はじめに
この記事は、Kaggleの自然言語処理コンペであるToxic Comment Classification Challengeに参加し、ベースラインモデルの作成までを紹介するものです。
Kaggleとは
Kaggleはデータ分析とモデル構築を競うコンペサイトで、与えられたタスクに対して、世界中のデータサイエンティストやエンジニアが様々な手法を駆使してスコアを競い合うサイトです。
Toxic Comment Classification Challengeとは
Toxic Comment Classification Challengeはウェブサイトにおけるコメントの毒性を予測するコンペです。
目的は、オンラインでのコミュニケーションを円滑に行うために、誹謗中傷など議論の場を乱す発言を自動的に検出して取り除くことです。
問題設定は、コメント(英語文)を入力として、6つの毒性カテゴリそれぞれについて毒性の確率[0,1]を出力するものです。
実現方法としては、カテゴリごとに二値分類器を学習してそのカテゴリを予測するという形式になるでしょう。
モデルの評価方法は、カテゴリごとのAUCの平均とされています。
二値分類と評価指標AUC
このコンペのタスクは二値分類で、評価指標であるAUCについておさらいします。
二値分類とは
二値分類はある入力を陽性・陰性のような2つのクラスに分類する問題で、陽性であるほどその値が高くなるようなスコア(陽性クラスらしさ)を入力から計算し、ある閾値以上であれば陽性、閾値未満であれば陰性と予測します。
例えば、入力から陽性確率[0,1]を求め、閾値0.5で予測するというモデルや、大きいほど陽性であるスコア$[-\infty,+\infty]$を求め、閾値0で予測するというモデルが挙げられます。
学習される要素は「入力からスコアを求める関数」と「閾値」の2つになります。
二値分類の評価指標
さて、二値分類の評価指標には、予測ラベルに関するもの(正解率、再現率、適合率、F値)とスコアに関するもの(AUC)があります。
正解率などは、ある閾値に対する予測ラベルを評価するもので、これは閾値に依存して変化します。また、もとのタスクの陽性クラス率(データ全体のうち陽性に属するデータの割合)にも影響を受けます。
一方で、AUCはモデルが持つスコア自体を評価しており、陽性のデータに高いスコアが付き陰性のデータに低いスコアが付いている場合には、陽性と陰性のクラスの集合が上手く分離できているので、AUCの値は高くなります。
AUCの定義
AUC(Area Under the Curve)はROC曲線の下側の面積のことで、0から1の値を取ります。
ROC曲線は閾値を動かした時に、縦軸を真陽性率1、横軸を偽陽性率2としてプロットした曲線のことです。
モデルのスコア上に陽性(赤色)と陰性(青色)が以下のように3パターンで分布していたとします。それぞれに対応するROC曲線は以下のようになります。
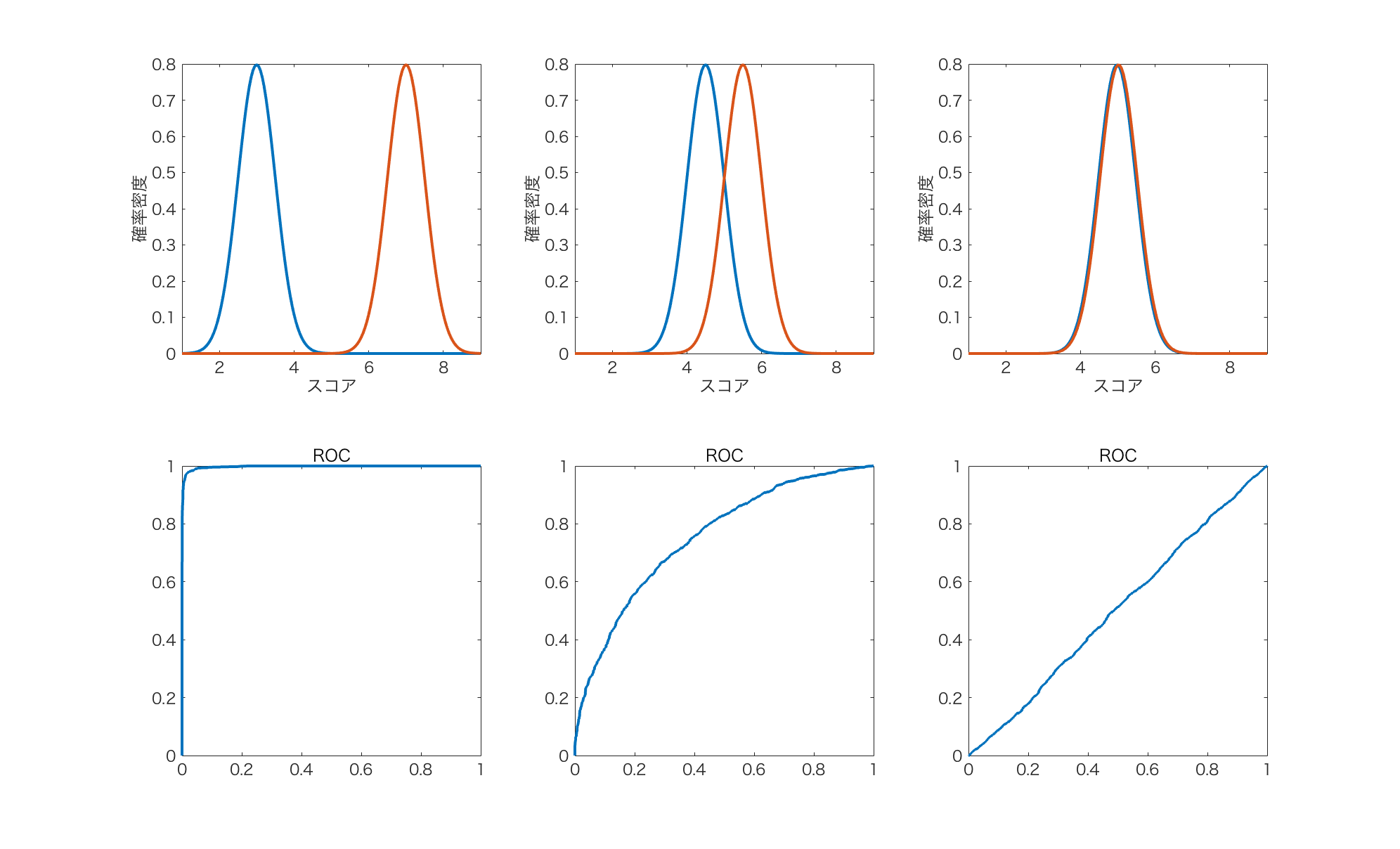
左の場合は、2つのクラスがスコア上でよく分離しているので、AUCが一番1に近くなります。
中央の場合は、2つのクラスが少し混合しているので、その分AUCは低くなります。
