良く自分が使うものを中心に備忘録としてまとめ。
更新頻度高めで更新していきます。
前提
まず前提として、必ず事前に作成するDataMartの構成をcsv,json,yaml形式問わずクライアントと合意する。
それを目標としてPythonでコーディングを始めること
pd.options.display(表示設定)
dataframe全ての列を表示
!注意! pandas==1.1.3までしかサポートされていない?(2020.12月現在 pandas==1.1.5が最新)
pd.options.display.max_columns = None
小数点第何位まで表示するかを設定(eを表示しないようにする)
pd.options.display.float_format = '{:.2f}'.format
warningを表示しないようにする
import warnings
warnings.filterwarnings('ignore')
### または下記。下記は動作確認済。
import warnings
warnings.simplefilter('ignore')
nan null 判定
math.isnan(), note
print(math.isnan(float('nan')))
# True
print(math.isnan(math.nan))
# True
print(math.isnan(np.nan))
# True
str = ''
if not str:
print('NULL')
else:
print('文字あり')
str = ''
if len(str) == 0:
print('NULL')
else:
print('文字あり')
#[結果] NULL
#余談:infの置換
df = df.replace([np.inf, -np.inf], np.nan)
# これを行うことによって、無限大がnanになるためその後fillnaなどで欠損値として操作しやすくなります。
データ整形/前処理編
cut()
# s_qcutで4分位が割り振られた配列
# binsはそれぞれの境界値
s_qcut, bins = pd.qcut(s, 4, labels=['Q1', 'Q2', 'Q3', 'Q4'], retbins=True)
# 【エラーメモ】qcut関数のエラーValueError: Bin edges must be unique
# https://guarana001.hateblo.jp/entry/2019/11/28/230808
# 解決策
data['RNK'] = pd.qcut(data['val'].rank(method='first'), 3, labels=['Q1', 'Q2', 'Q3'])
基本print文
#連結ができるのは文字列だけなので、数値などを出力するときは文字列に変換してから連結するようにしましょう。
name = 'Tanaka'
point = 80
print(name + 'の得点:' + str(point)) #pointをstr関数で文字列に変換
Tanakaの得点:80
np.where(よく見る使えるやつ)
#閾値(threshold)より小さければ、一定、0以下であれば下降、それ以外は上昇を表す
df["new_columns"] = np.where(abs(df["columns"]) <= threshold,"一定",np.where(df["columns"] <= 0, "下降","上昇"))
#連結ができるのは文字列だけなので、数値などを出力するときは文字列に変換してから連結するようにしましょう。
name = 'Tanaka'
point = 80
print(name + 'の得点:' + str(point)) #pointをstr関数で文字列に変換
Tanakaの得点:80
os.getcwd(),os.chdir() ディレクトリ の確認と変更
import os
#現状のディレクトリ の取得
os.getcwd()
#ディレクトリ の変更
os.chdir('../')
参考
https://note.nkmk.me/python-os-getcwd-chdir/
Dataframeにおけるandとorとnot
#https://note.nkmk.me/python-pandas-multiple-conditions/
PM_master_step_L_1 = PM_master_step[~((PM_master_step["訪問"]==0) &
(PM_master_step["メール開封"]==0)) &
(PM_master_step["label"]=="F")]
#条件を()で囲まないと下記のエラーが出るので注意
TypeError: unsupported operand type(s) for &: 'str' and 'str'
query
#数値指定
df.query('a == 3')
#複数列での条件指定
#aの値の列がbの列より大きい
df.query('a > b')
#文字列指定
#シングル、ダブルクォーテーションの使い分け
df.query('e == "a" ')
#複数条件
df.query('a > 2 and b < 3')
df.query('a > 2 or b < 3')
df.query('(age == 24 | point > 80) & state == "CA"')
##文字列指定と併せても使える
df.query('a > 2 or e == "d" ')
df.query(' 2<= a <= 4')
参考
https://qiita.com/dox/items/bf6ce1c71d8d18723e74
pivot
#数値を集計したいわけではなく、ピボット形式の要素を取得したい場合
In [4]: df.pivot(index="class",columns="state",values="name")
Out[4]:
state DC ND NY OH OK
class
high Gari NaN Alice NaN NaN
low NaN Chris Evan David NaN
middle NaN NaN NaN Bob Fabian
#ラベル同士の組み合わせで被りがあるとエラーが返ってきます。
ValueError: Index contains duplicate entries, cannot reshape
#classとblood_typeをみてみると、 class="high", bloody_type="A"のデータが2組存在してることがわかります。 このような場合、データを再構築できません。
#前処理が必要
pivot_table
#pythonでもpivot tableができる
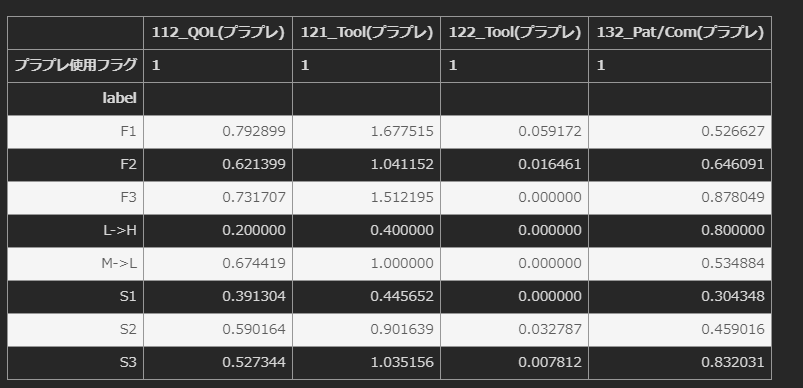
df000.pivot_table(index="label",columns="使用フラグ",values=["122_Tool","121_Tool","112_QOL","132_Pat/Com"],aggfunc="mean",fill_value = 0)
df = df.pivot_table(index = "ID",values=df.columns,aggfunc="mean").reset_index(drop=True)
DF = DF.pivot_table(index=["ID","YM"],columns="Product Name",values="金額",aggfunc="sum").reset_index(drop=True)
#aggfuncには"sum"や"count"もある
#reset_index()と利用するケースも多い。
#fill_valueでnan値を埋めることが出来る
#列名のマルチインデックスがpivot_tableの際に良く発生するが解消のためには関数書く必要あり
def rename_multicol(df):
df_col=df.columns #列名をコピー
df = df.T.reset_index(drop=False).T #一回列名をリセット
for i in range(df.shape[1]): #列名を新たに定義
rename_col = {i:"".join(df_col[i])}
df = df.rename(columns = rename_col)
