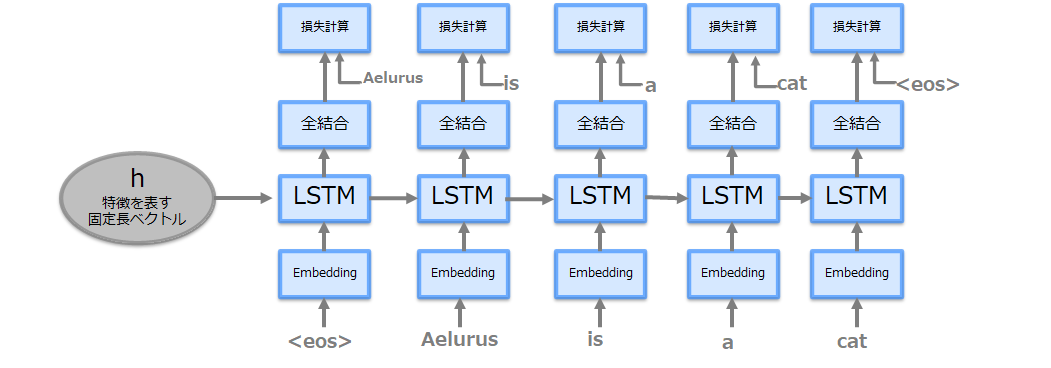
上記は推論時のモデルであり、学習時は以下のようになります。(正解ラベルを与え損失計算が加わる)
(3) Seq2Seqの工夫
Seq2Seqの学習の効率化に向けたモデルの改善として「Reverse(入力データの反転)」と、「Peeky(特徴ベクトルの覗き見)」があります。
-
Reverse(入力データの反転)
単純に入力データの順序を反転させるものです。多くの場合学習の進みが早くなり精度も改善されます(この理由について論文上はソースセンテンスとターゲットセンテンスの間に多くの短期的な依存関係が導入され、最適化問題が容易になるためとされています)。
https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks -
Peeky(特徴ベクトルの覗き見)
これまでのSeq2Seqのモデルでは、Encoderが生成した固定長の隠れベクトル「h」(=Decoderにとって必要な情報がすべて詰まっている)をDecoderの最初のLSTM層のみが入力として使っていました。この隠れベクトル「h」をDecoderの各層にも与え、学習の進みと精度を改善します。これを「Peeky Seq2Seq」といいます(モデルネットワークを以下参照)。
4.Attention
「Attention」はSeq2Seqに劇的な進化を起こすディープラーニングにおける重要なアーキテクチャです。これは大雑把に言うと、Seq2SeqのEncoderに時系列での特徴ベクトルを保持し、Decoderの各層に入力データと相対するどの特徴ベクトルに注意を払うかの「Attention層」を入れ込むようなイメージです。
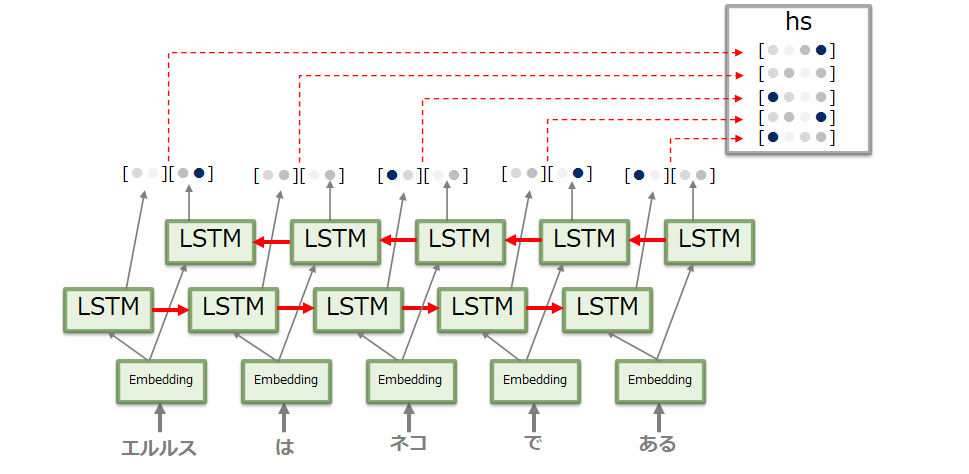
(1) Encoderで生成する特徴ベクトルの改良
Seq2Seqでは、Encoderが出力する固定長の隠れベクトルでは、入力データの長さにかかわらず常に同じベクトルに変換しなければなりませんでした。これでは長い入力データではその特徴をうまく詰め込むことができません。このため入力されるデータ長に応じて生成される特徴ベクトルの長さを変える、すなわち各LSTM層で生成されるベクトルをすべて利用するように改善し、各時系列の特徴ベクトルを蓄積(hs)するようにします(下図13参照)。

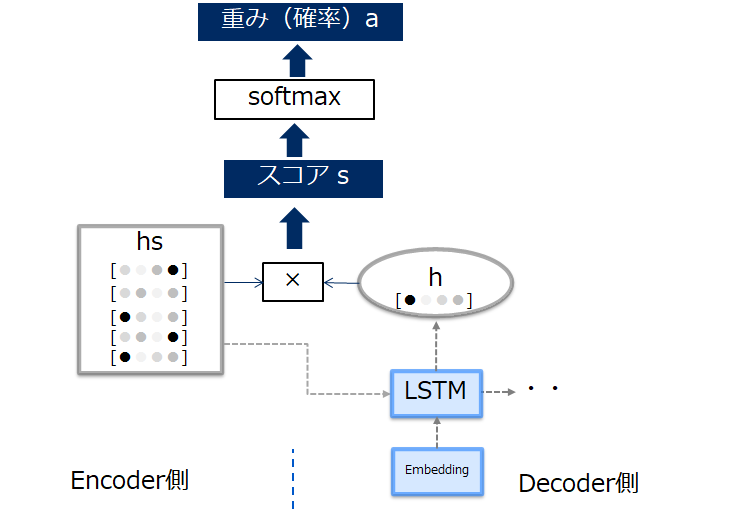
(2) Decoder側での処理(重み付きベクトルとコンテキストベクトル)
Decoder側では、Attention層を加え上記Encoderで生成した各時刻の特徴ベクトルを入力します。このとき、Decoder側の各層では自層の入力と対応関係にあるベクトルを選び出します(これをアライメントといいます)。