右の場合は、完全にランダムにスコアを出力した場合(データがスコアで見分けられない場合)に相当し、2つのクラスが完全に混合しているので、AUCは0.5になります。なので、実質的に0.5がAUCの下限になります。
基本的な方針
まずは与えられたタスクのデータを分析して、タスクの難しさを推測します。
その次に、もっともシンプルな構成でベースラインモデルを作成します。
その後、より問題の知識を活用するように、データの前処理とモデルの構築の2つの観点で改善策を組み込んでいき、精度を向上させます。
データ分析とベースラインモデルの作成
データの分析
今回のタスクは二値分類です。データの性質を知るために、陽性クラスの割合を分析します。全データに対する陽性クラスの割合を確認することで、問題の難しさをある程度推測することができます。
この分析はタスクの具体的な特徴には踏み込まずに行うことができます。
総訓練データ数 159,571
| 毒性カテゴリ | 陽性クラス数 | 陽性クラス率(%) |
|---|---|---|
| toxic(有害) | 15,294 | 9.58 |
| severe_toxic(重度に有害) | 1,595 | 1.00 |
| obscene(卑猥) | 8,449 | 5.29 |
| threat(脅迫) | 478 | 0.30 |
| insult(侮蔑) | 7,877 | 4.94 |
| identity_hate(人格攻撃) | 1,405 | 0.88 |
一般に、片方のクラスのデータが少ない二値分類問題は学習が難しくなります。これは不均衡データ問題としてよく知られており、例えば、陽性クラス率1%の二値分類問題は、「データはすべて陰性だ」という判定する頭の悪い分類器でも正解率は99%になります。しかし、AUCで評価すればこのモデルの頭の悪さ見抜くことができます。このモデルのAUCは0.5となるので、ランダムに分類するモデルと同等の能力しか持たないモデルであることがわかります。これがAUCの良さです。
データの前処理
学習モデルの入力は、基本的には固定長のベクトルにする必要があります3。
入力のコメントは可変長の英語文なので、これをdoc2vecによって固定長のベクトルに変換します。
doc2vecは、コーパス(文章からなるデータセット)内の単語や文章のある種の関係性4を保つように、文章を固定長のベクトルに変換する手法です。ラベルなしのコーパスから教師なし学習を行うことでdoc2vecは学習されます。
doc2vecの使用には何らかの学習コーパスが必要なので、今回は訓練データとテストデータのコメント全体を学習コーパスとしました。変換されるベクトルの次元数は100としました。doc2vecの実装は、gensimのmodels.doc2vecを用いました。
import pandas as pd
import numpy as np
import gensim
# 文章からコーパスへの変換関数
def doc_to_corpus(doc_list):
for i, line in enumerate(doc_list):
yield gensim.models.doc2vec.TaggedDocument(gensim.utils.simple_preprocess(line), [i])