df = df.drop(["level_0","level_1"],axis=0)
return df
#https://qiita.com/takuto512/items/2ce27c770cb0087a9def
idxmin() and idxmax()
#回数が最も最大のINST_CDを算出
df000.loc[df000["141_General"].idxmax()]["INST_CD"]
#普通に書くと割と大変
isin_便利
#clinet IDの中でtargetリストに含まれるレコードを抽出
df[df["Clinet ID"].isin(target)]
df[df["Clinet ID"].isin(target)].reset_index(drop=True,inplace=True)
#clinet IDの中でtargetリストに含まれないレコードを抽出
df[~df["Clinet ID"].isin(target)]
df[~df["Clinet ID"].isin(target)].reset_index(drop=True,inplace=True)
str.contains_pandasで特定の文字列を含む行を抽出(完全一致、部分一致)
df007 = df004[((df004["clusterS1_sequence"].str.contains("プレゼンテーション")) & (df004["clusterS1_sequence"].str.contains("リモート")))]
### na=Falseで含まれているNanを無視することが出来る
df.loc[(df["機種"].str.contains("iPhone",na=False)),:]
#### NOTE |で結ぶことで指定した文字列の何れかが含まれていたらという指定も可能
df = df.loc[~(df["伝票タイプ"].str.contains("AP|AR|GL")),:]
https://ohke.hateblo.jp/entry/2020/03/07/000000
###str.contains()列名に特定の文字列を含む要素を抽出
#label = 1かつ列名にP1が含まれていてその値が1以上のものが1つでもある、列名にP3が含まれていてその値が1以上のものが1つでもある
df[(df.loc[:,'label'] == 1) & (df.loc[:, df.columns.str.contains('P1')] >= 1).any(axis=1) & (df.loc[:, df.columns.str.contains('P3')] >= 1).any(axis=1)]
参考:pandas dataframeの列名に〇〇を含む要素を抽出しさらに値にフィルターをかける方法
.allと、.any
#列がすべて0のものを削除
df.loc[:, (df != 0).any(axis=0)]
[参考:Pythonの組み込み関数all(), any()の使い方]
(https://note.nkmk.me/python-all-any-usage/)
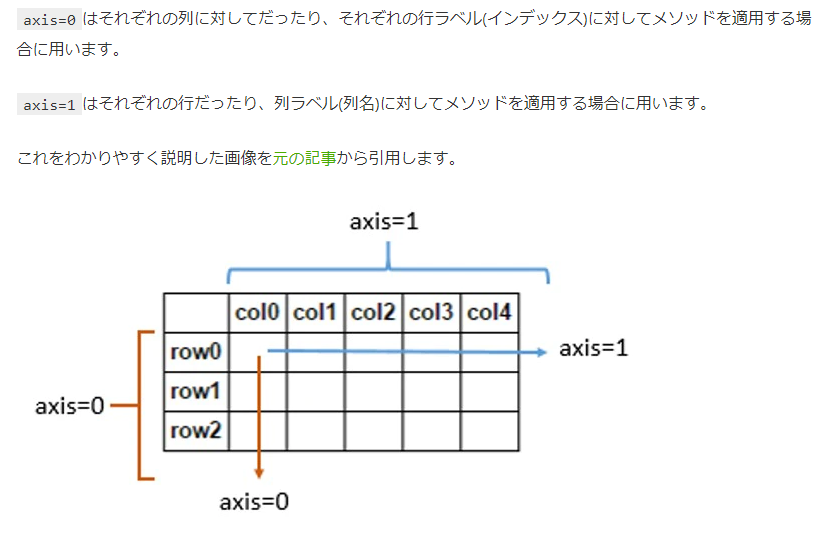
[pandasのaxisの方向の覚え方]
(https://qiita.com/udus/items/65eb9416dab37a5562dc)
→df.mean(axis=1)として平均を取ると、行ごとの平均が求まります。
一方で、df.drop(name, axis=1)とすると、列を削除することになります。
pd.concat([df1,df2],axis=1)とすると列方向に結合
filter(regex="xx")列名のワイルドカードの方法
#列名にP1が含まれる要素を全て抽出
P1Channels = data.filter(regex="P1")
str.split(文字の分割)
df_temp = df000["prod_nm"].str.split("P", expand=True)[0]
str.strip(文字の削除)
df_temp = df_temp[1].str.strip(" ")
#.xlsxを削除して後ろから4番目以降の文字列をYearとして取得
Year = filepath.strip(".xlsx")[-4:]
str.replace(文字の置換)
sr_3.str.replace('a-b', 'A')
文字から数値の抽出
import re
for row in df.index:
n = re.sub('\\D','',df.loc[row,"YM"])
print(n)
.loc(数字の置換)
#地味に強い。変にfor文使わなくて良い
df.loc[df.col1 > 4, "col2"] = 100
dogetsu_donaiyo.loc[dogetsu_donaiyo["取引先コード"] == "0", "同月同内容明細数"] = 1
#評価に"反対"というワードが含まれていたら
df.loc[df["評価"].str.contains("反対"),"悪評価フラグ"] = 0
Pandas DataFrameへの置換操作のまとめ
https://qiita.com/kazetof/items/992638be821a617b900a
###データ型変換/型確認,astype,dtype
#型確認
df["CL_CD"].dtype
#型変換
df["CL_CD"].astype(float)
#strから数値への変換は下記がおすすめ
##erros="coerce"をつけるとなぜか上手くいく
df["# of TAB"] = pd.to_numeric(df["# of TAB"],errors="coerce")
#下記で型をintにできる
df["# of TAB"] = pd.to_numeric(df["# of TAB"],errors="coerce",downcast="integer")
#読み込んだ数値データが文字列でかつ","が含まれている場合。下記の処理が必要
#そのままpd.to_numericをするとNanとなる
df["通貨"] = df["通貨"].str.replace(",","")
#たまに小数点が隠れていることがあるので下記も実行(intの場合はre.sub("\.\d+","",x)
df['通貨'] = df['通貨'].apply(lambda x:re.sub("\.\D+","",x))
df["通貨"] = pd.to_numeric(df["通貨"],errors="coerce",downcast="integer")
#余談
#下記でカンマ区切りにできる
df["通貨"] = df["通貨"].apply(lambda x:'{:,}'.format(x))
[NumPyのデータ型dtype一覧とastypeによる変換(キャスト)]
(https://note.nkmk.me/python-numpy-dtype-astype/)
DataFrameの初期化
df000 = pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
#指定したいときは各要素をリストで(1つでも)指定
df000 = pd.DataFrame(data=None, index=["{}_乖離率平均".format(col_name)], columns=None, dtype=None, copy=False)
DataFrameの考え方
#df001[df001["訪問"] == df001["訪問"].max()]までが1つのDF
df001[df001["訪問"] == df001["訪問"].max()]["顧客ID"]
データの読み込み(excel,csv)
#windowsの時はencoding="cp932"をつける
df_sheet_index = pd.read_excel('data/src/sample.xlsx', sheet_name=1,encoding="cp932")
# memo
ジャストFYIですが、ソースコードで読み込む場合はexcelよりparquet (pd.read_excel(), df.to_parquet())形式で揃えた方が入力、出力が爆速になります
(出力時にカラム単位で型が揃っている必要がありますが)