この選び出す操作は、各入力の重要度を表す重み「a」を別途計算することで実施します。この重み「a」と特徴ベクトルとの和を「コンテキストベクトル」といいます(このベクトルはその層での入力データと関係のある成分が多く含まれたベクトルになります)。

この重み「a」はデータから自動で学習します。これはDecoder側でのLSTM層で出力された隠れベクトルhと、Encoderで生成された入力データ各層の隠れベクトルhsから求めます。
(3) 双方向RNN/LSTM
これまでのRNNやLSTMは左から右へ時系列に処理しています。そのため、時系列の途中では左端から該当時間までの入力データの情報がエンコードされています。これを逆に右から左へ時系列に処理してバランスよい隠れ状態ベクトルを生成するのが双方向RNN/LSTMです。各時刻での隠れ状態のベクトルは「連結」したり、「和」や「平均」をとる方法があります(以下に連結した場合の例を示します)
(4) Attentionレイヤの配置場所
Attentionレイヤの配置はこれまでの例に示したLSTMと全結合の間で固定ではなく様々な実装のやり方があります(詳細はそれぞれのモデルの説明を参照ください。)。
(5) LSTM層の深層化とSkipコネクション
LSTMの層も1層ではなく深く重ねることでより高い表現力が生成されます。この場合、EncoderとDecoderの層を同一にするのが一般的です。
なお、層を深くするときに使われるテクニックとして「skipコネクション」が様々なモデルで多用されています。層をまたいで隠れベクトルを連携することで、勾配の消失(もしくは爆発)を抑止し学習精度を上げることができます。具体的には準方向の層の跨ぎは2つの隠れ層ベクトルhの出力を加算するため、勾配は何の影響を受けることなく前層へ伝えることができます。

5.そして、Transformerの登場
Attentionの利用により精度が高まりましたが、LSTM/RNNで時系列データを逐次的に処理しているためデータの並列処理ができず高速化ができない課題は解決されていないままでした(Attention付きCNNを用いたモデルも考案されたが、長文の依存関係モデルを構築することが難しかった)。2017年にGoogle社が発表した「Attention is All You Need」という論文で、RNN/LSTMおよびCNNを用いず、「Attention」のみを用いた「Transformer」を提案し、従来のモデルで抱えていた「高速化ができない」、「精度の高い依存関係モデルを構築できない」という課題を解決しました。
Transformerは、昨今のBERTやGPT2/GPT3といった最新のNLPモデルの基礎モデルであり、またDETR(別冊で掲載)などの画像認識にも使われている重要なモデルです。
(1) Transformerの特徴