# データの読み込み
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
all_corpus = list(doc_to_corpus(train_data.comment_text.append(test_data.comment_text)))
# doc2vecの学習
model = gensim.models.doc2vec.Doc2Vec(size=100, min_count=2, iter=55)
model.build_vocab(all_corpus)
%time model.train(all_corpus, total_examples=model.corpus_count, epochs=model.iter)
# x_trainの作成
x_train = np.array([model.infer_vector(x.words) for x in all_corpus[0:train_data.shape[0]]])
学習モデル
最近はディープラーニングが流行りということで、まずはシンプルな全結合ネットワークを試してみます。
通常は、ベースラインモデルはSVMなどの凸最適化で解けるモデルの方が良いです。凸最適化は結果の初期値依存性がなく、収束判定も確実なので結果がぶれません。さらにSVMはハイパーパラメータが2つしかないのでハイパーパラメータ最適化も容易です。(なぜSVMでやらないかはこちら5)
| 学習モデルの設定 | |
|---|---|
| アーキテクチャ | 全結合 |
| 層数 | 4 |
| 素子数 | 128(全層同一) |
| 誤差関数 | クロスエントロピー誤差 |
| 活性化関数 | ReLU |
| 出力関数 | シグモイド |
| ドロップアウト | 0.5 |
| 最適化手法 | Adam |
| 訓練・評価データの分割 | 8:2 |
| バッチサイズ | 1024 |
ニューラルネットは出力する陽性確率と訓練データの真のラベルの間の誤差が小さくなるように学習を行います。陽性確率は、出力層の手前の値をスコアとしてシグモイド関数で[0,1]に変換することで求めます。
学習はpatience=3の早期停止で停止させました。
実装はkerasを使いました。
import tensorflow as tf
from keras.backend import tensorflow_backend
from keras.layers import Input, Dense
from keras.models import Model
from keras.callbacks import EarlyStopping
from keras.models import Sequential
# パラメータの設定
epochs = 100
batch_size = 1024
layer_n = 4
unit_n = 128
drop_rate = 0.5
validation_split = 0.8
# 訓練データの読み込み
x_train,y_train = load_xy('toxic') # ここでは各自で定義してください。
