- 製造業出身のデータサイエンティストがお送りする記事
- 今回はAutoML ライブラリー(AutoGluon)を使ってみました。
はじめに
過去に他のAutoML ライブラリーやツールについては、別の記事に纏めておりますので下記をご参照ください。
また、今回はローカル環境では上手く環境構築ができなかった(エラーが直す時間が無かった)ため、Google Colaboratory で実装しております。
ここも単純にpip install ではエラーが発生しましたので、2021/6/24時点では下記方法で実行できると思いますが、将来的に上手くいかない可能性はございます。
AutoGluon を使ってみた
ライブラリーのインストールは下記です(Google Colab 使用前提)。
!pip install --upgrade pip
!pip install --upgrade setuptools
!pip install --upgrade "mxnet<2.0.0"
!pip install --pre autogluon
今回もUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いて実施します。
# ライブラリーのインポート
from autogluon.tabular import TabularDataset, TabularPredictor
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# ボストンの住宅価格データ
from sklearn.datasets import load_boston
# 前処理
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# データセットの読込み
boston = load_boston()
# 説明変数の格納
df = pd.DataFrame(boston.data, columns=boston.feature_names)
# 目的変数の追加
df["MEDV"] = boston.target
# ランダムシード値
RANDOM_STATE = 10
# 学習データと評価データの割合
TEST_SIZE = 0.2
# 学習データと評価データを作成
x_train, x_test, y_train, y_test = train_test_split(
df.iloc[:, 0 : df.shape[1] - 1],
df.iloc[:, df.shape[1] - 1],
test_size=TEST_SIZE,
random_state=RANDOM_STATE,
)
# trainのデータセットの2割をモデル学習時のバリデーションデータとして利用する
x_train, x_valid, y_train, y_valid = train_test_split(
x_train, y_train, test_size=TEST_SIZE, random_state=RANDOM_STATE
)
label = 'MEDV'
feature_names = x_train.columns
train_data = x_train.copy()
train_data[label] = y_train
test_data = x_test.copy()
test_data[label] = y_test
最初に基本的なオプション指定無しで実行してみます。
predictor = TabularPredictor(label='MEDV', problem_type='regression').fit(train_data)
leaderboard = predictor.leaderboard(test_data)
leaderboard
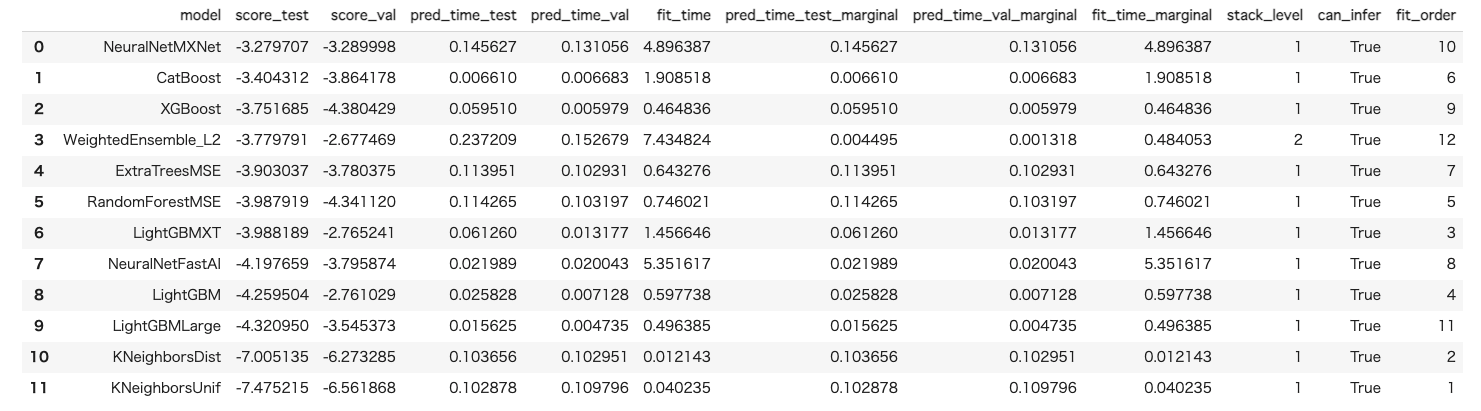
回帰モデルのデフォルトscore-testに表示されている指標はRMSE です。また、全て最大化問題として解けるように-1倍されているため、-1倍した結果が通常のRMSE の値となります。
他の評価指標も下記コマンドで見れます。
y_pred = predictor.predict(test_data)
print("Predictions: ", y_pred)
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)
出力される結果は下記です。
Evaluation: root_mean_squared_error on test data: -3.77979101112008
Note: Scores are always higher_is_better. This metric score can be multiplied by -1 to get the metric value.
Evaluations on test data:
{
"root_mean_squared_error": -3.77979101112008,
"mean_squared_error": -14.286820087744163,
"mean_absolute_error": -2.557449280981924,
"r2": 0.8633895717302121,
"pearsonr": 0.9332392557691281,
"median_absolute_error": -1.7555456161499023
}
Predictions: 305 29.202087
193 28.663527
65 26.790657
349 23.962158
151 18.179682
...
