本ブログは、超初心者でも機械学習を利用した予測モデルが構築できるようになる内容となってます
教材としては、Kaggle_GettingStartedのTitanic: Machine Learning from Disasterを利用し、その予測過程を解説します
本ブログは下記の順番で展開します
- データクレンジング(データ前処理)
- Light GBM(予測モデリング手法)の適用
「誰でも」 (精度は置いておいて)__Light GBMという先端的な予測モデリング手法を利用して、二値分類予測モデルが解けることを目的__としているので、中級者が読むとしょうもないことも、途中で記載しております
また本ブログは 下記2点を前提として進めております
- kaggleを知っている
- jupyter(データ分析プラットフォーム)を利用している
kaggleを初めてやるという方はこちらのQiitaブログからkaggleの開始方法をご確認下さい
分析かじっていて色々用語は知ってるんだけど、一回も実装したことが無い。。という方には特におすすめです
それ以外の方でも「読んでやるよ」という方は下記にてお進みください
1.データクレンジング(データ前処理)
今回、__Light GBM__というモデリング手法を使用します。kaggleの上位ランカーがかなり利用しており、実装は簡単ですが非常に精度の高い機械学習ライブラリとして注目されている手法です
そのLight GBMに必要なデータを与えると、予測結果を返してくれるという単純な仕組みなのですが、
与えるデータにざっくり下記の3つの条件が有ります
- 教師データと予測データの入力データ(データ種類、データ型、列数)が揃っていること(説明変数の設定)
- 欠損値(データ上の空白)が無いこと(欠損値の補完)
- 取り込まれるデータは全て「数値データ」であること(ダミー化)
数値データってintですか!?floatですか!?とかいろいろツッコミ来そうですが、最初はこれで十分です
なのでこれらの条件を満たすためにデータを綺麗にする、「データクレンジング」という処理を行います
ちょっと地味な作業になりますがお付き合いください
まず、教師データ(train)と予測データ(test)を読み込みます
厳密には予測データ(test)では無いと言われそうですが、最初はこちらの方が理解しやすいのでこのように記載します
import pandas as pd
test = pd.read_csv("test.csv" , encoding="CP932")
train = pd.read_csv("train.csv", encoding = "CP932")
*Tipsですが、windowsの人はencoding="CP932"をつけると日本語読み込む際に文字化けが消えます(今回は意味ないです)
*test.csvとtrain.csvはkaggleのCompetition内のTitanic:Machine Learning from Disaster(こちら)からダウンロードできます
次に教師データ(train)を教師データ説明変数(train_x)と教師データ目的変数(train_y)に分け読み込み、予測データ(test)はそのまま予測データ説明変数(test_x)として読み込みます
説明変数と目的変数って?という方もググったらすぐ分かりますが、
こちらが分かりやすいです。
train_x = train.drop("Survived",axis=1)
train_y = train["Survived"]
test_x = test
躓きポイント
この後、「欠損値の補完」→「ダミー化」と進んでいくのですが、
「ダミー化」の際に、train_xとtest_xのcolumns数(列数)が揃っておく必要が有ります
今の状態でダミー化してしまうと、列数が500列程数がズレてしまいLight GBMに与えるデータとして使えないので、ここからさらに説明変数に使用するカテゴリを絞ります
ここは最初実装するときに、割と躓きやすいポイントだと思います
よくモデルを作成する際にその精度を向上させるために行う「チューニング」という作業が有りますが、
この説明変数の設定もチューニングの一つです
*ダミー化が分からない方はこちらをご参照下さい