input_dim = x_train.shape[1]
# early stopping
early_stopping = EarlyStopping(monitor='val_loss', patience=3)
model = Sequential()
for i in range(layer_n):
model.add(Dense(units=unit_n, input_dim=input_dim, activation='relu'))
model.add(Dropout(drop_rate))
model.add(Dense(units=1, activation='sigmoid'))
model.compile(loss = 'binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size,
validation_split=validation_split, callbacks=[early_stopping])
学習結果
ベースラインモデルの学習結果をテストデータで確認します。
| toxic | severe_toxic | obscene | threat | insult | identity_hate | average | |
|---|---|---|---|---|---|---|---|
| AUC | 0.8936 | 0.9084 | 0.9089 | 0.9028 | 0.9009 | 0.9340 | 0.9081 |
AUCで評価した結果では、toxicが一番悪く、indetity_hateが一番良くなりました。詳しく分析するために、スコアから求めた陽性確率上での各クラスサンプルの分布をみてみます。
下の図は、ヒストグラムで各クラスで規格化した確率密度を左側、クラスごとの累積密度関数を右側にプロットしています。確率密度を見ると、陽性確率上でどのようにクラスのデータが分布しているかを知ることができます。累積密度を見ると、閾値によって偽陽性と偽陰性になるデータがどのように分割されるかを知ることができます。
赤が陽性、青が陰性のデータに対応しています。
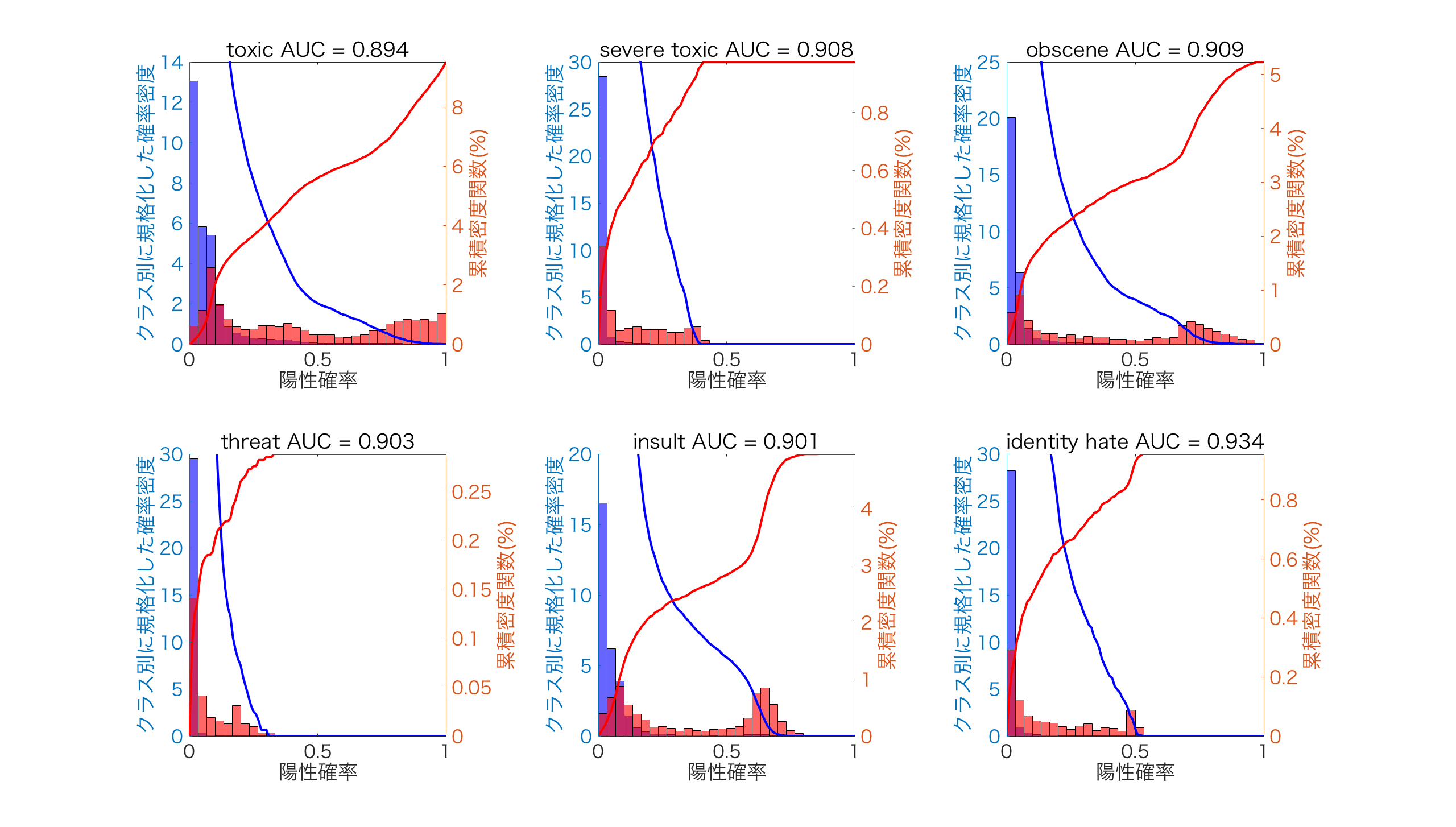
最もAUCが悪かったtoxicについて解釈すると、赤の陽性データが幅広く分布しており、陽性確率が小さい領域で青の陰性クラスと多く混合しています。陽性と陰性の分布の混合が大きいほど、その陽性確率上で両者を分離することが難しいので、AUCが低くなっています。
最もAUCが良かったindentity_hateについて解釈すると、青の陰性データの広がりが小さく、2つの分布の混合が小さいためAUCが高くなっています。
結果の提出
初回のスコアを得るために提出します。
テストデータに対する陽性クラス確率を予測して、Kaggleに提出した結果、スコアは0.8947(1914/2123位)でした。特に工夫もしていないのでこんなものでしょう。
改善への議論(不均衡データへの対策)
今回は陽性のデータが少ないせいで学習が上手く行っていない可能性があります。ここでは、その問題への対処を議論してみましょう。
不均衡データ問題を解決する方法は主に次の2つです。
