- 製造業出身のデータサイエンティストがお送りする記事
- 今回はAutoML(VARISTA)を使ってみましたので、メモとして残しておきます。
VARISTAとは
VARISTAは、機械学習を効率的に行うためのプラットフォームです。つまり、AutoMLですね。DataRobotやdotDataとかと一緒です。
後者の二つのAutoMLは有料ですが、VARISTAは無料でも一部機能が使えます。
基本的な流れ
GUIで全てできるので細かい説明は不要かと思いますが(サポートもでますので)、簡単に下記に整理しておきます。
- データセットを準備(サンプルデータも用意されております)
- 構築するモデルを作成
- 構築できるモデルは決まっております(無料プランのみ確認)
- XGBoost
- lightGBM
- catboost
- scikit-learn(一部)
- 有料プランではもっと他のモデルが使える可能性があります。
- 構築できるモデルは決まっております(無料プランのみ確認)
- モデル学習
- 学習モデルの評価
- その他
- ハイパーパラメータが利用可能です
実際の使い方
データのアップロード
今回はサンプルのタイタニックのデータをアップロードしております。
無料版では、100MBぐらいまでのデータセットなら使用できるようです。
プロジェクトは一つしか作成できないので、本当にお試しという感じですね。
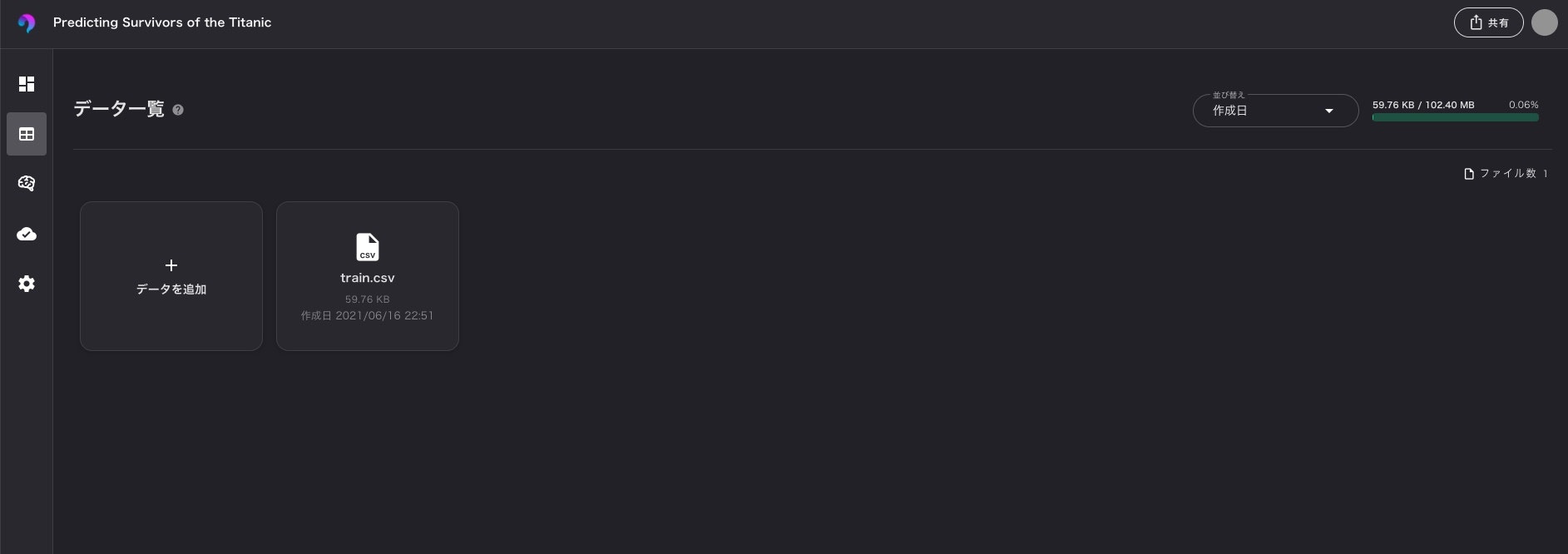
