- 製造業出身のデータサイエンティストがお送りする記事
- 今回はデータ解析でよく使われる勾配ブースティングの派生アルゴリズムで、不確実性を考慮した予測が可能なNGBoostを実装してみました。
はじめに
scikit-learnを活用した機械学習の予測モデルは過去の記事に書いておりますので、そちらを参照ください。
今回はNGBoostのみ書きます。
NGBoostとは
NGBoost(Natural Gradient Boosting)とは、「予測の不確かさ」を扱うことができる手法です。一般的な回帰モデルの場合は、1つの予測値を出力しますが、NGBoostでは、その値である確率も予測することができます。
基本的な考え方は、各入力における出力の確率分布をパラメータセットの形で表現し、勾配ブースティングの手法によりこのパラメータを算出します。
NGBoostは回帰問題だけでなく、分類問題などにも利用できます。
詳細は元の論文を読んでください。私も全てを完璧に理解できておりませんので、理論を理解しながら現場で使ってみたいと思っております。
NGBoostの実装
今回はUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いて予測モデルを構築します。
| 項目 | 概要 |
|---|---|
| データセット | ・boston house-price |
| サンプル数 | ・506個 |
| カラム数 | ・14個 |
最初にライブラリーをインストールします。詳細な使い方はuser guideを参照ください。
pip install --upgrade git+https://github.com/stanfordmlgroup/ngboost.git
pythonのコードは下記の通りです。
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston
# データセットの読込み
boston = load_boston()
# データフレームの作成
# 説明変数の格納
df = pd.DataFrame(boston.data, columns = boston.feature_names)
# 目的変数の追加
df['MEDV'] = boston.target
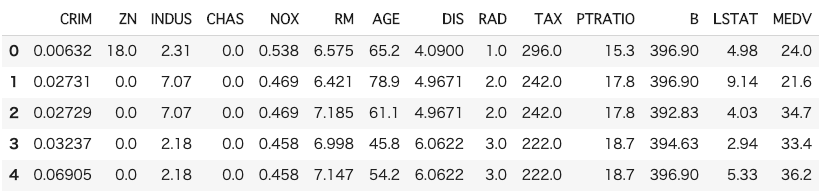
# データの中身を確認
df.head()
具体的なモデルの学習は下記になります。
# ライブラリーのインポート
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 学習データと評価データを作成
x_train, x_test, y_train, y_test = train_test_split(df.iloc[:, 0:13], df.iloc[:, 13], test_size=0.2, random_state=2)
# データを標準化
sc = StandardScaler()
sc.fit(x_train) #学習用データで標準化
x_train_std = sc.transform(x_train)
x_test_std = sc.transform(x_test)
# スコア計算のためのライブラリ
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error
# ライブラリーのインポート
from ngboost import NGBRegressor
# モデルの学習
ngb = NGBRegressor()
ngb.fit(x_train_std, y_train)
# 予測
pred_ngb = ngb.predict(x_test_std)
# 評価
# 決定係数(R2)
r2_ngb = r2_score(y_test, pred_ngb)
# 平均絶対誤差(MAE)
mae_ngb = mean_absolute_error(y_test, pred_ngb)
print("R2 : %.3f" % r2_ngb)
print("MAE : %.3f" % mae_ngb)
# 変数重要度
print("feature_importances = ", ngb.feature_importances_)
出力結果は下記です。
[iter 0] loss=3.6377 val_loss=0.0000 scale=1.0000 norm=6.6433
[iter 100] loss=2.7355 val_loss=0.0000 scale=2.0000 norm=5.1141
[iter 200] loss=2.1841 val_loss=0.0000 scale=2.0000 norm=3.4826
[iter 300] loss=1.9234 val_loss=0.0000 scale=1.0000 norm=1.5236
[iter 400] loss=1.7831 val_loss=0.0000 scale=1.0000 norm=1.4034
R2 : 0.907
MAE : 2.066
feature_importances = [[0.07639064 0.00286589 0.03962475 0.01478072 0.05049657 0.20370851
0.06774932 0.14828321 0.02071867 0.06616878 0.06283506 0.07555015
0.17082773]
[0.0834246 0.00451744 0.04685921 0.00659447 0.04612649 0.22176486
0.05597659 0.14181822 0.0302414 0.0725739 0.07465938 0.08480453
0.1306389 ]]
予測値と実測値を散布図で表してみようと思います。
# ライブラリーのインポート
import matplotlib.pyplot as plt
%matplotlib inline
plt.xlabel("pred_ngb")
plt.ylabel("y_test")
plt.scatter(pred_ngb, y_test)
plt.show()
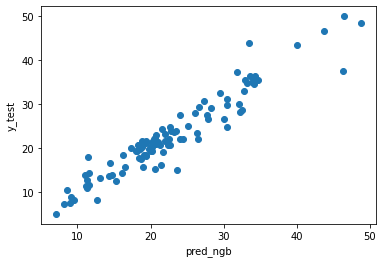
使用したデータは一緒なので過去にscikit-learnを使用して構築した手法MAEを比較してみたいと思います。
| 手法 | MAE |
|---|---|
| NGBoost | 2.066 |
| SVR | 2.904 |
| GBDT | 2.097 |
| RF | 2.122 |
| ElasticNet | 3.080 |
| Lasso | 3.071 |
| Ridge | 3.093 |
パラメータチューニングも何も実施していないので、一概にNGBoostが一番良いとは言えませんが、良さそうですね。
さいごに
最後まで読んで頂き、ありがとうございました。
今回はとりあえずNGBoostをライブラリーを使って実装しただけなので、今後は実務でも使ってみようと思います。
訂正要望がありましたら、ご連絡頂けますと幸いです。