- 製造業出身のデータサイエンティストがお送りする記事
- 今回はDataRobotみたいなライブラリー(PyCaret)があったので使ってみました。
はじめに
過去に回帰モデルの手法を実装してみましたが、複数のモデルを簡単に比較できると楽だなと思っておりました。世の中のツールではDataRobotと呼ばれるツールがあるのですが、高くて買えないためPythonで似たようなライブラリーが無いかなと思って探していたらPyCaretという機械学習のモデル開発においてデータ前処理や可視化、モデル開発を数行のコードで出来てしまうライブラリを発見しました。
PyCaretを使ってみた
ライブラリーのインストールは下記で簡単にできます。
pip install pycaret
必要なライブラリーとデータを読み込んで、PyCaretを起動させます。
今回もUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いて実施しますが、PyCaret’s Data Repository では、約50種類のデータセットが提供されています。
PyCaretの引数は下記です。
- 第一引数:解析に用いる data(読み込んだデータ)
- 第二引数:予測に用いる目的変数の名称
- 第三引数:分析から外す説明変数の名称
# 必要なライブラリーのインポート
import pandas as pd
from pycaret.regression import *
# データセットの読込み
from pycaret.datasets import get_data
boston_data = get_data('boston')
# PyCaretを起動
exp1 = setup(boston_data, target = 'medv', ignore_features = None, session_id=1498)
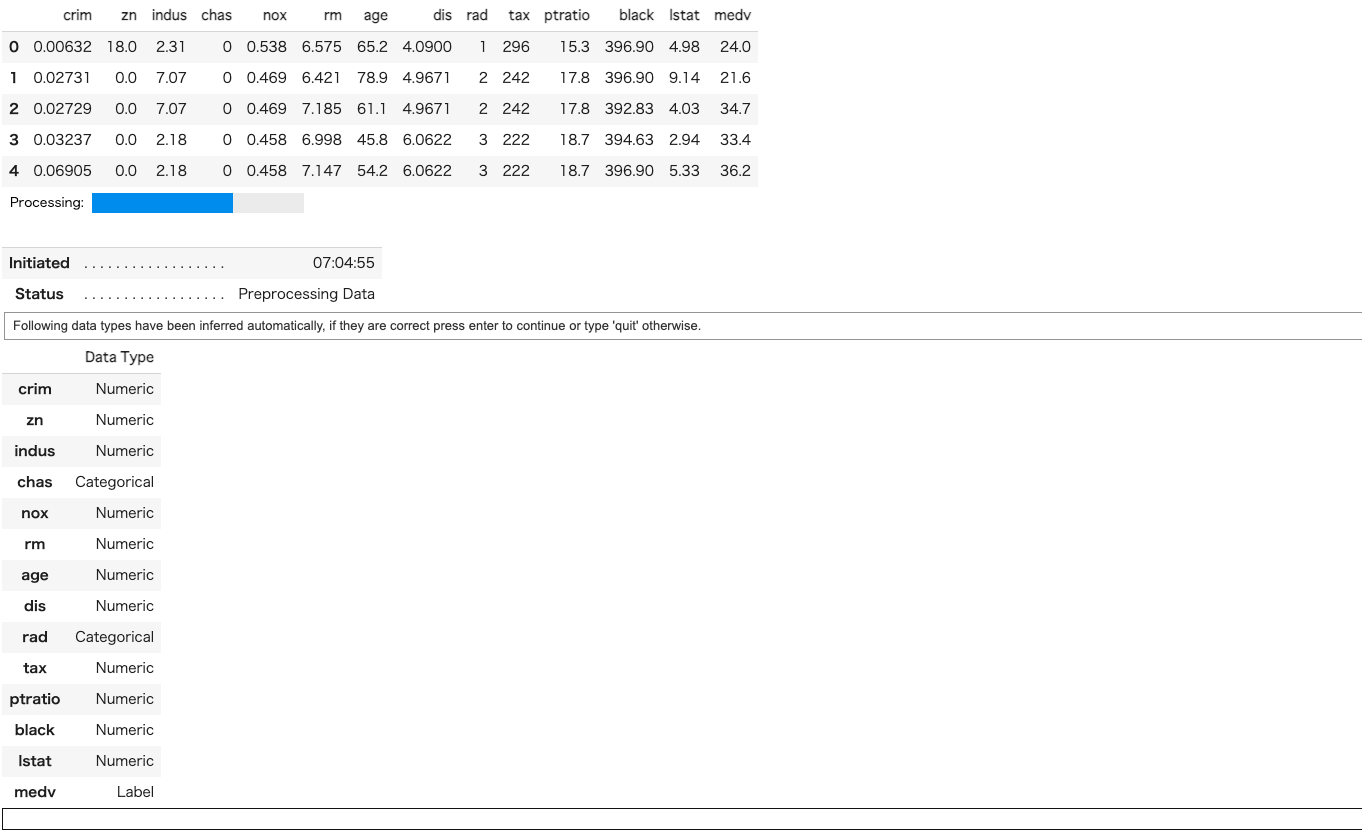
起動すると、投入したデータに対するデータ型の予測結果が表示されます。
きちっと中身を自分でも確認する必要があります。
問題がなければ、下の白枠にカーソルで「Enter」を押します。