df_parque = pd.read_parquet(file_path)
#読み込むデータの方を指定することも可能。
#Pythonは型起因によるエラーが多いのでTips
df_sheet_index = pd.read_csv('data/src/sample.csv', sheet_name=1,encoding="cp932",dtype="object")
#2020.12最新のpandasではxlrdがxlsxに対応されなくなったため、最新のpandasにupdateしている場合、engine="openpyxl"をつけることが必要
#事前にpip install openpyxlでopenpyxlのモジュールインストールをすることが必要
df = pd.read_excel('https://github.com/okumuralab/literacy4/raw/master/data/birthdeath.xlsx',engine='openpyxl')
#encoding="cp932"でのエラーが出る場合
import codecs
with codecs.open("test\test.csv", "r", "shift-jis", "ignore") as f:
df = pd.read_csv(f,dtype="object",header=None,names = [・・])
#encoding="cp932"でのエラーが出る場合:file内の複数ファイルの読み込み
dfs = {} # キー:ファイル名, 値:データフレーム
files = glob.glob(r'02.model_apply\01.input\kongetsu\*.csv', recursive=True)
for file in files:
import codecs
with codecs.open(file,"r","shift-jis","ignore") as f:
dfs[file] = pd.read_csv(f,dtype="object",header=None,names = [・・])
#encoding="cp932"エラーが出る場合、下記のような回避も可能
#自身のPCのデフォルトエンコーディングを取得し引数とする
#①
import sys
encoding = sys.getdefaultencoding()
with open(fname,encoding=encoding) as f:
for i, l in enumerate(f):
pass
#②:read_csvの場合はもっとシンプル
import sys
encoding = sys.getdefaultencoding()
#下記の様にtry/except利用すればwindowsのどのようなファイルも扱えそう。
#warn_bad_lines=Falseを付けることで不必要な警告が出ないようにする
try:
df_tmp = pd.read_csv(fname, encoding=encoding, header=i, dtype='object',error_bad_lines=False,warn_bad_lines=False)
except Exception as e:
df_tmp = pd.read_csv(fname, encoding="cp932", header=i, dtype='object',error_bad_lines=False,warn_bad_lines=False)
print(str(e) # NOTE 一応エラーメッセージを出すことも可能
#https://office54.net/python/error/unicode-decode-cp932#section3
### warn_bad_lines=False
#https://stackoverflow.com/questions/43891391/pandas-dataframe-read-skipping-line-xxx-expected-x-fields-saw-y
#人が作ったエクセルは型がめちゃくちゃなことが多いので,converters={"列名":型}で指定する
df = pd.read_excel(r"input\管理簿.xlsx",converters={"番号":int})
データの書き出し(excel,csv)
df000.to_excel("name.xlsx",encoding="cp932",index=False)
#複数のシートに書き出す場合は下記
with pd.ExcelWriter('data.xlsx') as writer:
df1.to_excel(writer, sheet_name='Good Month')
df2.to_excel(writer, sheet_name='oneToThree')
#encoding="cp932"でのエラーが出る場合
# 一度ファイルオブジェクトをエラー無視、書き込みで開く
with open("./sjis.csv", mode="w", encoding="cp932", errors="ignore",newline="") as f:
# pandasでファイルオブジェクトに書き込む
df.to_csv(f,index=False)
# 下記でも行けた(errors="ignore"をつける)
test.to_csv(r"\01.input\kongetsu_file\test.csv",index=False,encoding="cp932",errors="ignore")
#参考
#https://hytmachineworks.hatenablog.com/entry/2018/11/07/155050
#windowsの場合、仕様上各行に空白が出てしまう可能性があるのでnewline=""を引数に追加
#https://qiita.com/ikura1/items/17e6dd19f98145afc2eb
###########encoding="cp932"エラーが出てしまう場合の読み込みと書き出し例######################
#結合先のデータフレームの初期化
dfs = pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
#指定ファイルないのdatファイルを1つずつ読み込み、結合
for file_name in glob.glob(r'C:\Users\xxx\Desktop\1.input\*.dat'):
print(file_name)
with codecs.open(file_name,"r","shift-jis","ignore") as f:
df = pd.read_table(f,header=None)
dfs = pd.concat([dfs,df],axis=0,join="outer")
#結合したファイルをタブ区切りでテキストファイルに保存
with open(r'C:\Users\xxx\Desktop\2.output\BBJPWM10.txt', mode="w", encoding="cp932", errors="ignore", newline="") as result:
dfs.to_csv(result,sep="\t",index=False,header=None)
[pandasでExcelファイル(xlsx, xls)の書き込み(to_excel)]
(https://note.nkmk.me/python-pandas-to-excel/)
###with open("xx.txt) as fデータの読み込み(text)
with open("stopwords_ja2.txt") as f:
l = [s.strip() for s in f.readlines()]
l
[Pythonでファイルの読み込み、書き込み(作成・追記)]
(https://note.nkmk.me/python-file-io-open-with/)
for文、if文
#セル参照
for i in range(len(df004)):
if df004.loc[i,"人口総計"] >= 500000 and ("区" in df004.loc[i,"市区町村名"]):
df004.loc[i,"都市規模"] = "大都市"
elif df004.loc[i,"人口総計"] >= 100000 and df004.loc[i,"人口総計"] < 500000:
df004.loc[i,"都市規模"] = "中都市"
elif df004.loc[i,"人口総計"] >= 10000 and df004.loc[i,"人口総計"] < 100000:
df004.loc[i,"都市規模"] = "小都市"
else:
df004.loc[i,"都市規模"] = "田舎"
#もし該当の文字が含まれていたら
for i in tqdm(df000.index[:]):
if ("関東" in df000.loc[i,"プロモーション地域"]):
df000.loc[i,"効果測定フラグ"] = 1
else:
pass
#下記の様な書き方もできる
#列参照(こっちの方が断然早い)
for col in master.columns[4:]:
master.loc[:,col] = master['dose']*master['tablet']*master.loc[:,col]
#行参照
for row in df0070.index[:]:
if df0070.index.get_loc(row) == 0:
df0070.loc[row,"stack_trust_value"] = df0070.loc[row,"trust_value"]
else:
now_row = df0070.index.get_loc(row)
df0070.loc[row,"stack_trust_value"] = df0070.loc[row,"trust_value"] + df0070.iloc[now_row-1,51]
stack_trust_value = df0070["stack_trust_value"]
print(stack_trust_value)
#for文を1文で書く方法
# data配列の中身を2倍にする
newData = []
for d in data:
newData.append(d * 2)
↓
# data配列の中身を2倍にする
newData = [d * 2 for d in data]
#if文も組み合わせると下記
newData = []
for d in data:
if d % 2 == 0:
newData.append(d * 2)
↓
newData = [d * 2 for d in data if d % 2 == 0]
#if文を1文で書く方法
if a > 5:
i = a
else:
i = 0
↓
i = a if a > 5 else 0
apply+lambda
df.apply(lambda x: func(x['col1'],x['col2']),axis=1)
#if文も組み込める
#df_S_F["S_F"]の要素が"L->L"ならF1それ以外ならそのままの値を"S_F_new"に代入
df_S_F["S_F_new"] = df_S_F["S_F"].apply(lambda x: "F1" if x == "L->L" else x)
#例えば列名を取ってくる
df_S1['Sequence'] = df_S1.loc[:, '製品コール':].apply(lambda d:d.index[d > 1].values,axis=1)
#移動平均を取る際は下記の様にできる。例は国ごとの移動平均を算出している
df['count'] = df.groupby(['country'])['count'].apply(lambda x:x.rolling(window=3, center=True,min_periods=1).mean())
#関数と組み合わせるのがやはり相性良いのでは?
#下記の例は店舗内全ての店舗が優良である店舗にフラグを立てる
def quality_check(s):
for value in s:
if value != '優良':
return False
return True
df002 = pd.DataFrame(df001.groupby("店舗ID")["顧客カテゴリ"].apply(quality_check))
移動平均については下記を参照
pandasで窓関数を適用するrollingを使って移動平均などを算出
apply(lambda x:)例:偏差値の算出
##偏差値はmeanでもmedianでも良いらしい。分布見て判断
#mean = df000['売上'].describe()["mean"]
median = df000['売上'].median()
std = df000['売上'].describe()["std"]
print(median,std)
df000['DeviationValue'] =
df000['売上'].apply(lambda x: round((x - median) / std * 10 + 50))
#X["A"].apply(lambda x:F(x))
#上記のように書くとlambda(x:F(x))のxにはA列の全行においてf(x)が適用されるイメージ
指定した列に定義した関数を一気に適用
Ref.
https://towardsdatascience.com/apply-and-lambda-usage-in-pandas-b13a1ea037f7
if文で複数条件分岐使うなら関数作った方が良いかも
https://qiita.com/Hyperion13fleet/items/98c31744e66ac1fc1e9f
map
#例えばfrequency encodingで利用する場合
#カテゴリ値を出現頻度の値に変更する
for col in tmp_train_test_forctd.columns[:]:
#カテゴリ変数毎の出現頻度の値を計算
#ex)アメリカの出現頻度が4回とかを算出
freq = tmp_train_test_forctd[col].value_counts()
#列のカテゴリ値を出現頻度に変換
#ex)カテゴリ変数「アメリカ」の値を"4"に変更。
tmp_train_test_forctd[col] = tmp_train_test_forctd[col].map(freq)
推論データと学習データでエンコードラベルを合わせる場合
#取引先コード
##学習コード:ラベルを割り振り割り振り結果を吐き出し
torihikisaki_encode = kongetsu_feature.drop_duplicates(subset="取引先コード",keep="first").loc[:,["取引先コード","取引先コード_encode"]]
torihikisaki_encode.to_csv("torihikisaki_encode.csv",index=False,encoding="cp932")
##推論コード:学習で用いたラベルに合わせる
torihikisaki_encode = pd.read_csv("torihikisaki_encode.csv",encoding="cp932")
torihikisaki_encode = torihikisaki_encode.set_index(["取引先コード"])
kongetsu_feature["取引先コード_encode"] = kongetsu_feature["取引先コード"].map(torihikisaki_encode["取引先コード_encode"]).fillna(0)
groupby
同要素を集約
applyと組み合わせることで複雑な処理も可能に
https://qiita.com/propella/items/a9a32b878c77222630ae
count() — Number of non-null observations
sum() — Sum of values
mean() — Mean of values
median() — Arithmetic median of values
min() — Minimum
max() — Maximum
mode() — Mode
std() — Standard deviation
var() — Variance
###同要素を持つ、文字列を集約
df_Split.groupby("result",as_index=False).agg({"Word":lambda x: ",".join(x)})
df.groupby('city',as_index=False).mean()