208 23.886160
174 25.854280
108 19.739082
242 20.812876
102 17.641972
Name: MEDV, Length: 102, dtype: float32
次に高精度モデルのAutoGluon を使用してみようと思います。
presets='best_quality' をオプションとして指定するだけですので非常に簡単です。
predictor = TabularPredictor(label='MEDV', problem_type='regression').fit(train_data, presets='best_quality') # 高精度モデル
leaderboard = predictor.leaderboard(test_data)
leaderboard
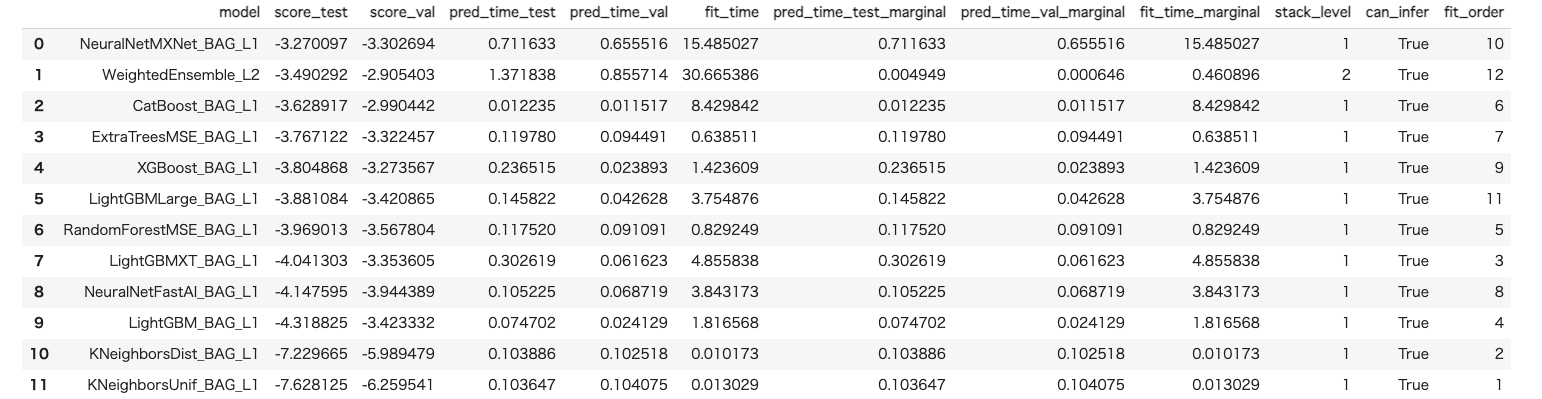
presets のオプションとしては下記パターンが用意されているようで、高精度順にできる順番で下記に記載しておきます。
- best_quality
- best_quality_with_hiigh_quality_refit
- high_quality_fast-inference_only_refit
- medium_quality_faster_train
- optimize_for_deployment
また、time_limits オプションを使うことで設定した学習時間内で高精度なモデルを作成するように指定することもできます。
次にauto_stack のオプションを有効化し、たそうスタックアンサンブルを実行できるようにします。
predictor = TabularPredictor(label='MEDV', problem_type='regression').fit(train_data, auto_stack=True) # Multi-layer stack ensemblingを有効化
leaderboard = predictor.leaderboard(test_data)
leaderboard
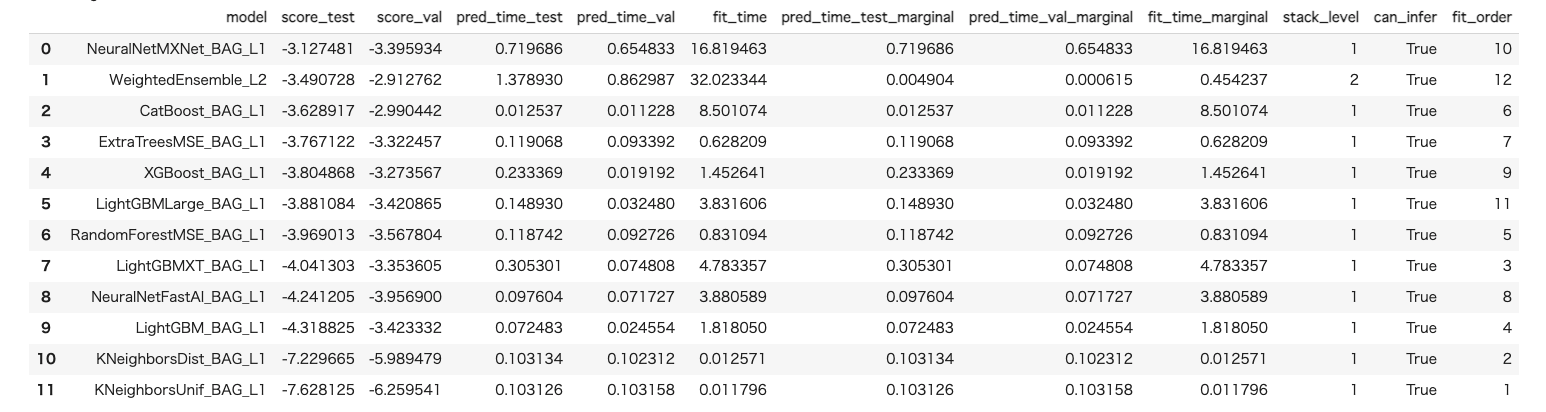
その他、ハイパーパラメータの探索もでき、画像や文書分類とかもできるそうです。
上記までは今回実装できなかったため、時間があれば試してみようと思います。
下記に公式サイトとgithub のサイトを載せておきます。
さいごに
最後まで読んで頂き、ありがとうございました。
個人的にはPyCaret の方が使いやすかったですね。
ただ、AutoGluon はテーブルデータ以外も扱えるAutoML ということで時間があればもう少し触ってみようかと思います。
訂正要望がありましたら、ご連絡頂けますと幸いです。