アップロードしたデータは、下記のような感じで各カラム毎にデータの型、欠損値、使用可否を簡単に確認・選択できます。
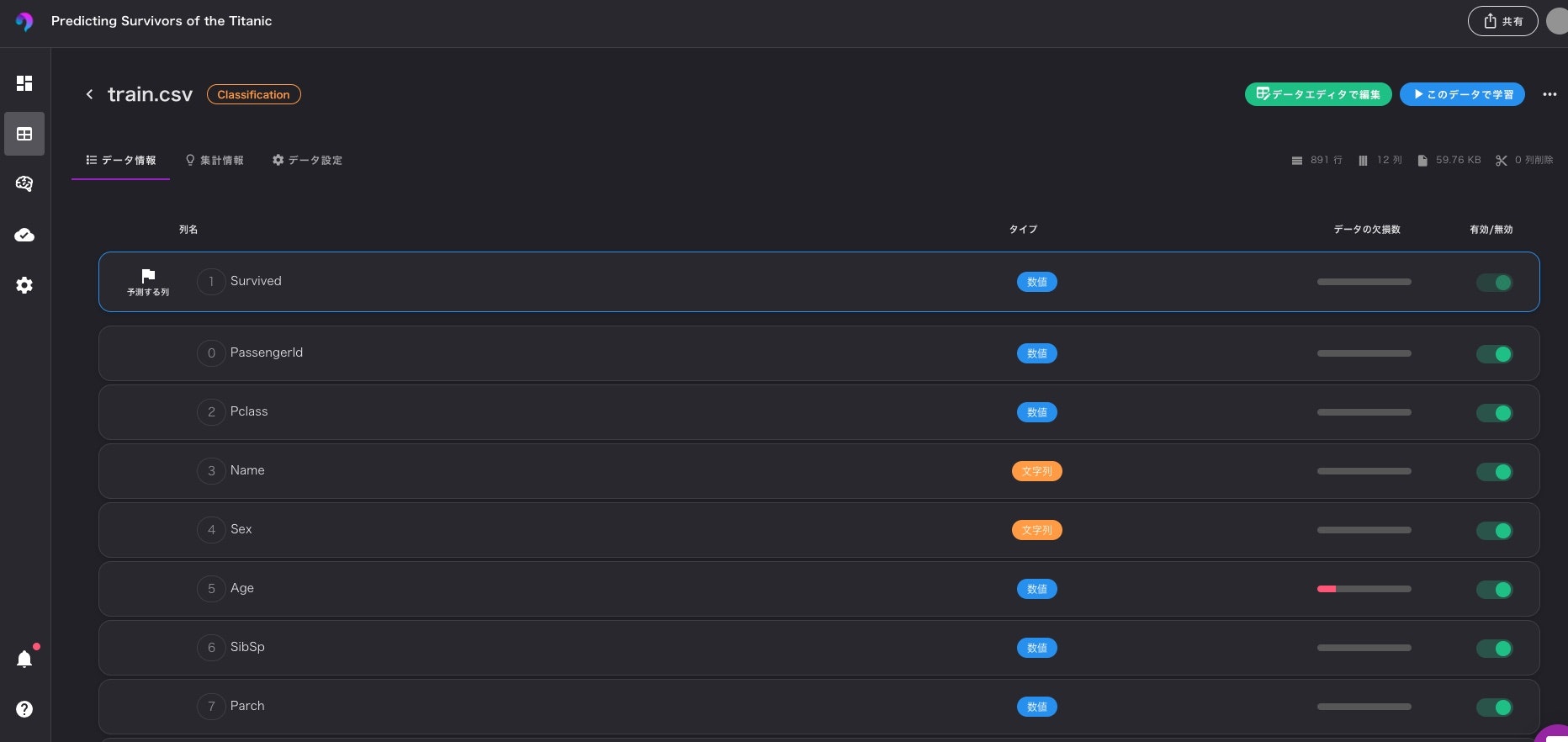
モデルの構築
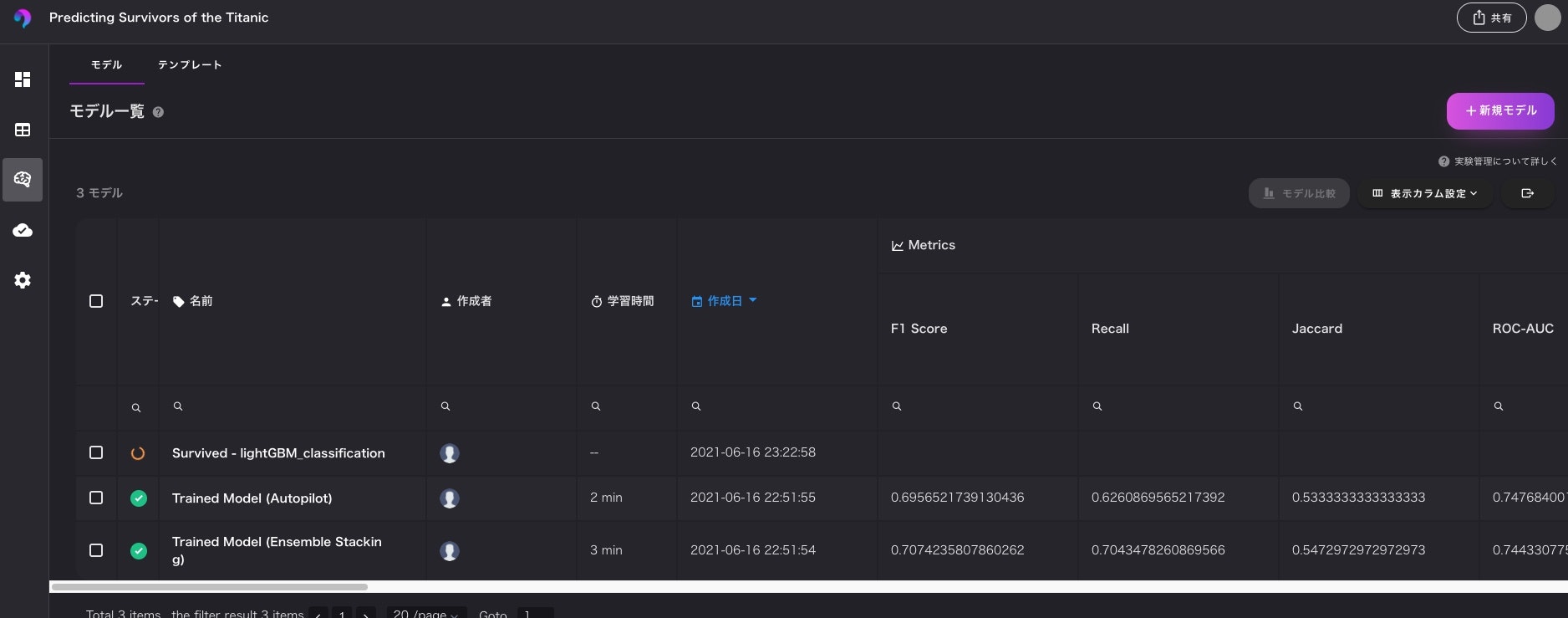
次に構築するモデルを作成します。無料プランではサンプルでいくつかのモデルが作成されております。
一番上の「lightGBM_classificaion」が今回作成したモデルであり、その他はテンプレとして用意してくれているモデルです。