#複数指定も可能
df.groupby(['city', 'food']).mean()
#Pandas のグループごとに一意の値をカウントする
df.gruopby(['city','food').nunique()
# https://www.delftstack.com/ja/howto/python-pandas/how-to-count-unique-values-with-pandas-per-groups/
###groupbyで文字列を結合
##少し遅いけど下記
df.groupby('A').apply(lambda x: x.sum())
# https://www.web-dev-qa-db-ja.com/ja/python/pandas-groupby%EF%BC%9A%E6%96%87%E5%AD%97%E5%88%97%E3%81%AE%E7%B5%90%E5%90%88%E3%82%92%E5%8F%96%E5%BE%97%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95/1041034993/
##下記のパターンもあり
df.groupby('a')['b'].apply(', '.join)
# https://www.polka-dot.net/python-pandas-groupby%E3%81%A7%E6%96%87%E5%AD%97%E5%88%97%E3%82%92%E3%83%AA%E3%82%B9%E3%83%88%E5%8C%96/
duplicated(), drop_duplicates()重複しているものを抽出
df000.duplicated()
#重複しているもの以外を最初の1行だけ残して抽出したい場合はkeep="first"(デフォルトがkeep="first"
df001 = df000[~(df000.duplicated(subset="顧客ID",keep="first")]
#drop_duplicates()でも同様の処理が可能
df001 = df000.drop_duplicates(subset="顧客ID",keep="first")
#keep="last"で重複した最後を残す
df001 = df000.drop_duplicates(subset="顧客ID",keep="last")
#keep=Falseで重複レコードを全削除
df001 = df000.drop_duplicates(subset="顧客ID",keep=False)
set_index(["A","B") インデックス(index)の設定
df_mi = df.set_index(['state', 'name'])
print(df_mi)
# age point
# state name
# NY Alice 24 64
# CA Bob 42 92
# Charlie 18 70
# TX Dave 68 70
# CA Ellen 24 88
# NY Frank 30 57
#sort_indexで上記の結果を綺麗に
df_mi.sort_index(inplace=True)
print(df_mi)
# age point
# state name
# CA Bob 42 92
# Charlie 18 70
# Ellen 24 88
# NY Alice 24 64
# Frank 30 57
# TX Dave 68 70
reset_index()インデックス(index)を列に戻す
print(df_i)
# age state point
# name
# Alice 24 NY 64
# Bob 42 CA 92
# Charlie 18 CA 70
# Dave 68 TX 70
# Ellen 24 CA 88
# Frank 30 NY 57
df_ri = df_i.reset_index()
print(df_ri)
# name age state point
# 0 Alice 24 NY 64
# 1 Bob 42 CA 92
# 2 Charlie 18 CA 70
# 3 Dave 68 TX 70
# 4 Ellen 24 CA 88
# 5 Frank 30 NY 57
df_ri = df_i.reset_index(drop=True, inplace=True)
#drop=True を指定しなければ、旧インデックスがデータ列に移動します。
#inplace=True で、オブジェクトを直接書きかえられます。
#isinとかconcatとかした後は実施した方が良い
インデックス(index)毎に演算
print(df_multi.mean(level=['Sex', 'Pclass']))
#例えば下記の様にすると、"ID"、"年月"毎の"#_of_Customer"の合計がDF_Aの"市場計"という列全てに入る
DF_A = DF_B
DF_A["市場計"] = DF_B["#_of_customer"].sum(level=["ID","年月"])
#下記は"ID"、"年月"毎に"#_of_customer"の値が3の営業マンの名称が"優良者"列に入る(indexが異なると名前も変化する)
DF_A["優良者"] = DF_B[DF_B["#_of_customer"] == 3]["営業者名"]
#番号で指定することも可能
print(df_multi.mean(level=[0, 1, 2]))
DataFrameの行と列を入れ替える(転置)
時系列データ時によく使う
import pandas as pd
df = pd.DataFrame({'X': [0, 1, 2], 'Y': [3, 4, 5]}, index=['A', 'B', 'C'])
print(df)
# X Y
# A 0 3
# B 1 4
# C 2 5
print(df.T)
# A B C
# X 0 1 2
# Y 3 4 5
stack,unstack
pandasでstack, unstack, pivotを使ってデータを整形(要マスター)
https://note.nkmk.me/python-pandas-stack-unstack-pivot/
Python: PandasのDataFrameを横持ち・縦持ちに変換する
https://ohke.hateblo.jp/entry/2018/07/21/230000
df005 = df004.set_index(["ID","名称"])
#dropna=FalseとするとNanの行になる
df006 = df005.stack(dropna=False)
df006
#levelを利用してindex名を指定することでunstackする行を編集することも可能
print(df_m.unstack(level='A'))
unstack
行→列
インデックスを行から列に変換する
unstackの方が良く使うイメージ
count_要素をカウントする
DF["顧客名称"].count()
#条件に合う行をカウントTrueの数を合計するのでsum
#行カウントの場合はaxis=1
df["顧客数"] = (df.iloc[:,1:len_columns-4] > 0).sum(axis=1)
value_counts
DF["顧客名称"].value_counts()
ユニークな値毎にその個数をカウント
unique
DF["顧客名称"].unique()
顧客名称のユニークな要素を抽出
nunique
DF["顧客名称"].nunique()
顧客名称のユニークな要素をカウント
loc[row,column]1行1列をピンポイントで取得
df.loc['行名', 'カラム名']
# 出力は値のみ
df_S_F = df_mar_1.loc[:,["顧客ID","施設ID","遷移"]]
#複数指定も可能
iloc["row_number,"column_number"]1列の#番目を取得
df.iloc[:, [1]]
# カッコ内の数値は先頭を0とするカラム番号
#.iloc等pythonでの範囲指定
#始まり=含む、終わり=含まない
df.iloc[:3]
#行番号=0,1,2を取得
df.iloc[1:3]
#行番号=1,2を取得
##右の数値-左の数値=取得できるデータの個数
特定列内のある要素だけ抽出したい場合