主なモデルの特徴としては以下になります。
-
RNNやCNNを使わずAttention層のみで構築
後述するSelf-Attention層とTarget-Source-Attention層のみで構築することで、並列処理が可能となりました。 -
PositionalEncoding
RNN/LSTMを利用しないことで失われる文脈情報を、入力する単語データの文全体での位置情報を埋め込みます。 -
Attention層におけるQuery-Key-Valueモデルの採用
より単語同士のアライメントをより正確に反映することができるようになりました。
(2) Tansformerの構造
TransformerはSeq2Seqと同様Encoder-Decoderモデルであり、Encoder-Decoderで異なる時系列データが入力されています。
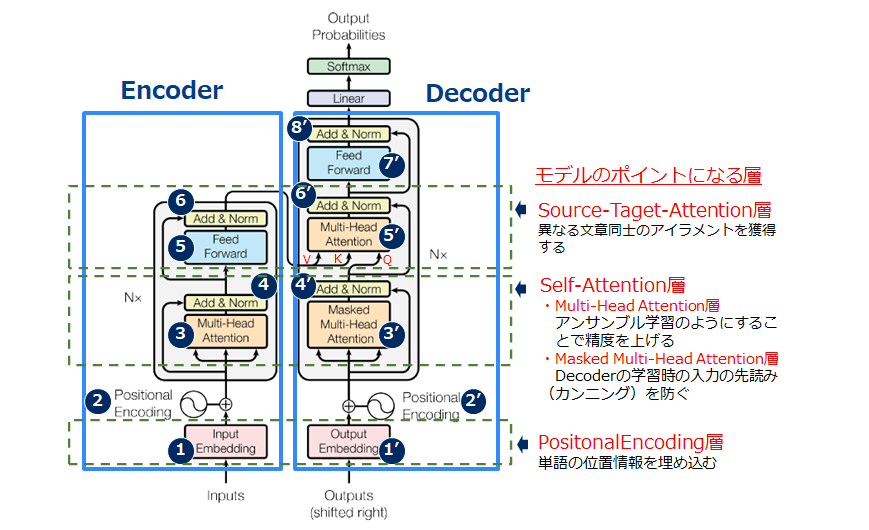
③~⑥をN回繰り返す
③~⑧をN回繰り返す
(3) 予測のための構造
Decoderの出力結果をLiner(線形変換)+softmaxで各ラベルの予測確率を計算して、予測した結果を出力します。
(4) モデルのポイントとなる各層の説明
a) PositionalEncoding層
Transformerでは、RNNやCNNを使わないので文脈情報(単語同士の長期依存関係)を取得できないため単語列の語順(位置情報)を明示的に付与する必要があリます。PositionalEncodingは、各要素に「n番目」というような文中の位置が一意に定まる情報を付与します。実際には、周波数が異なるSin関数・Cos関数の値をEmbedding後の文(input, output)の行列に加算することで、各単語と文脈(位置)情報を考慮した情報を取得します。
PE(pos,2i) = sin(pos/100002i/dmodel) …①
PE(pos,2i+1) = cos(pos/100002i/dmodel) …②
※posはセンテンス中の出現位置 (0,1,...,T)、iは次元数(単語の分散表現の次元数)
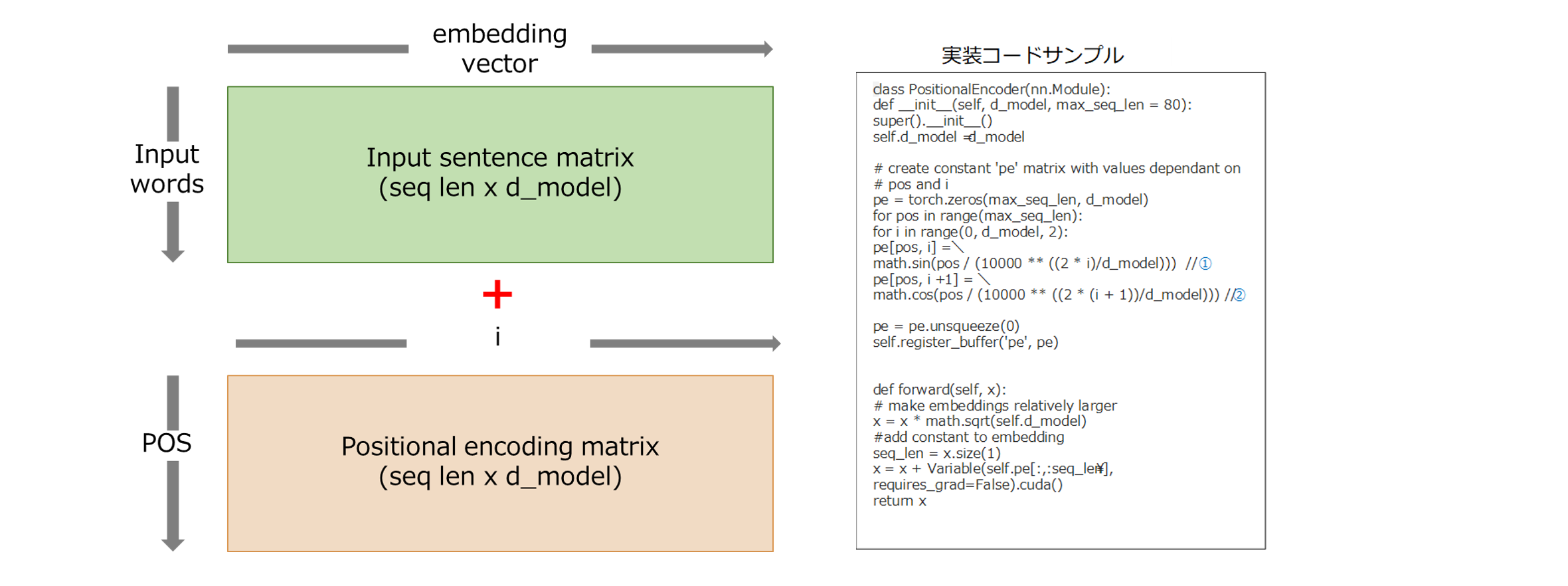
出展:How to code The Transformer in Pytorchを参照に加筆
b) Self-Attention層
Self-Attentionは、従来のSeq2Seqモデルで使われていたエンコーダとデコーダ間のAttentionを発展させ、同じ系列内の単語同士で行うAttentionです。これにより、各単語が文全体の他の単語を一度に参照できるようになり、長い文章でも離れた単語同士の関係を効率的にとらえることができます。また、Attentionは並列処理ができるため、RNNのような逐次処理よりも高速に学習が可能です。
ex.