- 誤分類誤差の重みを調整する
- データをサンプリングする
前者は、少数クラスの誤分類により大きいペナルティを課すことで、学習時に少数クラスを見逃さないようにさせるものです。典型的には、誤分類重みをクラスに属するサンプル数の逆数に設定しますが、比率は調整したほうが良いでしょう。誤分類重みは多くの学習モデルの関数のオプションとして設定できるので、実現が非常に楽な方法です。まずはこちらを試してみるべきでしょう。
後者は、データをサンプリングで増やす/減らすことで、クラスのデータ数の偏り自体を修正するものです。もっともシンプルな方法は大量にあるクラスをランダムに間引くことで、これはアンダーサンプリングといいます。ただし、アンダーサンプリングは間引かれた分のデータを損することになります。逆に、少数しかないクラスのデータを生成モデルによって増やす方法をオーバーサンプリングと呼びます。データの性質に依存しない生成モデル(ガウス混合モデル(GMM)、最近流行っているGAN)を使えば、簡単にデータ数を増やすことはできますが、大事なのは「如何にデータの性質を保ちながら意味のある水増しができるか」です。こちらは技術や知識がいる方法になります。
これらの工夫を行うことで、より良いスコアへの変換を学習できる可能性があります。しかし、どちらの方が適切かはタスクに依存するので、試行錯誤を行う必要があります。
今後の改善
データの前処理とモデルの構築の2つの観点で改善策をあげます。
- データの前処理
- doc2vecの改善を行う。doc2vecにも様々な方式がある。また、既存の学習済みword2vecを利用してコメントを固定長のベクトルに変換する方式の方が良い特徴表現が得られる可能性がある。
- 少数の陽性クラスを検出するために、コンペのDiscussionで公開されているような外部データを利用する。
- モデルの構築
- モデルの学習時に不均衡データ問題に対する対策を行う。
- ニューラルネットのアーキテクチャを変更してみる。例えば、畳み込みニューラルネット(CNN)などがある。
次の記事はこちら【Kaggle: 自然言語処理コンペ】(2)「GloVe+CNN」による性能改善
参考
この取り組みは、株式会社データグリッドの取り組みの一環として実施されました。
※なお、この記事はコンペの規則に則り、コンペサイト内Discussionでも公開しています。
-
真のクラスが陽性のものをモデルが陽性と予測した割合 ↩
-
真のクラスが陰性のものをモデルが陽性と予測した割合 ↩
-
回帰型ニューラルネット(RNN)であれば、可変長のベクトルを入力にすることができます。 ↩
-
方式によって取り扱う関係性は異なります。今回用いたPV-DMモデルは、文書内のある単語を文書IDとその単語の周辺に現れる単語から予測できるように学習します。 ↩
-
今回は計算時間を考慮してSVMではなくNNを使いました。SVMはデータ数の指数オーダーで学習時間がかかり、今回の15万データという膨大なデータすべてを使い学習するのは、NNでの学習よりもかなり時間がかかります。NNの学習の強みは、訓練データ数に学習時間が依存しないため大規模データでの学習に向いていることと、GPUの使用により計算時間が大幅に短縮できることです。 ↩