h29_hem_inxex = h29_hem[h29_hem["初回再来名称"] == "初回"]
h29_hem_1 = h29_hem[(h29_hem["初回再来名称"] == "初回") & (h29_hem["ヘモグロビン"] >= 10)]
時系列データへの変更、期間抽出
#まず型をTimestampに変更
DF["YM"] = pd.to_datetime(DF["YM"],format='%Y%m')
start = "2019-12-01"
end = "2020-02-01"
DF_201912_202002 = DF[(DF["YM"]>=start)&(DF["YM"]<=end)]
Df_201912_202002 = DF.query('"start" <= YM <= "end"')
Timestamp型への変更は下記
https://deepage.net/features/pandas-to-datetime.html
drop
#1行削除
df.drop(0)
#1行目~3行目削除
df001 = df000.drop(range(0,3))
#1列削除
df.drop('カラム名', axis =1)
#複数列削除
df.drop(['カラム名','カラム名'], axis =1)
###droplevel
#pivot_table等でマルチカラムとなったときに一度列をリセットすることが可能
df.columns = df.columns.droplevel(0)
#行を範囲を指定して削除
#1~2行目を削除する場合
dataDelete = data.drop(range(1, 3))
#列を範囲を指定して削除
dataDelete = data.drop(data.columns[1:3],axis=1)
指定の値がある行だけを取り除く
#削除する削除するという頭だとどうしてもdf[df.A == n]をdropすることばかりに頭がいくが, 逆に考えてn以外の値を持つ行を抽出する
df = df[df.A != n]
.columns
Data Frameの列名の編集(変更)/取得
df_DDD_GP_arrange.columns = ["施設コード","顧客コード"]
#列名の取得
df_DDD_GP_arrange.columns
#列名を1行目の値に全て変更(たまに使う)
df.columns = df.iloc[0,:]
.reindex()
#既存のカラムの順番を任意に変更
df = df.reindex(columns=['C','B','D','F'])
index
df.index
#行名の追加
df.index=["xxx","xxx"]
get_loc
#列番号や行番号を取得
#指定Keyの列番号を取得
df.columns.get_loc("key")
#指定Keyの行番号を取得
df.index.get_loc("key")
# 指定の値のindexを取得:index[0]がポイント
import datetime
from dateutil.relativedelta import relativedelta
today = datetime.date.today()
# 先月を取得
sengetsu = (today - relativedelta(months=1)).strftime('%Y-%m')
index_name = df[df["YM"] == sengetsu].index[0]
print(index_n)
Data Frameへの列の追加
#追加したい列名を宣言してinitを代入しておくだけ
df["新規列"] = 0
rename():Data Frameの列名の変更
df_new = df.rename(columns={'A': 'a','C':'c'}, index={'ONE': 'one'})
loc,iloc 列順の変更
data = pd.read_csv('in.txt', names=('id', 'region', 'weather', 'value'))
dataExchange = data.loc[:, ['region', 'id', 'weather', 'value']]
dataExchange = data.iloc[:, [3,2,1,0]]
reindex_列順の変更
print(df.reindex(index=['Two', 'Three', 'One']))
# A B C
# Two 2 20 200
# Three 3 30 300
# One 1 10 100
print(df.reindex(columns=['B', 'C', 'A']))
# B C A
# One 10 100 1
# Two 20 200 2
# Three 30 300 3
print(df.reindex(index=['Two', 'Three', 'One'], columns=['B', 'C', 'A']))
# B C A
# Two 20 200 2
# Three 30 300 3
# One 10 100 1
#新たな行名・列名を指定すると、デフォルトではすべての要素が欠損値NaNとして追加される。
print(df.reindex(columns=['B', 'X', 'C'], index=['Two', 'One', 'Four']))
# B X C
# Two 20.0 NaN 200.0
# One 10.0 NaN 100.0
# Four NaN NaN NaN
insert:任意の場所への列の挿入
PL_BS_Data_Ts["Company_name"] = "mycompany"
YM = PL_BS_Data_Ts["YM"]
CN = PL_BS_Data_Ts["Company_name"]
PL_BS_Data_Ts.drop(["YM","Company_name"],axis=1,inplace=True)
#末尾に追加された要素を先頭に挿入
PL_BS_Data_Ts.insert(0,"YM",YM)
PL_BS_Data_Ts.insert(1,"Company_name",CN)
isnull().sum()
Nullが含まれている列を調査し、列ごとのnull数を出す
Pythonでの欠損値処理
[Pandasで欠損値処理]
(https://qiita.com/0NE_shoT_/items/8db6d909e8b48adcb203)
#from renom.utility import interpolate
#20220219_renomで補完したいけどgit利用しなきゃいけないから一旦、sklearnで対応->充分
## Scikit-learn の impute で欠損値を埋める
## https://qiita.com/maskot1977/items/ba4ed8a9ba2289204742
## from sklearn.impute import SimpleImputer:確定値による欠損値補完(fillnaと同様)
## from sklearn.impute import KNNImputer:KNNによる欠損値補完:簡易な割にロバストな欠損値補完であると評判。最初に適用
## from sklearn.impute import IterativeImputer:多重代入法による欠損値(欠損値以外の値から分布を推定し、欠損値を埋める):最も良さそう。ただ最適な手法を選ぶコストが大きい
from sklearn.impute import KNNImputer
for mobile_model in gerakuritsu_mobile_model_dict.keys():
#n_neighbors = パラメータなので自由に設定可能:時系列モデルの値を見ながらモニタリング
try:
imputer = KNNImputer(n_neighbors=5)
sample_df = pd.DataFrame(
#imputer.fit_transform(gerakuritsu_mobile_model_dict[mobile_model].loc[:,"European Union - 27 countries (from 2020)":])
imputer.fit_transform(gerakuritsu_mobile_model_dict[mobile_model].loc[:,'Samsung_Chuto':])
