はじめに
この記事は、Kaggleの自然言語処理コンペであるToxic Comment Classification Challengeでベースラインモデルから性能を改善させるために行った取り組みを紹介するものです。
比較するベースラインモデルは前回の記事【Kaggle: 自然言語処理コンペ】(1)ベースラインモデルの作成を参照してください。
今回の取り組み
前回に次のような改善策を挙げていました。今回は太字の部分に着目します。
- データの前処理
- doc2vecの改善を行う。doc2vecにも様々な方式がある。また、既存の学習済みword2vecを利用してコメントを固定長のベクトルに変換する方式の方が良い特徴表現が得られる可能性がある。
- 少数の陽性クラスを検出するために、コンペのDiscussionで公開されているような外部データを利用する。
- モデルの構築
- モデルの学習時に不均衡データ問題に対する対策を行う。
- ニューラルネットのアーキテクチャを変更してみる。例えば、畳み込みニューラルネット(CNN)などがある。
改善の勘所
基本的に、データの前処理を改善する方がモデルの構築を改善するよりも性能に大きく影響を与えます。なぜなら、データの前処理によってモデル(学習者)が見ているタスクをより解きやすいものにできるからです。
ここで言う「解きやすさ」には2つの意味合いがあります。一つは、単純化:分類に有用な情報を抽出してそれのみをモデルに渡すこと、もう一つは、複雑化:分類に有用な情報を増やすためにより多くの情報をモデルに渡すことです。前者は、古典的な取り組み、単純なモデルによって単純なタスクを確実に学習させるという方法論で、後者は、最近の深層学習の流れ、複雑なモデルによって複雑なタスクを工夫して学習させるという方法論です。
ここで問題になるのは「有用な情報をどうやって発見するか」です。古典的には、専門家が専門知識をもって試行錯誤することによって有用な情報を発見していましたが、最近は、大量のデータからそれを自動的に発見させようという流れが強くなっています。
さて、データの前処理によって、深層学習と相性の良い複雑化という観点でタスクを解きやすいものにするためにはどうすればよいでしょうか?
doc2vecの改善を模索
学習済word2vecを利用してdoc2vecを行うという発想の手法があると思い文献を調査してみましたが、すぐにはそれらしいものを見つけられませんでした。単語IDではなく単語ベクトルを入力として文章ベクトルに変換するほうが強力なように思えるのですが、もしご存知の方がおられればコメントにお願いします。
さて、doc2vecには2種類の方式: PV-DMとPV-DBOWがあります。それぞれの特徴を確認してみましょう。
PV-DMは下の図のように、ある単語を文書IDとその周辺単語から予測できるように学習します。文書に含まれる単語と語順などの情報が保存されるように学習されます。

引用元: Distributed Representations of Sentences and Documents
PV-DBOWは下の図のように、文書IDからその文書に含まれる単語を予測できるように学習します。文書に含まれる単語の情報が保存されるように学習されます。

引用元: Distributed Representations of Sentences and Documents
前回のベースラインモデルはPV-DMのdoc2vecを使いました。一般的には、PV-DMの方が語順に関する情報を含むためPV-DBOWよりも精度が高いと言われています。そのため、PV-DBOWでdoc2vecをやり直したとしてもあまり性能は向上しないでしょう。
そこでword2vecのような単語ベクトルを使ったデータの前処理を調べてみました。unintended-ml-bias-analysisというモデルがKaggleのdiscussionで紹介されていたので、今回はそれを流用してみます。このモデルはGloVeという単語ベクトルを利用して、コメントを行列に変換し、CNNで学習をしています。
改善策とそのゲイン
改善したモデルがベースラインモデルと比較してどれほど性能向上したかをゲインとして評価します。
GloVeによる前処理とCNNによる学習
今回は、このレポジトリunintended-ml-bias-analysisを利用してGloVeでコメントを固定長に変換し、CNNによって学習を行ってみました。
GloVeとは、word2vecと同様に単語を固定長のベクトルに変換する単語埋め込みの手法の一つです。GloVeは大規模なコーパスで学習した学習済モデルが公開されており、今回はそれを用います。GloVeやword2vecといった単語埋め込みの手法の性能は、大規模なコーパスで学習することで向上します。
次のような前処理で、コメントを固定長の行列に変換します。まずコメントを250単語の系列にパディングします。パディングとは、文章を固定長の単語の系列に変換することです。