モデルを構築する際は、構築するモデルの目的(回帰、分類)を選択し、前処理や検証データの分割方法とかを選択できます。
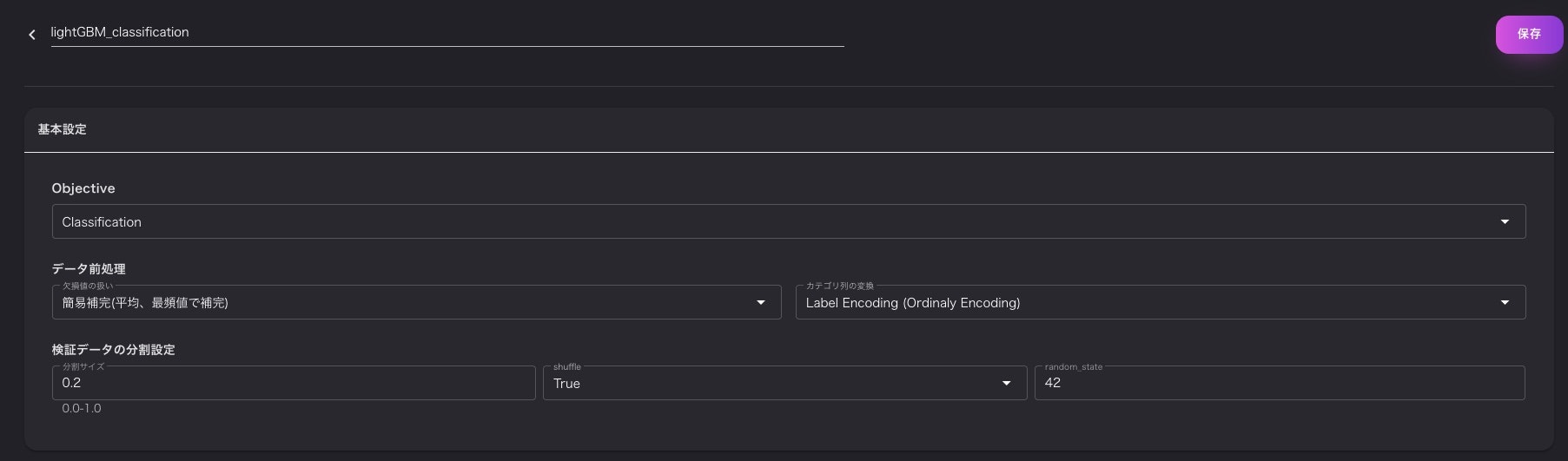
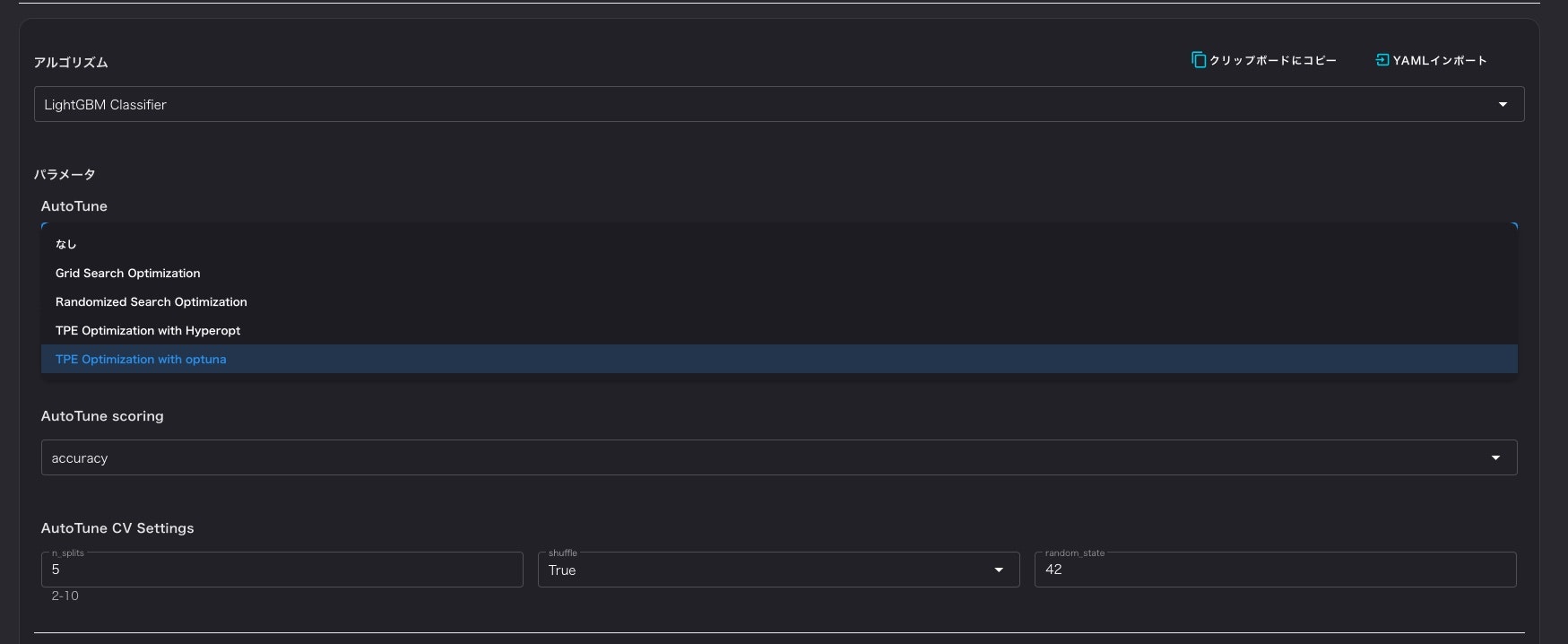
その他、アルゴリズムはハイパラチューニング方法も選択できます。
ハイパラチューニングはグリッドサーチ、ランダムサーチ、ベイズ最適化(Hyperopt、optuna)が選択できます。