「ダミー化」とは簡単に言うと、文字列データを数値化するよといったニュアンスです。詳細はリンクで
上記の躓きポイントを解消するために説明変数を絞り込みます
今回は__"Name"(乗客の名前) "Ticket"(チケット番号) "Cabin"(部屋番号)は"Survived"(生存結果1:生存,0:死亡)に寄与しないという仮説を立て__、この3カテゴリを省いたものを説明変数とします
train_x = train_x.drop(["Name","Ticket","Cabin"],axis=1)
test_x = test_x.drop(["Name","Ticket","Cabin"],axis=1)
以上のコードで 1.説明変数の設定 が完了致しました
次に、2.欠損値の補完 を行います
最初に、すぐに欠損値の補完を行うのでは無く、__どのカテゴリにどの程度欠損値があるかを把握__します
確認するコードは下記です。(最初に教師データ説明変数(train_x)で確認しております)
train_x.isnull().sum()
結果は下記です
PassengerId 0
Pclass 0
Sex 0
Age 177
SibSp 0
Parch 0
Fare 0
Embarked 2
Ageの欠損が目立ちますね
Embarked(出港した港)も欠損値が2つ見られます
同様に、予測データ説明変数(test_x)でも確認します
test_x.isnull().sum()
PassengerId 0
Pclass 0
Sex 0
Age 86
SibSp 0
Parch 0
Fare 1
Embarked 0
こちらも同様にAgeの欠損が目立ち、Fare(乗船料金)にも一つ欠損が見られます
以上より"Age""Fare""Embarked"に対して欠損値補完の方針を検討し、実行します
今回の欠損値補完方針は下記で行います
- Age = 全体の乗船者年齢の中央値(median)
- Fare = 全体の乗船料金の中央値(median)
- Embarked = "S"(Sの港を利用した人が最も多いので)
中央値じゃなくて、平均値じゃダメなんですか!とも言われそうですが 結論OKです
ここも __チューニングポイントの一つ__なので、この値をどう設定するかも後の予測結果に影響してきます
ただ、この中では深く議論しません。欠損値を埋めるという目的をただ遂行します
ちなみにEmbarkedで"S"が一番多いのを判定したプログラムは下記です
train_x["Embarked"].value_counts()
これにより下記の通り出力が有ります
S 270
C 102
Q 46
上記結果をtest_xにも適用して、__Sが最も多いと判定__し、欠損値の補完要素の1つとして採用致しました
value_counts()は、__選択した列に含まれる文字のユニーク数をカウントしてくれる__コードなので割と頻出で良く使えます
話を戻して、決定した方針を元に、実際に欠損値を補完します
コードは下記です
train_x["Age"] = train_x["Age"].fillna(train_x["Age"].median())
train_x["Fare"] = train_x["Fare"].fillna(train_x["Fare"].median())
train_x["Embarked"] = train_x["Embarked"].fillna("S")
test_x["Age"] = test_x["Age"].fillna(test_x["Age"].median())
test_x["Fare"] = test_x["Fare"].fillna(test_x["Fare"].median())
test_x["Embarked"] = test_x["Embarked"].fillna("S")
__fillna("補完値")__でデータが空白(Nan)の値を指定した"補完値"で補完出来ます
ちなみに__median()__というのが中央値を算出するコードです
以上で 2.欠損値の補完 が完了致しました
最後に、3.データをすべて数値化(ダミー化) を行います
ダミー化については再掲ですがこちらをご覧ください。