例えば、"This is a pen."と"This is a pen and this is an apple."という2つの文章を長さ5の系列にパディングすることを考えます。
"This is a pen."→['This', 'is', 'a', 'pen', '']
"This is a pen and this is an apple."→['This', 'is', 'a', 'pen', 'and']
のようになります。すなわち、元の文章が系列長よりも短ければ''(空集合)で残りを埋めて、逆に長ければ後ろの単語を切り捨てます。
次に、パディングされた単語のそれぞれをGloVeで100次元に変換する(''の場合はすべて0のベクトルにする)ことで、250✕100の行列が得られます。これをモデルの入力として使います。
モデルの構成のイメージ図

このモデルは、1次元の畳み込みとプーリングによって、特定の単語の組み合わせからなる特徴がコメント中のどこに現れていたとしても、その特徴を吸い上げて全結合層に渡すことができます。例えば、"Fuck you!"という単語の並びがコメント中のどこかにあればその特徴を見逃さずに全結合層に渡すことができます。全結合層では、抽出された特徴から二段に渡って分類問題を学習します。
畳み込み層では毒性に関わる単語群をフィルタによって学習しているとも解釈でき、これはある種の特徴抽出になります。このように畳込みとプーリングはある種の平行移動を吸収することができ、加えてフィルタにパターンを保存して特徴抽出を行います。例えば、画像処理に用いられる2次元の畳込みとプーリングは、2次元の平行移動に影響されずに特徴を吸い上げることができ、低層のフィルタには低次なエッジ、高層のフィルタには高次な顔のパーツなどのパターンを保存します。
実装は、unintended-ml-bias-analysisの/unintended_ml_bias/model_tool.pyを改変して使いました。
class ToxModel():
"""Toxicity model."""
def build_model(self):
"""モデルを構築する"""
sequence_input = Input(
shape=(self.hparams['max_sequence_length'],), dtype='int32')
embedding_layer = Embedding(
len(self.tokenizer.word_index) + 1,
self.hparams['embedding_dim'],
weights=[self.embedding_matrix],
input_length=self.hparams['max_sequence_length'],
trainable=self.hparams['embedding_trainable'])
embedded_sequences = embedding_layer(sequence_input)
x = embedded_sequences
for filter_size, kernel_size, pool_size in zip(
self.hparams['cnn_filter_sizes'], self.hparams['cnn_kernel_sizes'],
self.hparams['cnn_pooling_sizes']):
x = self.build_conv_layer(x, filter_size, kernel_size, pool_size)
x = Flatten()(x)
x = Dropout(self.hparams['dropout_rate'])(x)
# TODO(nthain): Parametrize the number and size of fully connected layers
x = Dense(128, activation='relu')(x)
preds = Dense(2, activation='softmax')(x)
rmsprop = RMSprop(lr=self.hparams['learning_rate'])
self.model = Model(sequence_input, preds)
self.model.compile(
loss='categorical_crossentropy', optimizer=rmsprop, metrics=['acc'])
def build_conv_layer(self, input_tensor, filter_size, kernel_size, pool_size):
output = Conv1D(
filter_size, kernel_size, activation='relu', padding='same')(
input_tensor)
if pool_size:
output = MaxPooling1D(pool_size, padding='same')(output)
else:
# TODO(nthain): This seems broken. Fix.
output = GlobalMaxPooling1D()(output)
return output
改善策のゲイン
このモデルを使ってカテゴリごとの分類器を使って予測した結果をサブミッションします。サブミッションのスコアは0.9456(2936位/3400人)でした。前のサブミッションから0.0509伸びました。結構な進歩ですが、既存のモデルを使いまわしているだけなので上位層にはまだまだ食い込めそうにありません。ちなみに、現在のトップのスコアは0.9885です。
ベースラインモデルと今回のGloVe+CNNのテストデータでのAUCを毒性カテゴリごとに比較してみましょう。
| 手法 | toxic | severe_toxic | obscene | threat | insult | identity_hate | average |
|---|---|---|---|---|---|---|---|
| baseline(doc2vec+DNN) | 0.8936 | 0.9084 | 0.9089 | 0.9028 | 0.9009 | 0.9340 | 0.9081 |
| GloVe+CNN | 0.9565 | 0.9753 | 0.9741 | 0.9363 | 0.9651 | 0.9542 | 0.9603 |
| ゲイン(差分) | +0.0629 | +0.0669 | +0.0652 | +0.0335 | +0.0642 | +0.0202 | +0.0522 |
| 陽性クラス率(%) | 9.58 | 1.00 | 5.29 | 0.30 | 4.94 | 0.88 | - |
{threat, indentity_hate}以外ではほぼ+0.06のゲインがあるため、GloVe+CNNの改善が非常に強力だったと言えます。indentity_hateはベースラインでもAUCが高かったの伸び幅が少ない分ゲインも落ちているようです。threatは陽性クラス率が6カテゴリ中最下位の0.30%でなので不均衡データの学習が難しいという問題が残っている可能性があります。
考察
今回は、AUCで約+0.05のゲインがありました。前回と同様にスコアから求めた陽性確率上での各クラスサンプルの分布をみてみます。
下の図は、ヒストグラムで各クラスで規格化した確率密度を左側、クラスごとの累積密度関数を右側にプロットしています。確率密度を見ると、陽性確率上でどのようにクラスのデータが分布しているかを知ることができます。累積密度を見ると、閾値によって偽陽性と偽陰性になるデータがどのように分割されるかを知ることができます。
赤が陽性、青が陰性のデータに対応しています。
GloVe+CNN