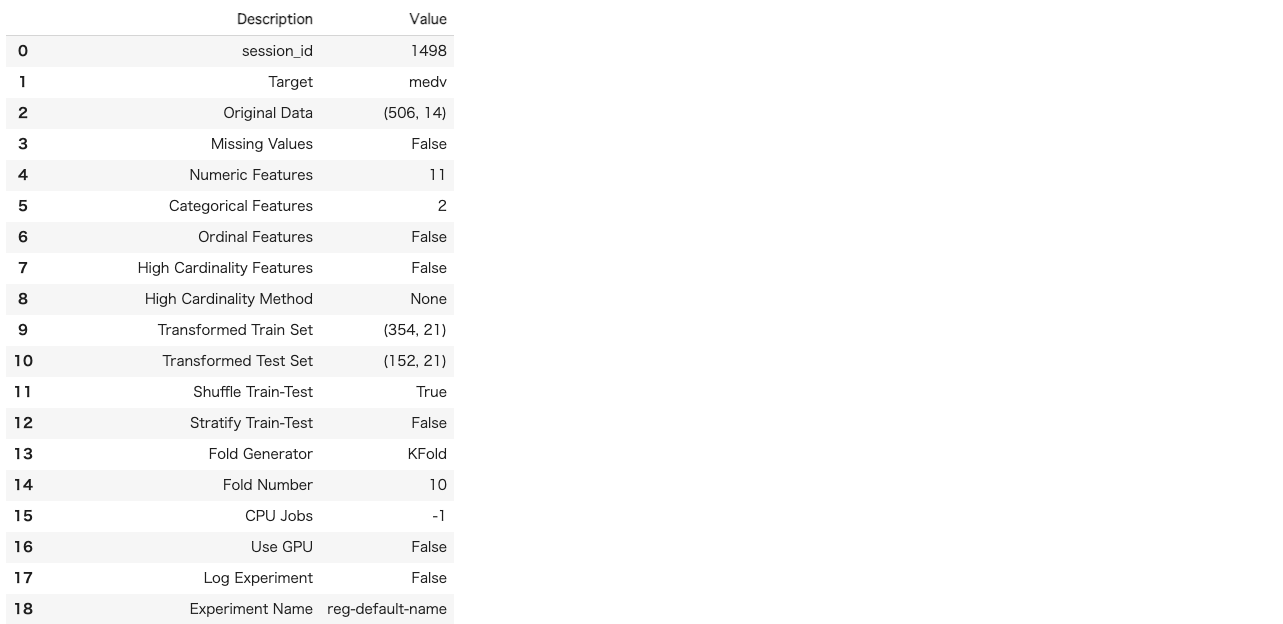
セットアップが完了します。session_idで乱数シードを固定できます。
次にモデルを構築します。
# モデルの構築
compare_models()
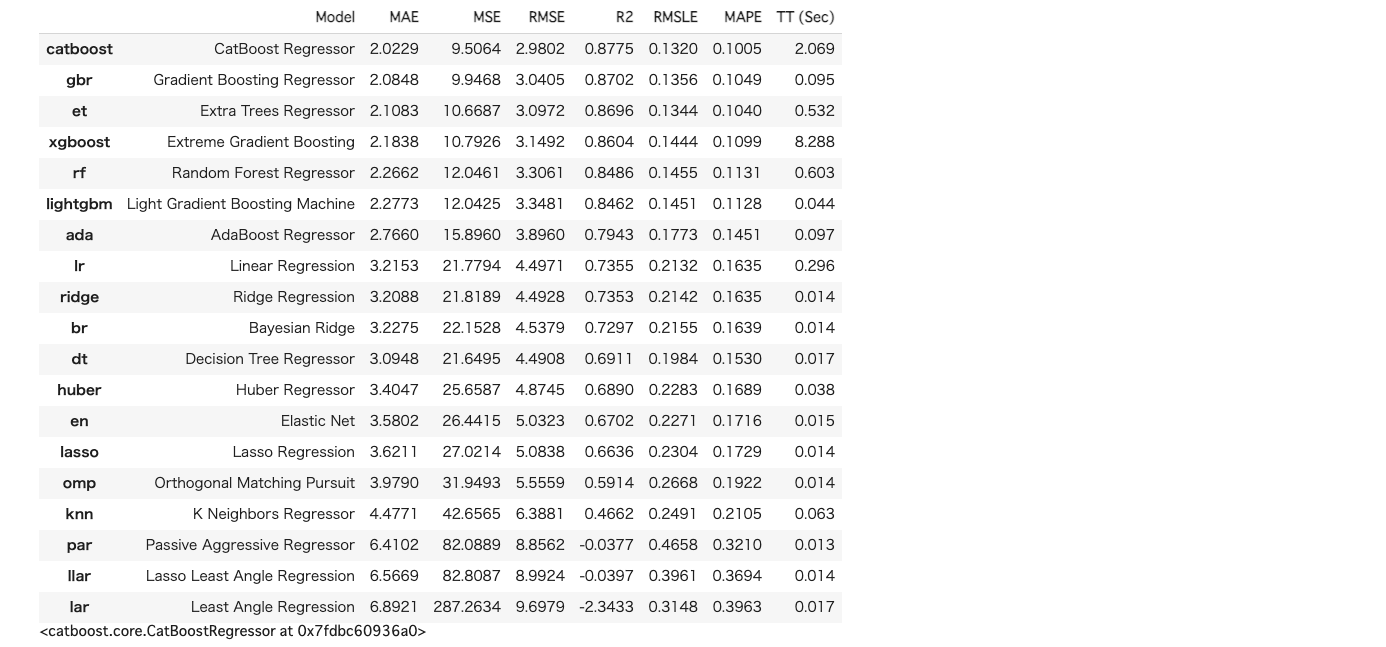
「CatBoost Regressor」や「Gradient Boosting Regressor 」、「Ridge Regression」など主要な回帰モデルを自動で作成し、評価指標も自動で計算してくれます。
ただし、現状はハイパーパラメータのチューニングまでは実施されていません。
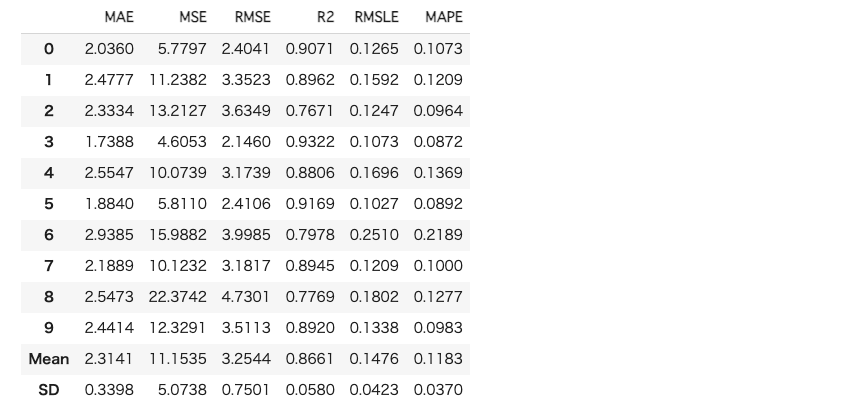
次にモデル構築時に交差検証をデフォルトでは10回実施してくれておりますので、その結果を確認してみようと思います。
今回は一番精度の良かったcatboostを選択します。
# catboostのモデルを確認
catboost = create_model('catboost')