そしてダミー化を行うコードは下記です
train_x_dummy = pd.get_dummies(train_x,columns=["Sex","Embarked"])
test_x_dummy = pd.get_dummies(test_x,columns=["Sex","Embarked"])
教師データ(train_x)、予測データ(test_x)それぞれにpd.get_dummies()を適用すれば、一行でダミー化完了です
少し長かったですが、ここまでで1.データクレンジング(データの前処理)が終了致しました
__実際のAnalyticsプロジェクトでもデータクレンジング(データの前処理)はきついポイントの1つ__となってますので、以前最もセクシーな職業と言われたデータサイエンティストも、業務の大半がこういった地味な作業であることがほとんどです
それでは、ここから ___2.Light GBM(予測モデリング手法)の適用___に移ります
2. Light GBM(予測モデリング手法)の適用
まずLight GBMを利用するために必要なライブラリ(モジュールともいったりします)を分析環境上に読み込みます
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import metrics
import numpy as np
これらは「おまじない」なので実践するときもコピペして使ってもらって結構です
ちなみにLight GBMは事前にPC上にインストールしておく必要があります。
windowsの方はanaconda prompt、macの方はterminal上でpip installで簡単に落とせますのでまだインストールしてないという方はこちらを参照下さい。
次に、「モデル」を作成していきます
よく分析屋がモデルの構築とか、モデルの精緻化とかモデルモデル言ってますが、
要は関数です
皆さんが中学、高校でやった y = ax + bとかそういったものが「モデル」です
なので、分析屋が「モデルの構築」とか言ってたら、
ああ、要はちょっと複雑な関数を作るのね、y=ax + bみたいな
とかって思っておけばいいです
y = ax+bで説明すると、"y"が目的変数。今回で言うとtrain_y。カテゴリでいうと、"Survived"(生存結果1:生存,0:死亡)で、
"x"が説明変数。今回で言うとtrain_xとかになります
Light GBM(予測モデリング手法)を適用することで、上記の"a"や"b"の、係数や切片を特定することが出来ます。この係数や切片を求める行為が「モデルの構築」となります
ここら辺がまとめてある物がなくて、あえて混乱させているようにしか見えないほど難しく記載するものばかりでしたので書いてみました
「モデル」は「関数」
中学、高校でみんな「モデルの構築」やってます
前置きが長くなってしまいましたがここから「モデルの構築=関数の作成」を行います
コードは下記です
model = lgb.LGBMClassifier()
model.fit(train_x_dummy,train_y)
以上です
たった二行でモデルが出来ました
一行目はおまじないです
今回使用した、"lgb.LGBMClassifier()"の他に、"lgb.LGBMRegressor()"というのもあります
前者の方は分類問題で使用する関数です、今回でいうと__「生き残った人と死んでしまった人を分類する」__ので適用しています
後者の方は値予測(回帰問題)で使用する関数です、例でいうと、__価格の予測、販売予測とかそういった具体的な数値を予測する場合__に使用します。別で解説します
二行目は
model.fit("教師データ説明変数"、"教師データ目的変数")
という構成です
これにより教師データから、y=ax+bのaとbを求めモデル=関数を作成しています
*注意:実際はy=ax+bでは無くもっと高次です、こんな単純じゃありませんがあくまで理解のために単純化しております
そして最後に、「予測」を行います。
今回で言うと、予測データ説明変数(test_x)から予測データ目的変数"Survived"を予測判定します
y_pred = model.predict(test_x_dummy)
以上、一行です