baseline(doc2vec+DNN)
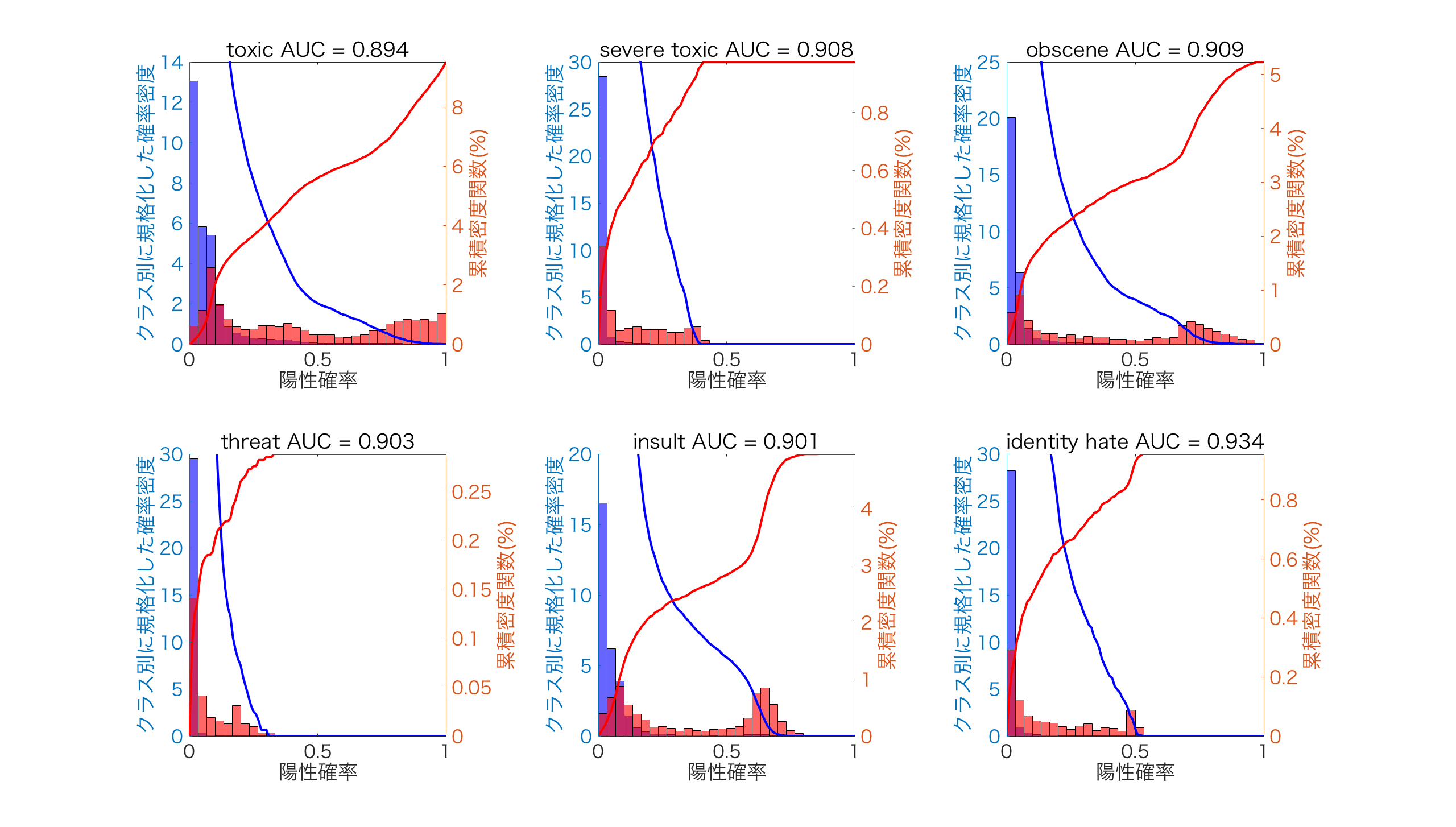
両者を比べると、{toxic,obsence,insult}において、baselineでは2つ山になっていた陽性クラス(赤)の分布がGloVe+CNNでは陽性確率1を頂点とする一つの山に変化しています。これは、ベースラインでは拾いきれなかった特徴(陽性確率が低いところにある山)をGloVe+CNNでは拾っていると解釈できます。{severe_toxic,threat,indentity_hate}では陽性クラス(赤)の分布がより右側に伸びていっているので、陽性クラスがより上手くスコアに埋め込まれるようになったのでしょう。
今回のモデルで最もAUCが低かったthreatを分析してみましょう。threatの陽性確率での陽性クラス(赤)は[0,0.25]の範囲内でしか分布していません。一方で、他のAUCが高いカテゴリでは陽性クラス(赤)は[0,1]の広い範囲で分布しています。これはモデルの学習で陽性クラスの特徴をあまり取り込めていないということになるので、前回の記事で議論したような「不均衡データへの対策」をthreatで試してみる価値がありそうです。
前回doc2vecでは100次元に押し込んでいたため潰れていた情報が、今回GloVeによって250✕100次元の単語情報をそのまま保存する形にしたことでより残るようになったようです。また、CNNにより文章の位置によらず単語群の特徴を拾うことができることも大きいでしょう。
まとめ
今回はデータの前処理でタスクの捉え方を大きく変えたことが成功しているようでした。学習モデルのアーキテクチャや学習のパラメータを調整することよりも、学習モデルがみるタスク自体をより解きやすいものとなるように前処理をすることは非常に強力な改善法です。
次への改善策を挙げます。
- データの前処理
doc2vecの改善を行う。doc2vecにも様々な方式がある。また、既存の学習済みword2vecを利用してコメントを固定長のベクトルに変換する方式の方が良い特徴表現が得られる可能性がある。- 少数の陽性クラスを検出するために、コンペのDiscussionで公開されているような外部データを利用する。
- 【New】データのサンプリングを用いて不均衡データ問題への対策を行う。
- モデルの構築
- モデルの学習時に不均衡データ問題に対する対策を行う。
ニューラルネットのアーキテクチャを変更してみる。例えば、畳み込みニューラルネット(CNN)などがある。- 【New】再帰型ネットワーク(RNN)を利用する。
この取り組みは、株式会社データグリッドの取り組みの一環として実施されました。
※なお、この記事はコンペの規則に則り、コンペサイト内Discussionでも公開しています。