・従来のAttention
I have a cat. $\hspace{2mm}\leftrightarrow$ 私は猫を飼っています
$\to$ このとき、例えば「I」は、特に「私」や「飼っています」とのアライメントを獲得する
・Self-Attention
I have a cat. $\hspace{2mm}\leftrightarrow$ I have a cat.
$\to$ このとき、例えば「I」は、特に「I」や「have」とのアライメントを獲得する
Self-Attentionを行うことで同一センテンス内の類似度が獲得され、特に多義語や代名詞などが実際に何を指しているのかを正しく解釈できるようになりました。
ex.
・The animal didn’t cross the street because it was too tired.
$\to$ このときの「it」は「animal」
・The animal didn’t cross the street because it was too wide.
$\to$ このときの「it」は「street」
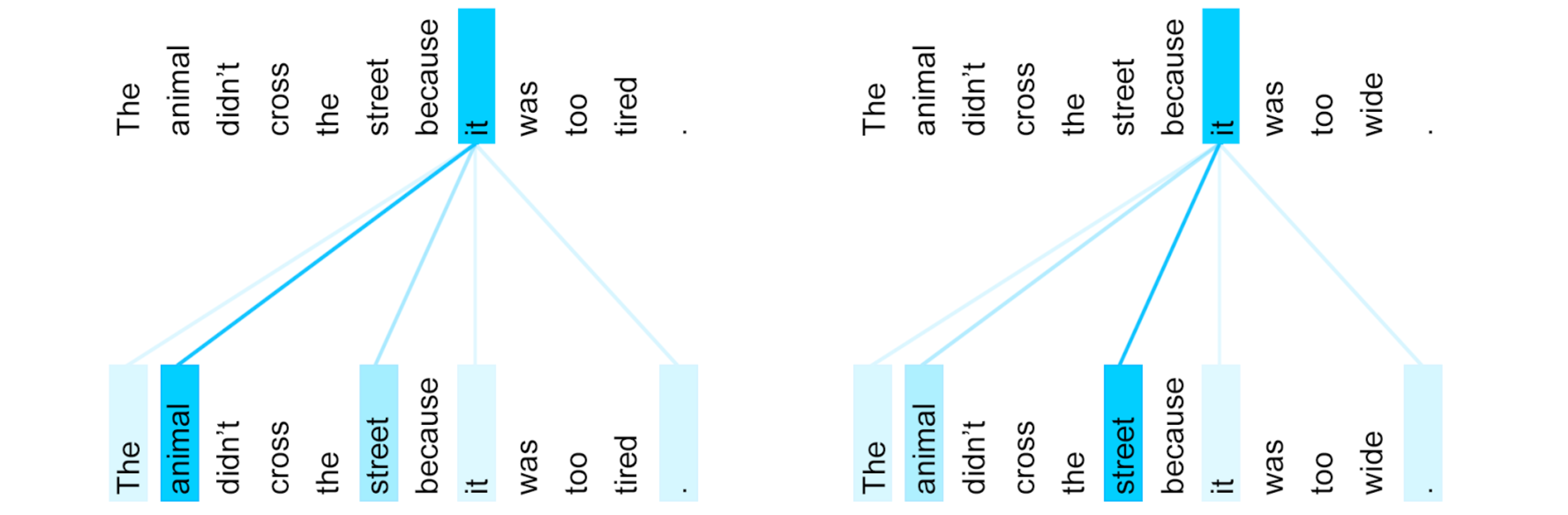
出典 Transformer: A Novel Neural Network Architecture for Language Understanding
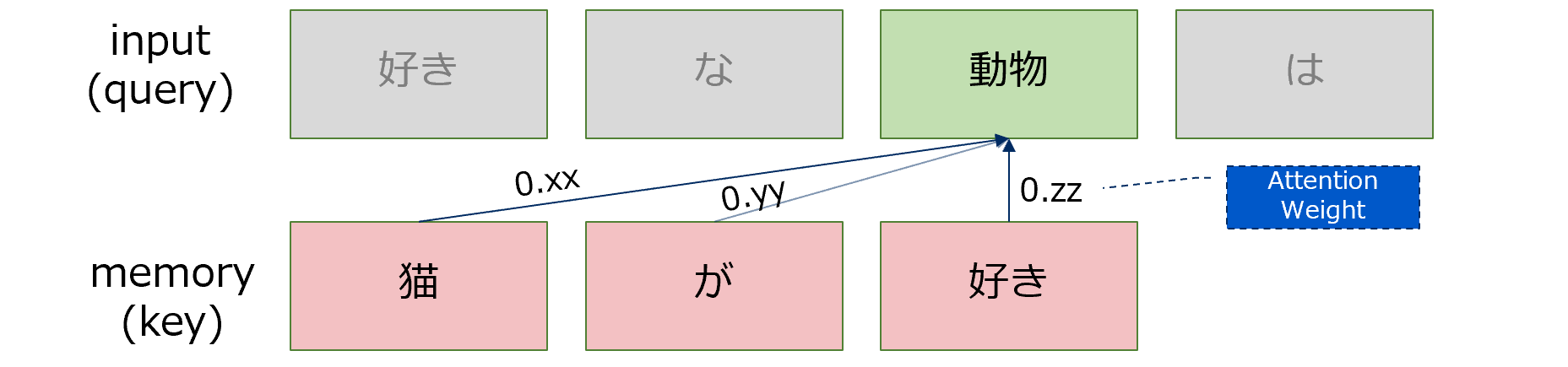
実装の基本となるのは、queryとmemory(key, value)です。 queryによってmemoryから必要な情報を選択的に引っ張ってきますが、queryはkeyによって取得するmemoryを決定し対応するvalueを取得します。一方、学習は元データ(memory)と検索をかけたい入力(input)の関連度を学習するだけです。一般的には下記のフローとなリます。
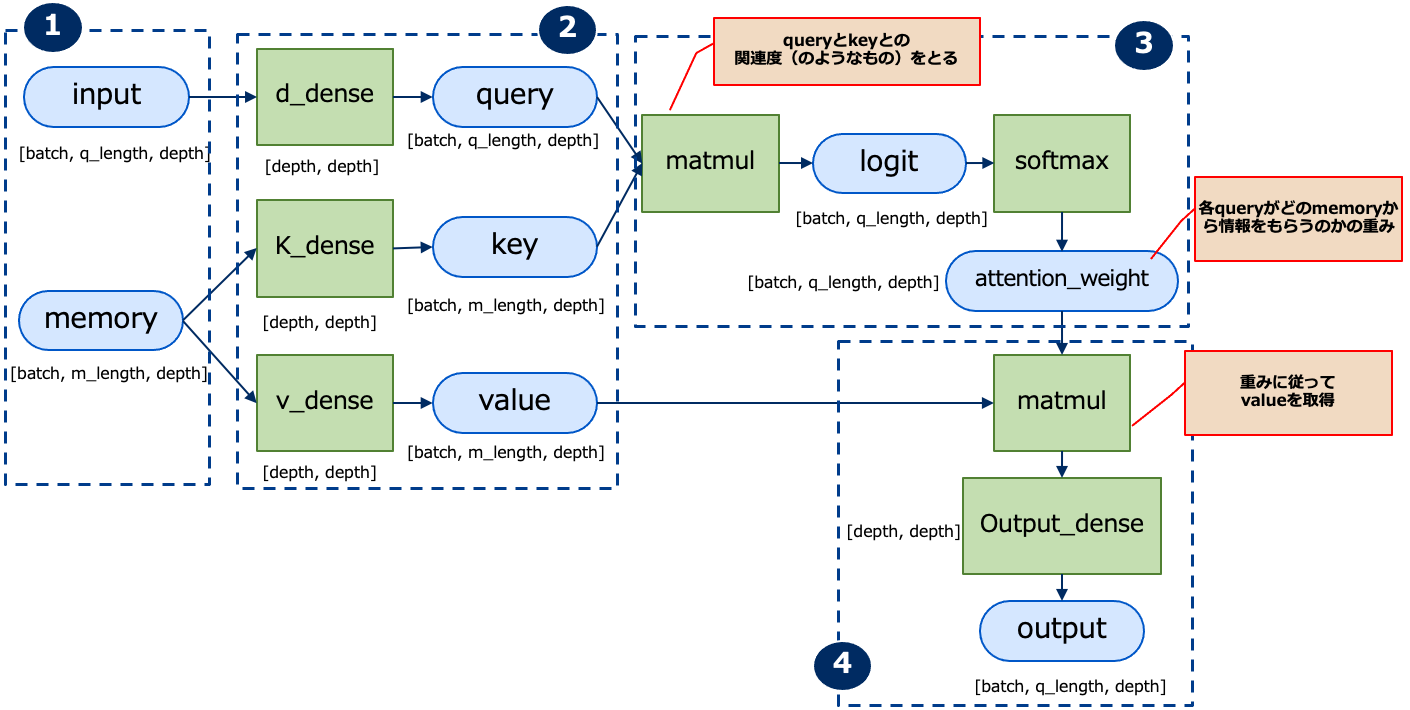
① Input、memory
input(query)は入力時系列、memoryは引いてくる情報の時系列。
ベクトルのlengthは文章中のトークンの長さ(例えば1文の中の最大単語数等)、depthは各単語をEmbeddingしたときの次元数。
ex.