次にハイパーパラメータのチューニングを実施します。
パラメータのチューニング方法はランダムグリッドサーチになります。
# catboostのモデルを最適化
catboost_tuned = tune_model(catboost, optimize = 'MAE')
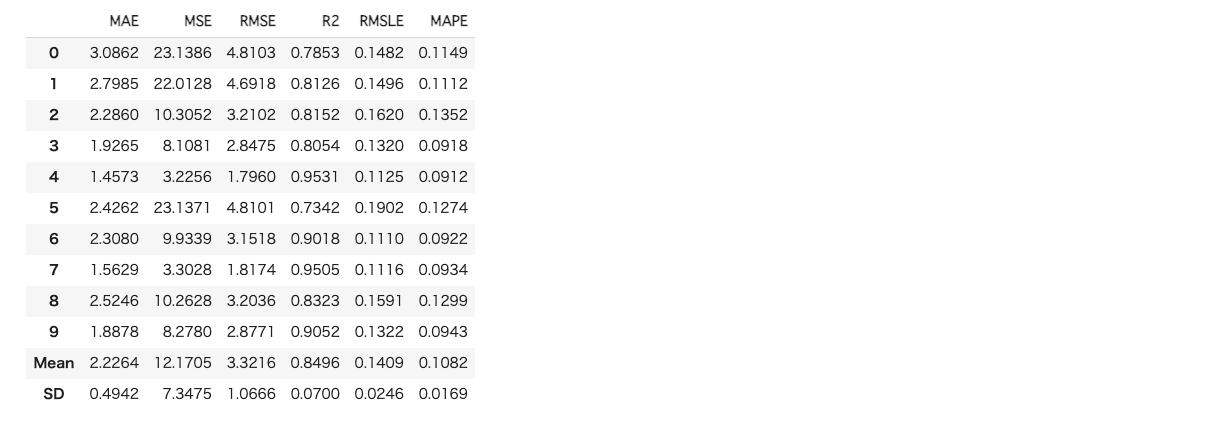
次に解析結果を確認します。
# 解析結果の確認
evaluate_model(catboost_tuned)
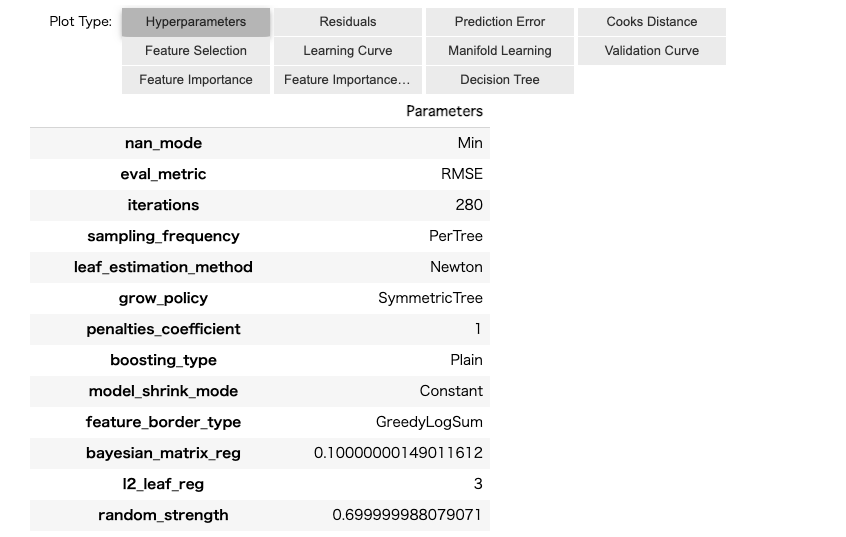
「Hyperparameters」で最適化後のハイパーパラメータの値を確認することができます。
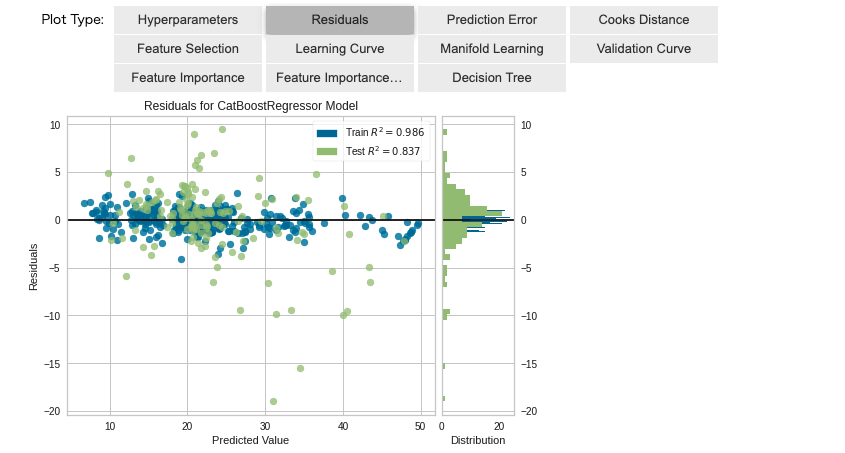
「Residuals」で残差分析の結果を確認できます。
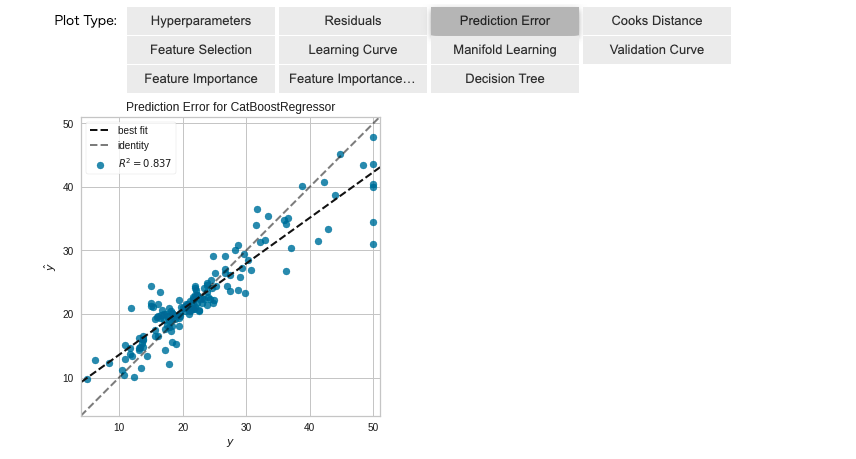
「Prediction Error」で予測精度を確認できます。