その他、ハイパラの探索範囲なども選択できるようになっております。
モデルの学習
あとは、モデルを選択して学習します。
構築したモデルの評価
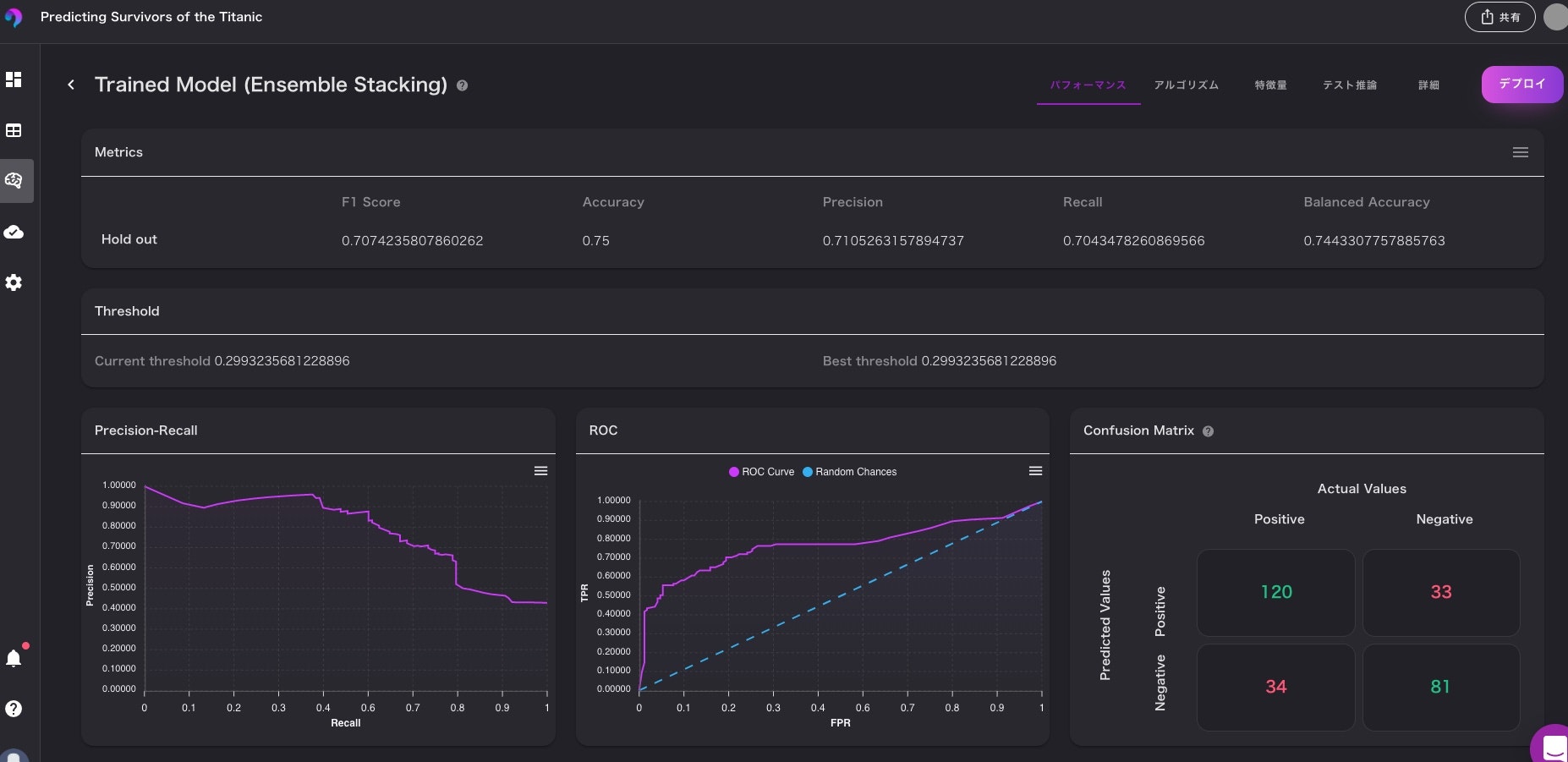
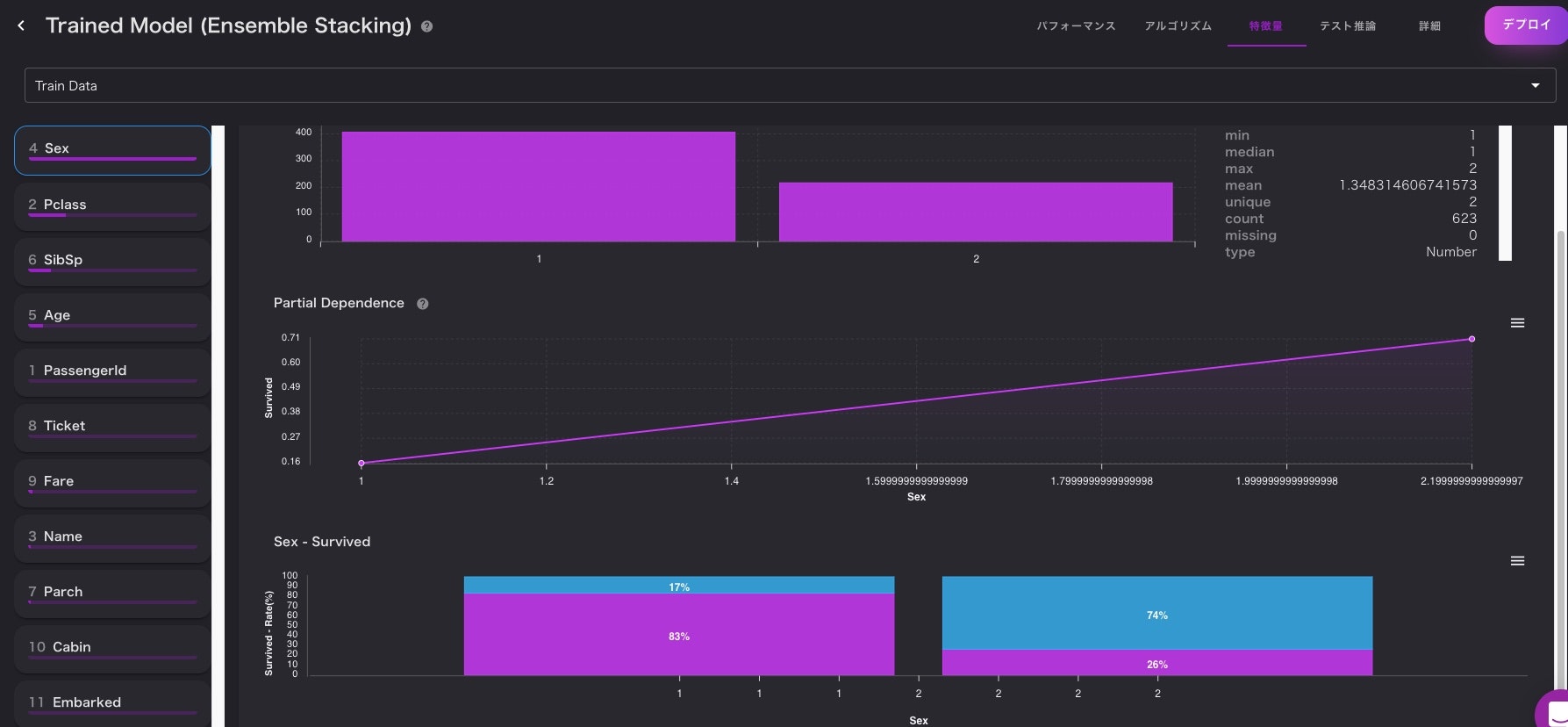
構築したモデルの中身を見て評価を行います。
分析できる項目としては、ある程度揃っている印象があります。