input :「好き」「な」「動物」「は」
memory:「猫」「が」「すき」
このとき、input(query)のlengthは4、memoryのlengthは3となる。
また、「depth」はdepth次元の単語の分散表現(n次元のベクトル、Transformerのデフォルトでは512次元)にしたものとなる。
② Query-Key-Value
inputデータは全結合層(Dense)でquery(ベクトル)に、memoryは2つの全結合層(Dense)でそれぞれkey(ベクトル)、value(ベクトル)に変換されます。このとき入力データをα、depthの次元をn、重みをW(それぞれWq、Wk、Wv)とすると以下のように計算されます。
Qn = Wq × αn
Kn = Wk × αn
Vn = Wv × αn
③ attention weight
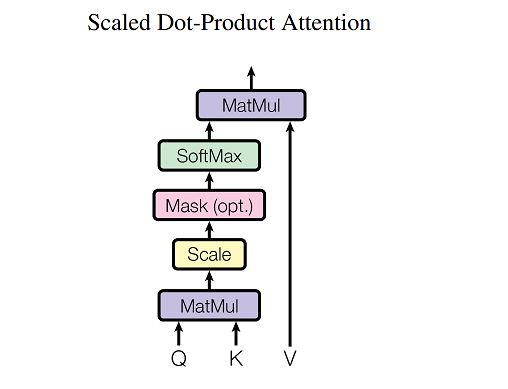
queryは、memoryのどこから情報を引いてくるのかを決めるためにkeyを使います。例えば、「動物」というqueryに対して、「「猫」がxx%、「が」がyy%、「好き」がzz%」というような計算をします。具体的には、queryとkeyとの行列積(matmul)を行います。行列積をとった後はsoftmaxにより確立に落としていきます(★この辺りは従来のAttentionと同じ考え方)。
$\hspace{25mm} Attention(Q, K, V) = softmax (\frac{QK^T}{\sqrt{d_k}}) V$
$\hspace{25mm}$ ※この式は図22の③、④を実装したものになります
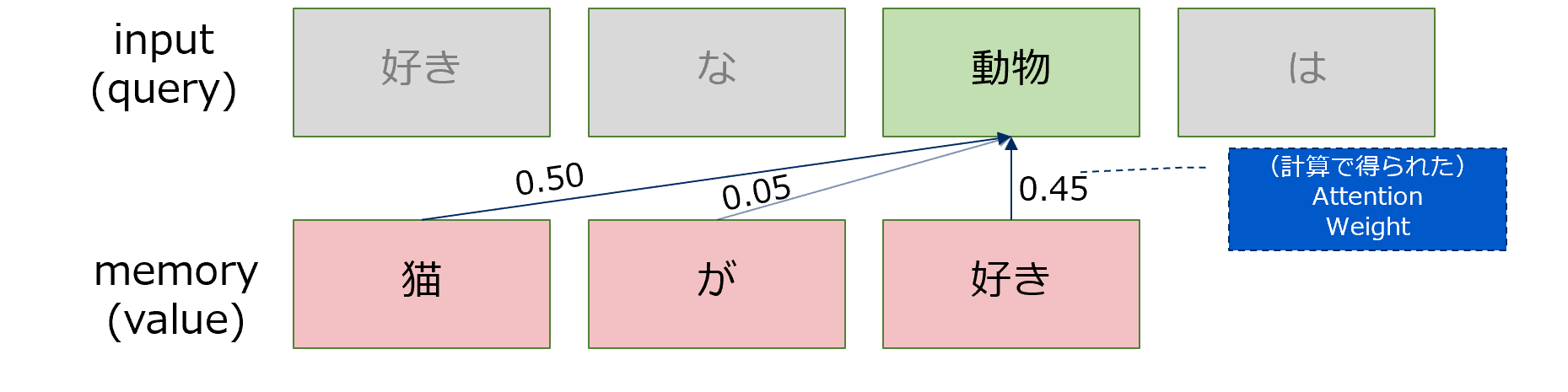
④ attention weightに従ってvalueから情報を引き出す
attention weightとvalueの行列積を取ることで、重みに従ってvalueの情報を取得します。
c) Multi-Head Attention層
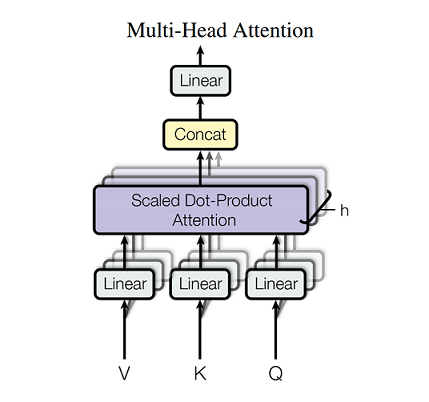
各単語に対してヘッド数分だけのQuery、Key、Valueの組をつくり、それぞれのヘッドで異なる組を用いて潜在表現を計算する方法です。最終的にそれらを1つのベクトルに落とすことで、ある単語のもつ潜在表現とします(アンサンブル学習のようなもの)。
具体的には、それぞれのheadの潜在表現を結合(concat)し、それを重みで掛け算することで元の次元に戻してその層のOutputとします。
一般的にはMultiHeadの方がSingleHeadよりも高い性能が出ます。これは、SingleHeadで深く潜在変数を処理するよりも、ヘッドが異なれば処理している潜在表現空間も異なるという事実からMultiHeadで複数の潜在表現を処理してまとめる方がより広範囲に豊かな情報を取ってくることが可能なためです。
d) Masked Muiti-Head Attention層
