解決するのに少し手間取ったのでメモ
環境設定
import pandas as pd
from datetime import date, timedelta
PCはmacです。
何をやりたいのか
日付が並んでいるデータフレームに対し、欠けている日付を補います。
例えば、2/14から2/18の売上データがあるとします。
tmp = pd.DataFrame(
{"売上個数": [2, 3, 1]},
index=[pd.to_datetime("2018-2-14"), pd.to_datetime("2018-2-16"), pd.to_datetime("2018-2-17")])
tmp
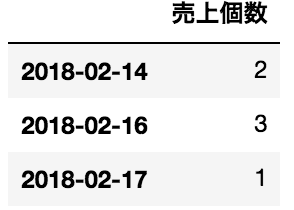
このデータフレームでは2/15と2/18のデータが欠けています(2/14-2/18の売上データなので)。
売上個数が欠測した理由はさておき、2/15と2/18に売上個数NAの行を追加したい場合、どのようにすれば良いでしょうか。
どうすればできるのか
補完したい期間の日付を入れたデータフレームを作ってマージしましょう。
日付を入れる場所はindexでも列でも大丈夫です。
実際にやってみます。
'''
補完したい日付のデータフレームを作る
'''
# indexに日付を入れる場合
dates_DF = pd.DataFrame(index=[pd.to_datetime("2018-2-14") + timedelta(days=i) for i in range(5)])
# okadateさんのコメントを反映、こちらの方が綺麗
dates_DF = pd.DataFrame(index=pd.date_range('2018-2-14', periods=5, freq='D'))
# 列に日付を入れる場合
dates_DF2 = pd.DataFrame({"日付": [pd.to_datetime("2018-2-14") + timedelta(days=i) for i in range(5)]})
'''
マージ
'''
# index同士を結合させる場合
tmp.merge(dates_DF, how="outer", left_index=True, right_index=True)
# indexと列を結合させる場合
tmp.merge(dates_DF2, how="outer", left_index=True, right_on="日付")

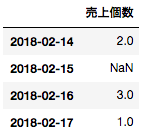
2/15と2/18の行を補うことが出来ました。
indexしかない空の日付データフレームを作るのがポイントです。
(列に日付を入れたデータフレームを作っても結果は変わりません)
追記
欠測している日付がデータの間である場合はpd.resampleで補完が出来るそうです。
# resampleは時系列データの解像度(頻度)を変更する関数
# データの圧縮などに使えるが、この場合は欠けている日付を補う事も出来る
tmp.resample('D').mean()
気をつけること
pandas.to_datetime()はdatetimeではなくTimestampを返すことに注意しましょう。
indexでマージする場合は問題ありませんが、列でマージする場合、Timestampとdatetime.dateをマージするとTimestampが日付からUNIX時間(1970年1月1日 午前0時0分0秒からの経過秒数)になったりエラーを吐いたりします。
特に理由がなければマージはindexで行うか、列で行う場合は元の日付の型がTimestampなのかdatetime.dateなのか確認して、それに合わせた型を準備しましょう。
まず、型を確認しましょう。
type(pd.to_datetime("2018-2-14")) # => pandas._libs.tslib.Timestamp
type(date(2018,2,14)) # => datetime.date
pd.to_datetime()はTimestamp、date()はdatetime.dateであることがわかります。
次に、datetime.dateとTimestampでマージをしてみましょう。
'''
前処理
'''
# datetime.dateの売上データを作る
tmp_dt = pd.DataFrame(
{"売上個数": [2, 3, 1]},
index=[date(2018, 2, 14), date(2018, 2, 16), date(2018, 2, 17)])
# datetime.dateの日付データを作る
# timedeltaはTimestampに対してもdatetime.dateに対しても計算出来る
dates_DF_dt = pd.DataFrame(index=[date(2018, 2, 14) + timedelta(days=i) for i in range(5)])
# Timestamp型であることを明示する
tmp_ts = tmp
dates_DF_ts = dates_DF_ts
売上:Timestamp, 日付: datetime.dateの場合
# indexでマージ
tmp_ts.merge(dates_DF_dt, how="outer", left_index=True, right_index=True) # 問題ない
# 列でマージ
# reset_index()でindexにある日付を列に持ってこられる
# その場合列名は"index"となる
tmp_ts.reset_index().merge(dates_DF_dt.reset_index(), how="outer", on="index") # エラー
indexでマージをする場合は問題ありませんが、列でマージをするとエラーを吐きます。
売上: datetime.date, 日付: Timestampの場合
# indexでマージ
tmp_dt.merge(dates_DF_ts, how="outer", left_index=True, right_index=True) # 問題ない
# 列でマージ
tmp_dt.reset_index().merge(dates_DF_ts.reset_index(), how="outer", on="index") # エラーは吐かないが上手くマージ出来ない
indexでマージする場合は問題ありませんが、列でマージした場合出力は以下のようになります。
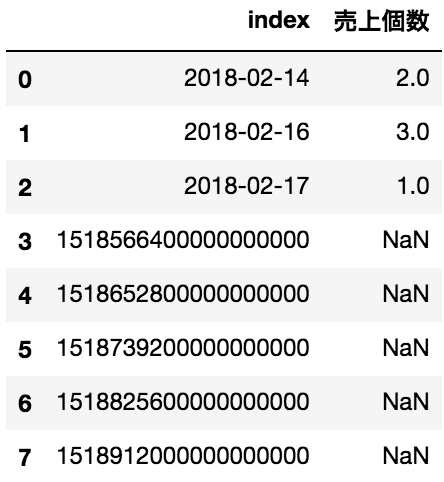
日付データフレームのTimestampがUNIX時刻(int)になっていることがわかります。
まとめ
- 日付が縦に並んでいるデータフレームに対し欠けている日付の行を補いたいときは、日付のデータフレームを作ってマージする
-
resampleやdate_rangeを使った方が綺麗 -
pandas.to_datetime()はTimestampを返すので注意 - マージはindexで行った方が安全