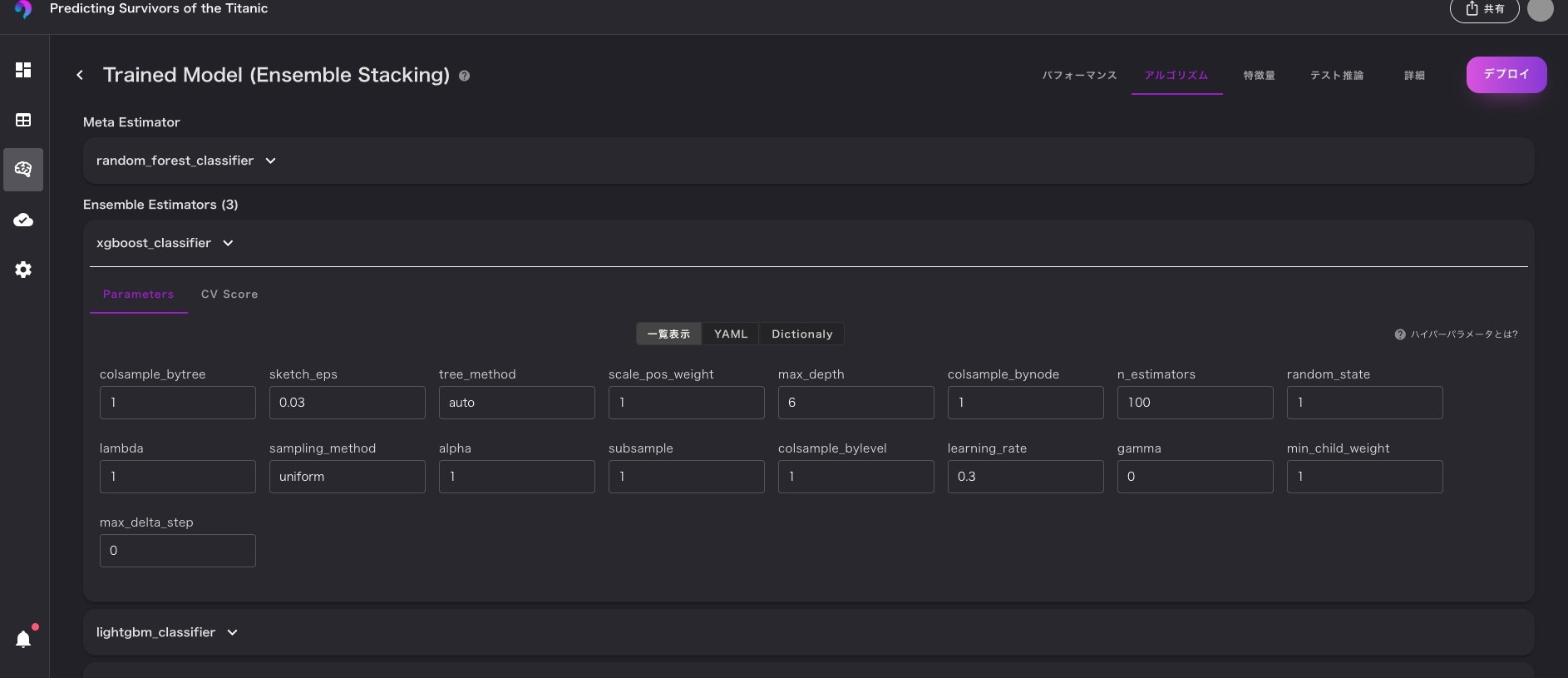
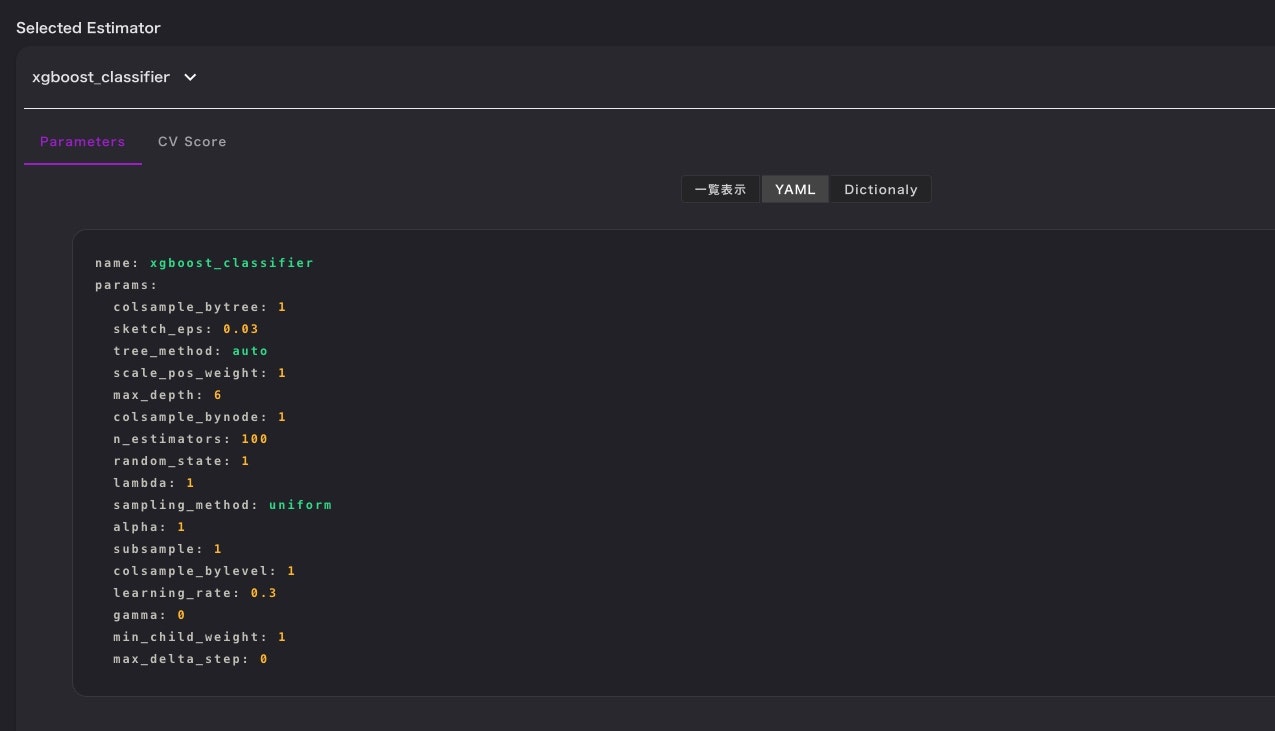
その他
構築したモデルのハイパラもyamlファイルで取得可能です。
ただし、pythonで完全に同じモデルを再現できるのかどうかは確認しておりません。
さいごに
最後まで読んで頂き、ありがとうございました。
今回はAutoML(VARISTA)を使ってみましたので、メモとして整理してみました。
有料版を試していないので分からないですが、モデルの種類に関してはDataRobotが一番多くて良いのかなとは思います。
また、dotDataは特徴量エンジニアリング自動化の部分が強みです。
VARISTAは上記2つのAutoMLツールに対してどのような優位性を持って戦っていくつもりなのか、無料版では見えてこなかったため、そこら辺が分かると選択肢の候補として上がるのかなと思います。
一方で、無料でもお試して簡単に使えるのは良かったです。