訓練時のデコーダでは、全ターゲット単語を同時に入力し全ターゲット単語を同時に予測します。このため、入力した単語が先読みを防ぐために情報を遮断するマスクをするオプションがあります(評価/推論時は、逐次的に単語列を生成するので必要はありません)。 例えば3番目の単語を予測する際には最初と2番目のみ使用、4番目の単語を予測する際には1番目、2番目、3番目の単語のみ使用するようにします。
具体的には、maskは特定のkeyに対してattention_weightを0(重みゼロ)にすればその項目はマスクされます(ただし、attention_weightはsoftmaxの出力なので、その入力であるlogitに対しては-∞に値を置き換えることになる)。
なお、マスクは先読みを防ぐ目的以外にも、PADを無視するためにも使います。以下に例を示します。
ex.
Key_length = 3のときのPADの例
[
おはよう /<PAD> / <PAD>
猫 /が /すき
お腹 /すいた / <PAD>
]
e) Source-Target-Attention層
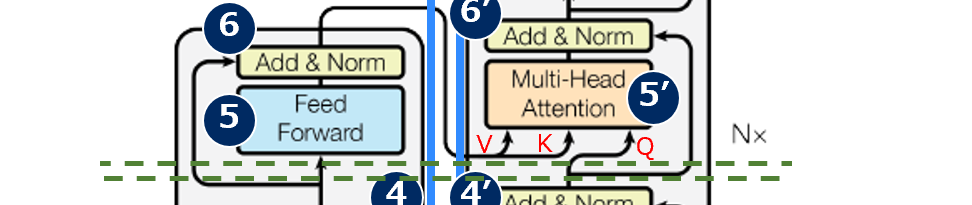
Self-Attentionと同様にQuery-Key-Value構造を持ちますが、Source-Targer-Attentionは、異なるデータ間のアライメントを獲得します(従来のAttention)。KeyとValueはEncoderの隠れ層(Source)からきて、QueryはDecoderの隠れ層(Target)からきます。
これはTansformerの構造図の⑤‘部分が該当します。
【補足】Key-Valueモデル
これまでのAttentionでは、Target、Sourceという2つの変数からアライメントを見ていました。
Transformerでは前述のとおり、Target=Query、Source=Key、Valueという3つの変数からアライメントをより適切に反映させています。これはアライメントをただ持たせるだけでなく辞書表現のように探索用(Key)と内実用(Value)に分離することで、より適切な表現力が得られるという考えに基づいています。
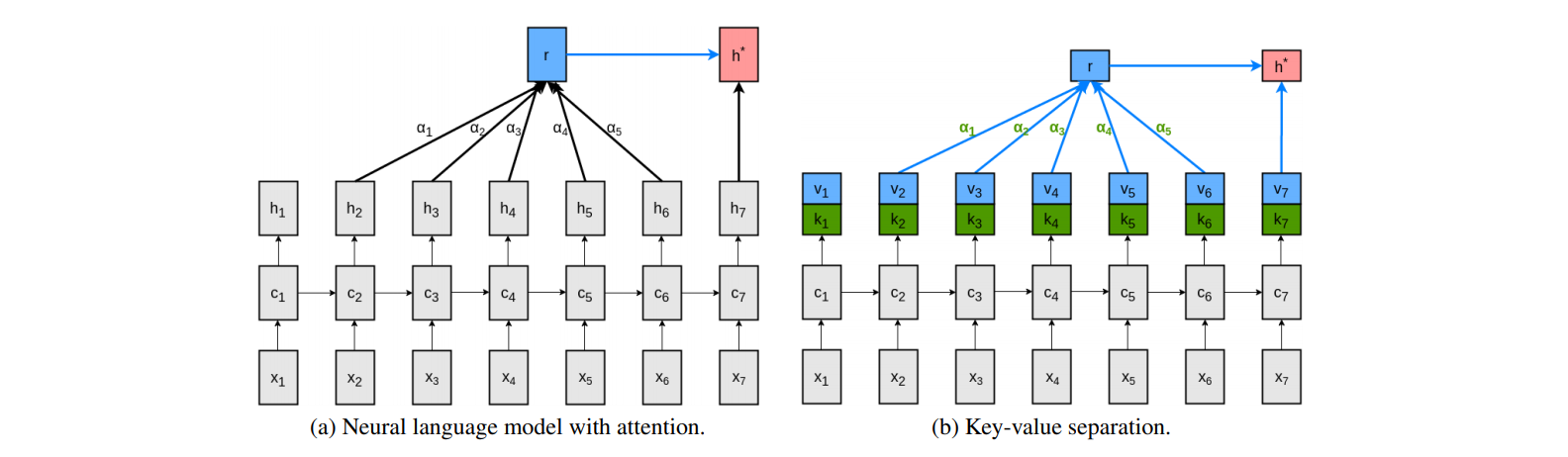
従来のAttentionで行われていたアライメントの探索の仕方は、
①EncoderとDecoderで獲得された各々の固定長ベクトル同士の類似度を算出し
②類似度が高いものをより強いアライメントであると判定
します。
このとき、「固定長ベクトルとは各単語の特徴を表すもとである」ことが成立していることが前提となっています。これは厳密に単語同士を分離することは言語学的にも不可能であるというのが理由になっています。例えば、「Tom」とは何か、という説明をするためには他の単語(「human」など)の助けが必要、つまり各単語そのものがほかの単語と共有している何かがあるために成り立っています(このような発想のもと分散表現などが考案されている)。
しかし、それでもある単語は他の単語とは異なるものとして存在している以上、それらを分離することのできる単語の核ともいうべき特徴があるはずであり、この微妙な関係性を表現したのが「Key」と「Value」という辞書オブジェクトの組み合わせであり、このことがより正確に単語同士のアライメントを参照することを可能にしました。