予測データ目的変数は"y_pred"で表現しております
y_predに予測判定結果が格納されてます。これでLight GBM(予測モデリング手法)の適用が完了し、機械学習の実装を達成致しました
3.最後に
本ブログの通りに実行し、kaggleにsubmitした結果下記でした
良くもないけど悪くもないといった感じですね
何も捻り加えてないのにさすがLight GBM。。。
モデル作成部分(model = lgb.LGBMClassifier()の)()内で)まだまだチューニングの余地が多分にあるのでそこを調整するとより精度の高い予測モデルが構築できそうです!
今後も更新を予定しており、次回はPricing(価格予測)の機械学習モデルの構築を予定してます
2019.04.08追記 : 4.説明変数の評価
今回の予測モデルの中で、で結局何がTitanic号の生死を分けたのかを検証するコードも紹介しようと思います。
下記です。
lgb.plot_importance(model, figsize=(12, 6))
これにより下記の結果が出力されます。
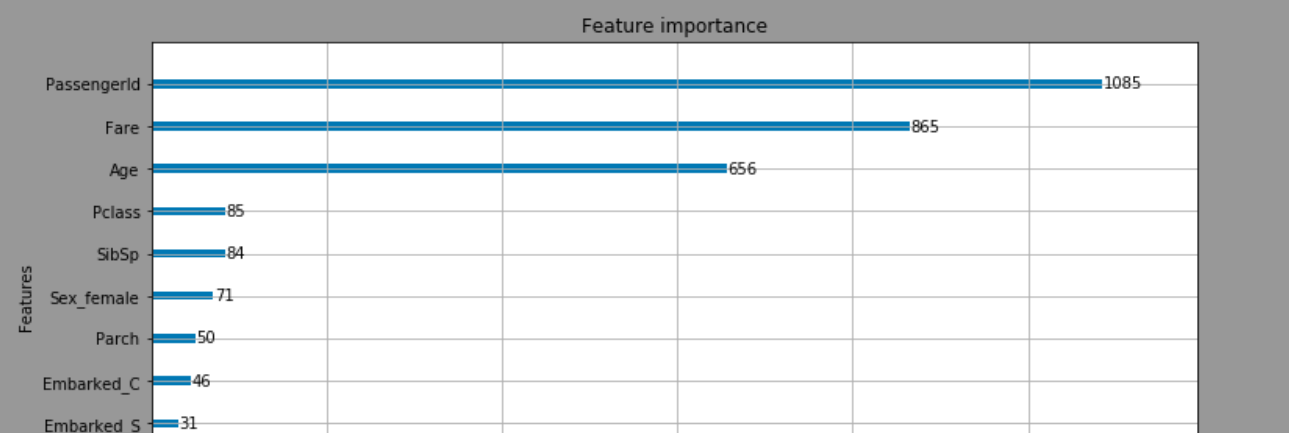
上記は今回設定した説明変数のうち、どの変数が重要かを示している横棒グラフです
今回で言うと、一番上の"Passenger ID"は乗客毎の固有IDなので解釈からは省くとして、
次に重要度が高いのが、"Fare(乗船料金)"というのは、高い料金を払った人が良く助かっているというのはなんとなく予想出来る結果となります。優先的に救助が行われたのでしょう。
次に高い__"Age(年齢)"からは、若い人を中心に救助活動が行われていた__ことが想定できます。
その他に、__"Sex_female(性別_女性)"が重要度が"Sex_male"より高いことから女性を中心に救助活動が行われていた__ことなどが想像できますね。
このようにLight GBMではどういった説明変数がその予測に最も寄与したかも視覚的に表現することが可能です。
予測理由の解釈等でクライアントへの説明が必要な際に是非活用してみて下さい!
2019.08.29追記 各乗客の生存確率
predict_proba()という関数を使うことでその乗客の生存確率も算出することが出来るようです。
# 教師データにモデルを適用し、各乗客の生存確率を計算
y_pred_train = model.predict_proba(train_x)
y_pred_train
# output
array([[0.95371417, 0.04628583],
[0.00143701, 0.99856299],
[0.29402107, 0.70597893],
...,
[0.73775402, 0.26224598],
[0.04120933, 0.95879067],
[0.96127199, 0.03872801]])
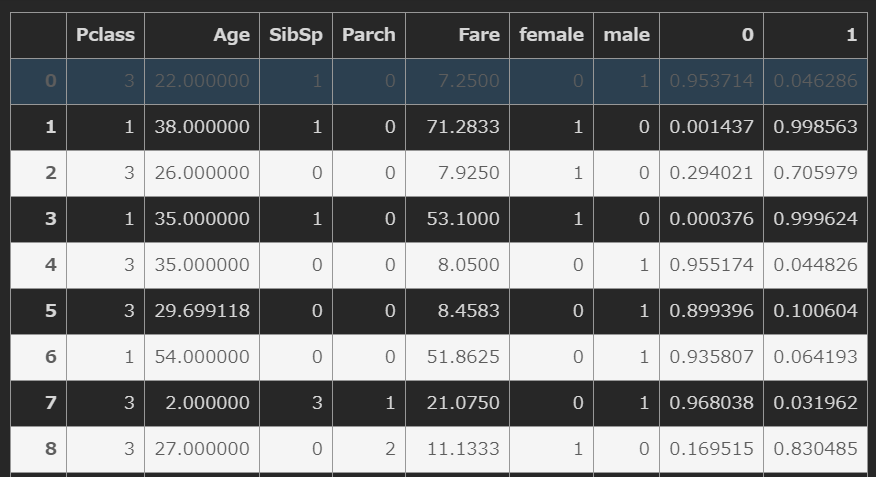
# データフレームに変換して、元の教師データに結合すると見やすい
y_pred_train_df = pd.DataFrame(y_pred_train)
pd.concat([train_x,y_pred_train_df],axis=1)
0 が死亡、1が生存でそれぞれ確率が出る。
Ref.各カラムの説明
PassengerId – 乗客識別ユニークID
Survived – 生存フラグ(0=死亡、1=生存)
Pclass – チケットクラス
Name – 乗客の名前
Sex – 性別(male=男性、female=女性)
Age – 年齢
SibSp – タイタニックに同乗している兄弟/配偶者の数
parch – タイタニックに同乗している親/子供の数
ticket – チケット番号
fare – 料金
cabin – 客室番号
Embarked – 出港地(タイタニックへ乗った港)
permutaion importance
特徴量を図る指標
https://blog.datarobot.com/jp/permutation-importance
XGBの木を取り出す
graph1 = xgb.to_graphviz(xgb_clf, num_trees=2)