)
#sample_df.columns = gerakuritsu_mobile_model_dict[mobile_model].loc[:,"European Union - 27 countries (from 2020)":].columns
print(mobile_model)
## 指定した期間でレコードが1つしかない場合、knnによる欠損値補完が出来ないので対象列が削除される。それにより列が合わないエラーが起きうる
sample_df.columns = gerakuritsu_mobile_model_dict[mobile_model].loc[:,'Samsung_Chuto':].columns
gerakuritsu_mobile_model_dict[mobile_model] = \
pd.concat([gerakuritsu_mobile_model_dict[mobile_model].loc[:,:"ハンセン指数"],sample_df],axis=1)
## 指定した期間でレコードが1つしかない場合に正常に処理完了したモデルの欠損値補完結果を利用する
success_model = mobile_model
except:
##レコードが長く欠損値がうまく埋めれているものをマージする
print(mobile_model + "は対象レコードが1レコードの為、" + success_model+ "の値をマージします")
temp_df = pd.concat([gerakuritsu_mobile_model_dict[success_model].loc[:,"YM"],\
gerakuritsu_mobile_model_dict[success_model].loc[:,"Samsung_Chuto":]],axis=1)
gerakuritsu_mobile_model_dict[mobile_model] = \
pd.merge(gerakuritsu_mobile_model_dict[mobile_model].loc[:,:"ハンセン指数"],\
temp_df,on="YM")
#gerakuritsu_mobile_model_dict[mobile_model].fillna(0,inplace=True)
pass
dropna()
#how=allを設定することですべて行がnanの行を削除
df.dropna(how='all')
#特定の列に欠損値がある場合にその行を削除することも可能
df.dropna(subset=['age']
df.dropna(subset=['age', 'state'])
df.dropna(subset=['age', 'state'], how='all')
concat
#二つのデータフレームを結合
#基本的にはconcatで結合するが、appendもある。
df_A.append([df_B,df_C]) = pd.concat([df_A,df_B,df_C],axis=0)
#列名が揃っていなくても下方向に結合可能
#option'join'で指定
df = pd.concat([df_A,df_B,df_C],axis=0,join="outer)"
#縦方向への結合の場合、reset_index()を推奨
df_A_B_C = pd.concat([df_A,df_B,df_C],axis=0).reset_index(drop=True)
```python
#横方方向の連結の場合、axis=1をつける
pd.concat([df1, df2], axis =1)
#データフレーム同士ではなく、column同士の結合もできる
#下記は全ての列を1列に集約するコード
for i, col in enumerate(df000.columns):
if i == 0:
tmp = df000[col]
continue
tmp = pd.concat([tmp,df000[col]], axis =0)
tmp = tmp[tmp.notna()]
tmp
#DataFrameのリストを作ると、concat引数はリストのみでリスト内の全結合が可能
df_list = []
for i range(len(hogehoge)):
df = pd.read_csv("hogehoge_{}.csv".format(i))
df_list.append(df)
all_df = pd.concat(df_list)
merge,マージ
ExcelでいうVlookup
#keyは双方で型が揃っていることを確認
pd.merge(df000, df001, on='key', how='outer')
#key列をキーとして結合する
#inner: 既定。内部結合。両方のデータに含まれるキーだけを残す。
#left: 左外部結合。ひとつめのデータのキーをすべて残す。
##leftするとレコード増えてしまうこともあり。
##その場合はdrop_duplicate等で対応
##参考:https://tiruka.hatenablog.jp/entry/2018/09/06/112413
#right: 右外部結合。ふたつめのデータのキーをすべて残す。
#outer: 完全外部結合。すべてのキーを残す。
#left_on right_onで違うkeyを設定することも可能
#keyは双方で型が揃っていることを確認
df_mar_1_merge_pre = pd.merge(df_mar_1_ext,df_Dr_info,left_on='顧客ID',right_on='顧客コード',how='left')
df_mar_1_merge = pd.merge(df_mar_1_merge_pre,df_DrTgt,left_on='医顧客コード',right_on='Client_CD',how='left')
#時系列データのmerge
#日付とIDのkeyを複数指定(この時、leftとrightで指定した型がそれぞれ正しいことを確認)
DF_C = pd.merge(DF_A,DF_B,left_on=['date', 'user_id'],right_on=["年月","ID"],how='left')
[時系列データで使うPandas小技集]
(https://ohke.hateblo.jp/entry/2018/05/05/230000)
注意!
mergeの際にtimestampデータの型を"object"に変更したとして、
その値が"2018-12-01 00:00:00"とかだとmergeの際にtimestamp含まれてるよ!
と注意されるその場合は、
- Excelで元データの表示形式を変更
- Python上で"201812"といった形式に変換する必要が有る
その時のコードとして下記
[参考:Pythonで文字列 <-> 日付(date, datetime) の変換]
(https://qiita.com/shibainurou/items/0b0f8b0233c45fc163cd)
#timestampデータを文字列に変更
df["年月_str"] = df["年月"].apply(lambda x: x.strftime("%Y%m"))
その他にも時系列データは取り扱いを注意すること。
[参考:Pandasの日付が縦に並んでいるデータフレームで、欠けている日付の行を補う方法と気をつけること]
(https://qiita.com/hanon/items/29cf5ed9acb4f731538f)
↑left_index, right_indexでindexを利用した結合もできるらしい。要理解
as_matrix()→いまはvaluesしか使えないようです。
X = wine.loc[:, ['density']].as_matrix() # ★該当箇所
# 目的変数に "alcohol (アルコール度数)" を利用
Y = wine['alcohol'].as_matrix() # ★該当箇所
# 説明変数に "density (濃度)" を利用
X = wine.loc[:, ['density']].values # ★変更後
# 目的変数に "alcohol (アルコール度数)" を利用
Y = wine['alcohol'].values # ★変更後
#?np.asarray() or np.arrays()でも同様の操作可能?