以下に、各単語の類似度からアライメントを判定することの問題点、Key-Valueに分類することの利点を説明します。
「直接単語の特徴を参照する」ことで生じている問題をイメージするために、例えば質疑応答に関する学習について考えてみるとわかりやすくなります。
情報: Yoshi is 18years-old.
質問: Who is 18yeass-old in fdit-team?
答え: Yoshi.
このとき、正しい答えを導くために2つの動作が行われていると考えることができます。
① 質問に対する探索
② (質問に正しく応答している)答えに対する探索
重要なことは「質問に答えは含まれていない」ということです。このとき、従来のKeyとValueが一致している場合、質問に含まれる単語(18years-oldなど)の特徴に類似しているものを探索して答えを見つけ出していました。この場合、Tomと18years-oldの間には強いアライメントがあるため、18years-oldだけの特徴を用いて質問を探し答えたとしても多くの場合は正解することができます。
しかし、本来18years-oldとYoshiは別の概念であり、単語同士の類似性のみを根拠にして答えとすることは、全体データが大きくなればなるほど不安定になってきます(例えば、類似性だけであれば19years-oldのような表現の方が近いかもしれない)。このときYoshiの内実の特徴(Yoshi自身を示す特徴)だけでなく、18years-oldとの繋がりを示す特徴があれば、それを参照することでより正確にYoshiにたどり着くことができます。加えて、whoなどとの繋がりを示す特徴を持つことでより正確に近づいていくことができます。
つまり、Keyとは他の単語との関係性を示す(分散表現のベクトルもの)、Valueはその単語そのものを示す(分散表現のベクトル)ものといえます。無鉄砲に荒野から自分と似ているというValueを探すよりも、Keyという目印に従ってValueという答えを得る方が、より早く・より適切な答えを見つけることができるようなイメージであり、KeyとValueを設定することで高い表現力を獲得できます。Key-Valueモデルを提唱した研究チームは「Keyは質問に一致させるのを助ける特徴を持つべきであり、Valueは応答に一致させるのを助ける特徴を持つべきである」と述べています。
(ⅰ)自分のタスクに関する事前知識を符号化するためのより大きな柔軟性を
(ⅱ)keyとValueの間の非自明な変換を介してモデルのより効果的なパワーの両方を得る
ことができるとしています。
このようにKeyとValueを明確に分離することでより高い表現力を獲得することが可能となりました。
おわりに
Seq2SeqやAttentionを応用した様々なモデルが存在しますが、基本的な内容は本説明で記載したとおりです。Transformerは物体検出にも適用され始めています。代表的なモデルであるDETR(DEtection TRnsformer)について、以下に執筆しました。