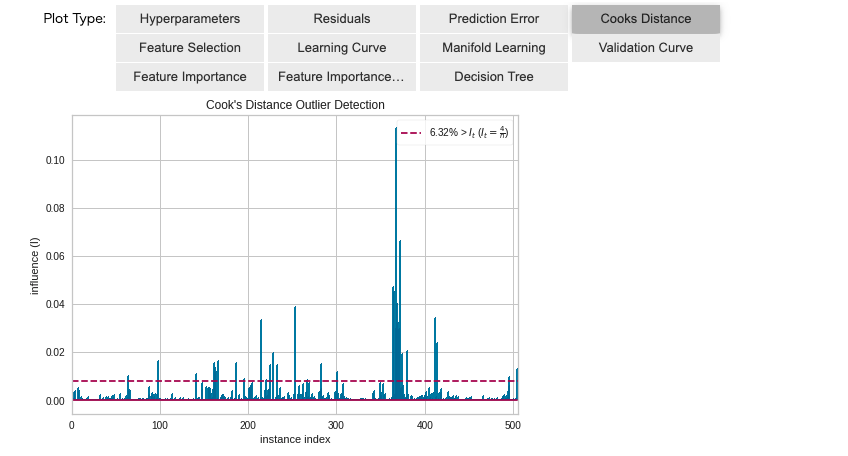
「Cooks Distance」でクックの距離を確認できます。クックの距離とは、「i番目の観測値を使用して計算された係数と、観測値を使用しないで計算された係数との間の距離に対する測度」です。
他に「Feature Importance:変数重要度」や「Learing Curve:学習曲線」、「Validation Curve:木の深さによる予測精度の変化」等を確認できます。選択した手法によって分析できる内容は異なります。
最後にアンサンブル学習などもできます。
# アンサンブル学習
lgbm = create_model('lightgbm')
xgboost = create_model('xgboost')
ensemble = blend_models([lgbm, xgboost])
さいごに
最後まで読んで頂き、ありがとうございました。
こんな便利なライブラリーがあるとは知りませんでした。DataRobot無くても十分満足できる解析ができますね。
訂正要望がありましたら、ご連絡頂けますと幸いです。