#参考:https://qiita.com/f0o0o/items/1090b71fba1d053f5f67
X = np.asarray(wine.loc[:, ['density']])
【Pandas】as_matrix()でエラー、valuesに変換
https://ntnl-it-wiz.blogspot.com/2018/11/pandasasmatrixvalues.html
データフレームをアレイに変換
ランダムフォレストに入力するときや、ディープラーニングに入力するときに使える
データフレームへ変換:pd.series or pd.DataFrame
アレイをデータフレームに変換
pd.DataFrameの方が上手くいく気がする
ex)
#Light GBMで出した成功確率を元のリストに結合
y_pred_train_df = pd.DataFrame(y_pred_train)
pd.concat([train_x,y_pred_train_df],axis=1)
describe()
a = df000.describe().loc["max"]
sum()
#locで範囲指定してaxis=1で行の値を全てタス
df000["リモート"] = df000.loc[:,"311_General_視聴":"332_Pat/Com_視聴"].sum(axis=1)
fillna()
#inplace =Trueで上書きできる
train["フラグ"].fillna(0,inplace=True)
#method = 'ffill'
df_method.fillna(method='ffill') # 直前の値を使って埋めていく
#method = 'bfill'
df_method.fillna(method='bfill') # 直後の値を使って埋めていく
https://note.nkmk.me/python-pandas-nan-dropna-fillna/
#Pandasでnan値を削除、穴埋めするfillna、dropnaの使い方

qcut()
#下記は4分位に分割
mpg['mpg_qcut'] = pd.qcut(x = mpg['mpg'], q = 4, labels = [1,2,3,4])
sort(), sorted(),sort_values()
nums = [3, 1, 9, 6]
nums.sort()
print(nums) # [1, 3, 6, 9]
nums.sort(reverse=True)
print(nums) # [9, 6, 3, 1]
nums_1 = [3, 1, 9, 6]
nums_2 = sorted(nums_1)
print(nums_1) # [3, 1, 9, 6]
print(nums_2) # [1, 3, 6, 9]
nums_3 = sorted(nums_1, reverse=True)
print(nums_3) # [9, 6, 3, 1]
#辞書の並び替えはlambdaを使う
#keyで並び替えたいとき
score = {'kokugo': 33, 'sansuu': 85, 'eigo': 60}
score.sort() # AttributeError: 'dict' object has no attribute 'sort'
score_sorted = sorted(score.items(), key=lambda x:x[0])
print(score_sorted) # [('eigo', 60), ('kokugo', 33), ('sansuu', 85)]
#valueで並び替えたいとき
score = {'kokugo': 33, 'sansuu': 85, 'eigo': 60}
score_sorted = sorted(score.items(), key=lambda x:x[1])
print(score_sorted) # [('kokugo', 33), ('eigo', 60), ('sansuu', 85)]
# dictで囲むとsort結果をdictに出来る
score_sorted = dict(sorted(score.items(), key=lambda x:x[1]))
print(score_sorted) # {('kokugo', 33), ('eigo', 60), ('sansuu', 85)}
#辞書のリスト
scores = [
{'kokugo': 33, 'sansuu': 85},
{'kokugo': 77, 'sansuu': 23},
{'kokugo': 55, 'sansuu': 100}
]
scores_sorted = sorted(scores, key=lambda x:x['kokugo'])
print(scores_sorted)
# [
# {'kokugo': 33, 'sansuu': 85},
# {'kokugo': 55, 'sansuu': 100},
# {'kokugo': 77, 'sansuu': 23}
# ]
# sort_values() NOTE: arrayのsort
# 書き方は二通り
df["金額"].sort_values(ascending=False) # ascending=False:降順
df.sort_values('金額')
option:keyにて組み込み関数を指定することも可能。
l = [1, -3, 2]
print(sorted(l))
# [-3, 1, 2]
print(sorted(l, key=abs))
# [1, 2, -3]
#lambda式の指定も可能
print(sorted(l_2d, key=lambda x: max([abs(i) for i in x])))
# [[2, 10], [-3, 20], [1, -30]]
#標準ライブラリoperatorのitemgetter()はリストの要素や辞書の値を取得する呼び出し可能オブジェクトを返す。
#以下のように、リストのリストを任意の位置(インデックス)の値に従ってソートできる
import operator
l_2d = [[2, 10], [1, -30], [-3, 20]]
print(sorted(l_2d, key=operator.itemgetter(1)))
# [[1, -30], [2, 10], [-3, 20]]
Pythonのsorted()やmax()などで引数keyを指定
Scaling処理(正規化,標準化)
時系列データのクラスタリング
Pythonで正規化・標準化(リスト、NumPy配列、pandas.DataFrame)
#### 正規化
from sklearn.preprocessing import MinMaxScaler
ms = MinMaxScaler()
#### 縦に時系列推移となるようにデータを転置
group_1_for_ms_t = group_1_for_ms.T
#### 小技:元のDataFrameの値を丸ごと正規化したい場合の書き方
group_1_ms = group_1_for_ms_t.copy()
group_1_ms.loc[:,:] = ms.fit_transform(group_1_for_ms_t)
#### 標準化
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
group_1_ms.loc[:,:] = ss.fit_transform(group_1_for_ms_t)
#### そのままCluster
### NaNがあるとClustering出来ないので
group_1_ms.fillna(0,inplace=True)
### 縦に時系列推移から横に時系列推移に再変換
group_1_ms_t = group_1_ms.T
### 階層クラスター
#from scipy.cluster.hierarchy import linkage,dendrogram
#pred = linkage(group_1_ms_t,metric = 'euclidean',method="ward")
### K-means
from sklearn.cluster import KMeans
pred = KMeans(n_clusters=4).fit_predict(group_1_ms_t)
### 元のDataFrameに結合しやすいようにDataFrameに変換
pred_df = pd.DataFrame(data=pred,columns=["# of cluster"])
### 結合処理
group_1_ms_t = group_1_ms_t.reset_index(drop=True)
group_1_ms_t = pd.concat([group_1_ms_t,pred_df],axis=1)
相関が大きい特徴量の排除
#相関が大きい値の排除
threshold = 0.7
feat_corr = set()
corr_matrix = train_x_feature.corr()
corr_matrix.fillna(0,inplace=True)
for i in range(len(corr_matrix.columns)):
#for j in range(len(corr_matrix.index)):
for j in range(i):
if abs(corr_matrix.iloc[i, j]) > threshold:
feat_name = corr_matrix.columns[i]
feat_corr.add(feat_name)
''' #loc ver.
for i in corr_matrix.columns:
for j in corr_matrix.index:
if abs(corr_matrix.loc[i, j]) > threshold:
feat_name = corr_matrix.columns[i]
feat_corr.add(feat_name)
'''
train_x_feature.drop(labels=feat_corr, axis='columns', inplace=True)
valid_x_feature.drop(labels=feat_corr, axis='columns', inplace=True)